




1. 什么是Kafka Connect?
Kafka Connect, an open source component of Apache Kafka®, is a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems.
Kafka Connect是Apache Kafka®的一个开源组件,是一个用于将Kafka与外部系统(如数据库、键值存储、搜索索引和文件系统)连接的框架。Kafka Connnect有两个核心概念:Source和Sink。Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。
KafkConnect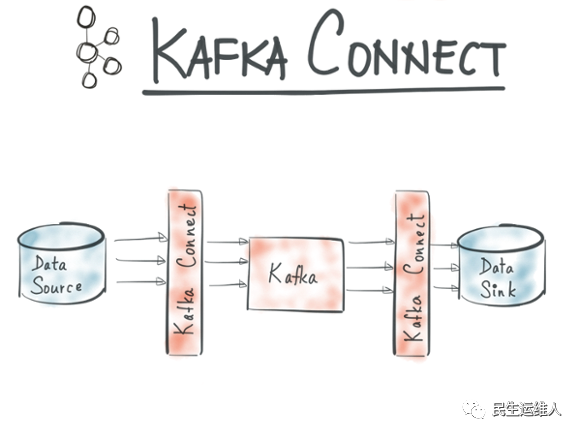
Kafka Connect包括如下特性:
Kafka connector通用框架,提供统一的集成API
同时支持分布式模式和单机模式
REST 接口,用来查看和管理Kafka connectors
自动化的offset管理,开发人员不必担心错误处理的影响
分布式、可扩展
流/批处理集成
2.当前已有Connector总结
如果开发人员通过producer/consumer API写了一些导入导出的功能,可以考虑尝试换成Kafka Connector,会简化代码,提高应用可扩展和容错的能力。Kafka背后的公司Confluent鼓励社区创建更多的开源的Connector,将Kafka生态圈扩大,促进Kafka Connect的应用。另外在Kafka Connect框架的支持下,我们还可自定义开发Connector,关于如何开发一个定制的Connector,可参考《Connector Developer Guide》。当前已有的Connector包括(涉及到常用开源产品,截至2020年8月18日,从Confluent官网上统计,https://www.confluent.io/hub/):
| Connector Name | Plugin type | Author | License |
|---|---|---|---|
| Kafka Connect HDFS3 | Sink | Confluent, Inc. | Confluent Software Evaluation License |
| Kafka Connect HDFS 3 Source | Source | Confluent, Inc. | Confluent Software Evaluation License |
| Kafka Connect HDFS 2 Source | Source | Confluent, Inc. | Confluent Software Evaluation License |
| Kafka Connect HDFS | Sink | Confluent, Inc. | Confluent Community License |
| Kafka Connect JDBC | Source/Sink | Confluent, Inc. | Confluent Community License |
| Debezium MySQL CDC Connector | Source | Debezium Community | Apache License 2.0 |
| Debezium PostgreSQL CDC Connector | Source | Debezium Community | Apache License 2.0 |
| Debezium MongoDB CDC Connector | Source | Debezium Community | Apache License 2.0 |
| Kafka Connect Elasticsearch | Sink | Confluent, Inc. | Confluent Community License |
| Kafka Connect Apache HBase Sink Connector | Sink | Confluent, Inc. | Confluent Software Evaluation License |
| Kafka Connect HBase Sink | Sink | Nishu Tayal | Apache License 2.0 |
| MongoDB Connector for Apache Kafka | Source/Sink | MongoDB | Apache License 2.0 |
| Kafka Connect InfluxDB | Source/Sink | Confluent, Inc. | Confluent Community License |
| Kafka Connect Redis | Sink | Jeremy Custenborder | Apache License 2.0 |
3.Kafka Connect重要概念
Kafka connect的几个重要的概念包括:
Connectors: 通过管理任务来协调数据流的高级抽象(一个Connector实例是一个逻辑Job,这个逻辑Job就是负责管理Kafka和其他系统之间数据的拷贝) Tasks: 数据写入kafka和数据从kafka读出的实现 Workers: 运行connectors和tasks的进程(一个Worker里可以运行多个Connector实例,每个Connector实例里会把一个Job分成多个Task) Converters: kafka connect和其他存储系统直接发送或者接受数据之间转换数据 Transforms**: 用在connect消费或者产生的记录上的简单转换逻辑** Dead Letter Queue: Connect如何处理connector错误,使用Sink Connector时用到
对于这里的Connector和上个章节中提到的Connector这里需要区分,实现Connector实例或者Connector实例需要使用的类都是定义在Connector Plugin里的,上个章节中实际指的是Connector plugin。Connector实例和Connector Plugin都可以都可以被称为“Connectors”,但可以从上下文中可以区分,例如,“安装Connector”是指Connector Plugin,“检查Connector的状态”指Connector实例。
4.Kafka Connect工作模式
Kafka Connect的工作模式分为两种,分别是standalone模式和distributed模式。
4.1 Standalone Workers
在standalone模式中,所有的工作都在一个独立的Worker进程中完成,比较简单,适合开发环境,但是由于只有一个进程,不具备容错性。
Standalone Worker启动的命令很简单,如下:
USAGE: ./connect-standalone.sh [-daemon] connect-standalone.properties
4.2 Distributed Workers
分布式模式为Kafka Connect提供了可扩展性和自动容错能力。在分布式模式下,可以启动多个Workers,这些Worker采用相同的group.id,通过自动协调(类似Consumer Group的协调均衡机制),在多个Workers之间调度执行connectors和tasks。如果增加Worker,关闭Worker或某个Worker进程意外失败,其他Workers将会检测到这种变化进行rebalance,重新分配connectors以及tasks。下图展示了一个Worker发生故障后,Task如何进行故障转移:
task-failover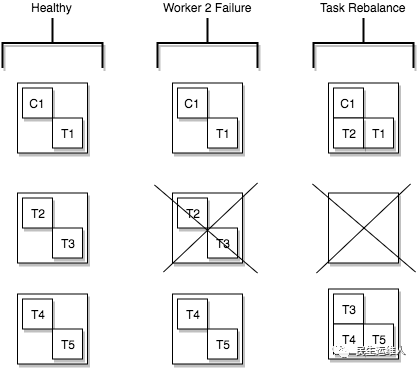
Distributed Worker启动命令如下:
USAGE: ./connect-distributed.sh [-daemon] connect-distributed.properties
5. Distributed模式下启动流程分析
根据connect-distributed.sh启动脚本,我们发现入口类是ConnectDistributed:
#Distribute Worker的入口类是ConnectDistributed
exec $(dirname $0)/kafka-run-class.sh $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectDistributed "$@"
以下是启动的核心代码:
/**
* Connect启动函数
* @param workerProps Worker的配置文件
* @return
*/
public Connect startConnect(Map<String, String> workerProps) {
log.info("Scanning for plugin classes. This might take a moment ...");
//1.扫描plugin.path路径,加载插件
Plugins plugins = new Plugins(workerProps);
plugins.compareAndSwapWithDelegatingLoader();
DistributedConfig config = new DistributedConfig(workerProps);
//2.获取Kafka集群ID
String kafkaClusterId = ConnectUtils.lookupKafkaClusterId(config);
log.debug("Kafka cluster ID: {}", kafkaClusterId);
//3.创建一个RestServer,并启动,hostname是rest.advertised.host.name指定,
// port是rest.advertised.port指定,默认端口是8083,这个rest是供其他worker或者客户端调用
// workerId就是有host:port指定
RestServer rest = new RestServer(config);
rest.initializeServer();
URI advertisedUrl = rest.advertisedUrl();
String workerId = advertisedUrl.getHost() + ":" + advertisedUrl.getPort();
//4.KafkaOffsetBackingStore用于管理offset,需要设置offset.storage.topic,否则会报错
KafkaOffsetBackingStore offsetBackingStore = new KafkaOffsetBackingStore();
offsetBackingStore.configure(config);
//5.client端参数能否被connector里参数覆盖,设置connector.client.config.override.policy参数,默认是NONE,还可以选All,Principal
ConnectorClientConfigOverridePolicy connectorClientConfigOverridePolicy = plugins.newPlugin(
config.getString(WorkerConfig.CONNECTOR_CLIENT_POLICY_CLASS_CONFIG),
config, ConnectorClientConfigOverridePolicy.class);
//6.worker初始化
Worker worker = new Worker(workerId, time, plugins, config, offsetBackingStore, connectorClientConfigOverridePolicy);
WorkerConfigTransformer configTransformer = worker.configTransformer();
//获取InternalValueConverter(参数internal.value.converter)的值,初始化StatusBackingStore
Converter internalValueConverter = worker.getInternalValueConverter();
//7.初始化StatusBackingStore,connector和task的状态信息存在status.storage.topic这个Topic里
StatusBackingStore statusBackingStore = new KafkaStatusBackingStore(time, internalValueConverter);
statusBackingStore.configure(config);
//8.初始化ConfigBackingStore,需要获取参数config.storage.topic的值,connector的配置信息存在config.storage.topic这个Topic里
ConfigBackingStore configBackingStore = new KafkaConfigBackingStore(
internalValueConverter,
config,
configTransformer);
//9.初始化herder,这个类非常关键,和其他Worker进行协调工作,类似一个Consumer Group,
// Coordinator会分配任务(connector和task)给它(RoundRobin)
DistributedHerder herder = new DistributedHerder(config, time, worker,
kafkaClusterId, statusBackingStore, configBackingStore,
advertisedUrl.toString(), connectorClientConfigOverridePolicy);
//10.初始化connect
final Connect connect = new Connect(herder, rest);
log.info("Kafka Connect distributed worker initialization took {}ms", time.hiResClockMs() - initStart);
try {
//11.connect真正启动的入口
connect.start();
} catch (Exception e) {
log.error("Failed to start Connect", e);
connect.stop();
Exit.exit(3);
}
return connect;
}
以下是Kafka Connect启动流程的展示,包括和ConnectDistributed关联的类的关系:
Kafka Connect启动流程
接下来,我们将对上述流程中的重点步骤和类进行详细分析:
5.1 步骤1,扫描plugin.path,加载Connector插件
Plugins初始化时,将Worker的配置传给该类的构造函数,构造函数中首先会提取plugin.path的配置,这个配置的值是以逗号分隔的目录列表,指向Connector/Converters/Transforms Plugin的jar包及其依赖等文件目录。涉及到的代码如下:
public Plugins(Map<String, String> props) {
//提取配置中plugin.path的值
List<String> pluginLocations = WorkerConfig.pluginLocations(props);
delegatingLoader = newDelegatingClassLoader(pluginLocations);
delegatingLoader.initLoaders();
}
然后遍历这个插件路径,加载插件:
protected void initLoaders() {
for (String configPath : pluginPaths) {
initPluginLoader(configPath);
}
// Finally add parent/system loader.
initPluginLoader(CLASSPATH_NAME);
addAllAliases();
}
5.2 步骤3,构造一个Rest Server
RestServer内置了一个Jetty Server,用于接收其他Worker或客户端的请求。关于Rest Server监听的hostname和port相关的配置参数出现了多个,但是在Kafka源代码中提供的配置示例connect-dstiributed.properties中都未列明这些参数,先来看看rest.host.name和rest.port,这两个参数目前在代码里是被 标识被弃用,暂时可用:
/**
* @deprecated As of 1.1.0.
*/
@Deprecated
public static final String REST_HOST_NAME_CONFIG = "rest.host.name";
private static final String REST_HOST_NAME_DOC
= "Hostname for the REST API. If this is set, it will only bind to this interface.";
/**
* @deprecated As of 1.1.0.
*/
@Deprecated
public static final String REST_PORT_CONFIG = "rest.port";
private static final String REST_PORT_DOC
= "Port for the REST API to listen on.";
public static final int REST_PORT_DEFAULT = 8083
这两个参数是代表REST API监听哪个网络接口,可以用参数listeners代替:
public static final String LISTENERS_CONFIG = "listeners";
private static final String LISTENERS_DOC
= "List of comma-separated URIs the REST API will listen on. The supported protocols are HTTP and HTTPS.\n" +
" Specify hostname as 0.0.0.0 to bind to all interfaces.\n" +
" Leave hostname empty to bind to default interface.\n" +
" Examples of legal listener lists: HTTP://myhost:8083,HTTPS://myhost:8084";
如果使用者按照样例文件配置成如下:
#rest.host.name=
#rest.port=8083
那么会将listeners设置为HTTP://:8083,相应的代码在如下位置:
@SuppressWarnings("deprecation")
List<String> parseListeners() {
//由于listeners未设置,那么这里返回null
List<String> listeners = config.getList(WorkerConfig.LISTENERS_CONFIG);
if (listeners == null || listeners.size() == 0) {
//由于rest.host.name未设置,这里返回null
String hostname = config.getString(WorkerConfig.REST_HOST_NAME_CONFIG);
if (hostname == null)
hostname = "";
//这里listeners=[HTTP://:8083],默认的rest.port是8083
listeners = Collections.singletonList(String.format("%s://%s:%d", PROTOCOL_HTTP, hostname, config.getInt(WorkerConfig.REST_PORT_CONFIG)));
}
return listeners;
}
除了上述参数,还有rest.advertised.host.name、rest.advertised.port、rest.advertised.listener这些参数,
这些参数是用于Worker之间通信的hostname和端口。
5.3 步骤4、7、8,三个BackingStore
为了保存Connector和Task的信息,启动Connect之前需要先建立3个Topic,分别由参数offset.storage.topic、status.storage.topic和config.storage.topic指定,这些Topic设置时需要注意,清理策略需要设置为compact,否则如果设置为delete可能会因为大小或时间的原因,Topic里的数据被清理掉。另外为了保证读取config信息是有序的,config.storage.topic指定的Topic必须是单分区。
上述3个Topic的读取和写入分别由KafkaOffsetBackingStore、KafkaStatusBackingStore、KafkaConfigBackingStore管理,这三个类中均有一个KafkaBasedLog的实例,在每个实例中,包含一个Consumer实例(读取offset/status/config信息),一个Producer实例(往Topic中写入offset/status/config信息),以及一个线程WorkThread,该线程一直在消费对应Topic中的消息。
这里需要注意一个offset提交方式,在Worker启动时,会构造一个SourceTaskOffsetCommiter类,一个Worker会统一对其管辖范围内SourceTask的offset提交,这个功能就是由SourceTaskOffsetCommiter类提供。
/**
* Start worker.
*/
public void start() {
log.info("Worker starting");
offsetBackingStore.start();
//构建一个SourceTaskOffsetCommiter,只针对SourceTask
sourceTaskOffsetCommitter = new SourceTaskOffsetCommitter(config);
connectorStatusMetricsGroup = new ConnectorStatusMetricsGroup(metrics, tasks, herder);
log.info("Worker started");
}
offset提交是定时的,由参数offset.flush.interval.ms指定,默认值是60000L,即Task启动后,每1分钟提交一次offset。
public void schedule(final ConnectorTaskId id, final WorkerSourceTask workerTask) {
long commitIntervalMs = config.getLong(WorkerConfig.OFFSET_COMMIT_INTERVAL_MS_CONFIG);
ScheduledFuture<?> commitFuture = commitExecutorService.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try (LoggingContext loggingContext = LoggingContext.forOffsets(id)) {
commit(workerTask);
}
}
}, commitIntervalMs, commitIntervalMs, TimeUnit.MILLISECONDS);
committers.put(id, commitFuture);
}
6.参考文档:
http://kafka.apache.org/documentation.html#connect
https://www.confluent.io/blog/announcing-kafka-connect-building-large-scale-low-latency-data-pipelines/
https://docs.confluent.io/current/connect/
作者介绍:
文乔:2012年硕士毕业后加入民生银行生产运营部系统管理中心,天眼日志平台主要参与人,目前在开源软件支持组负责Flume、Kafka的源码研究和工具开发等相关工作。微信tinawenqiao,邮箱wenqiao@cmbc.com.cn。
王健 :2011年加入民生银行科技部,数据库管理员(负责DB2,Oracle,MySQL等运维工作,对MPP等数据库有很长的维护和实施经验,擅长数据迁移等等),同时负责行内KAFKA集群运维和实施工作,负责行内数据库实时复制等工作。
李腾:2019年加入民生银行信息科技部,DBA,主要负责行内KAFKA相关运维工作。

