




最近一个客户一直在强调将引用系统的数据进行分库分表,具体原因不说了,在整理方案的时候简单做了一个mycat与OB(分布式数据库)的对比,以下摘抄对比部分进行讨论,欢迎大佬们指正,当然最后我的建议是推荐客户使用分布式数据库。
在做方案的时候主要从以下几个角度来进行区分。
一、单表查询
mycat
在使用mycat的时候建议使用分片键进行查询,这样可以通过路由功能直接找到所在的水平库表,如下图: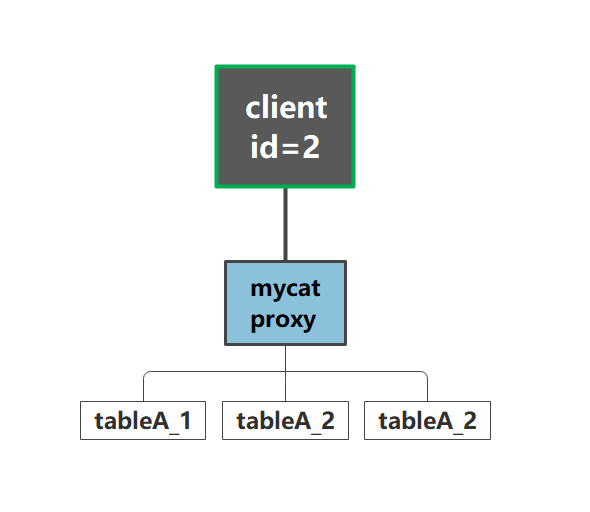
客户端执行一条sql语句,路由根据分片建id,可以确定是在那个分库分表中。
但是一旦没有分片建,那么就会从所有的分库中查询结果在进行汇总,这样会非常消耗mycat和mysql的资源。
OBCluster
这里先引用ob官方文档里的一张图
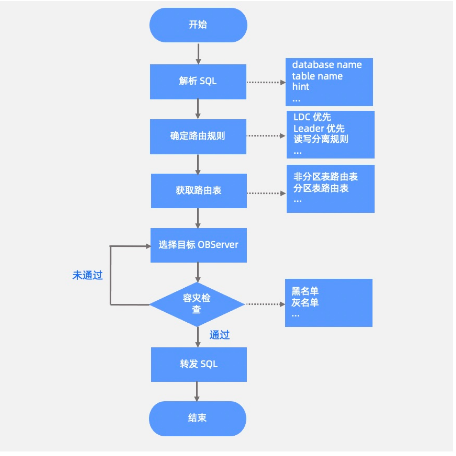
OBProxy 中保存了 Partition 和 OBServer_addr 的映射缓存,如果where条件中存在分区键,则会直接找到patition的主副本,如果查询中没有指定分区建,则会路由到随便一台机器,这台机器执行remote的并行执行计划,相比与mycat来说obcluster集成了路由、并行执行计划、远程执行计划等,并且obproxy基本上不存在性能瓶颈的情况,并且ob是支持类似于oracle的全局索引和本地索引,因此可以大大提升查询效率。
二、分页查询
mycat
如果某个表存在三个分片,数据分布如下
DB1.table1:[0,1,2,3,4,5]
DB2.table2:[32,33,34,35]
DB3.table3:[22,23,24,25]
如果执行一下sql语句,没有使用任何条件
select * from table limit 2;
这样的查询结果集是不确定性的,因为查询结果可能是【0,1】或【32,33】或【22,23】,为了解决此类问题mycat后台执行了特别多的处理来保证结果的正确,因此非常消耗cpu进行计算。
Obcluster
我们先看一下ob的分布式执行计划
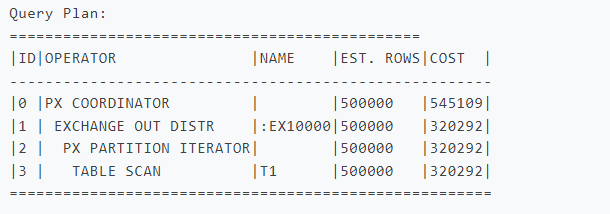
生成分布式计划就是EXCHANGE 表示的位置表示从此处开始分布式执行计划,每个TABLE SCAN 和 EXCHANGE OUT构成了一个分布式执行计划任务实行并行执行。不对存在单节点性能瓶颈
三、join操作
mycat
使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布
Obcluster
obproxy会根据事务开始的第一条sql语句进行路由,如果join的表的主副本不在本地,则开启remote执行计划
四、其他的一些对比图
| 特性 | Mysql | OceanBase |
| 水平拆分 | 借助Mycat、sharding jdbc等中间件 | 支持 |
| 数据迁移 | 需要手工拆分 | 无需手工介入 |
| 应用改造工作量 | 对应用透明 | 对应用透明 |
| 分布式事务 | 不支持 | 支持 |
| 分表设计 | 复杂 | 简单 |
| 多表join | 支持(join)的谓词必须在同一数据库分片 | 支持 |
| 排序、聚合、full scan、range scan | 效率低 | 效率高 |
| 读写分离 | 不支持 | 支持 |
| 二次改造 | 复杂 | 简单 |
| 可扩展性 | 需要开发人员重新水平拆分表 | 无需开发接入 |
| 备份恢复 | 备份恢复多套数据库 | 备份一套即可 |
