




列存储格式是OLAP类数据库系统最常用的数据格式,适合复杂查询、范围统计类查询的在线分析型处理系统。本节主要介绍openGauss数据库内核中cstore列存储格式的实现方式。
一、cstore整体框架
cstore列存储格式整体框架如下图所示。与行存储格式不同,cstore列存储的主体数据文件以CU为I/O单元,只支持追加写操作,因此cstore只有读共享缓冲区。CU间和CU内的可见性由对应的CUDESE表(astore表)决定,因此其可见性和并发控制原理与行存储astore基本相同。
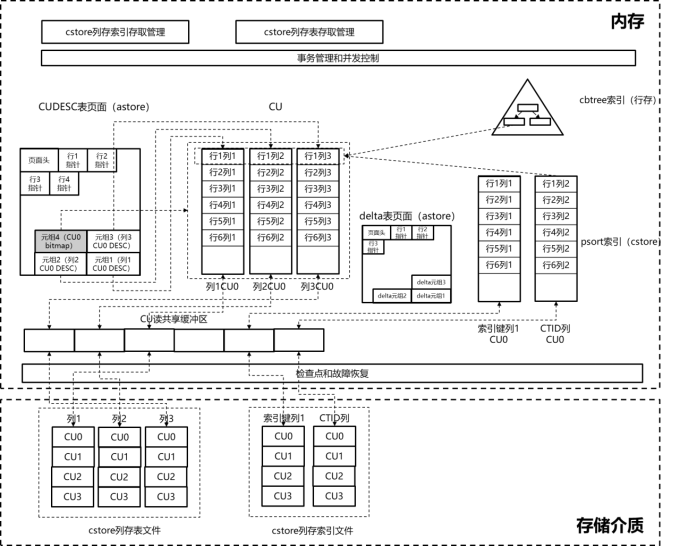
cstore列存储格式整体框架示意图
二、cstore存储单元结构
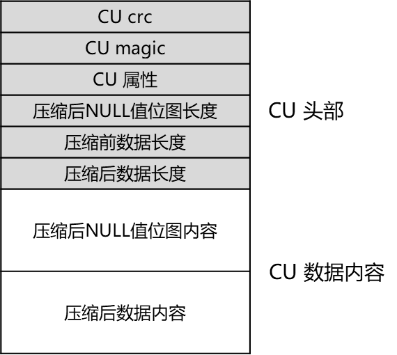
图 CU结构示意图
如上图所述,cstore的存储单元是CU,分别包括以下内容。
(1) CU的CRC值,为CU结构中除CRC成员之外,其他所有字节计算出的32位CRC值。
(2) CU的magic值,为插入CU的事务号。
(3) CU的属性值,为16位标志值,包括CU是否包含NULL行、CU使用的压缩算法等CU粒度属性信息。
(4) 压缩后NULL值位图长度,如果属性值中标识该CU包含NULL行,则本CU在实际数据内容开始处包含NULL值位图,此处储存该位图的字节长度,如果该CU不包含NULL行,则无该成员。
(5) 压缩前数据长度,即CU数据内容在压缩前的字节长度,用于读取CU时进行内存申请和校验。
(6) 压缩后数据长度,即CU数据内容在压缩后的字节长度,用于插入CU时进行内存申请和校验。
(7) 压缩后NULL值位图内容,如果属性值中标识该CU包含NULL行,则该成员即为每行的NULL值位图,否则无该成员。
(8) 压缩后数据内容,即实际写入磁盘的CU主体数据内容。
每个CU最多保存对应字段的MAX_BATCH_ROWS行(默认60000行)数据。相邻CU之间按8kB对齐。
CU模块提供的主要CU操作接口如表所示。
表 CU操作接口
函数名称 | 接口含义 |
AppendCuData | 向组装的CU中增加一行(仅对应字段) |
Compress | 压缩(若需)和组装CU |
FillCompressBufHeader | 填充CU头部 |
CompressNullBitmapIfNeed | 压缩NULL值位图 |
CompressData | 压缩CU数据 |
CUDataEncrypt | 加密CU数据 |
ToVector | 将CU数据解构为向量数组结构 |
UnCompress | 解压(若需)和解析CU |
UnCompressHeader | 解析CU头部内容 |
UnCompressNullBitmapIfNeed | 解压NULL值位图 |
UnCompressData | 解压CU数据 |
CUDataDecrypt | 解密CU数据 |
三、cstore多版本机制
cstore支持完整事务语义的DML查询,原理如下。
(1) CU间的可见性:每个CU对应CUDESC表(astore行存储表)中的一行记录(一对一),该CU的可见性完全取决于该行记录的可见性。
(2) 同一个CU内不同行的可见性:每个CU的内部可见性对应CUDESC表中的一行(多对一),该行的bitmap字段为最长MAX_BATCH_ROWS个bit的删除位图(bit 1表示删除,bit 0表示未删除),通过该位图记录的可见性和多版本,来支持CU内不同行的可见性。同时由于DML操作都是行粒度操作的,因此对于行号范围相同的、不同字段的多个CU均对应同一行位图记录。
(3) CU文件读写并发控制:CU文件自身为APPEND-ONLY,只在追加时对文件大小扩展进行加锁互斥,无须其他并发控制机制。
(4) 同一个字段的不同CU,对应严格单调递增的cu_id编号,存储在对应的CUDESC表记录中,该cu_id的获取通过图4-24中的文件扩展锁来进行并发控制。
(5) 对于cstore表的单条插入以及更新操作,提供与每个cstore表对应的delta表(astore行存储表),来接收单条插入或单条更新的元组,以降低CU文件的碎片化。
可见,cstore表的可见性依赖于对应CUDESC表中记录的可见性。一个CUDESC表的结构如下表所示,其与CU的对应关系如下图所示。
表 CUDESC表的结构
字段名 | 类型 | 含义 |
col_id | integer | 字段序号,即该cstore列存储表的第几个字段;特殊的,对于CU位图记录,该字段恒为-10 |
cu_id | oid | CU序号,即该列的第几个CU |
min | text | 该CU中该字段的最小值 |
max | text | 该CU中该字段的最大值 |
row_count | integer | 该CU中的行数 |
cu_mode | integer | CU模式 |
size | bigint | 该CU大小 |
cu_pointer | text | 该CU偏移(8k对齐);特殊的,对于CU位图记录,该字段为删除位图的二进制内容 |
magic | integer | 该CU magic号,与CU头部的magic相同,校验用 |
extra | text | 预留字段 |
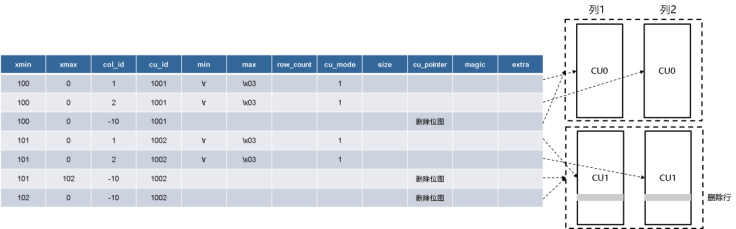
图 CUDESC表和CU对应关系示意图
如下图所示,下面结合并发插入和并发插入查询2种具体场景,介绍openGauss中cstore多版本的具体实现方法。
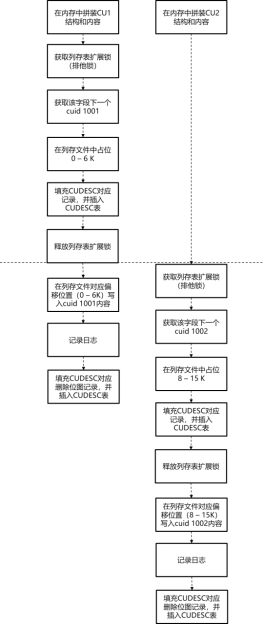
图 cstore表并发插入示意图
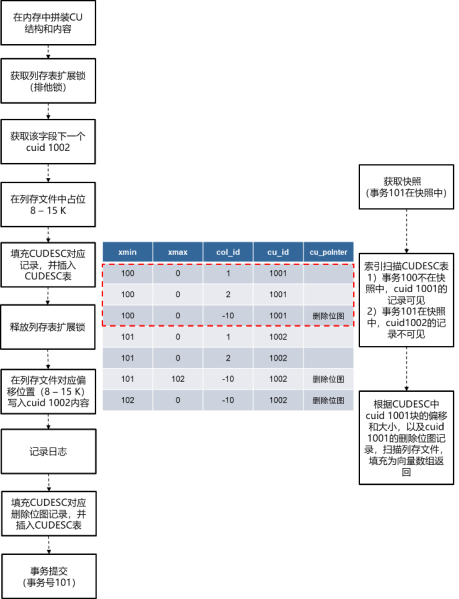
图 cstore表并发插入和查询示意图
1) 并发插入操作
对于并发的插入操作,会话1和会话2首先分别在各自的局部内存中完成待插入CU的拼接。然后假设会话1先获取到cstore表的扩展锁,那么会话2会阻塞在该锁上。在持锁阶段,会话1申请到该字段下一个cuid 1001,预占了该cu文件0 - 6 K的内容(即cuid 1001的内容大小),将cuid的大小、偏移以及cuid 1001头部部分信息填充到CUDESC记录中,并完成CUDESC记录的插入。接着,会话1放锁,并将cuid 1001的内容写入到CU对应偏移处,记录日志,再将删除位图记录插入CUDESC表中。当会话1释放cstore表的扩展锁之后,会话2就可以获取到该锁,然后,类似会话1的后续操作,完成cuid 1002的插入操作。
2) 并发插入和查询操作
假设在上述会话2的插入事务(事务号101)执行过程中,有并发的查询操作执行。对于查询操作,首先基于col_id和cuid这两个索引键对CUDESC表做索引扫描。由于事务号101在查询的快照中,因此cuid 1002的所有记录对于查询事务不可见,查询事务只能看到cuid 1001(事务号100)的那些记录。然后,查询事务根据CUDESC记录中对应的CU文件偏移和CU大小,将cuid 1001的数据从磁盘文件或缓存中加载到局部内存中,并拼接成向量数组的形式返回。
四、cstore访存接口和索引机制
cstore访存接口如下表所示,主要包括扫描、插入、删除和查询操作。
表 cstore访存接口
接口名称 | 接口含义 |
CStoreBeginScan | 开启cstore扫描 |
CStore::RunScan | 执行cstore扫描,根据执行计划,内层执行cstore顺序扫描或者cstore min-max过滤扫描 |
CStoreGetNextBatch | 继续扫描,返回下一批向量数组 |
CStoreEndScan | 结束cstore扫描 |
CStore::CStoreScan | cstore顺序扫描 |
CStore::CStoreMinMaxScan | cstore min-max过滤扫描 |
CStoreInsert::BatchInsert(VectorBatch) | 将输入的向量数组批量插入cstore表中 |
CStoreInsert::BatchInsert(bulkload_rows) | 将输入的多行数组插入cstore表中 |
CStoreInsert::BatchInsertCommon | 将一批多行数组(最多MAX_BATCH_ROWS行)插入cstore表各个列的CU文件中、插入对应CUDESC表记录、插入索引 |
CStoreInsert::InsertDeltaTable | 将一批多行数组插入cstore表对应的delta表中 |
InsertIdxTableIfNeed | 将一批多行数组插入cstore表的索引表中 |
CStoreDelete::PutDeleteBatch | 将一批待删除的向量数组暂存到局部数据结构中,如果达到局部内存上限,则触发一下删除操作 |
CStoreDelete::PutDeleteBatchForTable | CStoreDelete::PutDeleteBatch对于普通cstore表的内层实现 |
CStoreDelete::PutDeleteBatchForPartition | CStoreDelete::PutDeleteBatch对于分区cstore表的内层实现 |
CStoreDelete::PutDeleteBatchForUpdate | CStoreDelete::PutDeleteBatch对于更新cstore表操作的内层实现(更新操作由删除操作和插入操作组合而成) |
CStoreDelete::ExecDelete | 执行cstore表删除,内层调用普通cstore表删除或分区cstore表删除 |
CStoreDelete::ExecDeleteForTable | 执行普通cstore表删除 |
CStoreDelete::ExecDeleteForPartition | 执行分区cstore表删除 |
CStoreDelete::ExecDelete(rowid) | 删除cstore表中特定一行的接口 |
CStoreUpdate::ExecUpdate | 执行cstore表更新 |
cstore表查询执行流程,可以参考下图中所示。其中,灰色部分实际上是在初始化cstore扫描阶段执行的,根据每个字段的具体类型,绑定不同的CU扫描和解析函数,主要有FillVector、FillVectorByTids、FillVectorLateRead3类CU扫描解析接口。
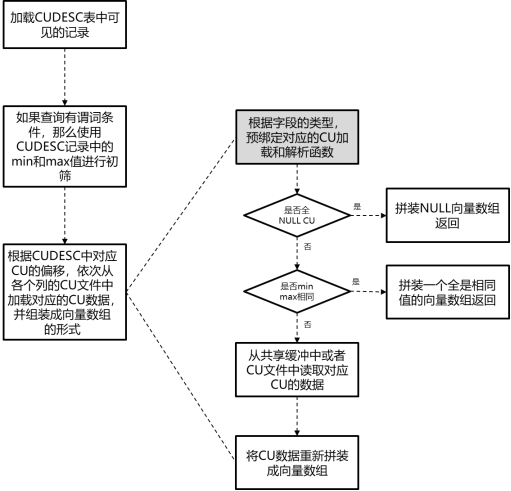
图 cstore表查询流程示意图
cstore表插入执行流程,可以参考下图所示。其中灰色部分内的具体流程可以参考图中所示。当满足以下3个条件时,可以支持delta表插入:
(1) 打开enable_delta_store GUC参数。
(2) 该批向量数组为本次导入的最后一批向量数组。
(3) 该批向量数组的行数小于delta表插入的阈值。
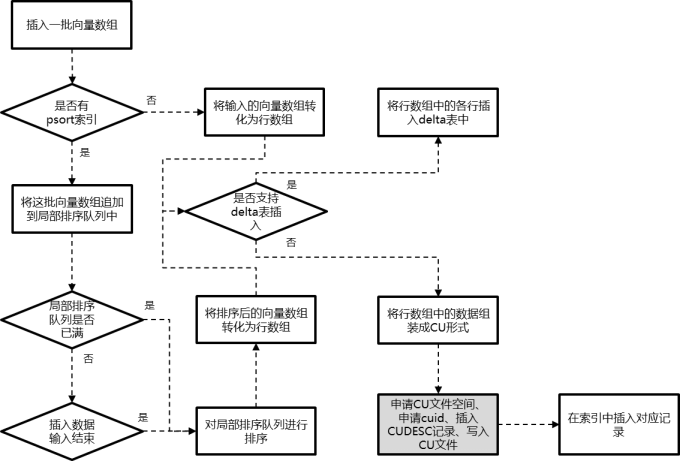
图 cstore表插入流程示意图
cstore表的删除流程主要分为两步。
(1) 如果存在delta表,那么先从delta表中删除满足谓词条件的记录。
(2) 在CUDESC表中更新待删除行所在CU的删除位图记录。
cstore表的更新操作由删除操作和插入操作组合而成,流程不再赘述。
openGauss的cstore表支持psort和cbtree两种索引。
psort索引是一种局部排序聚簇索引。psort索引表的组织形式也是cstore表,该cstore表的字段包括索引键中的各个字段,再加上对应的行号(TID)字段。如图所示,将一定数量的记录按索引键经过排序聚簇之后,与TID字段共同拼装成向量数组之后,插入psort索引cstore表中,插入流程和上面cstore表插入流程相同。
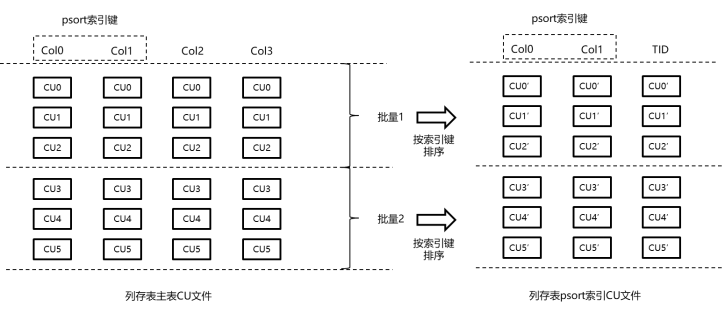
图 psort索引插入原理图
查询时如果使用psort索引扫描,会首先扫描psort索引cstore表(扫描方式和上面cstore表扫描流程相同)。在一个psort索引CU的内部,由于做了局部聚簇索引,因此可以使用基于索引键的二分查找方式,快速找到符合索引条件的记录在该psort索引中的行号,该行的TID字段值即为该条记录在cstore主表中的行号。上述流程如下图所示。值得一提的是由于做了局部聚簇索引,因此在索引cstore表扫描过程中,在真正加载索引表CU文件之前,可以通过CUDESC中的min max做到非常高效的初筛过滤。
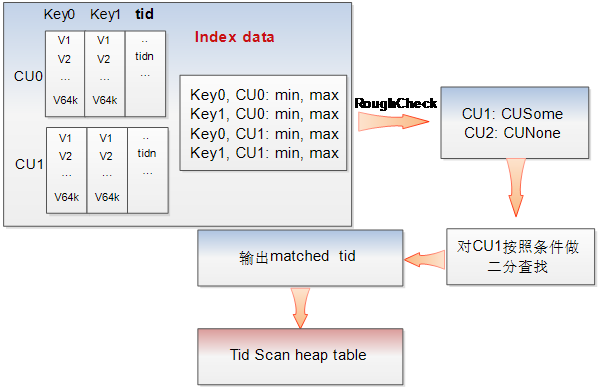
图 psort索引查询原理图
cstore表的cbtree索引和行存储表的B-Tree索引在结构和使用方式上几乎完全一致,相关原理可以参考行存储索引章节(“ 行存储索引机制”节),此处不再赘述。
openGauss cstore表索引对外提供的主要接口如表所示。
表 cstore表索引对外接口
接口名称 | 接口含义 |
psortgettuple | 通过psort索引,返回下一条满足索引条件的元组。伪接口,实际psort索引扫描通过CStore::RunScan实现 |
psortgetbitmap | 通过psort索引,返回满足索引条件的元组的tid bitmap。伪接口,实际psort索引扫描通过CStore::RunScan实现 |
psortbuild | 构建psort索引表数据。主要流程包括,从cstore主表中扫描数据、局部聚簇排序、插入到psort索引cstore表中 |
cbtreegettuple | 通过cbtree索引,返回下一条满足索引条件的元组。内部和btgettuple都是通过调用_bt_gettuple_internal函数实现的 |
cbtreegetbitmap | 通过cbtree索引,返回满足索引条件的元组的tid bitmap。内部和btgetbitmap都是通过调用_bt_next函数实现的 |
cbtreebuild | 构建cbtree索引表数据。内部实现与btbuild类似,先后调用_bt_spoolinit、CStoreGetNextBatch、_bt_spool、_bt_leafbuild和_bt_spooldestroy等几个主要函数实现。与btbuild区别在于,B-Tree的构建过程中,扫描堆表是通过heapam接口实现的,而cbtree扫描的是cstore表,因此使用的是CStoreGetNextBatch |
五、cstore缓存机制
五、cstore缓存机制
考虑到cstore列存储格式主要面向只读查询居多的OLAP类业务,因此openGauss提供只读的共享CU缓冲区机制。
openGauss中CU只读共享缓冲区的结构如下图所示。和行存储页面粒度的共享缓冲区类似,最上层为共享哈希表,哈希表键值为CU的slot类型、relfilenode、colid、cuid、cupointer构成的五元组,哈希表的记录值为该CU对应的缓冲区槽位slot id(对应行存储共享缓区的buffer id)。在全局CacheDesc数组中,用CacheDesc结构体记录与slot id对应的缓存槽位的状态信息(对应行存储缓冲区的BufferDesc结构体)。在共享CU数组中,用CU结构体记录与slot id对应的缓存CU的结构体信息。
与行存储固定的页面大小不同,不同CU的大小可能是不同的(行存储页面大小都是8 K),因此上述CU槽位只记录指向实际内存中CU数据的指针。另一方面为了保证共享内存大小可控,通过另外的全局变量来记录已经申请的有效槽位中所有CU的大小总和。
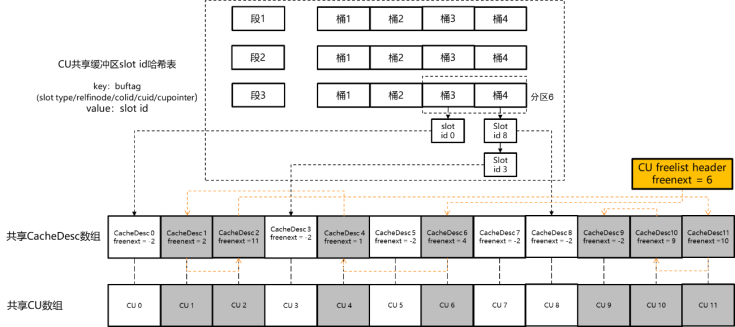
图 CU只读共享缓存结构示意图
CU只读共享缓冲区的工作机制如下图所示。
(1) 当从磁盘读取一个CU放如Cache Mgr时,需要从FreeSlotList里拿到一个free slot(空闲槽位)存放CU,然后插入到哈希表中。
(2) 当FreeSlotList为NULL的时,需要根据LRU算法淘汰掉一个slot(槽位),释放CU data占的内存,减小CU总大小计数,并从哈希表中删除,然后存放新的CU,再插入哈希表中。
(3) 缓存大小可以配置。如果内存超过设置的大小,需要淘汰掉适量的slot,并释放CU data占用的内存。
(4) 支持缓存压缩态的CU或解压态的CU两种模式,可以通过配置文件修改,同时只能存在一种模式。
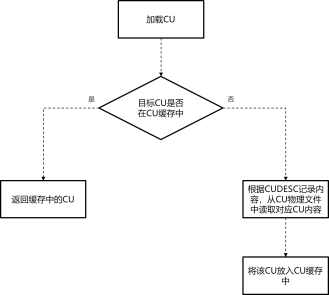
图 CU只读共享缓存读取示意图
与CU只读共享缓冲区相关的关键数据结构代码如下:
typedef struct CUSlotTag {
RelFileNodeOld m_rnode;
int m_colId;
int32 m_CUId;
uint32 m_padding;
CUPointer m_cuPtr;
} CUSlotTag;
/* slot id哈希表键值主要部分,各个成员的含义从命名中可以清晰看出 */
typedef struct DataSlotTag {
DataSlotTagKey slotTag;
CacheType slotType;
} DataSlotTag;
/* slot id哈希表键值结构体,成员包括CUSlotTag与slot类型(CU、OBS外表等) */
typedef struct CacheLookupEnt {
CacheTag cache_tag;
CacheSlotId_t slot_id;
} CacheLookupEnt;
/* slot id哈希表记录结构体,成员包括哈希表键值和对应的slot id */
typedef struct CacheDesc {
uint16 m_usage_count;
uint16 m_ring_count;
uint32 m_refcount;
CacheTag m_cache_tag;
CacheSlotId_t m_slot_id;
CacheSlotId_t m_freeNext;
LWLock *m_iobusy_lock;
LWLock *m_compress_lock;
/*The data size in the one slot.*/
int m_datablock_size;
bool m_refreshing;
slock_t m_slot_hdr_lock;
CacheFlags m_flag;
} CacheDesc;
/* CU共享缓冲区槽位状态结构体,其中m_usage_count、m_ring_count为LRU淘汰算法需要的使用计数,m_refcount为判断能否淘汰的被引用计数,m_freeNext指向下一次空闲的slot槽位(如果本槽位在free list中的话,否则m_freeNext恒等于-2),m_iobusy_lock为I/O并发控制锁,m_compress_lock为压缩并发控制锁,m_datablock_size为CU实际数据的大小,m_slot_hdr_lock保护整个CacheDesc的并发读写操作,m_flag表示槽位状态(包括全新、有效、freelist中、空闲、I/O中、错误等状态)*/ 