




本文基于ob的特性,在oltp类系统的优化中可能会使用到,提供几个基于功能级的优化建议,本文假设OB集群是以同城双中心,zone1和zone2在一个机房A,zone3在灾备机房B,应用和zone1和zone2在同一个机房。
1、 主副本分布位置
由于zone1和zone2都分布在机房A,避免路由到灾备机房B,可以通过primary_zone设置优先级把租户的主副本都分布在zone1和zone2中。
|
2、 读写分离(弱一致读)
我们先看一下某个OLTP类系统的应用架构图(截取了其中部分)
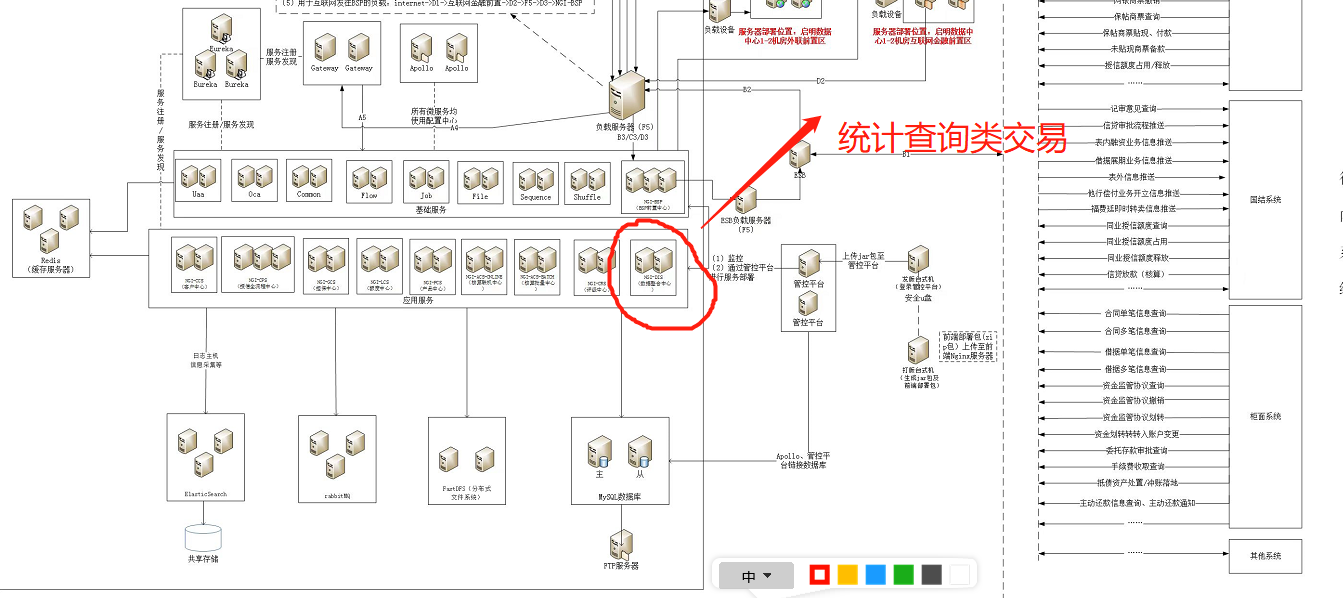
其中红线标注的是一个统计查询类系统,主要实现报表查询和统计分析。对实时性要求不高,如果也查询所有的主副本,那么性能必定会存在影响,因此我们可以考虑基于OB的弱一致性读来实现读写分离,直接从备副本中查询。
实现弱一致性读的方式可以对相关sql语句增加hint,obproxy会自动路由到本地备副本中。实现读写分离的步骤如下:
|
设置每个zone1的IDC属性 ALTER
SYSTEM MODIFY zone "z1" set region = "QINGDAO";--地域 ALTER SYSTEM MODIFY
"z1" set idc = "jifangA";--机房 |
|
设置每个zone2的IDC属性 ALTER
SYSTEM MODIFY zone "z2" set region = "QINGDAO";--地域 ALTER SYSTEM MODIFY "z2" set idc
= "jifangA";--机房 |
|
设置每个zone3的IDC属性 ALTER
SYSTEM MODIFY zone "z3" set region = "QINGDAO";--地域 ALTER SYSTEM MODIFY "z3" set idc
= "jifangB";--机房 |
|
配置proxy的ldc属性 根据obproxy的部署情况,不同的机房启动proxy指定不同的ldc属性,我们以启动机房A的obproxy为例
|
|
Sql启用弱一致性读
|
3、 分组表
随着业务系统需求越来越复杂,表的关联查询不可避免,可以通过分析开发人员的所有sql分析最经常关联的表查询,此事可以考虑使用分区表,使主副本都在同一个observer中。分组表实例如下:
创建表组
|
|
创建表指定表组
|
create table table_A ( cont_no int , a varchar(20),b varchar(30) , primary key ( cont_no ) )tablegroup tpcc_group partition by hash(cont_no) partitions 6; create table table_B ( bill_no int ,cont_no int , a varchar(20),b varchar(30) , primary key ( bill_no ) )tablegroup tpcc_group partition by hash(cont_no) partitions 6; |
4、 复制表
Ob主备副本的同步是多数派同步机制,因此读写分离读取备副本的时候有可能存在延时,即备副本还未同步完成,因此查询出现偏差;大多数应用系统中都存在一些配置表、比如操作员、机构、数据字典等等,此类表修改的几率比较低。因此为了避免读写分离的时候出现不一致的情况,可以把多数派同步修改成强同步,即所有的副本都同步完成以后提交才完成。
开启复制表主要是在创建表的语句增加duplicate_scope='cluster' ;实例如下:
|
create table t1(id bigint not null
auto_increment , c1 varchar(50), c2 timestamp not null default
current_timestamp) duplicate_scope='cluster' ; |
