




行存储缓存加载和淘汰机制如下图所示。
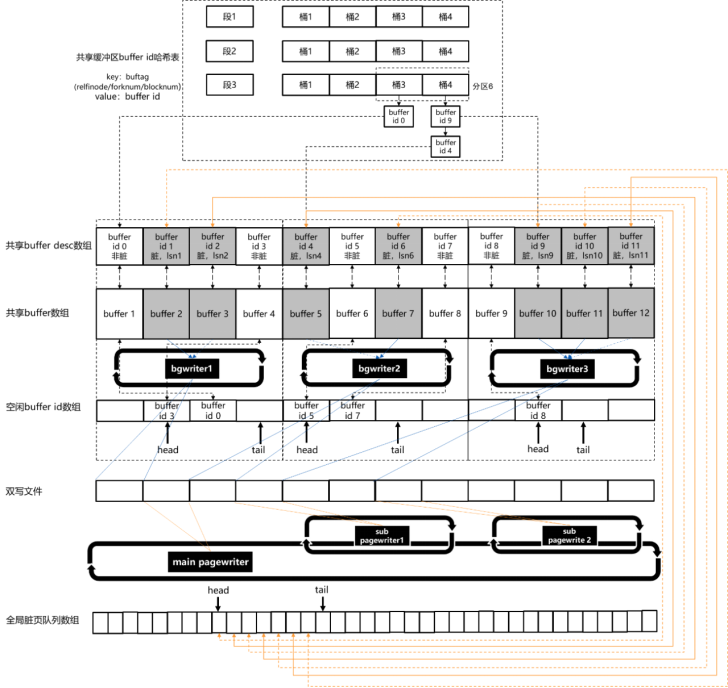
图 行存储缓存和淘汰机制示意图
行存储堆表和索引表页面的缓存和淘汰机制主要包含以下几个部分。
一、共享缓冲区内存页面数组下标哈希表
共享缓冲区内存页面数组下标哈希表用于将远大于内存容量的物理页面与内存中有限个数的内存页面建立映射关系。该映射关系通过一个分段、分区的全局共享哈希表结构实现。哈希表的键值为buftag(页面标签)结构体。该结构体由“rnode”、“forkNum”、“blockNum”三个成员组成。其中“rnode”对应行存储表物理文件名的主体命名;“forkNum”对应主体命名之后的后缀命名,通过主体命名和后缀命名,可以找到唯一的物理文件;而“blockNum”对应该物理文件中的页面号。因此,该三元组可以唯一确定任意一个行存储表物理文件中的物理页面位置。哈希表的内容值为与该物理页面对应的内存页面的“buffer id”(共享内存页面数组的下标)。
因为该哈希表是所有数据页面查询的入口,所以当存在并发查询时在该哈希表上的查询和修改操作会非常频繁。为了降低读写冲突,把该哈希表进行了分区,分区个数等于NUM_BUFFER_PARTITIONS宏的定义值。在对该哈希表进行查询或修改操作之前首先需要获取相应分区的共享锁或排他锁。考虑到当对该哈希表进行插入操作时待插入的三元组键值对应的物理页面大概率不在当前的共享缓冲区中,因此该哈希表的容量等于“g_instance.attr.attr_storage.NBuffers + NUM_BUFFER_PARTITIONS”。该表具体的定义代码如下:
typedef struct buftag {
RelFileNode rnode; /* 表的物理文件位置结构体 */
ForkNumber forkNum; /* 表的物理文件后缀信息 */
BlockNumber blockNum; /* 页面号 */
} BufferTag;二、共享buffer desc数组
该数组有“g_instance.attr.attr_storage.NBuffers”个成员,与实际存储页面内容的共享buffer数组成员一一对应,用来存储相同“buffer id”(即这两个全局数组的下标)的数据页面的属性信息。该数组成员为BufferDesc结构体,具体定义代码如下:
typedef struct BufferDesc {
BufferTag tag; /*缓冲区页面标签 */
pg_atomic_uint32 state; /* 状态位、引用计数、使用历史计数 */
int buf_id; /*缓冲区下标 */
ThreadId wait_backend_pid;
LWLock* io_in_progress_lock;
LWLock* content_lock;
pg_atomic_uint64 rec_lsn;
volatile uint64 dirty_queue_loc;
} BufferDesc;(1) tag成员是该页面的(relfilenode,forknum,blocknum)三元组。
(2) state成员是该内存状态的标志位,主要包含BM_LOCKED(该buffer desc结构体内容的排他锁标志)、BM_DIRTY(脏页标志)、BM_VALID(有效页面标志)、BM_TAG_VALID(有效tag标志)、BM_IO_IN_PROGRESS(页面I/O状态标志)等。
(3) buf_id成员,是该成员在数组中的下标。
(4) wait_backend_pid成员,是等待页面unpin(取消引用)的线程的线程号。
(5) io_in_progress_lock成员,是用于管理页面并发I/O操作(从磁盘加载和写入磁盘)的轻量级锁。
(6) content_lock成员,是用于管理页面内容并发读写操作的轻量级锁。
(7) rec_lsn成员,是上次写入磁盘之后该页面第一次修改操作的日志lsn值。
(8) dirty_queue_loc成员,是该页面在全局脏页队列数组中的(取模)下标。
三、共享buffer数组
该数组有“g_instance.attr.attr_storage.NBuffers”个成员,每个数组成员即为保存在内存中的行存储表页面内容。需要注意的是,每个buffer在代码中以一个整型变量来标识,该值从1开始递增,数值上等于“buffer id + 1”,即“数组下标加1”。
四、bgwriter线程组
该数组有“g_instance.attr.attr_storage.bgwriter_thread_num”个线程。每个“bgwriter”线程负责一定范围内(目前为均分)的共享内存页面的写入磁盘操作,如图4-20中所示。如果全局共享buffer数组的长度为12,一共有3个“bgwriter”线程,那么第1个“bgwriter”线程负责“buffer id 0 - buffer id 3”的内存页面的维护和写入磁盘;第2个“bgwriter”线程负责“buffer id 4 - buffer id 7”的内存页面的维护和写入磁盘;第3个“bgwriter”线程负责buffer id 8 - buffer id 11的内存页面的维护和写入磁盘。每个“bgwriter”进程在后台循环扫描自己负责的那些共享内存页面和它们的buffer desc状态,将被业务修改过的脏页收集起来,批量写入双写文件,然后写入表文件系统。对于刷完的内存页,将其状态变为非脏,并追加到空闲buffer id队列的尾部,用于后续业务加载其他当前不在共享缓冲区的物理页面。每个“bgwriter”线程的信息记录在BgWriterProc结构体中,该结构体的定义代码如下:
typedef struct BgWriterProc {
PGPROC *proc;
CkptSortItem *dirty_buf_list;
uint32 dirty_list_size;
int *cand_buf_list;
volatile int cand_list_size;
volatile int buf_id_start;
pg_atomic_uint64 head;
pg_atomic_uint64 tail;
bool need_flush;
volatile bool is_hibernating;
ThrdDwCxt thrd_dw_cxt;
volatile uint32 thread_last_flush;
int32 next_scan_loc;
} BgWriterProc;其中比较关键的几个成员含义是:
(1) dirty_buf_list为存储每批收集到的脏页面buffer id的数组。dirty_list_size为该数组的长度。
(2) cand_buf_list为存储写入磁盘之后非脏页面buffer id的队列数组(空闲buffer id数组)。cand_list_size为该数组的长度。
(3) buf_id_start为该bgwriter负责的共享内存区域的起始buffer id,该区域长度通过“g_instance.attr.attr_storage.NBuffers / g_instance.attr.attr_storage.bgwriter_thread_num”得到。
(4) head为当前空闲buffer id队列的队头数组下标,tail为当前空闲buffer id队列的队尾数组下标。
(5) next_scan_loc为上次bgwriter循环扫描时停止处的buffer id,下次收集脏页从该位置开始。
五、pagewriter线程组
“pagewriter”线程组由多个“pagewriter”线程组成,线程数量等于GUC参数(g_instance.ckpt_cxt_ctl->page_writer_procs.num)的值。“pagewriter”线程组分为主“pagewriter”线程和子“pagewriter”线程组。主“pagewriter”线程只有一个,负责从全局脏页队列数组中批量获取脏页面、将这些脏页批量写入双写文件、推进整个数据库的检查点(故障恢复点)、分发脏页给各个pagewriter线程,以及将分发给自己的那些脏页写入文件系统。子“pagewriter”线程组包括多个子“pagewriter”线程,负责将主“pagewriter”线程分发给自己的那些脏页写入文件系统。
每个“pagewriter”线程的信息保存在PageWriterProc结构体中,该结构体的定义代码如下:
typedef struct PageWriterProc {
PGPROC* proc;
volatile uint32 start_loc;
volatile uint32 end_loc;
volatile bool need_flush;
volatile uint32 actual_flush_num;
} PageWriterProc;其中:
(1) proc成员为“pagewriter”线程属性信息。
(2) start_loc为分配给本线程待写入磁盘的脏页在全量脏页队列中的起始位置。
(3) end_loc为分配给本线程待写入磁盘的脏页在全量脏页队列中的结尾位置。
(4) need_flush为是否有脏页被分配给本“pagewriter”的标志。
(5) actual_flush_num为本批实际写入磁盘的脏页个数(有些脏页在分配给本“pagewriter”线程之后,可能被“bgwriter”线程写入磁盘,或者被DROP(删除)类操作失效)。
“pagewriter”线程与“bgwriter”线程的差别:“bgwriter”线程主要负责将脏页写入磁盘,以便留出非脏的缓冲区页面用于加载新的物理数据页;“pagewriter”线程主要的任务是推进全局脏页队列数组的进度,从而推进整个数据库的检查点和故障恢复点。数据库的检查点是数据库(故障)重启时需要回放的日志的起始位置lsn。在检查点之前的那些日志涉及的数据页面修改,需要保证在检查点推进时刻已经写入磁盘。通过推进检查点的lsn,可以减少数据库宕机重启之后需要回放的日志量,从而降低整个系统的恢复时间目标(recovery time objective,RTO)。关于“pagewriter”的具体工作原理,将在“4.2.9 持久化及故障恢复机制”小节进行更详细的描述。
六、双写文件
一般磁盘的最小I/O单位为1个扇区(512字节),大部分文件系统的I/O单位为8个扇区。数据库最小的I/O单位为一个页面(16个扇区),因此如果在写入磁盘过程中发生宕机,可能出现一个页面只有部分数据写入磁盘的情况,会影响当前日志恢复的一致性。为了解决上述问题,openGauss引入了双写文件。所有页面在写入文件系统之前,首先要写入双写文件,并且双写文件以“O_SYNC | O_DIRECT”模式打开,保证同步写入磁盘。因为双写文件是顺序追加的,所以即使采用同步写入磁盘,也不会带来太明显的性能损耗。在数据库恢复时,首先从双写文件中将可能存在的部分写入磁盘的页面进行修复,然后再回放日志进行日志恢复。
此外也可以采用FPW(full page write,全页写)技术解决部分数据写入磁盘问题:在每次检查点之后,对于某个页面首次修改的日志中记录完整的页面数据。但是为了保证I/O性能的稳定性,目前openGauss默认使用增量检查点机制,而该机制与FPW技术无法兼容,所以在openGauss中目前采用双写技术来解决部分数据写入磁盘问题。
结合文章上部图片,缓冲区页面查找的流程如下。
(1) 计算“buffer tag”对应的哈希值和分区值。
(2) 对“buffer id”哈希表加分区共享锁,并查找“buffer tag”键值是否存在。
(3) 如果“buffer tag”键值存在,确认对应的磁盘页面是否已经加载上来。如果是,则直接返回对应的“buffer id + 1”;如果不是,则尝试加载到该“buffer id”对应的缓冲区内存中,然后返回“buffer id + 1”。
(4) 如果“buffer tag”键值不存在,则寻找一个“buffer id”来进行替换。首先尝试从各个“bgwriter”线程的空闲“buffer id”队列中获取可以用来替换的“buffer id”;如果所有“bgwriter” 线程的空闲buffer id队列都为空队列,那么采用clock-sweep算法,对整个buffer缓冲区进行遍历,并且每次遍历过程中将各个缓冲区的使用计数减一,直到找到一个使用计数为0的非脏页面,就将其作为用来替换的缓冲区。
(5) 找到替换的“buffer id”之后,按照分区号从小到大的顺序,对两个“buffer tag”对应的分区同时加上排他锁,插入新“buffer tag”对应的元素,删除原来“buffer tag”对应的元素。然后再按照分区号从小到大的顺序释放上述两个分区排他锁。
(6) 最后确认对应的磁盘页面是否已经加载上来。如果是,则直接返回上述被替换的“buffer id + 1”;如果不是,则尝试加载到该“buffer id”对应的buffer内存中,然后返回“buffer id + 1”。
行存储共享缓冲区访问的主要接口和含义如表所示。
表 行存储共享缓冲区访问的主要接口
函数名 | 操作含义 |
ReadBufferExtended | 读、写业务线程从共享缓冲区获取页面用于读、写查询 |
ReadBufferWithoutRelcache | 恢复线程从共享缓冲区获取页面用于回放日志 |
ReadBufferForRemote | 备机页面修复线程从共享缓冲区获取页面用于修复主机损坏页面 |
