




数据库备份恢复的意义就在于,当受到黑客入侵、硬件故障、软件故障或者误操作等事故的发生后,可以完整、快速、简捷、可靠地恢复原有数据,在一定的时间范围内尽可能保障系统的正常运行。无论是全量恢复还是单表恢复,在我们日常数据库运维工作中,都是常见项。大部分数据库都会有自己的备份恢复机制来保证数据的完整性、准确性,如Oracle数据库的逻辑备份expdp/impdp、在线热备份工具rman、MySQL数据库常见的mysqldump、Xtrabackup等。我们对于工具的选择需要和场景结合来选择。对于分布式数据库OceanBase该如何选择合适的工具来备份恢复呢?后面的章节会为大家介绍几种常见工具。
DataX技术
DataX是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。从源端使用reader插件读取数据,在目标端使用writer插件写入数据,理论上DataX框架可以支持任意数据源类型的数据同步工作。开源地址:https://github.com/alibaba/DataX
其中OceanBase V10 Writer插件实现了写⼊数据到 OB数据库的⽬的表的功能。在底层实现上,OceanbaseV10Writer 通过 java客户端(底层MySQL JDBC或oceanbase client) 连接obproxy远程OB,并执⾏相应的insert语句。
以下为相关优化参数:
"setting": { # 流量控制
"speed": {# 并发任务,若单独配置,没有splitPk,则依旧单通道
"channel": 32,# 按照record限速,-1代表解除对读取行数的限制
"record": -1,# 控制传输速度(byte/s),运行时尽可能达到该速度但是不超过
"byte": -1,# 批量提交,可减少网络交互,提升吞吐量,默认1024
"batchSize": 100000
},
"errorLimit": {# 脏数据控制
"record": 1, # # 对脏数据最大记录数阈值(record值)
}
}
reader插件优化参数:
"splitPk": "XX" # 按照字段数据切分,配合channel实现并发任务,要求仅整形型且不为空一个通用Oracle表到OB-Oracle迁移示例JSON文件:
{
"job": {
"content": [{
"reader": {
"name": "oraclereader",
"parameter": {
"username": "oracleusername",
"password": "oraclepassword",
"column": [
"*"
],
"connection": [{
"table": ["AAAA"],
"jdbcUrl": [
"jdbc:oracle:thin:@//oracleip:oracleport/oracleservicename"
]
}]
}
},
"writer": {
"name": "oceanbasev10writer",
"parameter": {
"obWriteMode": "insert",
"username": "obusername",
"password": "obpassword",
"writerThreadCount": 16,
"batchSize": 10000,
"useObproxy": true,
"column": [
"*"
],
"connection": [{
"jdbcUrl": "||_dsc_ob10_dsc_||obclustername:obtenantname||_dsc_ob10_dsc_||jdbc:oceanbase://obip:obport/obusername?useUnicode=true&characterEncoding=utf-8",
"table": ["AAAA"]
}]
}
}
}],
"setting": {
"errorLimit": {
"record": 0
},
"jvmOption": "-Xms8092m -Xmx8092m",
"speed": {
"channel": 16
}
}
}
}示例:通过进行channel和splitPk来配置,Oracle同步到OB-oracle数据(数据量5100W)效率:
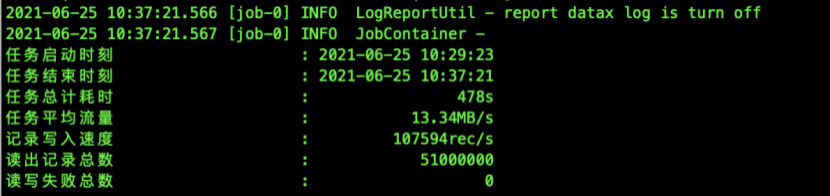
总结:大部分异构数据库都可以通过datax进行传输数据,datax工具通过分片并发的形式可快速处理大量数据,但如果表中没有合适的分片的字段,那么datax只能单通道执行,效果很低。另外splitPk只能和table一起使用,如果通过query_sql来实现增量数据的传输,那么只能通过单通道进行,这里我们可以考虑将增量数据在源端形成临时表,在通过表模式来实现高效率传输。同时使用datax的时候也会有个缺点,每张表需要配置一个json文件,相对麻烦一点,并且因为每一张的分片字段可能不一致,这个时候对于想提高传输效率,我们又得通过手动对每张表修改splitPk。
mysqldump技术
mysqldump是MySQL自带的逻辑备份工具,它的备份原理就是通过协议连接到OceanBase数据库,将需要备份的数据查询出来,将查询出来的数据转换成对应的insert语句。当业务租户是兼容MySQL模式的时候,可以使用mysqldump进行备份数据,若业务租户是兼容Oracle模式的话,无法使用mysqldump进行备份。以下为mysqldump常见相关参数以及说明:
| 参数选项 | 说明 |
|---|---|
| -h | 连接OB数据库的接口,一般多采用Obproxy IP |
| -u | OceanBase连接用户(常见使用:用户名@租户名#集群名) |
| -P | 连接OB数据库的端口,一般多采用obproxy的方式,默认采用obproxy默认端口2883 |
| -p | OceanBase租户密码,若有特殊字段,需使用引号,如-p'Xcode@#$123' |
| --skip-triggers | 在OB3.1及之前版本,MySQL模式不支持触发器,必须使用该参数跳过 |
| --hex-blob | 使用十六进制格式导出二进制字符串字段。如果有二进制数据就必须使用该选项。影响到的字段类型有BINARY、VARBINARY、BLOB。 |
| -R | 选择导出存储过程以及自定义函数 |
| -d | 不导出任何数据,只导出数据库表结构 |
| -f | 导入导出的时候忽略错误并继续 |
以下为MySQL租户下几种场景的示例:
# 仅导出对象结构
$ mysqldump -h10.10.12.10 -uroot@obmysql0_13#obtest -P3306 -pxxx --skip-triggers --hex-blob db01 -R -d > /tmp/db01.sql
# 导出对象结构等对象和数据
$ mysqldump -h10.10.12.10 -uroot@obmysql0_13#obtest -P3306 -pxxx --skip-triggers --hex-blob db01 -R > /tmp/db01.sql
# 导入对象和数据
$ obclient -h10.10.12.10 -P3306 -uroot@obmysql0_13#obtest -pxxx -c -A db01 -f < /tmp/db01.sql# 或者使用登陆数据库后进行source SQL文件obclient> use db01
obclient> source /tmp/db01.sql
以下需要在使用mysqldump的时候需要注意
## 超时问题
当需要导出的数据量较多时,可能会报出TIMEOUT 4012,为避免这个错误需要使用租户管理员账户登录数据库运行下述语句调整系统参数,导出完成后您可以修改回原值
obclient> SET GLOBAL ob_trx_timeout=1000000000;
obclient> SET GLOBAL ob_query_timeout=1000000000;总结:mysqldump是传统mysql上的工具,由于协议开源,OB-MySQL租户也可以通过mysqldump备份数据库,但mysqldump的劣势在于无法并发和增量同步数据,在数据量很大的时候,导入的速度很慢。对于OB的数据备份方案,一般都是不推荐使用mysqldump。
outfile&load data技术
OceanBase目前兼容SELECT INTO OUTFILE语法,能够对需要导出的字段做出限制。作用是将查询结果输出保存到特定文件中,与之相反的命令是LOAD DATA语法。无论mysql租户还是oracle租户都可使用该语法。
| Select into outfile语法 | Load data语法 |
|---|---|
SELECT [column_list] INTO '/PATH/FILE' [TERMINATED BY OPTIONALLY] [ENCLOSED BY OPTIONALLY] [ESCAPED BY OPTIONALLY] [LINES TERMINATED BY OPTIONALLY] [FROM TABLENAME] [WHERE condition] [GROUP BY group_expression_list ] [HAVING condition]] [ORDER BY order_expression_list] | LOAD DATA [/*+ parallel(N)*/] INFILE 'file_name' [REPLACE | IGNORE] ---其中REPLACE仅适用于MySQL租户 INTO TABLE tbl_name [{FIELDS | COLUMNS} [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number {LINES | ROWS}] [(col_name_var [, col_name_var] ...)] |
Select into outfile导出数据
# 通过obproxy连接到OB-MySQL,执行导出
$ obclient -h10.10.12.10 -uroot@obmysql0_13#obtest -P3306 -p'xxx' -c -A test
obclient> select * into outfile '/tmp/sbtest1.csv' FIELDS TERMINATED BY ',' enclosed by '"' LINES TERMINATED BY '\n' from sbtest1;
$ ll /tmp/sbtest1.csv
这个时候,我们去本台机器查看导出的文件,会有可能文件不存在。主要原因当从客户端通过obproxy连接到OB的时候,obproxy会路由到表sbtest1主副本所在的observer上,最后导出的数据文件是在主副本所在的observer,而不是客户端机器上。这个地方对于我们日常使用来说很不友好。Load data导入数据
# 登陆到表sbtest1主副本所在的机器(10.10.12.11),通过obproxy连接到OB-MySQL,执行导入
$ ll /tmp/sbtest1.csv (文件存在)
$ obclient -h10.10.12.11 -uroot@obmysql0_13#obtest -P3306 -p'xxx' -c -A test
obclient> load data infile '/tmp/sbtest1.csv' into table sbtest1 fields terminated by ',' enclosed by '"' lines terminated by '\n';
ERROR 1017 (HY000): File not exist
$ obclient -h10.10.12.11 -uroot@obmysql0_13 -P2881 -p'xxx' -c -A test
obclient> set global secure_file_priv = "";(默认为NULL,代表禁用,会话重新登陆下)
obclient> load data infile '/tmp/sbtest1.csv' into table sbtest1 fields terminated by ',' enclosed by '"' lines terminated by '\n';
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 0
这里说明一个问题,OB目前对于使用LOAD DATA导入数据,只能在表主副本所在的机器,除非是采用一个NFS 磁盘,observer都能访问该磁盘,这样就不需要关注主副本对应在哪一台机器上,就可以从任一客户端机器进行使用该语法导入。总结:outfile和load data都是只能对数据进行处理的,而且语法支持都很简单,虽然导出导入的速度还不错,但对我们使用者来说,还要去知道表的主副本所在的位置,还需要直连observer,整体来说,使用繁琐不方便,不推荐使用。
obdumper&obloader技术
obdumper&obloader是使用Java开发的导出导入工具,可以把存储在OceanBase中的数据按照SQL或CSV格式导出到文件中。同时也可以利用该工具把结构定义导出到文件中。需要安装OpenJDK1.8+并且配置JAVA_HOME。字符编码推荐使用utf-8。另外在使用obdumper/obloader的时候需要关注启动脚本中的 JVM 参数,特别是内存相关的参数,如:-Xms4G -Xmx4G (默认) ,-Xss328K。具体的优化性参数可参考工具文档。常见参数说明如下:
| 参数选项 | 参数说明 |
|---|---|
| -h | 连接obproxy的IP |
| -P | 连接obproxy的端口 |
| -t | 业务租户名称 |
| -c | ob数据库集群名称 |
| -u | 数据库用户名 |
| -p | 数据库用户密码 |
| -D | 数据库名/schema名 |
| --ddl | 对象导出成DDL文件 |
| --sql | 数据导成sql文件 |
| --csv | 数据导成csv文件 |
| --all | 导出数据库所有对象 |
| --sys-user | 系统租户 |
| --sys-password | 系统业务的密码 |
| --thread | 导出线程的并发数,可以根据具体的情况进行调整。 |
| --public-cloud | 简易模式,不需要依耐--sys-user/--sys-password,性能和功能都差点 |
| --page-size | 指定分页查询的记录数,可以根据实际的情况调整大小。 |
obdumper导出示例:
# 导出所有对象DDL文件(针对mysql租户导出的对象只能包含表和视图)
$ ./obdumper -h10.10.12.10 -u root -t obmysql0_13 -c obtest -P3306 -p xxx -D db0601 --ddl --all --sys-password 'xx' --thread 1 --skip-check-dir -f /tmp/db0601
# 导出数据成CSV文件
$ ./obdumper -h10.10.12.10 -u root -t obmysql0_13 -c obtest -P3306 -p xxx -D db0601 --csv --all --sys-password 'xx' --thread 16 --skip-check-dir --skip-header -f /tmp/db0601obloader导入示例:
# 导入表结构
$ ./obloader -h 10.10.12.10 -u root -t obmysql0_13 -c obtest -P3306 -p xxx -D db0601 --ddl --sys-password 'xx' --all -f /tmp/db0601
# 导入数据
$ ./obdumper -h10.10.12.10 -u root -t obmysql0_13 -c obtest -P3306 -p xxx -D db0601 --csv --all --sys-password 'xx' --skip-header -f /tmp/db0601
# 使用obloader将上述通过outfile导出的文件导入租户
$ ./obloader -h 10.10.12.10 -u root -t obmysql0_13 -c obtest -P 2883 -p 'xxx' -D testdb --external-data --cut --table sbtest1 --column-separator ',' --column-splitter '"' --file-suffix ".csv" -f /tmp/sbtest1.csv
--external-data代表非obdumper导出的数据,导入的时候不需要检查元数据信息
--cut代表着数据使用字符串作为分隔,非标准CSV文件导入的时候建议使用
--column-separator指定列分隔符,默认值 ','(英文逗号)
--column-splitter定义列分隔串,数据按照指定的字符串进行分隔
--line-separator指定行分隔符,默认值 '\n'
-file-suffix指定数据文件的后缀名
通过obloader相关参数,我们开发人员可以在任意客户端机器,都可以将自定义的CSV文件进行导入到OB租户中去,当然需要我们的CSV文件必须规范化,否则可能会报错。 OB的导数工具(obdumper&obloader)更像Oracle数据库的exp/imp工具,支持从客户端将数据、对象等进行导出与导入。对于Oracle数据库上还有数据泵(expdp/impdp),这款工具比exp/imp的效率都是要好点。从官方得知,对于OB来说,暂时没有打算开发这类工具,主要还是聚焦于当前导数工具的优化。会结合客户需求与实际场景进行版本快速迭代优化,如空表导入导出优化、并行任务生成、排除表导出等,目前来看,OB的逻辑备份与恢复的最佳工具只能是obdumper&obloader,
OB物理备份恢复
OceanBase数据库从V2.2.52版本开始支持集群级别的物理备份。物理备份由基线数据、日志归档数据两种数据组成,因此物理备份由日志归档和数据备份两个功能组合而成。OceanBase数据库支持租户级别的恢复,恢复是基于已有数据的备份重建新租户的过程。用户只需要一个alter system restore tenant命令,就可以完成整个恢复过程。目前备份时用到的存储介质只能为OSS、NFS、COS。具体的备份恢复的架构可参考对应文档,整体的备份恢复流程见如下:
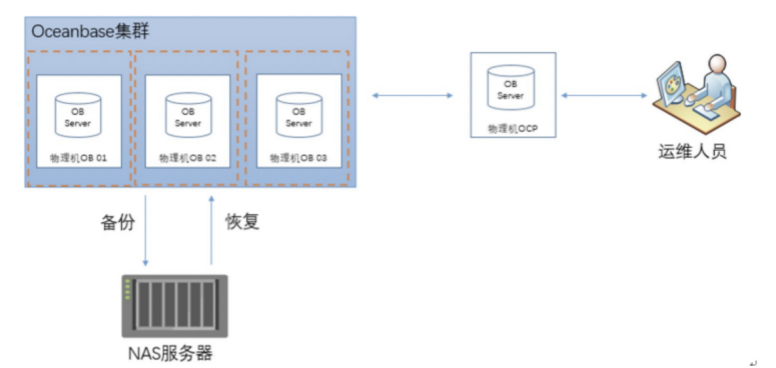
手动物理备份:
# 使用系统租户sys登陆,设置备份目的地
obclient > show parameters like 'backup_dest';
# 观察value列,默认为空
obclient> alter system set backup_dest='file:///data/backup/obbackup';
如果是OSS,可参考如下
obclient> alter system set backup_dest='oss://xxx/?host=oss-cn-hz-xxx.com&access_id=xxxx&access_key=xxxx';
#【可选】开启归档日志压缩功能,默认压缩算法为lz4_1.0
obclient> ALTER SYSTEM SET backup_log_archive_option='compression=enable';
# 关闭日志压缩
obclient> ALTER SYSTEM SET backup_log_archive_option='compression=disable';
#【可选】配置备份模式,默认是OPTIONAL,,建议选optional
obclient> alter system set backup_log_archive_option = 'optional';
obclient> alter system set backup_log_archive_option = 'mandatory';
optional模式表示以用户业务优先。在该模式下,当备份(日志归档)来不及的情况下,日志可能来不及备份就回收了,可能会发生备份断流。
mandatory模式表示以备份优先。在该模式下如果备份跟不上用户数据的写入,可能会导致用户无法写入。
# 启动事务日志归档,启动成功后,OceanBase数据库会自动将集群产生的事务日志定期备份到之前指定的备份目的地。
obclient> alter system archivelog;
# 确认日志备份已开始,status列为DOING
obclient> select * from oceanbase.cdb_ob_backup_archivelog_summary;
# 执行集群合并,等待合并结束
obclient> alter system major freeze;
# 等待info列为IDLE
obclient> select * from oceanbase.__all_zone where name='merge_status';
# 对集群进行全量备份
obclient> alter system backup database;
# 查看正在备份的任务和历史任务,确认全量备份都完成。
obclient> select * from oceanbase.cdb_ob_backup_progress;
obclient> select * from oceanbase.cdb_ob_backup_set_details;
集群执行一次全备份完成,备份类型BACKUP_TYPE为D-全备份。查看START_TIME和COMPLETION_TIME两列的值,可以看到备份所花费的时间,后面恢复可以根COMPLETION_TIME完成时间进行时间点恢复。
对租户oboracle0_20操作一张表,模拟增量数据
obclient> alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
obclient> select sysdate from dual;
obclient> create table t0117_1 (id number(10));
obclient> insert into t0117_1 values (1);commit;
obclient> select sysdate from dual; //2022-01-17 16:56:20
# 开启增量备份
obclient> alter system backup incremental database;
# 查看正在备份的任务和历史任务,确认全量备份都完成。
obclient> select * from cdb_ob_backup_progress;手动恢复:
步骤一:关闭日志备份,由于当前版本暂不支持日志备份在集群上发起恢复,如果发起恢复,则会导致日志备份断流,故建议在执行恢复前先停止日志备份。
obclient> alter system noarchivelog;
步骤二:创建资源单元和资源池
# 创建资源单元
obclient>CREATE RESOURCE unit restore_unit max_cpu 1, max_memory 6147483648, max_iops 5000, max_disk_size 53687091200, max_session_num 1500, MIN_CPU=1, MIN_MEMORY=6147483648, MIN_IOPS=5000;
# 创建资源池
obclient> create resource pool restore_pool unit = 'restore_unit', unit_num = 1,zone_list = ('am44_1','am44_2','am44_3');
# 打开恢复设置
obclient> show parameters like 'restore_concur%';
obclient> alter system set restore_concurrency=50;
步骤三:执行恢复任务
将租户oboracle0_20恢复至oboracle1,时间点为增量备份完成点:2022-01-17 17:07:49.512945,参数’timestamp’, 是恢复的时间戳:
要大于等于最早的基线备份的 start_time
obclient> select start_time from cdb_ob_backup_set_details order by start_time asc;
要小于等于事务日志备份的
obclient> select max_next_time from cdb_ob_backup_archivelog_summary order by max_next_time desc ;
obclient> alter system restore oboracle1 from oboracle0_20 at 'oss://xxx/?host=oss-cn-hz-xxx.com&access_id=xxxx&access_key=xxxx' until '2022-01-17 17:06:49.512945' with 'backup_cluster_name=obtest&backup_cluster_id=3100001&pool_list=restore_pool';
查询恢复
# 恢复完成的话,查询为空
obclient> select svr_ip,role, is_restore, count(*) from __all_virtual_meta_table as a, (select value from __all_restore_info where name='tenant_id') as b where a.tenant_id=b.value group by role, is_restore, svr_ip order by svr_ip, is_restore;
obclient> SELECT * FROM oceanbase.__all_restore_info;
obclient> select * from oceanbase.__all_restore_history\G
步骤四:在OCP上查看租户,与确认数据。总结:建议日常通过OCP进行备份与恢复,集群的物理备份是所有租户中的所有对象和数据的备份,其中包含来系统租户等,每一次的备份耗时久,“工程量”大。而且恢复的时候只能以租户最小粒度来恢复,还需要集群有一定的资源来新建租户。这样的方式适合于一旦集群发生不可修复故障,我们可以通过物理恢复的方式来恢复集群。
总结
| 工具种类 | 优点 | 缺点 |
|---|---|---|
| datax | 适合异构数据库数据迁移 支持表分片与并发 文件不落地迁移 | 每张表一个jso文件,配置繁琐 只能处理表数据,不支持对象处理 |
| mysqldump | 支持库、表级别备份恢复 操作简单 备份速度一般 | 不支持并发、断点 大数据量下导入速度很慢 只支持mysql租户下对象数据处理 |
| outfile&load data | SQL语法级别操作备份 支持指定hint来提升效率 | 与主副本所在observer有关,操作繁琐 |
| obdumper&obloader | 支持oracle/mysql租户下对象和数据处理 效率高 | 目前mysql租户只支持表与视图的处理,不支持存储过程等备份恢复,导入的时候无法自动处理外键表顺序问题 |
通常我们根据自己的需求来选择合适的工具,每一个工具都有着自己的优势,例如datax可以异构数据库间数据不落地形式迁移数据,而obdumper&obloader不仅仅可以处理数据还可以对数据库对象进行导出导入,不管是单表还是单库甚至部分数据导出都可以,并发速度也还不错。前面几种技术都是逻辑性的备份,遇到故障时候,无法恢复到数据库遇到故障的前几分钟(取决于备份策略),而OB的物理备份恢复就可以解决这个问题,通过全量、增量备份与日志备份来尽可能保证能数据恢复到故障前。综合考虑,推荐大家使用ob官方导数工具和物理备份恢复两种方案最大程度上保证数据少丢失。
