




1、数据库的诞生
20世纪60年代,硬盘开始取代磁带广泛使用,相较于磁带只能顺序读取,硬盘中的数据可以在十几毫秒中访问到,数据摆脱了访问顺序的限制,可以创建网状和层次的数据库,并以链表、树、图等数据结构保存在磁盘上。
2、实现一个简单的数据库
一个单机的数据库系统如何实现可以参考sqlite的实现原理,SQLite实现了一个小型、快速、独立、高可靠性、功能齐全的SQL数据库引擎。SQLite是世界上最常用的数据库引擎。SQLite内置于所有手机和大多数计算机中,并捆绑在人们每天使用的无数其他应用程序中。其功能架构如下图:
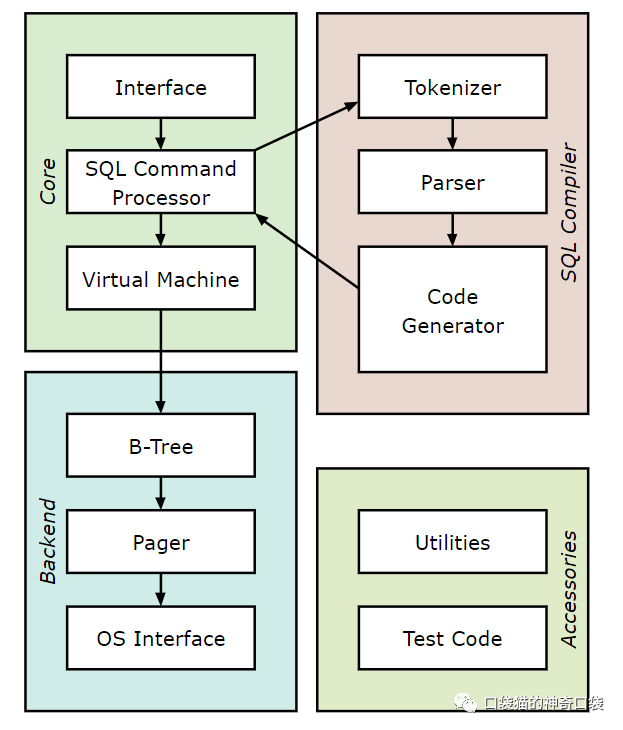
从图中可以看出,sqlite的重点部分在于sql语法分析器与存储引擎,储存引擎是数据库的核心,储存引擎底层是可以采用多种类型的数据结构实现的,不同的数据结构有不同的效果,储存引擎本质目的是为了将数据更快的写入,查询及修改。
储存引擎通过索引关联数据文件,索引就像是目录,目的是为了让计算机更快的查询到需要的数据文件。不同的数据可能会采用不同的数据结构来构建索引结构,如果不考虑性能的情况下,以链表为索引,关联数据文件也是可以实现数据引擎的。
a.以哈希的储存引擎
哈希存储的基本思想是以关键字Key为自变量,通过一定的函数关系(散列函数或哈希函数),计算出对应函数值(哈希地址),以这个值作为数据元素的地址,并将数据元素存入到相应地址的存储单元中。查找时再根据要查找的关键字采用同样的函数计算出哈希地址,然后直接到相应的存储单元中取要找的数据元素。代表性的数据库:Redis
b.B+树
B+树是一种数据结构,是一个N叉排序树,每个节点通常有多个子节点,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点, 也可能是一个包含两个或两个以上子节点的节点。
B+树通常用于数据库和操作系统的文件系统中。NTFS、ReiserFS、NSS、XFS、JFS、ReFS和BFS等文件系统都在使用B+树作为元数据索引。B+树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入。
b+树索引本质上是利用了二分查找法,通过主键的值更快的找到数据所在的区域。因此B+树索引并不能找到一个给定键值的具体行。B+树索引只能找到的是被查找数据行所在的页。然后数据库通过把页读入内存,再在内存中进行查找,最后得到查找的数据。
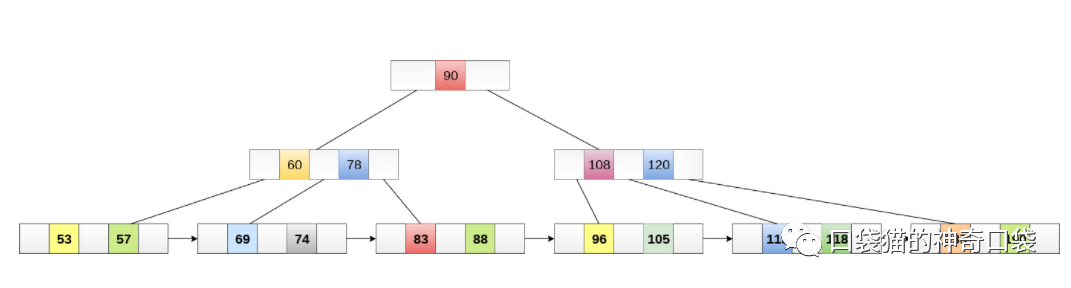
B+树常被用于数据库中,作为Mysql数据库索引。索引(index)是帮助MySQL高效获取数据的数据结构。以mysql最常用的储存引擎InnoDB为例:
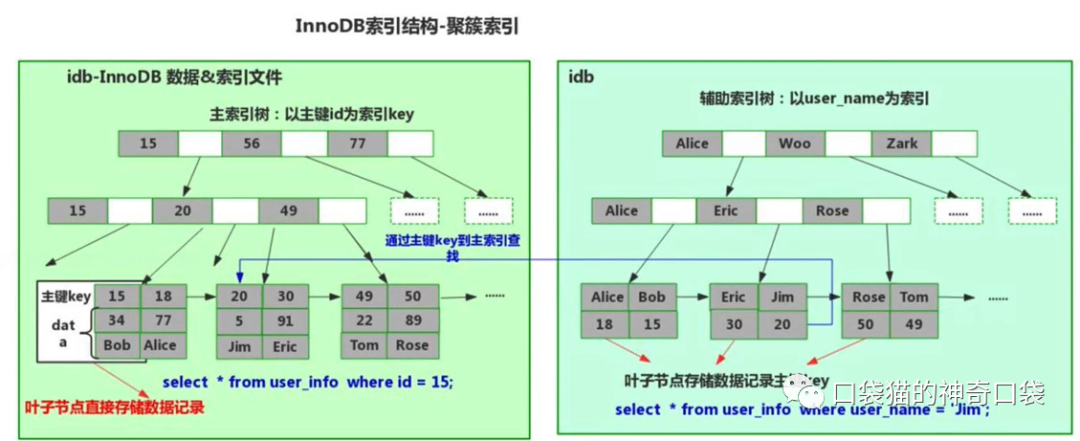
在InnoDB存储引擎中,表数据文件本身就是按B+树组织的一个索引结构,这棵树的叶节点数据保存了完整的数据记录,所以我们把它的主索引叫做聚集索引。而它的辅助索引都是将主键作为数据域,所以这样当我们查找的时候通过辅助索引先找到主键,然后通过主索引找到对应的主键,从而得到相应的数据信息。
c.sql分析器
为了让数据库知道要做什么,因此需要sql分析器对 SQL 语句做解析。分析器先会做“词法分析”。由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。MySQL 从输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断输入的这个 SQL 语句是否满足 MySQL 语法。
