





在上一篇文章中我们提到了事务的隔离级别是如何来实现的,引出了 undo log 这个日志,接下来我们再来看在一个事务里面具体是怎么判定需要回滚到哪个数据版本为止的。
这里再引出一个事务 id 的概念,实际上数据库在每个事务启动时都会向服务申请一个唯一的事务 id,而且这个事务 id 是顺序递增的,每次事务更新数据的时候会生成一个新的数据版本,并且把当前事务 id 赋值给这个数据版本,记为 trx_id,同时旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它,因此在新的数据版本中除了包含本次数据的值和当前更新的事务 id 外,还有一个引用(指向上一个数据版本),通过 undo log 进行回滚时需要用到。上面的几个事务更新在加上事务 id 之后,更新流程图如下:

从图中可以看到最开始更新之前张三这条数据是由事务 id=100 的事务 X 所更新的,接下来依次被事务一事务二事务三所更新,对应的事务 id 分别是 105,110,115,而在不同时刻启动的事务会创建不同的一致性读视图,这个一致性读视图其实也就是给整个库打了个快照,注意并不是说事务启动的时候将整个库的数据拷贝一份出来,要是这样做的话就太费内存,太费时间了。
它的实现上是将目前还处于活跃事务的事务 id 放到一个数组里面,活跃事务是指事务开启了但还没提交的事务,数组中最小值记为低水位,当前系统中已经创建的事务 id 的最大值 +1 记为高水位,然后依据高低水位来判断数据版本可不可见,注意理解这句话,说明数组中包含的是活跃事务 id,中间已经提交了的事务是不在里面的,也就是说数组中的值不一定是连续的。
有了这个数组之后,就可以利用这个数组来判断数据可不可见了,判断规则如下:
1.数据版本对应的事务 id 比最低水位小,说明是已经提交了的事务,该数据版本可见
2.数据版本对应的事务 id 比最高水位大,说明是在当前事务之后启动的事务,不管提没提交,该数据版本都不可见
3.数据版本对应的事务 id 大于等于最低水位小于等于最高水位,那存在两种情况:
数组中包含该事务 id,说明是还未提交的事务,该数据版本不可见
数组中不包含该事务 id,说明是已经提交的事务,该数据版本可见
接下来我们来模拟几个事务的 SQL 执行场景,然后我们用上面的规则来分析可见性,看看是否和我们之前理解的数据可见性是一致的。下面的场景将会涵盖上面三种情况,SQL 执行的顺序就是按照表格从上到下的顺序,事务隔离级别没有特殊说明都是可重复读:
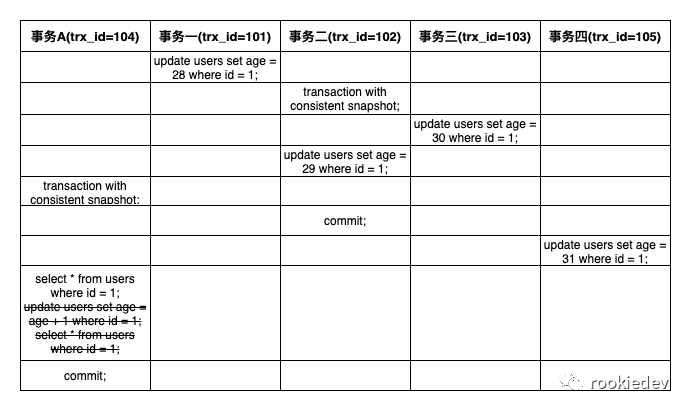
上面表格中没有显式开启事务的都是自动提交,表头描述了每个事务的名称以及对应的事务 id,表格内容从上到下可以看到首先是事务一将 id = 1 的 age 字段更新成 28 并且自动提交,接下来启动事务二但没提交,紧接着事务三将 id = 1 的 age 字段更新成 30 并且自动提交,然后事务二再将 id = 1 的 age 字段更新成 29 依然没提交。
再接着事务 A 启动,随后对事务二进行提交,然后事务四将 id = 1 的 age 字段更新成 31 并且自动提交,这时再回到事务 A 查询 id = 1 的那条数据,这时看到的 id = 1 的那条数据的 age 等于多少呢?
上面描述了这个场景执行的整个过程,我们用上面的规则来进行分析,其实主要就是分析事务 A 中的查询语句看到的 age 字段是多少。
首先事务 A 启动时将当前库活跃事务的事务 id 放到一个数组里面,我们假设数据库目前只有这几个事务在操作数据库,那么事务 A 启动时处于活跃的事务就只有事务二是还没提交的,同时事务 A 启动时系统中已经创建的事务 id 的最大值是 103,高水位就是 104,那么事务 A 启动时对应的数组就是 [102, 104],低水位就是 102。
在事务 A 中查询 id = 1 的那条记录时,该记录目前最新版本 age 的最新值是 31,对应的事务 id 是 105,105 比高水位大,对应上面规则中的第二种情况,那么该数据版本不可见,然后根据 undo log 回滚到前一个版本。
前一个版本是事务二进行更新的,事务二的事务 id 是 102,等于最低水位并且数组中包含该事务 id,对应着上面规则中的第三种情况里面的第一种,数据版本依然不可见,继续根据 undo log 回滚到前一个版本。
前一个版本是事务三进行更新的,事务三的事务 id 是 103,大于最低水位小于最高水位,但数组中没有包含该事务 id,对应着上面规则中的第三种情况里面的第二种,数据版本可见,所以在事务 A 中看到的数据 age = 30。
而其实如果还需要再回滚的话,那就回滚到了事务一更新的版本,事务一的事务 id 是 101,比最低水位小,对应着上面规则中的第一种情况,该数据版本也是可见的。上面的场景实际执行结果也是一样的,实际操作如下所示:
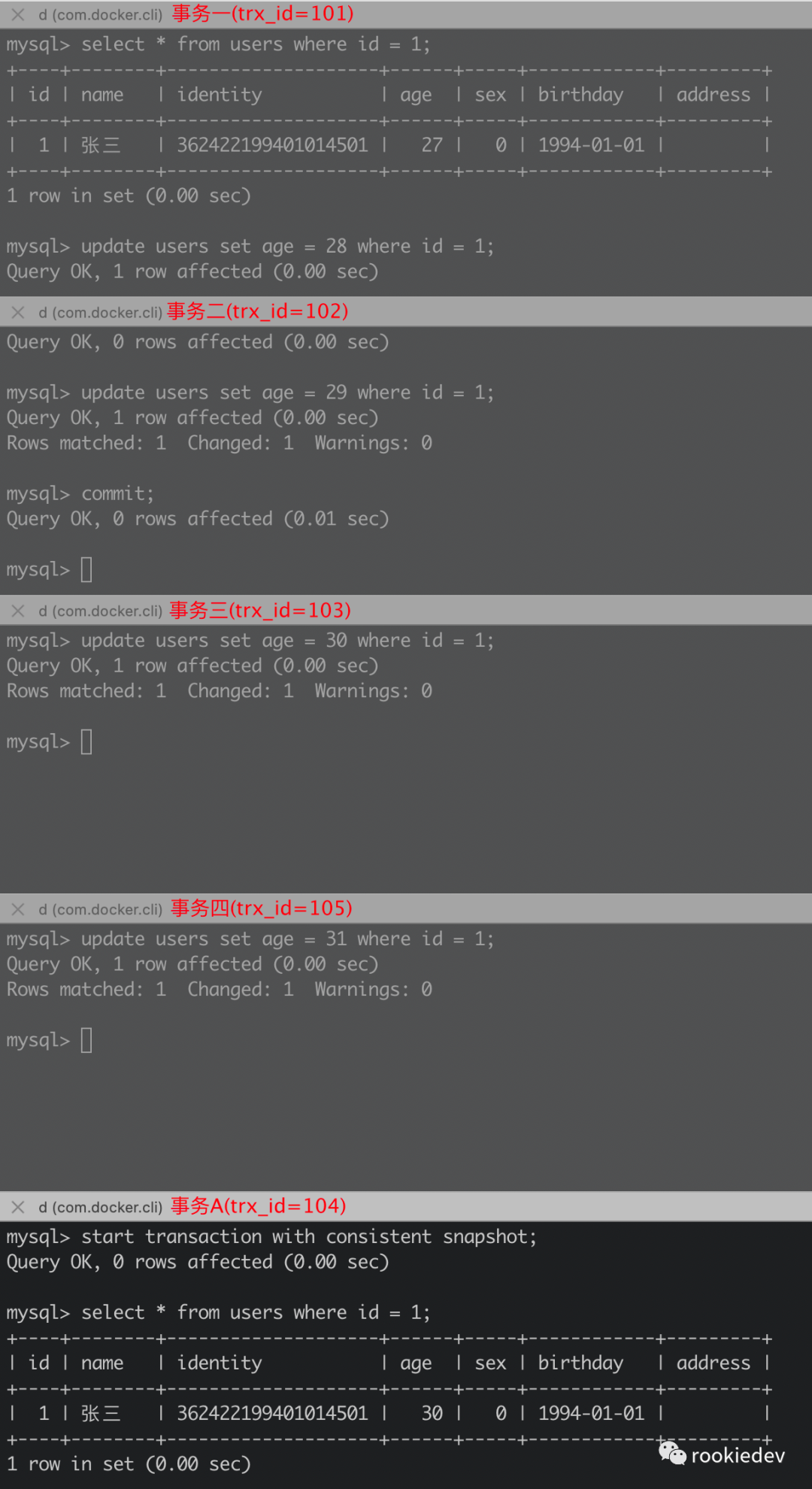
上面开了五个终端,每个终端里面都和 MySQL 建立连接,各个连接中的 SQL 执行顺序对应着表格中从上到下的顺序,可以看到最后查询出来的值也是我们上面按照高低水位的判断规则分析出来的结果 age = 30。
上面其实更多的是从底层实现层面来分析得到这个结果,如果说每次事务间的数据可见性都按照这个去分析就有点太麻烦了,其实总结下来也就下面两点,以事务启动的那一刻为准:
1.该事物开启时,对于还没提交的事务更新都是不可见的
2.该事务开启时,对于已经提交的事务更新都是可见的
再回到上面表格中模拟的场景,事务 A 开启时,事务一和事务三是已经提交了的,并且事务三在事务一之后提交,事务二还没提交,事务四在事务 A 开启时还没创建,那么在事务 A 中的查询,看到的就是事务三的更新 age = 30,这样去分析是不是就简单多了。
从上面的分析也可以看到,事务开启后,不管在什么时候查询,前后看到的数据都是一致的,因为数据版本的可见性只取决于事务启动的那一刻,这个就称作一致性读。
可能你注意到了在上面表格中事务 A 里面的查询语句后面有两个划线了的 SQL 语句,一个是更新,一个是查询,假如我们把这两个 SQL 语句放开执行,那么后面的这个查询语句查询到的数据是多少?
如果按照上面一致性读的说法,执行更新语句时看到的张三的年龄应该是 30,age = 30 + 1,那紧接着的查询语句查询出来的张三的年龄应该就是 31。如果是这样的话看起来好像不太对,因为这样的话事务四的更新就丢失了,因为在事务 A 中进行更新前,事务四已经将张三的年龄更新成 31 了。
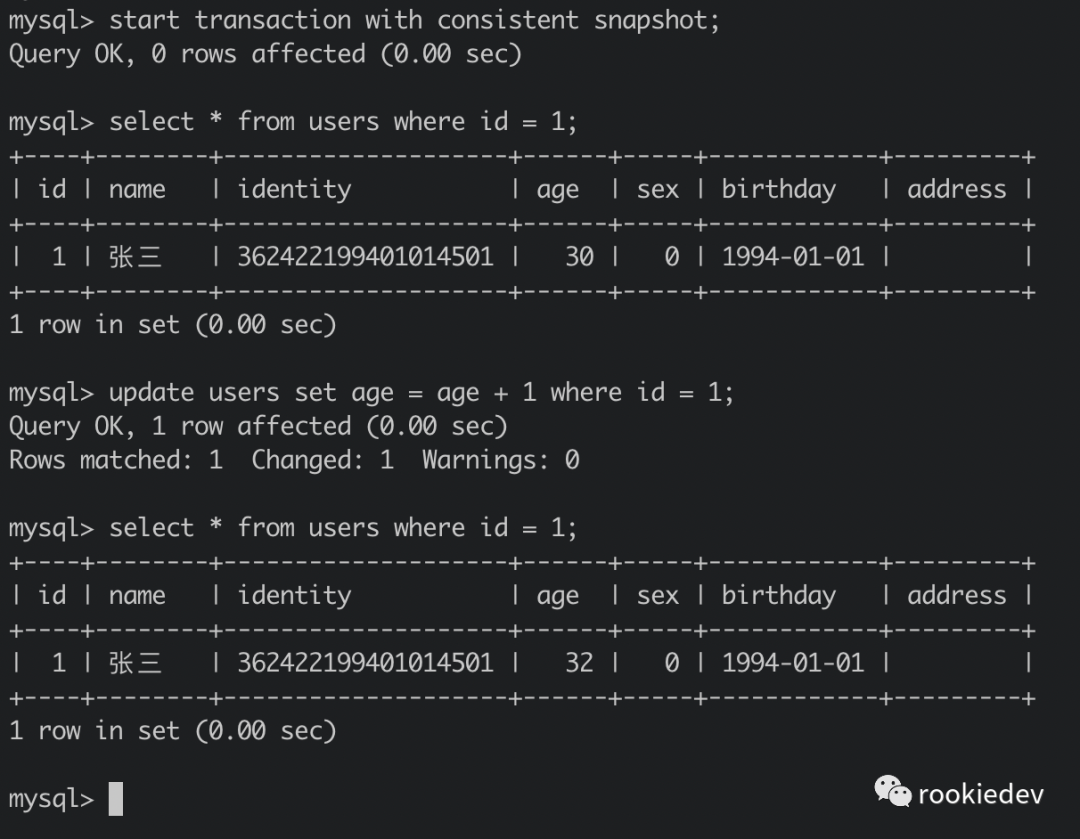
事实上,我们真正去执行的时候,事务 A 中查询得到的值是 age = 32,也就是事务 A 里面是认事务四的那个更新的,当然也必须得认,不然就都乱套了,但这样就又和我们上面的一致性读说法好像不一致了,这里就需要引出另一个概念,对于查询是按照一致性读的原则,而对于更新则是按照当前读的原则,也就是说更新都是从最新版本的数据上开始更新的。
所以这里就是直接从事务四对应的版本的数据上进行更新的,age = 31 + 1,紧接着的查询语句一看最新版本的数据是 32,对应的事务 id 是 104,和自己的事务 id 相等,这个版本是自己的更新,那也是要认的,因此查询出来的数据就是 age = 32,下面我单独将事务 A 加上更新语句之后的执行截图贴出来:
其实除了更新语句,对于加读锁或者写锁的查询也是当前读,我们可以简单的模拟一下这种场景,先在一个连接中开启事务,然后在另一个连接中更新一条数据,再回到第一个连接中加读锁或者写锁去查询刚才更新的那条数据。
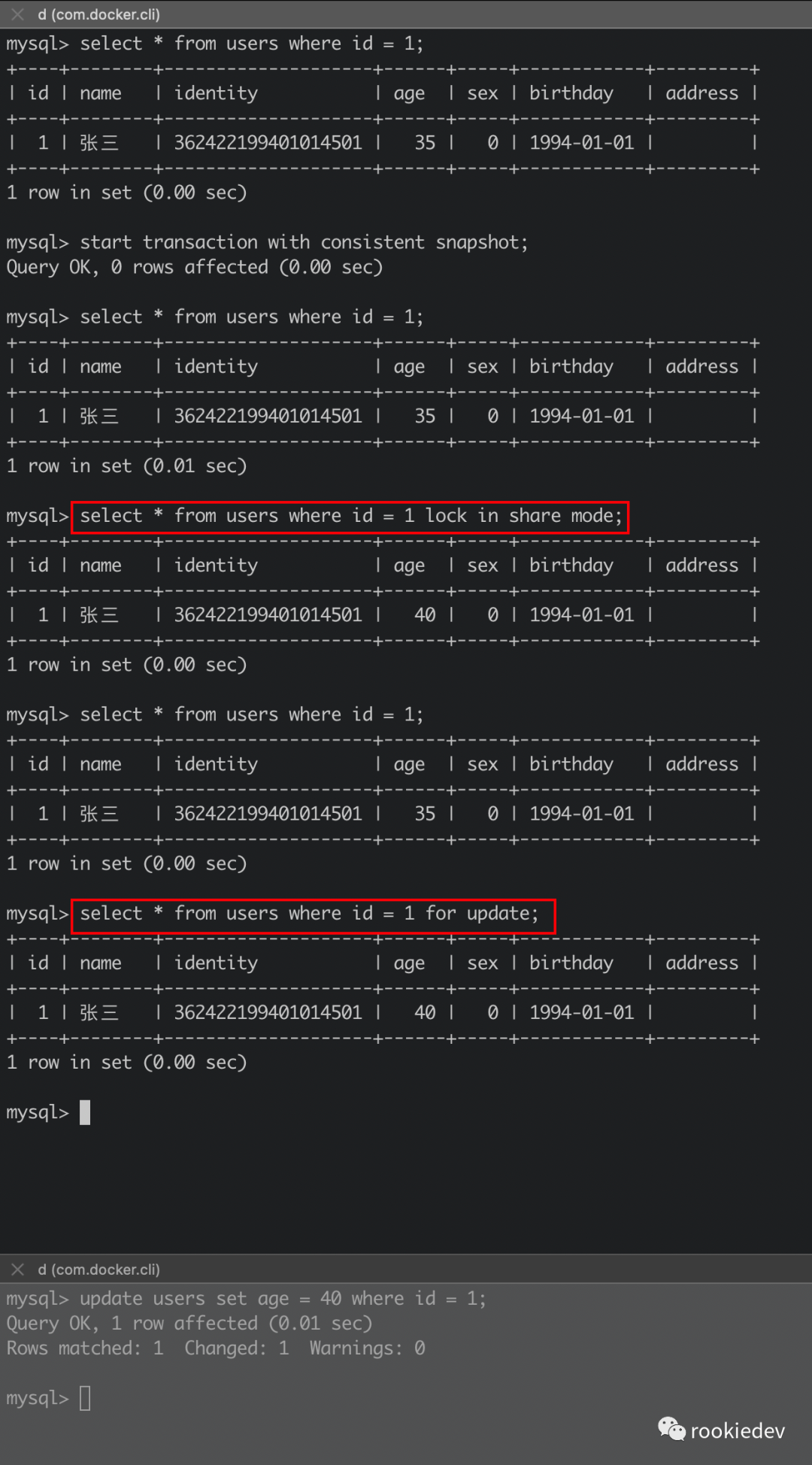
上面截图中就是先在上面的窗口查询当前 id = 1 的那条记录,age = 35,然后开启事务,紧接着在下面的窗口将 id = 1 的记录 age 更新成 40,再回到上面的窗口中去查询,可以看到在加读锁或者写锁的时候都是当前读,查询到的是当前最新版本的数据,其中在查询语句后面加上 lock in share mode,表示加读锁,查询语句后面加上 for update,表示加写锁,读读不冲突,读写和写写是冲突的,这个后面提到锁的时候再具体细说。
上面我们就已经描述了在可重复读的隔离级别下,事务开启时会创建一个一致性读视图,接下来的数据查询都依赖于事务开启时创建的一致性读视图,但如果是读提交的隔离级别呢?不妨先来实际操作下,先将事务的隔离级别修改成读提交:
1set global transaction isolation level read committed;
注意执行完上面的 SQL 之后将连接断开,重新连接之后才会生效,这个操作最好不要在生产库上做测试。
修改好了之后,同样用刚才的方式做测试,在一个连接里面开启事务,另一个连接里面更新,再回到第一个连接里面去查询,结果如下:
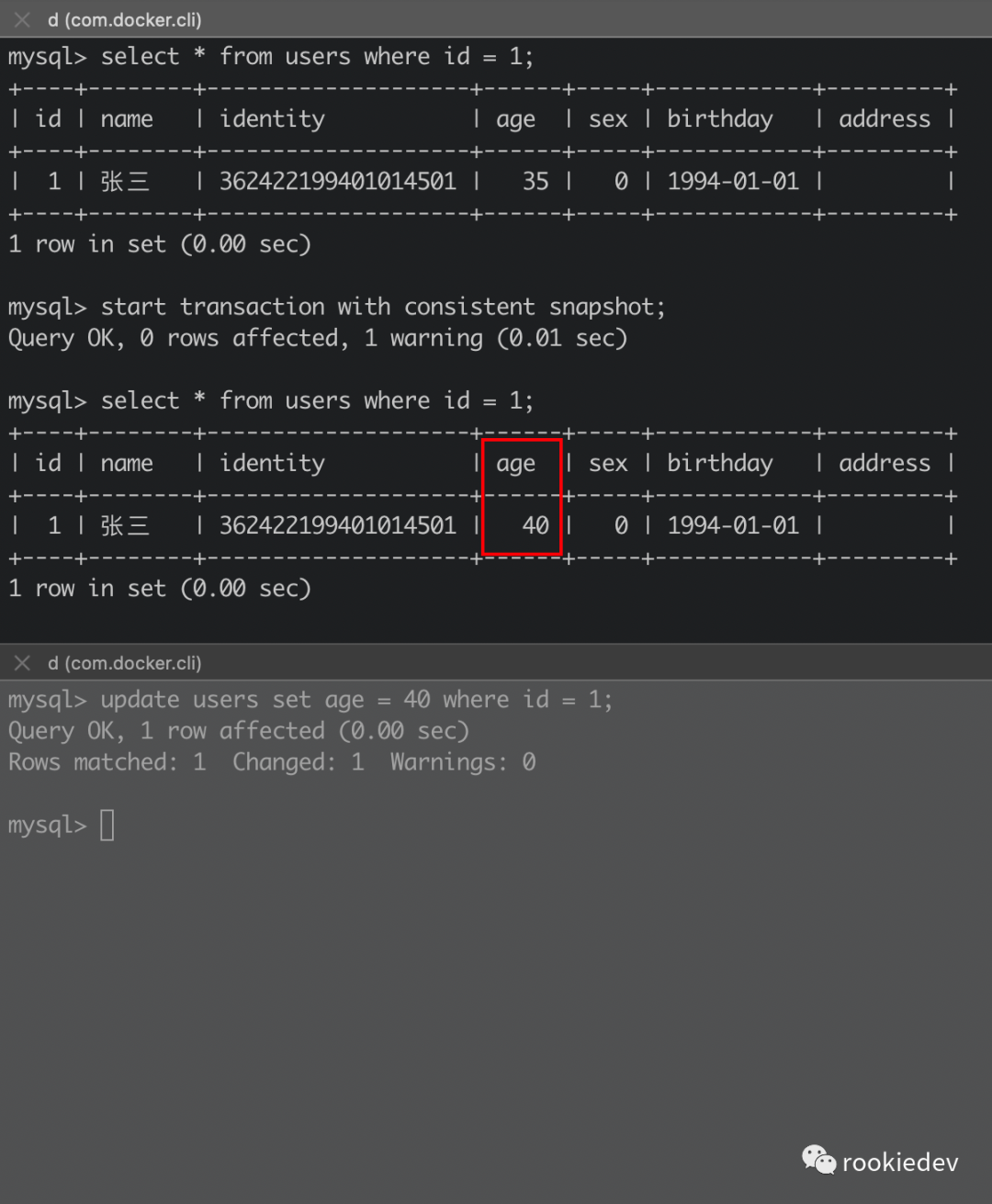
从结果可以看到,第一个窗口中查到的是已经提交的最新版本的值,其实读提交是在每个 SQL 执行前都会重新创建一个一致性读视图,而可重复读则是在事务正式开启时创建,所以读提交的隔离级别下,每次都查询得到已经提交的最新版本的值。而对于读未提交的隔离级别那就是每次直接将当前数据的最新版本返回就可以了,也就没有视图的概念了。
上面我们可能多次提到一致性读视图,这里可能需要进行说明下,它和我们在查询时通过 create view 的方式创建的视图是不一样的,这里的一致性视图是静态的,当前视图对应的数据是由字段上的当前值通过 undo log 回滚计算得到,它是用来辅助实现可重复读和读提交的隔离级别。而通过 create view 的方式创建的视图则是利用查询语句定义的一张虚拟的表,调用的时候执行相应的查询语句来生成查询结果。
还有一点你可能也注意到了,我在上面的实践中开启事务都是用的 start transaciton with consistent snapshot; 语句,和我熟悉的 begin 或者 start transaction 好像有点不一样,这里我们来了解下他们之间的区别:
begin 或者 start transaction: 一致性读的视图不会马上创建,而是在执行 begin 或者 start transaction 后面的第一个 SQL 语句时生成,这个SQL可以是 select,update,delete,insert 其中的任意一种,事务 id 也是此时才被分配,当然这其实也是能理解,这样做可以最大程度的支持事务之间并发。
start transaciton with consistent snapshot: 该语句执行后,会马上创建一个一致性读的视图,同时事务 id 也是立即被分配。
注意: 一致性读视图是基于整库的,在可重复读的隔离级别下,全库快照秒级实现,这正是 InnoDB 利用了“所有数据都有多个版本”的这个特性来实现的。
这两篇文章算是把我所理解的事务相关知识点尽力写出来了,可能看起来有点晦涩难懂,我只能说底层的的东西往往都是不太好理解的,这两篇文章还是花了我挺长时间才写出来的,因为只要一扣细节就更难说清楚了,所以说如果有细节方面的东西觉得不太对的地方,感兴趣的话可以尝试去研究研究,事务相关的东西到这里就先告一段落,接下来的文章我们一起来看下我们开发人员应该会感兴趣的 MySQL 索引。
推荐阅读
