




01
—
历史由来
2003年,谷歌将为了解决内部数据储存而开发的分布式存储方案发表成论文《The Google File System》,即GFS。2003年时,谷歌已经需要储存大量的搜索数据,以往的增加单个磁盘大小存储方案已经不能满足谷歌的要求。因此gfs的设计希望可以将大文件分别存储到多台便宜的储存设备中,实现数据的分布式存储,并通过数据冗余备份保证存储的可靠性。
其整体实现思路如图:

GFS系统包括master、多个chunkserver以及多个客户端(client)。文件被切分为固定大小的小文件(chunk)。每个chunk创建时,master会分配一个64bit的全局唯一且不可修改的chunk handler来标志这个chunk。chunkserver负责将chunk存储在本地磁盘的Linux文件中,并通过chunk hander和byte range来读写chunk文件。为了提高可靠性,每个chunk都是多副本存储在多个chunkserver上,默认情况下是三副本。用户可以为不同名字空间下的文件配置不同的副本数。
Master维护所有文件系统的元数据,master节点主要存储三种类型的元数据:文件和chunk的命名空间(namespace),文件和chunk的映射关系(mapping),每个chunk副本的位置(location)。它也控制系统范围内的一些活动,比如chunk租赁管理,chunk的垃圾回收,chunkserver间chunk的迁移。Master与chunkserver通过周期性的心跳进行通信,从而发送指令和获取chunkserver的状态。
为了方便实现,GFS中只存在一个master来控制,而每个chunk的大小被设定为64M,这个数字是谷歌内部总结出来的合理值,太小提高master的压力,也因为内部空间碎片造成的空间的浪费;太大则单个节点上处理数据的时间会过长增加文件块大小,增加磁盘的传输速率要求。另一方面整个集群系统的任务数会减少,使得分配到任务的节点过少,这样不能充分利用集群,达不到应有的集群利用率。
客户端如果需要操作元数据则需要与master通信,其他的所有的纯数据的通信直接与chunksever通信。
GFS的数据备份机制:谷歌的GFS集群中包含有成百上千个chunksever,其分布在若干个机架上。在数据的备份时,为了保证最大程度保证数据的可靠性,同时减少网络宽带的压力,会尽可能把副本分散到不同的机架中。通常每个chunk会备份3个。
GFS的垃圾回收机制:当一个文件被删除后,master会将删除计入日志,并对chunk进行标记,但是不会立马删除,而只是将文件重命名为一个包含了删除时间戳的隐藏文件名。在master对namespace进行常规扫描的时候,如果发现这中隐藏的文件已经存在了3天以上了就才会被移除。
02
—
HDFS设计架构
Hadoop吸纳了GFS的经验,开发了HDFS,原理大致相同,但是HDFS做了一些简化,比如删除文件改为了直接删除而非标记。
HDFS的设计模型:
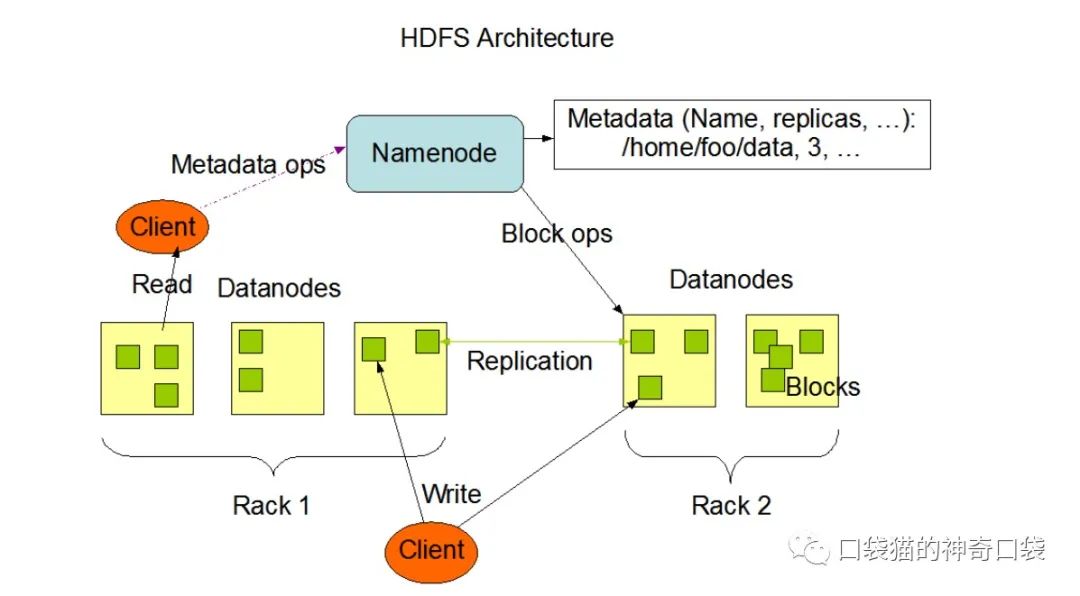
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成,其中Namenode相当于GFS中的master,负责执行有关文件系统命名空间 的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。HDFS中还设置了Secondary NameNode来辅助NameNode,帮助NameNode合并编辑日志,减少NameNode 启动时间,在紧急情况,可辅助恢复NameNode。
DataNode则负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作,存储实际的数据块。
客户端负责文件的切分,将上传的文件切分成一个一个的Block来存储,其可以从NameNode获取文件的位置,也可以从DataNode来读取和写入文件。
03
—
HDFS存储机制
HDFS存储机制,包括HDFS的写入数据过程和读取数据过程两部分:
读取流程:
客户端通过向NameNode请求下载文件,NameNode查询元数据到文件块所在的DataNode地址。挑选最近一台DataNode服务器,请求读取数据。DataNode将数据传输给客户端,客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
写入流程:
客户端向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。NameNode返回是否可以上传后,客户端请求NameNode将数据上传到哪几个datanode服务器上。NameNode返回3个datanode节点 。客户端便向第一个节点传入数据,第一个节点将数据传给第二个节点,第二个节点将数据传给第三个节点,之后依次循环这个过程。
