




“万物皆可 Embedding”这句话似乎每个做算法模型小伙伴都听过了。“万物”具体是指什么呢?Embedding 又是如何实现的呢?本文介绍了一款像积木般易于组合、开箱即用的 Embedding 流水线。
本文转载自知乎用户 CSY,转载已获得原作者授权。
万物皆可 Embedding
在大数据的现实世界中,包括了任何内容:图片、视频、语音、文本,甚至 3D 模型等,这些可统称为非结构化数据。了解了所谓的“万物”,那 Embedding 又指什么?如下图所示,针对非结构化数据,我们利用 AI 技术来对其进行编码,转换成特征向量,通过计算向量实现对非结构化数据的分析。通常将非结构化数据提取向量的过程称为 Embedding。
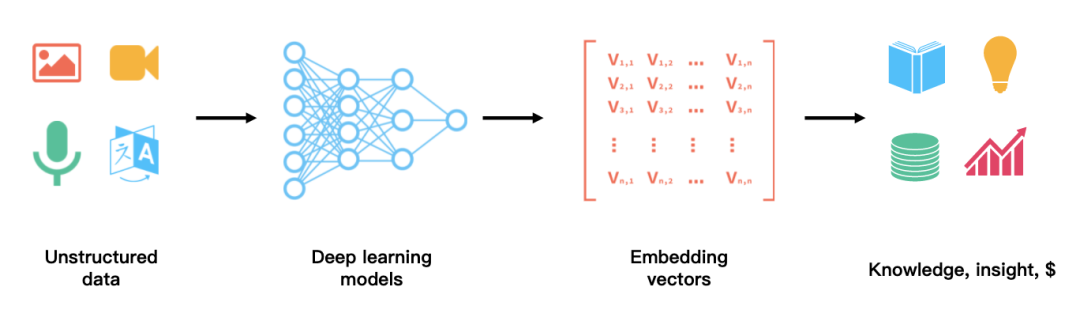
开箱即用的 Embedding 流水线——Towhee
Embedding 过程通常利用 AI 模型来实现,而模型使用包括调研、选型、训练与调优等复杂且成本较高的流程,好在业界已提供很多预训练好的模型可以直接用,但如何切换模型以及快速上手,就需要一套开箱即用的流水线(Pipeline)。
"X2Vec, Towhee is all you need!" 是 Towhee 这个开源项目的口号,它提供开箱即用的 Embedding 流水线,你无需了解内部工作原理,就可以开发和部署各种各样的流水线。
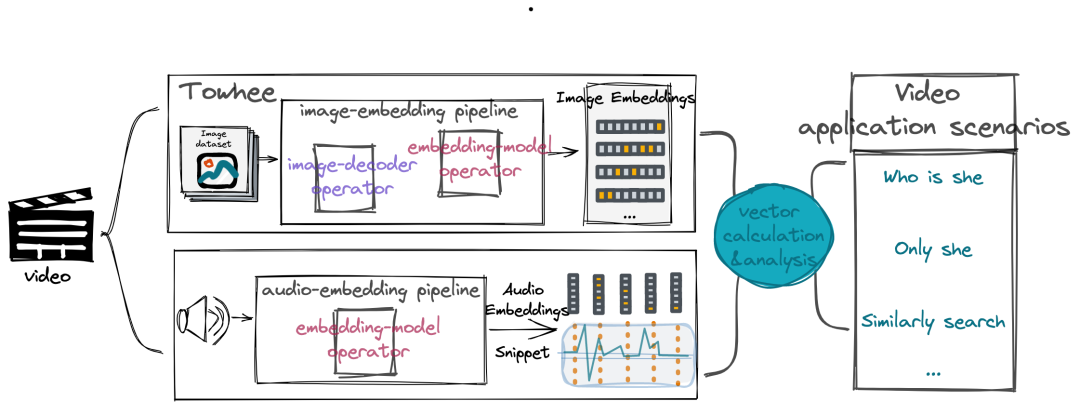
如上图所示,针对各种各样的视频应用场景,可以将流水线进行拆分,如图像处理和音频处理两个流水线。首先,截取视频帧,然后对截取到的图片集进行处理,得到特征向量;再获取视频中的音频数据,提取音频的特征向量。通过对图片帧和音频的处理来进一步分析视频,当然图片和音频的 embedding 也可以各自定义为一个流水线,并且流水线的使用非常简单,只需要运行 pipeline(pipeline_name:str)
,而这些流水线都被管理在 Towhee Hub 上,你也可以在 Hub 上寻找你需要的 Embedding 流水线。
Towhee Hub 地址(点击右侧的 Categories 可以进行筛选):https://towhee.io/pipelines?limit=30&page=1
Towhee 目前支持多个图像 Embedding 流水线,包括 resnet50,resnet101,efficientnetb5,efficientnetb7,vitlarge,swinbase,swinlarge,efficientnetb7-swinlarge-ensemble。值得关注的是 efficientnetb7-swinlarge-ensemble,它将 efficientnetb7 和 swinlarge 模型融合得出更优的模型效果。
>>> from towhee import pipeline>>> embedding_pipeline = pipeline('towhee/image-embedding-resnet50')>>> embedding = embedding_pipeline('path/to/your/image')
>>> embedding_pipeline = pipeline('towhee/audio-embedding-vggish')>>> embedding = embedding_pipeline('path/to/your/audio')
>>> embedding_pipeline = pipeline('towhee/video-embedding-resnet50-vggish')>>> embedding = embedding_pipeline('path/to/your/video')
Towhee 框架概览
你可能会好奇,为什么 towhee 使用 Embedding 流水线如此简单?似乎只需要指定模型就可以直接运行,接下来为你简单介绍下 Towhee 框架。Towhee 主要包含了流水线(Pipelines),算子(Operators),引擎(Engine),以及模型相关的模型层(Layers)和训练(Trainer)。
Pipeline: 一条流水线是由多个算子组成的 Embeddding 任务。
Operator: 算子是管道中的单个节点。它可以是机器学习模型、复杂算法或 Python 函数。Towhee 将多个算子连接在一起组成流水线。
Engine: 引擎是 Towhee 的核心。给定一个流水线,引擎会驱动各个算子之间的数据流、调度任务,并监控计算资源(CPU/GPU/等)的使用情况。
Layers: 模型层用于快速构建机器学习模型,它支持各种经典和新发布的模型。
Trainer: 训练提供模型训练与优化,它管理着模型训练的各个组件。
总结



