




前言
大家好,今天我们将结束TiDB的Parse
之旅。这是一期把前面全部都整合起来的文章。
从"香草数据库"的lexer说开去
研究 TiDB 中的 Parse模块 (一)
goyacc 新手入门,有趣。。。
今天的主题如下:

lex 和 scan
之前我们自己写的的Parse程序,在其中调用了Parse
的方法。
stmtNodes, _, err := p.Parse(sql, "", "")
我们调试跟踪Parse
函数,该函数会调用ParseSQL
函数。ParseSQL
函数的作用是解析输入的查询字符串,然后生成ast.StmtNode
。
// ParseSQL parses a query string to raw ast.StmtNode.
func (parser *Parser) ParseSQL(sql string, params ...ParseParam) (stmt []ast.StmtNode, warns []error, err error) {
resetParams(parser)
for _, p := range params {
if err := p.ApplyOn(parser); err != nil {
return nil, nil, err
}
}
sql = parser.lexer.tryDecodeToUTF8String(sql)
parser.src = sql
parser.result = parser.result[:0]
var l yyLexer
parser.lexer.reset(sql)
l = &parser.lexer
yyParse(l, parser)
warns, errs := l.Errors()
if len(warns) > 0 {
warns = append([]error(nil), warns...)
} else {
warns = nil
}
if len(errs) != 0 {
return nil, warns, errors.Trace(errs[0])
}
for _, stmt := range parser.result {
ast.SetFlag(stmt)
}
return parser.result, warns, nil
}
在上面这个函数中,比较重要的部分就是yyParse
函数。
var l yyLexer
parser.lexer.reset(sql)
l = &parser.lexer
yyParse(l, parser)
该函数是goyacc生成的解析器parse.go中的yyParse
函数。继续调试会出现以下调用链路。
Parse -> ParseSQL -> yyParse -> yylex1 -> Lex -> scan

这条调用链路的终点就是Lex - > scan
。
我们先来看Lex。Lex 函数返回一个token
并将 token
值存储在 v 中,这个v 就是 yySymType
结构体,在上一个章节学过的知识。这个结构体是我们在语法文件parse.y 中定义的 %union,而这个 Scanner 结构体是满足 yyLexer 接口的。
重点:
goyacc 内部有一个很重要的 interface就是yyLexer。需要使用者自己实现提供,TiDB这部分是通过手写实现的。
type yyLexer interface {
Lex(lval *yySymType) int
Error(e string)
}
我们看看Scanner结构体,注释上写的很清楚,实现了yyLexer
接口。
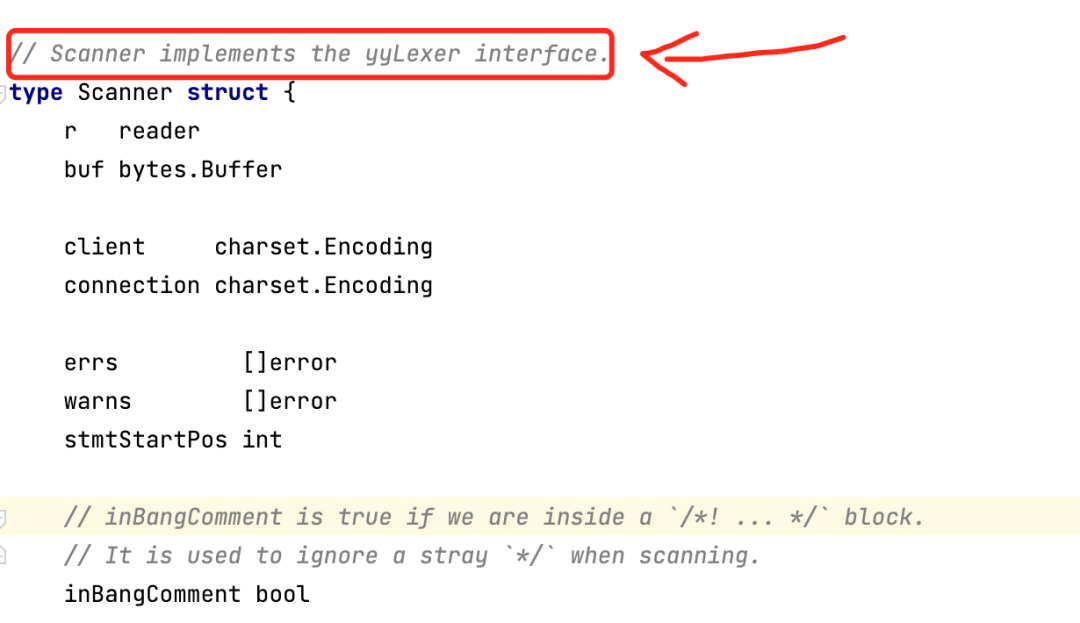
继续回到我们的lex
函数上。
// Lex returns a token and store the token value in v.
// Scanner satisfies yyLexer interface.
// 0 and invalid are special token id this function would return:
// return 0 tells parser that scanner meets EOF,
// return invalid tells parser that scanner meets illegal character.
func (s *Scanner) Lex(v *yySymType) int {
tok, pos, lit := s.scan()
s.lastScanOffset = pos.Offset
s.lastKeyword3 = s.lastKeyword2
s.lastKeyword2 = s.lastKeyword
s.lastKeyword = 0
v.offset = pos.Offset
v.ident = lit
if tok == identifier {
tok = s.handleIdent(v)
}
if tok == identifier {
if tok1 := s.isTokenIdentifier(lit, pos.Offset); tok1 != 0 {
tok = tok1
s.lastKeyword = tok1
}
}
if s.sqlMode.HasANSIQuotesMode() &&
tok == stringLit &&
s.r.s[v.offset] == '"' {
tok = identifier
}
if tok == pipes && !(s.sqlMode.HasPipesAsConcatMode()) {
return pipesAsOr
}
if tok == not && s.sqlMode.HasHighNotPrecedenceMode() {
return not2
}
if tok == as && s.getNextToken() == of {
_, pos, lit = s.scan()
v.ident = fmt.Sprintf("%s %s", v.ident, lit)
s.lastKeyword = asof
s.lastScanOffset = pos.Offset
v.offset = pos.Offset
return asof
}
switch tok {
case intLit:
return toInt(s, v, lit)
case floatLit:
return toFloat(s, v, lit)
case decLit:
return toDecimal(s, v, lit)
case hexLit:
return toHex(s, v, lit)
case bitLit:
return toBit(s, v, lit)
case singleAtIdentifier, doubleAtIdentifier, cast, extract:
v.item = lit
return tok
case null:
v.item = nil
case quotedIdentifier, identifier:
tok = identifier
s.identifierDot = s.r.peek() == '.'
}
if tok == unicode.ReplacementChar {
return invalid
}
return tok
}
一开始就会调用scan
这个函数,scan会将我们的SQL语句进行分词,扫描出的结果存放到tok,pos,lit
这三个变量中。
举个简单的例子,我这里的SQL语句,"SELECT a, b FROM t ",最终经过分词后将变成下面的形态。
pos(line col offest) tok lit
(1,0,0) 57521 "select"
(1,7,7) 57346 "a"
(1,8,8) 44 ","
(1,10,10) 57346 "b"
(1,12,12) 57423 "from"
(1,17,17) 57346 "t"
(1,18,18) 0 ""
上面tok是一些数字,一开始我没搞明白意义,后面看了上面的parse.go
的定义,瞬间懂了。这些是在Parse.y中定义的token。然后经过goyacc编译之后,自动转换的一个map类型。
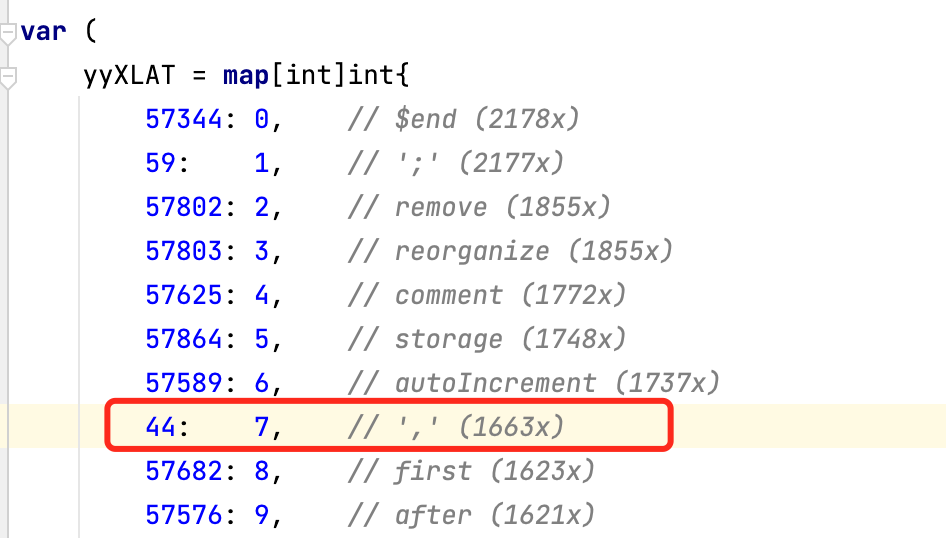

这些特殊的数字都是能找到对应的类型,例如57521被定义成为selectKwd
。
TiDB 中的 Parse.y
前面我们学过,语法规则,还有token
这些都定义在.y文件中,而TiDB的Parse.y文件的内容非常多。有了之前铺垫的知识,其实你也可以明白,它就是三部分。
TiDB的 Parse.y 的文件非常长,我们就只说几个重点的部分。
第一个称为定义部分,可以在其中进行各种定义,比如token。

这些定义部分主要是 Token 的类型、优先级以及它的结合性等等。
第二个部分是语法的规则,是比较关键的部分。我们可以在 https://pingcap.github.io/sqlgram/ 这个网站上找到语法的规则。
例如我们的update
语句,我们可以参考UpdateStmt
语法。它的语法如下图:
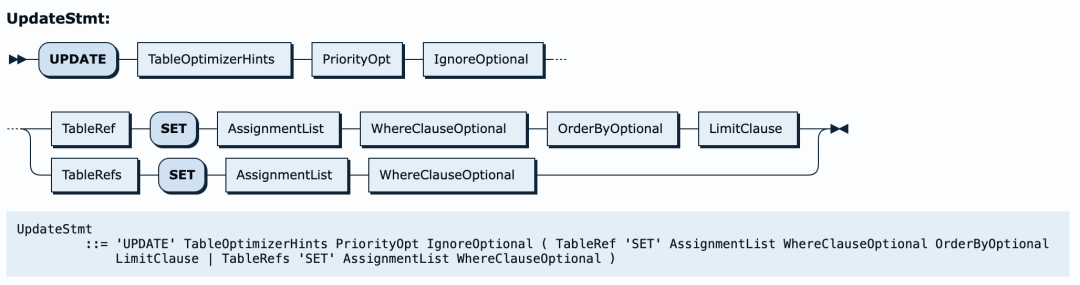
如果你看parse.y文件,可以找到与之对应的部分。
/***********************************************************************************
* Update Statement
* See https://dev.mysql.com/doc/refman/5.7/en/update.html
***********************************************************************************/
UpdateStmt:
UpdateStmtNoWith
| WithClause UpdateStmtNoWith
{
u := $2.(*ast.UpdateStmt)
u.With = $1.(*ast.WithClause)
$$ = u
}
UpdateStmtNoWith:
"UPDATE" TableOptimizerHintsOpt PriorityOpt IgnoreOptional TableRef "SET" AssignmentList WhereClauseOptional OrderByOptional LimitClause
{
var refs *ast.Join
if x, ok := $5.(*ast.Join); ok {
refs = x
} else {
refs = &ast.Join{Left: $5.(ast.ResultSetNode)}
}
st := &ast.UpdateStmt{
Priority: $3.(mysql.PriorityEnum),
TableRefs: &ast.TableRefsClause{TableRefs: refs},
List: $7.([]*ast.Assignment),
IgnoreErr: $4.(bool),
}
if $2 != nil {
st.TableHints = $2.([]*ast.TableOptimizerHint)
}
if $8 != nil {
st.Where = $8.(ast.ExprNode)
}
if $9 != nil {
st.Order = $9.(*ast.OrderByClause)
}
if $10 != nil {
st.Limit = $10.(*ast.Limit)
}
$$ = st
}
| "UPDATE" TableOptimizerHintsOpt PriorityOpt IgnoreOptional TableRefs "SET" AssignmentList WhereClauseOptional
{
st := &ast.UpdateStmt{
Priority: $3.(mysql.PriorityEnum),
TableRefs: &ast.TableRefsClause{TableRefs: $5.(*ast.Join)},
List: $7.([]*ast.Assignment),
IgnoreErr: $4.(bool),
}
if $2 != nil {
st.TableHints = $2.([]*ast.TableOptimizerHint)
}
if $8 != nil {
st.Where = $8.(ast.ExprNode)
}
$$ = st
}
UseStmt:
"USE" DBName
{
$$ = &ast.UseStmt{DBName: $2}
}
WhereClause:
"WHERE" Expression
{
$$ = $2
}
WhereClauseOptional:
{
$$ = nil
}
| WhereClause
CommaOpt:
{}
| ','
{}
这里的语法就是自顶向下分解定义语句,是一个递归下降的算法。当解析完成后,就会生成 ast.UpdateStmt
抽象语法树。
yyParse 处理
tok, pos, lit
这三个变量是通过循环读取字符串,分词最后得到的结果。tok
是一种类型,pos
代表了字符串的位置,lit
代表了真正的值。
然后Lex函数功能说了,会将其赋值给v。v就是yySymType
结构体。

v.offset = pos.Offset
v.ident = lit
当然函数里面还有一些判断,我们只要知道yySmType
结构体已经赋值了就行了。现在为止就实现了我们的Token
流。
然后Token流就需要经过yyParse
的处理,打开我们之前看过的图。
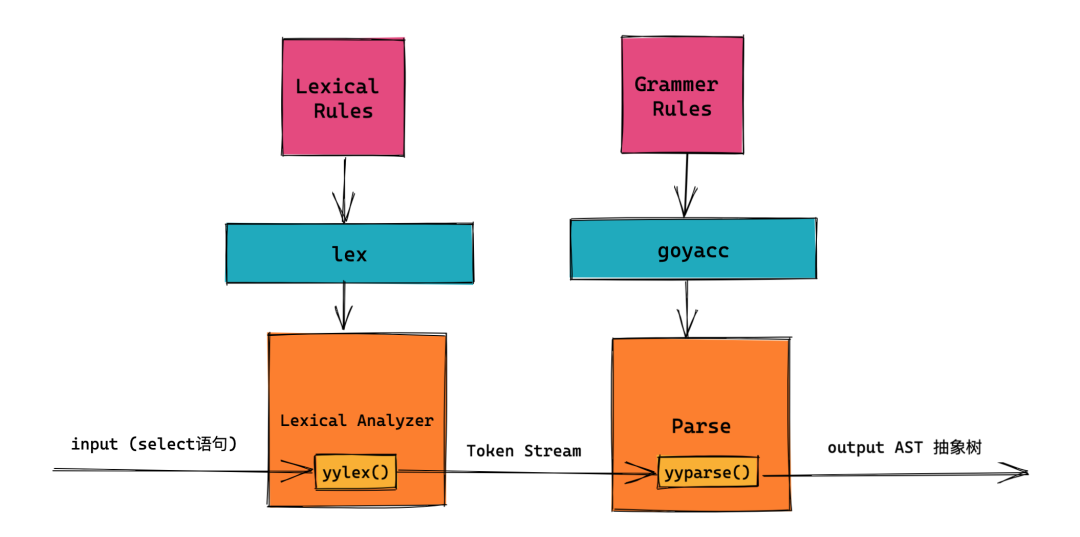
它经过yyParse函数中,做了语法解析。就会生成一个抽象的树,它最终的结果是保存在parser.result
中。

然后回到ParseSQL
函数里面。最后进行一个for .. range的循环,它会执行一个SetFlag的函数。
for _, stmt := range parser.result {
ast.SetFlag(stmt)
}
这个函数看注释是为表达式设置flag。
// SetFlag sets flag for expression.
func SetFlag(n Node) {
var setter flagSetter
n.Accept(&setter)
}
它会调用一个Accept
函数。Accept
函数实现 Node
结构体的 Accept
接口。这个 Node
接口是AST tree 的基本单元。
// Node is the basic element of the AST.
// Interfaces embed Node should have 'Node' name suffix.
type Node interface {
// Restore returns the sql text from ast tree
Restore(ctx *format.RestoreCtx) error
// Accept accepts Visitor to visit itself.
// The returned node should replace original node.
// ok returns false to stop visiting.
//
// Implementation of this method should first call visitor.Enter,
// assign the returned node to its method receiver, if skipChildren returns true,
// children should be skipped. Otherwise, call its children in particular order that
// later elements depends on former elements. Finally, return visitor.Leave.
Accept(v Visitor) (node Node, ok bool)
// Text returns the original text of the element.
Text() string
// SetText sets original text to the Node.
SetText(text string)
// SetOriginTextPosition set the start offset of this node in the origin text.
SetOriginTextPosition(offset int)
// OriginTextPosition get the start offset of this node in the origin text.
OriginTextPosition() int
}
该结构体有一些函数有点意思,比如Restore
函数,它可以逆向操作,把AST tree
反向还原成SQL文本。
Accept(v Visitor) (node Node, ok bool) 方法允许任何已实现ast.Visitor的结构遍历自身。
ast.Visitor接口定义如下,这里注释意思也很明显通过Visitor访问一个Node。这个Node是AST tree 的基本单元
// Visitor visits a Node.
type Visitor interface {
// Enter is called before children nodes are visited.
// The returned node must be the same type as the input node n.
// skipChildren returns true means children nodes should be skipped,
// this is useful when work is done in Enter and there is no need to visit children.
Enter(n Node) (node Node, skipChildren bool)
// Leave is called after children nodes have been visited.
// The returned node's type can be different from the input node if it is a ExprNode,
// Non-expression node must be the same type as the input node n.
// ok returns false to stop visiting.
Leave(n Node) (node Node, ok bool)
}
它里面有2个方法, Enter
方法在访问子节点之前调用,而Leave
是在访问了子节点之后调用。
这里非常绕看不明白在做什么?其实很简单,它的最终目的就是要实现一个遍历AST Tree的节点的方法。执行完成SetFlag
之后,ParseSQL
函数就执行结束了,然后返回了结果给Parse
函数,得到了最终版的AST解析树。
再探Visitor
看到上面介绍的Visitor
,其实有点懵,不过没关系,官网quickstart
有一个例子。还记得我们之前的操作吗 ?它返回了ast.StmtNode
。
这个ast.StmtNode
的输出结果是这样的。
&{{{{SELECT a, b FROM t 0}}} 0x140001a8cc0 false 0x1400006a380 <nil> 0x140001a8cf0 <nil> <nil> [] <nil> <nil> <nil> [] false false 0 <nil> <nil> 0 [] <nil>}
这其实是一棵树状结构。可以通过遍历自身获取colNames
,也就是列名。
1.定义一个colX结构体
和Visitor
接口一样,具备Enter和Leave的方法。
Enter方法在访问子节点之前调用,而Leave是在访问了子节点之后调用。
type Visitor interface {
Enter(n Node) (node Node, skipChildren bool)
Leave(n Node) (node Node, ok bool)
}
定义我们的colX结构体,有 Enter
和Leave
两个方法。
type colX struct{
colNames []string
}
func (v *colX) Enter(in ast.Node) (ast.Node, bool) {
if name, ok := in.(*ast.ColumnName); ok {
v.colNames = append(v.colNames, name.Name.O)
}
return in, false
}
func (v *colX) Leave(in ast.Node) (ast.Node, bool) {
return in, true
}
创建一个extract函数
extract
函数的作用是执行Accept
返回列名。
func extract(rootNode *ast.StmtNode) []string {
v := &colX{}
(*rootNode).Accept(v)
return v.colNames
}
修改Main函数进行调用
func main() {
astNode, err := parse("SELECT a, b FROM t")
if err != nil {
fmt.Printf("parse error: %v\n", err.Error())
return
}
fmt.Printf("%v\n", extract(astNode))
}
执行调用可以观察到 extract
可以把a,b两个列名给遍历出来。

当然我这只是遍历了字段名,你可以遍历ast tree
中想要的一切,例如FiledList
,DeleteStmt
等等。

如果你的visitor
中什么都不写,它就会把整个节点类型都遍历出来。
后记
整个Parse的过程就调试完了,其实也不难,就是需要抽一整断时间来学习,工作略忙,杂事很多,断断续续导致一个问题没研究清楚过了几个小时不知道调试到哪里去了。
重要说明
由于本人是DBA出身,非码农出身,实力水平有限。部分源码理解上可能存在偏差。三脚猫功夫还请见谅。
reference
https://pingcap.com/zh/blog/tidb-source-code-reading-5
https://asktug.com/t/topic/69253
https://zhuanlan.zhihu.com/p/165488348
