




文章转载自公众号:DB印象
业务需求描述
要求每个事务逻辑延迟1秒以内,业务初期读写3000的QPS,后续有明星大咖空降活动,要求QPS能力可横向扩展。
注:这里说的读写3000的QPS,其实水有点坑。(详见后文)
系统架构环境
1.前端应用部署55台客户端设备,单台client机型配置8核心14G内存,程序使用golang+lib/pq实现编码。
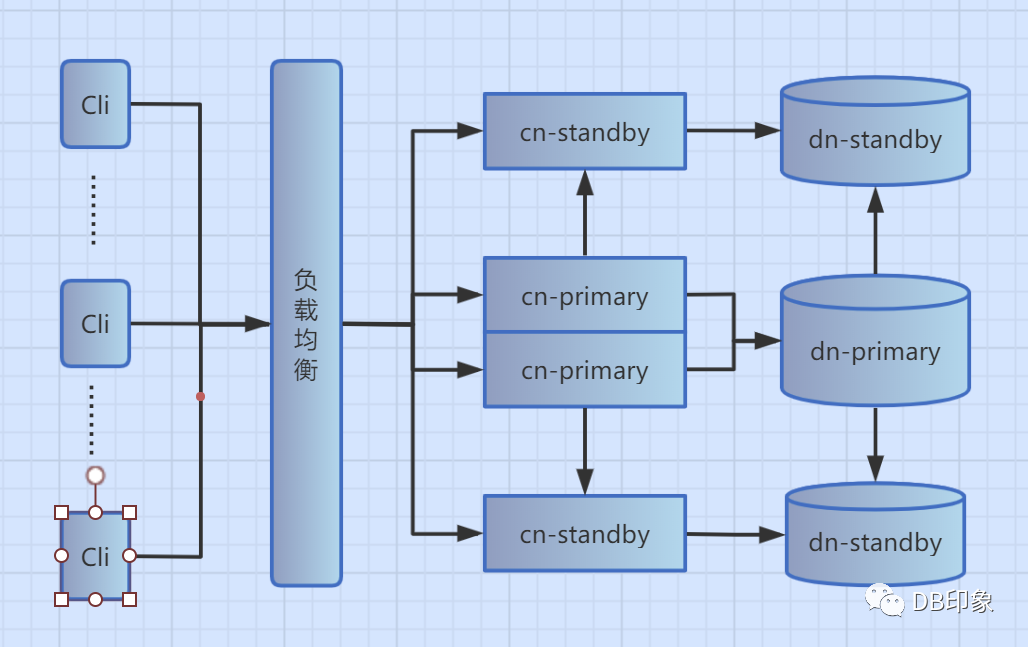
2.DB侧使用pg分布式,单分片一主二从架构,可进行读写分离(后续有时间再补充独立分离的情况):
1)写平面配置2个cn,机型8核14G虚拟机;
2)同城只读平面、异地只读平面各配置1个cn,8核14G虚拟机。
3)主备dn节点一主二从均为32核64G的物理机,SSD存储。
3.架构简图如下:
压测优化过程
业务层面设置每个tps为1秒强制超时,当tps达到500时业务出现大量超时报错,吐槽pg能力太差:
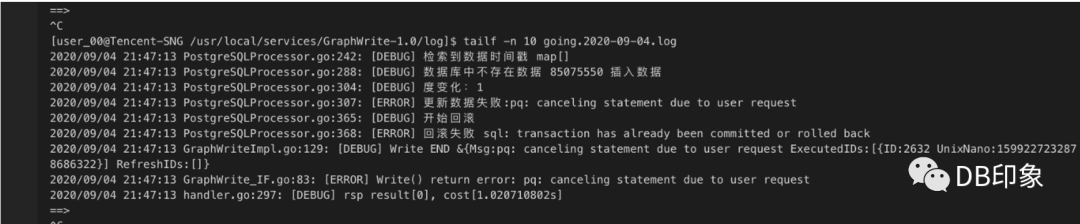


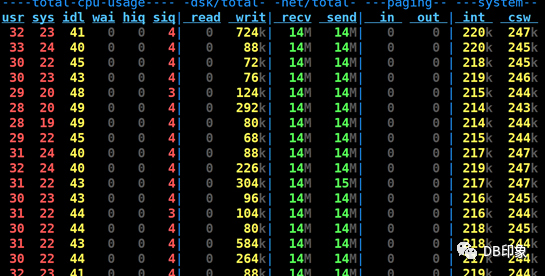
1.client配置上,连接数上限为32个,从db侧观察到32个连接已经全部用完。(剩余的324个连接为压测程序外的应用空闲连接):

2.从QPS信息看,压测程序业务请求属于读写混合型,读写比例各一半,业务事务处理逻辑如下:
// WritePeer 在事务内,写一端的数据func (pg *PostgreSQLProcessor) WritePeer(ctx context.Context, req *graph.WriteReq, rsp *graph.WriteRsp)(int32, error) {pg.log.Debug("写tdsql一端数据:%+v", req)vertexConfig := pg.GetVertexConfig(&req.GraphBasic)if vertexConfig.IsStoreOfflineEdges == false {本端不用写return 0, nil}targetsIDs := make([]string, 0)for _, v := range req.TargetsIDs {targetsIDs = append(targetsIDs, v.ID)}tablename := pg.GetTableName(req.GraphBasic.NodeType)pg.log.Debug("tablename is %v", tablename)degreeChange := 0首先检索数据存在args := make([]interface{}, 0)args = append(args, req.SourceID)for _, id := range targetsIDs {args = append(args, id)}rows, sqlerr := pg.tx.QueryContext(ctx, fmt.Sprintf("select id,target,unixnano,status from %s where id = $1 and target = ANY($2) for update", tablename),req.SourceID, pq.Array(targetsIDs))if sqlerr != nil {pg.log.Error("检索已有数据失败:%s", sqlerr)return -7700, sqlerr}defer rows.Close()edgeRows := make([]EdgeRow, 0)for rows.Next() {e := EdgeRow{}err := rows.Scan(&e.ID, &e.Target, &e.Unixnano, &e.Status)if err != nil {return -7800, err}edgeRows = append(edgeRows, e)}pg.log.Debug("检索到数据 %+v", edgeRows)// 记下数据库时间戳timeMap := make(map[string]*EdgeRow)for _, r := range edgeRows {timeMap[r.Target] = &r}pg.log.Debug("检索到数据时间戳 %+v", timeMap)// 根据情况写入数据for _, target := range req.TargetsIDs {dbrow, ok := timeMap[target.ID]if ok {if dbrow.Unixnano >= target.UnixNano {// 数据库中的时间大 不处理pg.log.Debug("数据库中的时间大 不处理")}if dbrow.Unixnano < target.UnixNano && dbrow.Status == req.Operation {// 数据库中时间小 但是状态与数据库中的时间一致 则只刷新时间pg.log.Debug("数据库中时间小 但是写入状态与数据库中的一致 则只刷新时间")rsp.RefreshIDs = append(rsp.RefreshIDs, target)_, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("update %s set unixnano = $1 where id = $2 and target = $3", tablename),target.UnixNano, req.SourceID, target.ID)if sqlerr != nil {pg.log.Error("更新数据失败:%s", sqlerr)return -7901, sqlerr}}if dbrow.Unixnano < target.UnixNano && dbrow.Status != req.Operation {// 数据库时间小 但是状态与数据库中不一致 覆盖时间和操作pg.log.Debug("数据库时间小 但是状态与数据库中不一致 覆盖时间和操作")rsp.ExecutedIDs = append(rsp.ExecutedIDs, target)var result sql.Resultresult, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("update %s set unixnano = $1 , status = $2 where id = $3 and target = $4", tablename),target.UnixNano, req.Operation, req.SourceID, target.ID)if sqlerr != nil {pg.log.Error("更新数据失败:%s", sqlerr)return -7902, sqlerr}rowsAff, sqlerr := result.RowsAffected()if sqlerr != nil {pg.log.Error("获取不到更新行:%s", sqlerr)}if rowsAff > 0 {// 判断覆盖方式对度的影响if req.Operation == graph.ESet {degreeChange++} else if req.Operation == graph.EUnset {degreeChange--}}pg.log.Debug("更新了时间 %v", target.UnixNano)}} else {// 数据库中不存在数据 插入数据pg.log.Debug("数据库中不存在数据 %v 插入数据", target.ID)rsp.ExecutedIDs = append(rsp.ExecutedIDs, target)// 判断覆盖方式对度的影响if req.Operation == graph.ESet {degreeChange++}// 如果不存在数据时,插入了取消边操作,则度不变化_, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("INSERT INTO %s (id, target, unixnano, status)VALUES ($1, $2, $3, $4)", tablename),req.SourceID, target.ID, target.UnixNano, req.Operation)if sqlerr != nil {pg.log.Error("更新数据失败:%s", sqlerr)return -7903, sqlerr}}}if degreeChange != 0 {pg.log.Debug("度变化:%v", degreeChange)_, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("INSERT INTO %s (id, degree) VALUES ($1, $2) on conflict(id)do UPDATE set degree = %s.degree + $2",tablename+degreeSuffix, tablename+degreeSuffix), req.SourceID, degreeChange)if sqlerr != nil {pg.log.Error("更新数据失败:%s", sqlerr)return -7904, sqlerr}}return 0, nil}
将代码中的SQL抽象出来的具体如下:
read:select target, unixnano from %s where id = $1 and status = 0 order by unixnano desc limit $2select target, unixnano from %s where id = $1 and unixnano < $2 and status = 0 order by unixnano desc limit $3select target, unixnano from %s where id = $1 and target = ANY($2) and status = 0select degree from %s where id = $1write:select id,target,unixnano,status from %s where id = $1 and target = ANY($2) for updateupdate %s set unixnano = $1 where id = $2 and target = $3update %s set unixnano = $1 , status = $2 where id = $3 and target = $4INSERT INTO %s (id, target, unixnano, status) VALUES ($1, $2, $3, $4)INSERT INTO %s (id, degree) VALUES ($1, $2) on conflict(id) do UPDATE set degree = %s.degree + $2select target, unixnano from %s where id = $1 and status = 0 order by unixnano desc limit $2
意思是每次事务处理之前都会先读取4次,写请求中第一句是事务起始读,根据返回结果执行如下三句中的一句,最后统一执行最后一句,执行完成后还要再查询一次。
每次业务从应用app界面请求的操作伴随两次相同的事务,即如果外网请求量为3000 qps,那么DB侧的写请求会达到 3000*2*5=3w tps ,读请求达到3000*2*5=3w qps,即业务说的的3000请求,事实上需要db侧能够支撑6w的QPS。
这个逻辑看起来感觉很别扭,经和开发同学沟通,其根本目的是根据id和target字段的唯一性来判断目标表中的记录是否已存在,无则插入,有则更新unixnano和status字段的值。
用意已明,纷纷扰扰这么复杂,其实该逻辑需求在pg里面可以合并起来用1个SQL就可以达到相同的目的:
INSERT INTO %s (id, target, unixnano, status) VALUES(123, 456, 789, 0) on conflict(id, target)do UPDATE set unixnano = $1, status = $2;
业务逻辑优化之后,整改代码就变成了下面这个样子:

代入具有代表性的变量值,验证一下单次SQL的性能,耗时在8.134ms:
moment_fav_test=# explain analyze INSERT INTO vertexa(id, target, unixnano, status) VALUES (123, 456, 789, 0) on conflict(id, target) do UPDATE set unixnano = 789, status = 0;QUERY PLAN---------------------------------------------------------------------------------------------------------Remote Fast Query Execution(cost=0.00..0.00 rows=0 width=0)(actual time=8.105..8.105 rows=0 loops=1)Node expr: 123Planning time: 0.087 msExecution time: 8.134 ms(4 rows)
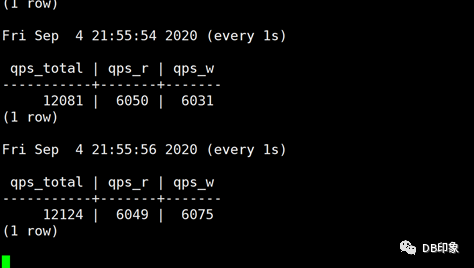
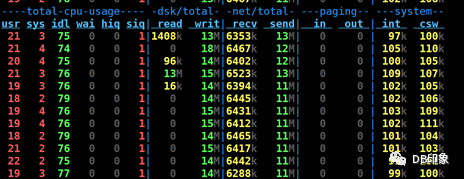
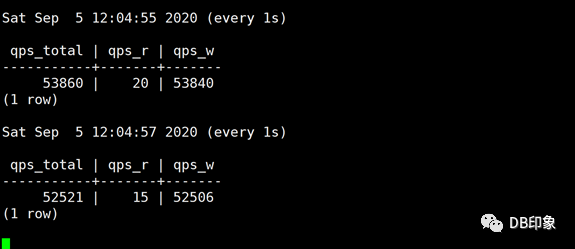
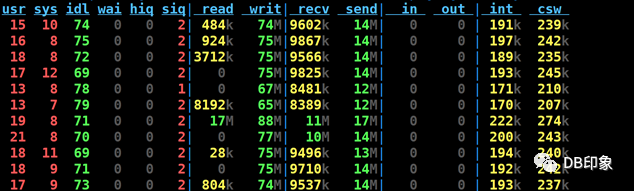
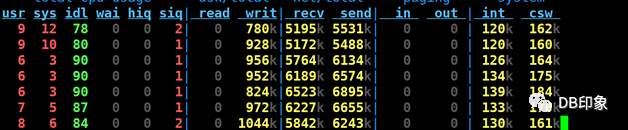
最后将client连接数上限配置为160,保持client数量为1台8核14G的虚拟机,QPS保持在5W左右可以稳定运行,业务请求成功率100%,dn节点CPU空闲70%以上,cn的CPU空闲87%以上:
cn负载:

总结
按上面的DB负载和QPS能力表现,单个primary节点的QPS理论极限能力应该远在5w的水平上。
如果说为了满足业务3000的QPS能力,使用1台client和pg的单主已经足够,何况这里还没有将该分片的一主二备的读写分离利用起来,而且后面随着业务增长,我们还可以继续横向扩展。
建议前端应用每个客户端设置32个长连接上限,只需5台同等配置的设备即共160个连接需求可满足业务1w的写需求(理论可支撑3W),可直接为业务节省50台的设备成本。
I Love PG
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:中国PG分会)于2017年成立,由国内多家PostgreSQL生态企业所共同发起,业务上接受工信部中国电子信息产业发展研究院指导。中国PG分会是一个非盈利行业协会组织。我们致力于在中国构建PostgreSQL产业生态,推动PostgreSQL产学研用发展。
技术文章精彩回顾 PostgreSQL学习的九层宝塔 PostgreSQL职业发展与学习攻略 2019,年度数据库舍 PostgreSQL 其谁? Postgres是最好的开源软件 PostgreSQL是世界上最好的数据库 从Oracle迁移到PostgreSQL的十大理由 从“非主流”到“潮流”,开源早已值得拥有 PG活动精彩回顾 创建PG全球生态!PostgresConf.CN2019大会盛大召开 首站起航!2019“让PG‘象’前行”上海站成功举行 走进蓉城丨2019“让PG‘象’前行”成都站成功举行 中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行 群英论道聚北京,共话PostgreSQL 相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报 相知巴厘岛| PG Conf.Asia 2019 DAY2简报 独家|硅谷Postgres大会简报 直播回顾 | Bruce Momjian:原生分布式将在PG 14版本发布 PG培训认证精彩回顾 中国首批PGCA认证考试圆满结束,203位考生成功获得认证! 中国第二批PGCA认证考试圆满结束,115位考生喜获认证! 重要通知:三方共建,中国PostgreSQL认证权威升级! 近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕! 2020年首批 | 中国PostgreSQL初级认证考试圆满结束 一分耕耘一分收获,第五批次PostgreSQL认证考试成绩公布 PG专辑预览阅读

