




本次阅读时长:

.

.


作者:劳伦兹·阿尔伯
Laurenz Albe是CYBERTEC的高级顾问和支持工程师。
自2006年以来,他一直在PostgreSQL上工作并为PostgreSQL做贡献。

HOT更新不是一项新功能。它们由2007年的commit 282d2a03dd引入,并首次出现在PostgreSQL 8.3中。
但是,由于HOT不在PostgreSQL文档中(尽管源树中有README.HOT),因此它并未得到应有的广泛了解。因此,本文将对这一概念进行说明,展示HOT的实际作用并给出调整建议。
什么是HOT?
HOT是“Heap Only Tuple”(仅元组堆)的缩写(与Overflow Update CHaining相比,它的缩写更好)。此功能克服了PostgreSQL处理UPDATE 效率低下的问题。
PostgreSQL实现UPDATE的问题
PostgreSQL通过将表行的旧版本保留在表中来实现多版本化– UPDATE会添加该行的新行版本(“tuple”)并将旧版本标记为无效。
在很多方面,PostgreSQL中的更新与删除后插入没什么区别。
这有很多优点:
不需要额外的存储区域来保存旧的行版本
ROLLBACK 回滚不需要撤销任何东西,而且非常快
修改多行的事务没有溢出问题
但这也有一些缺点:
最终必须从表中删除旧的,过时的(“死”)元组(VACUUM)
大量更新的表可能会因死元组而变得“膨胀”
即使没有修改索引属性,每次更新都需要添加新的索引条目,并且修改索引比修改表开销上大得多(必须维护顺序)
从本质上说,更新量大的工作负载对PostgreSQL来说是一个挑战。这就是HOT更新的帮助所在。
一个UPDATE例子
让我们创建一个包含235行的简单表:
CREATE TABLE mytable (id integer PRIMARY KEY,val integer NOT NULL) WITH (autovacuum_enabled = off);INSERT INTO mytableSELECT *, 0FROM generate_series(1, 235) AS n;
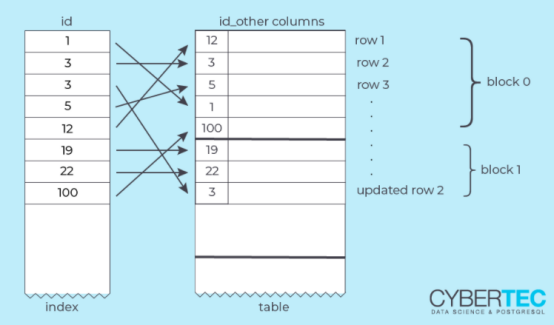
该表的长度略大于一个8KB的块。让我们看看每个表行的物理地址(“当前元组ID”或ctid):
SELECT ctid, id, valFROM mytable;ctid | id | val---------+-----+-----(0,1) | 1 | 0(0,2) | 2 | 0(0,3) | 3 | 0(0,4) | 4 | 0(0,5) | 5 | 0...(0,224) | 224 | 0(0,225) | 225 | 0(0,226) | 226 | 0(1,1) | 227 | 0(1,2) | 228 | 0(1,3) | 229 | 0(1,4) | 230 | 0(1,5) | 231 | 0(1,6) | 232 | 0(1,7) | 233 | 0(1,8) | 234 | 0(1,9) | 235 | 0(235 rows)
ctid由两部分组成:从0开始的“块号”和从1开始的“行指针”(块中的元组号)。
因此,前226行填充块0,最后9行在块1中。
让我们运行一个UPDATE:
UPDATE mytableSET val = -1WHERE id = 42;SELECT ctid, id, valFROM mytableWHERE id = 42;ctid | id | val--------+----+-----(1,10) | 42 | -1(1 row)
新的行版本已添加到块1,该块仍具有可用空间。
HOT更新如何工作
为了了解HOT,让我们概括一下PostgreSQL中表页面的布局:
“行指针”数组存储在页面的开头,每个指针都指向一个实际的元组。这种间接引用允许PostgreSQL在内部重新组织页面,而不改变页面的外观。
仅元组堆(Heap Only Tuple)是未从表块外部引用的元组。而是在旧行版本中存储“转发地址”(其行指针号):
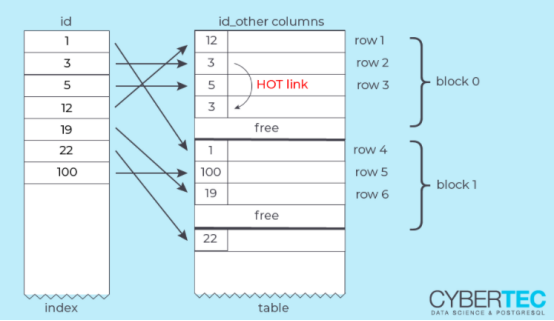
仅当该行的新版本和旧版本位于同一块中时,此方法才有效。该行的外部地址(原始行指针)保持不变。要访问仅元组堆,PostgreSQL必须遵循块中的“ HOT链”。
HOT更新的优点
HOT更新有两个主要优点:
PostgreSQL不必修改索引。由于元组的外部地址保持不变,因此仍可以使用原始索引条目。索引扫描遵循HOT链以找到适当的元组。
无需删除死元组即可执行VACUUM。如果一行上有多个HOT更新,则HOT链会很长。现在,任何后端进程处理的块,当检测到带有无效元组的HOT链,都将尝试锁定并重新组织该块,从而删除中间元组。这是可能的,因为没有外部引用这些元组,这大大减少了UPDATE繁重工作负载时对VACUUM的需求。
HOT更新要求
使用HOT更新有两个条件:
包含更新行的块中必须有足够的空间
在已修改值的任何列上均未定义索引
第二个条件并不明显,并且是该功能的当前实现所必需的。
在表上使用fillfactor以获取HOT更新
您可以确保满足上面的第二个条件,但是如何确保表块中有足够的可用空间呢?
为此,我们有存储参数fillfactor。它是介于10到100之间的值,它确定INSERT将填充表块的百分比。如果选择的值小于默认值100,则可以确保每个表块中都有足够的空间用于HOT更新。
fillfactor的最佳值取决于平均行的大小(较大的行需要较低的值)和工作负载。
请注意,fillfactor在现有表格上进行设置不会重新排列数据,它仅适用于将来的 INSERT。但是您可以使用VACUUM (FULL)或CLUSTER重写表,这将遵从fillfactor的新设置。
有一种简单的方法可以查看您的设置是否有效以及是否获得HOT更新:
SELECT n_tup_upd, n_tup_hot_updFROM pg_stat_user_tablesWHERE schemaname = 'myschema'AND relname = 'mytable';
这将显示自上次调用函数pg_stat_reset()以来的累计计数。
检查n_tup_hot_upd(HOT更新计数)的增长速度是否与n_tup_upd(更新计数)一样快,以查看是否获得了所需的HOT更新。
HOT更新的示例
让我们更改表的填充因子fillfactor,然后重复上面的实验:
TRUNCATE mytable;ALTER TABLE mytable SET (fillfactor = 70);INSERT INTO mytableSELECT *, 0 FROM generate_series(1, 235);SELECT ctid, id, valFROM mytable;ctid | id | val---------+-----+-----(0,1) | 1 | 0(0,2) | 2 | 0(0,3) | 3 | 0(0,4) | 4 | 0(0,5) | 5 | 0...(0,156) | 156 | 0(0,157) | 157 | 0(0,158) | 158 | 0(1,1) | 159 | 0(1,2) | 160 | 0(1,3) | 161 | 0...(1,75) | 233 | 0(1,76) | 234 | 0(1,77) | 235 | 0(235 rows)
这次,块0中的元组更少,并且仍有一些空间可用。
让我们UPDATE再次运行,看看这次效果如何:
UPDATE mytableSET val = -1WHERE id = 42;SELECT ctid, id, valFROM mytableWHERE id = 42;ctid | id | val---------+----+-----(0,159) | 42 | -1(1 row)
更新的行被写入到块0中,并且是HOT更新。
结论
HOT更新是使PostgreSQL能够处理大量UPDATE工作负载的一个特性。在UPDATE繁重的工作负载中,避免索引更新的列并将a设置fillfactor为小于100可以节省很多时间,某些场景下这可能是一个救命之策。
如果您对HOT更新的性能测量感兴趣,请参阅我的同事Kaarel Moppel撰写的这篇文章。
I Love PG
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:中国PG分会)于2017年成立,由国内多家PostgreSQL生态企业所共同发起,业务上接受工信部中国电子信息产业发展研究院指导。中国PG分会是一个非盈利行业协会组织。我们致力于在中国构建PostgreSQL产业生态,推动PostgreSQL产学研用发展。

活动成就
PostgresConf.CN & PGConf.Asia2020大会预告
经典文章
PostgreSQL与Oracle:成本、易用性和功能上的差异
精彩专辑


点击阅读原文
↓↓↓
