大概是2002年左右的时候,oracle.com.cn和itpub上面曾经展开过一场关于LOG BUFFER的大辩论。最主要的焦点在于LOG BUFFER应该设置多大才合适。大家都知道,LOG BUFFER的目的是为了提高REDO LOG文件写入的速度,前台进程产生的REDO首先会被写入LOG BUFFER中,然后,LGWR会将LOG BUFFER中的数据写入REDO LOG文件。当时大家对ORACLE REDO写入机制的研究还是刚刚起步,所以对Oracle的LOG BUFFER算法还一知半解。大家理解的REDO LOG写入机制就是为了让LGWR尽快将LOG BUFFER中的数据写入REDO LOG文件,以便于腾出更多的空闲空间,Oracle数据库设计了LGWR写的触发条件:如果每秒的事务数量较大,比如几十个或者几百个,甚至每秒数千个。在这种系统中,LGWR由于事务提交而被激发的频率很高,LOG BUFFER的信息会被很快的写入REDO LOG文件中。而对于某些系统来说,平均每个事务的大小很大,平均每个事务生成的REDO LOG数据量也很大,比如1M甚至更高,平均每秒钟的事务数很少,比如1-2个甚至小于一个,那么这种系统中LGWR由于事务提交而被激发的频率很低,可能导致REDO LOG信息在LOG BUFFER中被大量积压,oracle设计的LOG BUFFER中数据超过1M的LGWR激发条件就是为了解决这种情况而设计的,当LOG BUFFER中的积压数据很多时,虽然没有事务提交,也会触发LGWR将BUFFER中的数据写入REDO LOG文件。除此之外,Oracle还通过了_LOG_IO_SIZE这个隐含参数来进一步控制LGWR写操作,当LOG BUFFER中的数据超过了这个隐含参数的规定的大小,也会触发LGWR被激发。这个参数的缺省值是LOG BUFFER大小的1/3,这个参数单位是REDO LOG BLOCK。这个参数可以控制当LOG BUFFER中有多少个数据块被占用时,就要触发LGWR写操作,从而避免LOG BUFFER被用尽。如果一个系统很空闲,很长时间都没有事务提交,LOG BUFFER的使用也很少,就可能会导致LOG BUFFER中的数据长期没有被写入REDO LOG文件,带来丢失数据的风险,因此Oracle还设计了一个LGWR写的激发条件,设置了一个时间触发器,每隔3秒钟,这个触发器都会被激活,这个触发器被激活的时候,如果发现LOG BUFFER不是空的,并且LGWR不处于活跃状态,就会产生一个事件,激活LGWR。当然这是早期Oracle 8i/9i时候的lgwr触发条件,现在的lgwr算法已经做了巨大的改变,触发条件也更为复杂了。不过当年根据上面的一些算法,网上形成了两大派,一派是LOG BUFFER不宜超过3M,如果设置过大,会导致redo log写的性能问题。理由是,REDO LOG量超过_LOG_IO_SIZE或者超过1M都会触发LGWR写入日志,当LOG BUFFER超过3M,实际上是没有意义的。持有这种观点的人是没有搞清楚LOG BUFFER是一个环状BUFFER,写入者从尾部追加,LGWR从头部读取数据。现在绝大多数DBAY已经不再纠结3M这个限制了。而且从Oracle 10.2.0.4开始,会对LOG BUFFER作自动调节,当一个GRANULE里有剩余空间的时候,会自动添加到LOG BUFFER中,所以从10.2.0.4开始,你看到的LOG BUFFER的实际数量往往会比你设置的LOG_BUFFER参数要大一些。比如我们设置了200M的LOG_BUFFER,实际上可能会看到230M多点的LOG BUFFER。那么我们的LOG BUFFER设置为多大合适呢?实际上这取决于你每秒产生的REDO量。Oracle官方认为,LOG BUFFER能够确保存放600秒的REDO量是十分靠谱的,在有可能的情况下,尽可能按这个去设置LOG BUFFER。而实际上,在一些REDO 量很大的系统中,很难设置如此之大的LOG BUFFER,而且这个600秒也不是一个十分科学的计算值。如果要分析你的LOG BUFFER是否足够,实际上可以看几个系统统计值。这些值在AWR报告里很容易看到: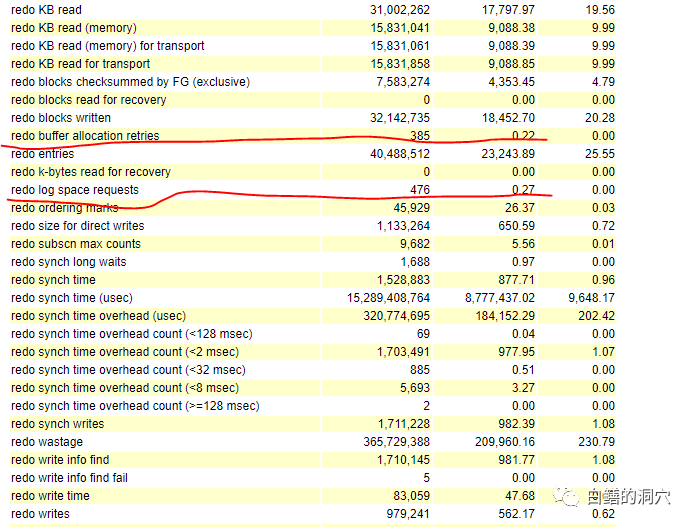
如果redo log space requests和redo buffer allocation retries指标不为零,那么说明LOG BUFFER还是存在不足的情况的。从Oracle 10.2开始log buffer支持自动设置,其设置为512K或者128K*CPU_COUNT中的最大值。11g和12c的算法有所改变。如果("log_buffer"没有设置,则 log_buffer = max(2M, 128K * cpu_count) * max(2, cpu_count/16),缺省的最小LOG BUFFER是4M。否则 log_buffer = max(user-specified value, 2M)。
同时granule中的剩余空间自动分配给LOG BUFFER这个规则仍然起作用,所以实际上你的LOG BUFFER可能比设置值更大。
另外一个可以判断LOG BUFFER不足的因素是Log file sync的平均延时。如果log file sync很高,比如9毫秒,而Log file parallel write的平均延时只有2毫秒,那么很可能也存在LOG BUFFER设置不足的问题。
和LOG FILE SYNC延时较高的因素除了LOG BUFFER大小,LOG FILE PARALLEL WRITE延时之外,还有一个因素是Adaptive Log File Sync。传统的LGWR和日志消费者之间的消息同步机制是Post/wait机制。当前台进程提交后,生成一个COMMIT的REDO RECORD,放入BUFFER,然后等待LGWR POST消息给他。LGWR完成一个写作业后,会给所有等待LOG FILE SYNC的进程发送消息,从而告诉他们你所等待的日志同步已经完成。这种情况前台进程可以最快的获得到相关消息,从而结束LOG FILE SYNC等待。不过这种算法有个弊端,就是LGWR的工作量很大,如果REDO 写入量很大,并发等待LOG FILE SYNC的进程数量很多,那么lgwr会因为忙于POST消息而影响REDO写入的工作。这种情况下,如果有问题,我们会看到LGWR的CPU占用率很高。从Oracle 11.2开始,Oracle引入了一个新的机制,POLLING机制。LGWR不再给每个等待LOG FILE SYNC的进程POST消息,而是只是将日志写入的进度公告到公告板上,等待LOG FILE SYNC的进程自动休眠后主动POLLING相关消息,从而确定是否结束等待。这种做法给LGWR减轻了负担,在REDO量很大,并发等待LOG FILE SYNC的进程很多的情况下,可以有效的提高效率。Oracle会根据工作负载自动的调整这两种机制,从而确保在不同的工作负载下都能够最快的结束LOG FILE SYNC等待。不过在某些情况下,这种自动调整可能会出现问题,导致Log file sync等待反而更严重了。这种情况下,使用"_use_adaptive_log_file_sync"关闭这个动态调整功能就可以解决这个问题。不过关闭ADAPTIVE LOG FILE SYNC是一个双刃剑,在并发的事务数较多,而且REDO 量较大的时候,LGWR的总体性能会受到较大影响。因此也不一定要一味的关闭这个功能。如果你的负载变化十分无规律,而且LOG FILE SYNC机制总是在POLLING和POST之间做频繁的调整(从lgwr的日志中可以看到这个现象),从而引起了LOG FILE SYNC等待过长的问题,那么关闭这个功能是十分必要的,如果没有出现这种情况,还是不关闭的好,这样就可以避免突发性的REDO 量很高,并且并发提交的量很大的时候出现系统卡顿。总之是需要具体问题具体分析的。





