





一
引言
本次我们讨论的话题依旧和日常运维工作相关。首先试想一个场景:当我们需要在主从架构的MySQL上需要进行超大量的数据库变更,且停机实施窗口有限,在具体实施前可以在数据库上做哪些准备?通常会采取的办法之一就是在应用停机后,断开MySQL的主从复制,这样做的好处有两方面。一方面在主库执行大量事务的时候,无需等待从库返回ACK即可提交,降低对主库性能的影响;另一方面则是如果在变更期间出现问题,从库则保留了停机时完整的表结构和业务数据,便于回退和保证业务的正常运行。
在完成变更后,重新恢复主从连接,这时从库会根据主库生成的新增binlog补充变更产生的事务,主库可以直接为业务提供服务。但由于变更内容很多,主从间的差距很大,从库想要追平主库的变更内容尚且需要很久,倘若该业务的并发量又很高,主库会继续产生大量的新增日志,从库的追平时间会进一步被拉长。这时如果主库因为意外发生宕机,从库则会因为数据的不一致而无法提供服务,只能等待主库服务器的修复,继而对业务的连续性产生影响。
由此可以看出,如何提升主从复制的效率,是MySQL发展必须解决的问题之一。于是,多线程复制MTS应运而生。

MTS的发展历程
MySQL社区版从5.6开始引入多线程复制(enhanced multi-threaded slave)的功能,本以为会成为广大MySQL运维工程师的福音,结果是雷声大雨点小,5.6版本的MTS苛刻的条件让众人望而却步。原因在于5.6版本的MTS实现的主从间并行复制以库为单位,这就说明想要最好的发挥并行复制的效果,MySQL实例上面的库要足够多,所有表放在一个库内则完全无法并行复制;同时库与库之间的数据量要基本均匀,数据在库间的倾斜度过高一样无法达到理想的效率。这种严重脱离现实场景的要求显然无法为大众所接受,故MTS俨然成为了MySQL 5.6的鸡肋功能。
峰回路转,再看MySQL 5.7版本中的MTS则对原有的逻辑进行了巨大的调整,从参数设置上看,标识并行复制模式的参数slave_parallel_type从5.6的DATABASE模式改为了5.7的LOGICAL_CLOCK模式,该模式下的MTS拥有怎样的机制和优化?下文将逐一展开。
Binlog隐藏的信息--MTS分组标志
通常我们在解析查看binlog的时候,更多的会关注它所记录的事务内容、GTID信息、日志偏移量等等,但同时它也记录了MTS的分组信息。从下图中展示的binlog内容可以看到,每一个事务的binlog内容都有两个变量last_committed和sequence_number,前者表示被分配在一组且可以并行复制的事务,后者为标识每一个事务的独立序号。
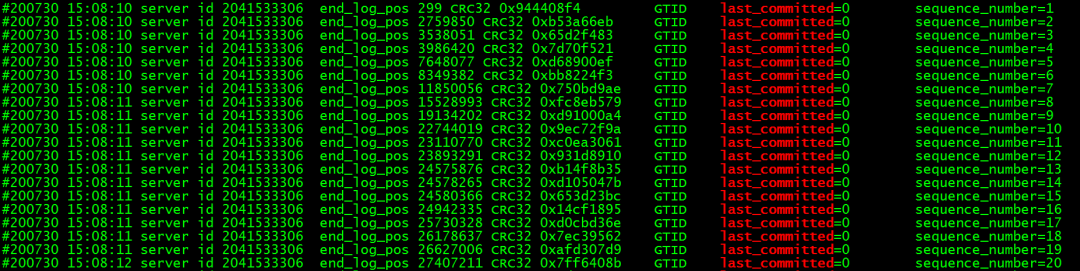
根据分组原则,处在同一组的事务拥有相同的last_committed值,表示它们可以进行并行复制,sequence_number则根据事务的先后顺序进行连续编号。分组时,当前组的last_committed值通常等于组内第一个事务(即组内sequence_number最小)的sequence_number-1,同时也等于上一个组的最后一个事务(即组内sequence_number最大)的sequence_number值。由于sequence_number值的生成从1开始,last_committed值从0开始,我们可以得到如下的分组示例:
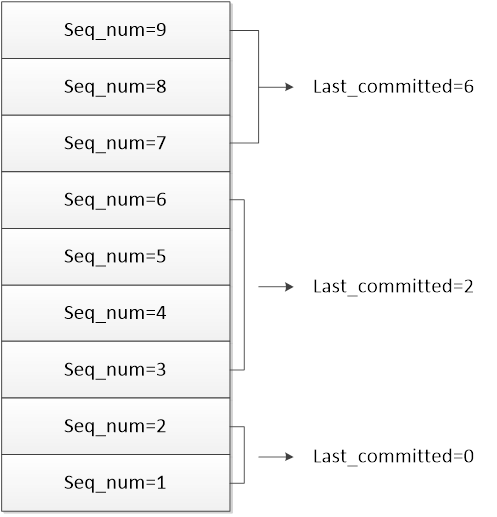
对从库来讲,可并行处理复制的线程数由变量slave-parallel-workers来控制。当从库接收到主库dump线程推过来的binlog后,会根据last_committed限定的组,对其中的每个事务逐一分配闲置的worker线程进行处理,进而完成并行复制。经过上文的分析,我们可以看出,真正决定MTS效率的点在于如何在binlog中对事务进行分组。用极限的思维想象,如果不考虑代码、硬件和网络资源的实际局限性,组内划分的事务数量足够多,且从库能够同时工作的worker线程也足够多,事务并行复制的效率将会非常大。下面我们就来看一下将事务进行分组、写日志以及最后提交的机制ordered commit。
ordered commit
MySQL的事务需要成功提交,会经历三个步骤,FLUSH、SYNC和COMMIT,每个步骤都会相应的维护一个队列,每个队列中处理的就是由last_committed来划分的一个组。为了便于观察,我们把图2中的事务按照提交步骤进行横向展开,如下图:
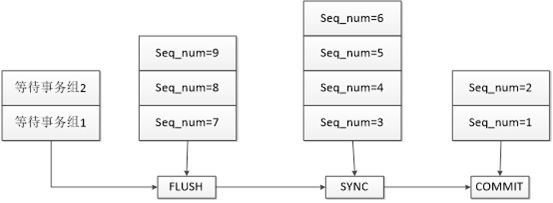
①起始状态时,三个队列都是空的。当有事务准备提交后,会首先进入FLUSH队列,此时第一个进入队列的则会成为队长,即sequence_number =1的事务,随后队长会等待一段时间,在这个时间内进入队列的都会成为这个组的成员,他们都拥有相同的last_committed值。FLUSH开始时,FLUSH缓冲区会被锁定,不允许其他事务再进入,随后从队长开始依次进行FLUSH,待FLUSH动作完成后由队长带领它们去进行下一个阶段的动作。
②当第一个组完成FLUSH操作后,FLUSH缓冲区则被清空,允许后面的事务进入去再次执行FLUSH。第一个组则进入SYNC阶段,在SYNC之前,会通知dump线程有新的binlog生成,从而让dump线程把新的binlog推送到从库。SYNC阶段就是把缓存中的binlog内容真正写入到磁盘中,生成最终的binlog日志。
③SYNC完成后,队列就进入最终的COMMIT阶段,在这个阶段MySQL会判断参数binlog_order_commits的值,如果为ON,则会按照进入队列的先后顺序进行依次提交。如果为OFF,则不会在这个阶段进行提交,而在后面由各个事务依次调用函数finish_commit进行独立提交
由上面步骤可以看出,整个ordered_committed的过程就像一个车间的生产线,每一个事务组都会经历生产线上的各个环节;在同一个时间点,各个不同的环节又在处理不同的事务组,整个流程有序进行。至于每个队列中的具体事务数量则与数据库提交时的压力有关,因为队长等待的时间其实很短,通常只有几秒钟,在这个时间段内数据库的压力越大,可能进入同一队列的事务数就越多,如图1所示,一个组内的事务数就有20个。当数据库压力较小且事务间间隔较长时,很可能每个事务都是一个队列中的队长,每阶段的队列操作也仅有一个事务而已。
ordered_committed函数源码解析
单纯只看上面的理论说明可能还是显得有些抽象,下面我们就结合源码来看一下ordered_committed的机制。
int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit)
ordered_committed的全部逻辑都在一个函数中,整个函数代码不过三四百行,但短小精悍,涵盖内容十分丰富。
① FLUSH STAGE
以下代码为第一个步骤flush的部分关键代码,为首的函数change_stage是一个比较重要的判断函数,后续代码也会多次调用,这个函数即为每次事务进入队列时判断该队列是否为空,如果队列可入且为空,此时进入的事务就会被定义为队列的队长,同时申请队列的锁,待flush开始时用于锁定队列
if(change_stage(thd,Stage_manager::FLUSH_STAGE, thd, NULL, &LOCK_log))
{
…
}
THD *wait_queue= NULL, *final_queue= NULL;
my_off_t flush_end_pos= 0;
bool update_binlog_end_pos_after_sync;
if (unlikely(!is_open()))
{
final_queue=stage_manager.fetch_queue_for(Stage_manager::FLUSH_STAGE);
leave_mutex_before_commit_stage= &LOCK_log;
goto commit_stage;
}
初始化入列的函数完成后,就是一些重要变量的定义,其中wait_queue和final_queue就是在提交过程中进行传递事务组的临时队列。flush_end_pos则代表刷新binlog产生的偏移量,初始为0。
下一个判断逻辑则以mysql server是否开启binlog为判断依据,如果binlog没有开启(MySQL认为这种场景发生的概率是很小的),则进行条件真值的执行逻辑,final_queue会通过状态管理类的队列获取函数传入当前在flush队列中的事务组,并直接跳过SYNC阶段(因为没有binlog可以落盘)转而去执行最后的innodb提交阶段。
flush_error= process_flush_stage_queue(&total_bytes,&do_rotate,&wait_queue);
if (flush_error == 0 && total_bytes > 0)
flush_error= flush_cache_to_file(&flush_end_pos);
update_binlog_end_pos_after_sync=(get_sync_period() == 1);
接下来就进行事务组的正式flush函数了,该函数将处理flush队列的结果返回给变量flush_error,并计算即将产生的binlog大小返回给total_bytes。下一个条件则进行函数结果的判断,当返回没有错误且即将生成的binlog长度不为0时,调用函数flush_cache_to_file进行内存刷入,该函数在此处并没有对binlog进行落盘,而是将内存中的binlog内容刷入操作系统缓存,并更新binlog的偏移量信息。
if (flush_error == 0)
{
…
if (!update_binlog_end_pos_after_sync)
update_binlog_end_pos();
}
flush步骤的最后,再次进行刷新结果的判断和binlog偏移量更新结果的判断,条件全部符合后,就调用函数update_binlog_end_pos,这个函数内部封装了一个signal_update函数,此函数则会向外通知主库有新的binlog产生(其实通知的就是从库),以次来唤醒dump线程进行binlog的推送。此处的代码也印证了新生成的binlog是由主库push给从库的,而不是从库主动来拉取的。
②SYNC STAGE
if(change_stage(thd,Stage_manager::SYNC_STAGE, wait_queue, &LOCK_log, &LOCK_sync))
{
…
}
final_queue=stage_manager.fetch_queue_for(Stage_manager::SYNC_STAGE);
if (flush_error == 0 && total_bytes > 0)
{
std::pair<bool,bool> result= sync_binlog_file(false);
sync_error= result.first;
}
if (update_binlog_end_pos_after_sync)
{
if (flush_error == 0 && sync_error == 0)
update_binlog_end_pos(tmp_thd->get_trans_pos());
}
有了前面对于flush步骤的说明,更简短的sync步骤就很直观了。步骤开始也是调用change_stage对sync队列进行一个入队和加锁的操作,随后通过状态管理类去获取需要做sync的事务组并赋给final_queue。随后依然进行flush结果和binlog生成量的判断,符合条件后就调用函数sync_binlog_file对操作系统缓存中的binlog进行实打实的落盘。最后进行flush和sync两阶段返回结果的同时判断,全部条件符合后,根据事务顺序更新binlog偏移量。至此SYNC阶段全部完成。
③COMMIT STAGE
if (opt_binlog_order_commits &&(sync_error == 0 || binlog_error_action != ABORT_SERVER))
{
if(change_stage(thd,Stage_manager::COMMIT_STAGE,final_queue,leave_mutex_before_commit_stage,&LOCK_commit))
{
…
}
THD*commit_queue=stage_manager.fetch_queue_for(Stage_manager::COMMIT_STAGE);
process_commit_stage_queue(thd,commit_queue);mysql_mutex_unlock(&LOCK_commit);
process_after_commit_stage_queue(thd, commit_queue);
final_queue= commit_queue;
}
else
{
if (leave_mutex_before_commit_stage) mysql_mutex_unlock(leave_mutex_before_commit_stage);
if (flush_error == 0 && sync_error == 0) sync_error= call_after_sync_hook(final_queue);
}
(void) finish_commit(thd);
}
上文就是commit阶段的部分关键代码,为了便于查看整体代码架构,此处不做拆分解读。该部分代码的主体架构就是一个比较大的if判断,条件判断中的主要依据就是变量binlog_order_commits,该变量是在global variables中可调整的变量。当该变量为on时,队长会代表队列中的所有事务进行依次提交;当该变量为off时,队列中的事务不会依从队长的提交要求,而是分别进行各自的提交。Binlog_order_commits=on分支的代码主体部分首先还是调用change_stage对commit队列进行初始化操作,随后获取需要做提交的事务组并放入commit_queue中,随后就调用函数process_commit_stage_queue对commit队列中的事务进行依次提交;binlog_order_commits=off的分支则没有对commit队列进行过多的操作,只是释放了队列的latch,以便于组内事务各自进行提交。最后的函数finish_commit内部则再次对binlog_order_commits进行判断,若为开启,则处理队列提交后的收尾工作;若为关闭,则分别处理各个事务在存储引擎的提交。此外finish_commit会完成事务提交成功或回滚后对GTID的更新操作,由于该部分与本文主旨无关,故不做继续展开。
三
结语
通过上文流程和源码的分别说明,相信各位读者对MySQL 5.7的MTS功能已经有了一个比较清晰的了解。有了MTS的助力,高负载下的主从延迟问题得到了显著的解决。更加可喜的是,MySQL在8.0的版本中对MTS的效率又有了进一步的改进和提升,这一部分内容有机会将在其他的文章中再做分享。
作者介绍:
曹啸:民生银行信息科技部DBA,目前主要致力于各类数据库运维,MySQL源码及新型数据复制工具研究等工作。在银行科技行业工作多年,兼具开发及运维工作经验,同时对银行多个业务领域亦有涉猎。
王健:2011年加入民生银行科技部,数据库管理员(负责DB2,Oracle,MySQL等运维工作,对MPP等数据库有很长的维护和实施经验,擅长数据迁移等等),同时负责行内KAFKA集群运维和实施工作,负责行内数据库实时复制等工作。
胡吉铭:民生银行信息科技部DBA,拥有十余年数据备份恢复领域经验,近期主要致力于数据库容器化工作。


编辑:民生运维文化建设组
