





背景和现象
为了监控AIX和HP操作系统中的日志Agent是否Active,我行采用Flume采集Agent心跳文件并上送到Kafka,心跳文件内容示例如下:
AGENT_IP:197.3.XX.XX
AGENT_PROCESS_NUM:0
AGENT_PROCESS_PID: 6590
AGENT_USE_CPU_PERCENT(1 core):0.0
AGENT_USE_RAM(M):3.91
AGENT_USE_STORAGE(M):1682.06
HOST_NAME:XXXX
OS_TYPE:AIX
OS_ARCH:PowerPC_POWER7
OS_VERSION:7.1
VM:lpar
AGENT_MEMORY_PERCENT:0.0
date:Mon Feb 24 14:30:03 BEIST 2020
心跳文件生成方法:我们在每个采集端增加了一个脚本,该脚本每分钟获取Agent的OS相关信息(以下简称心跳信息)写入到文件/home/logger/agent.sh.tmp中,1分钟后将文件mv到目录/home/logger/tmp/目录下并重命名为agent.sh.tmp.{TimeStamp},同时在/home/logger/目录下再生成一个名字为agent.sh.tmp的文件,并写入心跳信息。但是生产上发现Flume Agent会偶尔采集不到心跳文件内容,且无规律。
Flume相关配置信息如下:
agent.sources.rAGE.type = org.apache.flume.source.taildir.TaildirSource
agent.sources.rAGE.filegroups = fAGE
agent.sources.rAGE.filegroups.fAGE.parentDir = home/logger/
agent.sources.rAGE.filegroups.fAGE.filePattern = agent.sh.tmp
agent.sources.rAGE.headers.fAGE.type = am_agent
agent.sources.rAGE.positionFile = home/logger/flumeAgent/apache-flume-1.7.0-bin/conf/agent_tailPosition.json
agent.sources.rAGE.skipToEnd = true
agent.sources.rAGE.multiline = true //使用了多行合并功能
agent.sources.rAGE.multilinePattern = ^AGENT_IP:
agent.sources.rAGE.multilinePatternBelong = previous
agent.sources.rAGE.multilineMatched = false
agent.sources.rAGE.multilineMaxBytes = 3145728
agent.sources.rAGE.multilineMaxLines = 3000
agent.sources.rAGE.multilineEventTimeoutSeconds = 30
agent.sources.rAGE.cachePatternMatching = false
agent.sources.rAGE.fileHeader = true
agent.sources.rAGE.fileHeaderKey = path
agent.sources.rAGE.interceptors = iAGE i1
agent.sources.rAGE.interceptors.iAGE.type = host
agent.sources.rAGE.interceptors.i1.type = timestamp
从上面配置文件agent.sources.rAGE.multiline = true可以看出,这里使用了自研的多行合并功能,多行合并功能是将文件中的多行合并输出为一个event,而原生Flume是不支持该功能的,只能做到将一行文件内容输出为一个event。我们生产上使用的TaildirSource组件是定制版,在Flume1.7基础上合并了自研的多行合并,递归子目录等功能,详细细节请参见文章《中国民生银行大数据团队的Flume实践》。
02
问题定位和原因分析
打开Flume的日志debug开关(该开关是通过修改start.sh脚本,将日志级别从ERROR改为DEBUG,即改为-Dflume.root.logger=DEBUG,LOGFILE,然后重启),发现丢失现象发生时,日志里没有输出心跳文件里的内容,我们怀疑是生成心跳文件的脚本有问题,后来通过agent.sh脚本输出心跳文件的内容排除该问题。排除文件内容异常问题后,我们开始跟踪Flume的debug信息,发现在TaildirSource的日志输出中未打印出文件内容,因此定位是TaildirSource组件的问题,而不是Channel和Sink组件的问题。
Flume里我们使用的是TaildirSource组件收集日志,该组件是用于实时监控采集多个文件,核心处理逻辑在process()函数中,该函数的作用是读取文件内容并封装成event,写入到channel中。process()函数的处理逻辑如下:
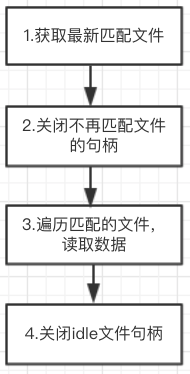
图1 Process()函数处理逻辑
通过debug日志分析,在执行到步骤3时,未读取数据,首先看一下这里的具体代码:
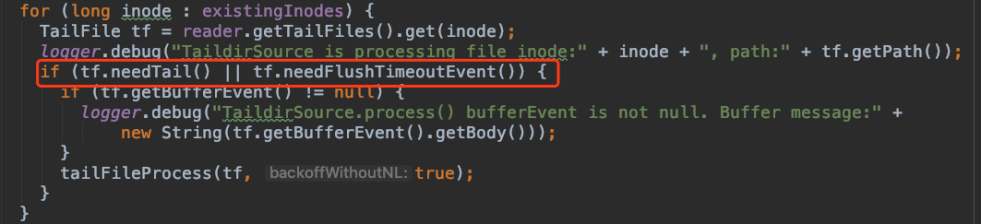
图2 读取文件数据的条件
当tf.needTail()为true或者tf.needFlushTimeoutEvent()为true时进入读取数据tailFileProcess()的逻辑。needTail()函数是判断文件是否有更新,needFlushTimeoutEvent()函数是判断是否有超时的缓冲区数据,在多行合并功能启用时有效,在该功能中我们设置了一个缓冲区存储已经合并的多行,并为这个缓冲区设置了一个超时时间,当缓冲区里的多行超过指定时间后,该函数返回为true,否则是false。因为一直没有读到数据,条件tf.needFlushTimeoutEvent()一直都是false,那么说明tf.needTail()也是false,才没有进入函数tailFileProcess(),那tf.needTail()为什么是false呢?
再查看needTail这个变量什么时候被设置为false。通过代码定位,发现只有一处会修改该变量的值,就是在ReliableTaildirEventReader.updateTailFiles()函数里,从注释中即可了解这个函数的作用是当新文件创建或者文件内容有追加时,更新匹配的文件信息,在上述流程图步骤1中会调用该函数:

图3 updateTailFiles的函数定义
接下来仔细分析updateTailFiles()函数中关于设置needTail变量处的的代码:
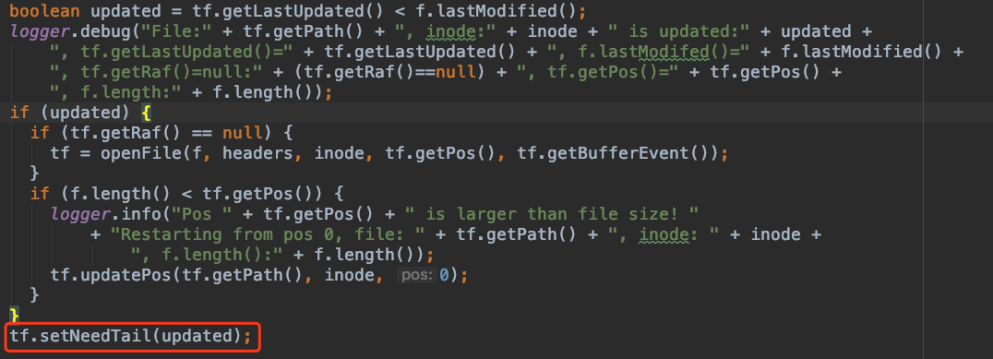
图4 needTail变量被更新逻辑
从上面代码可以看出,当文件lastUpdated的时间比文件被修改时间小,即文件从上次处理后若有被更新,那么updated变量会被设置为true, 进而needTail被设置为true,就是说需要读取文件,相反,needTail被设置为false,即文件没有被更新,不需要读取文件。也就是说这个lastUpdate变量比文件被修改时间小,造成了needTail设置为false,最后再来看一下lastUpdate变量在什么时候被修改。
经过代码定位,发现lastUpdate()在三处被调用:
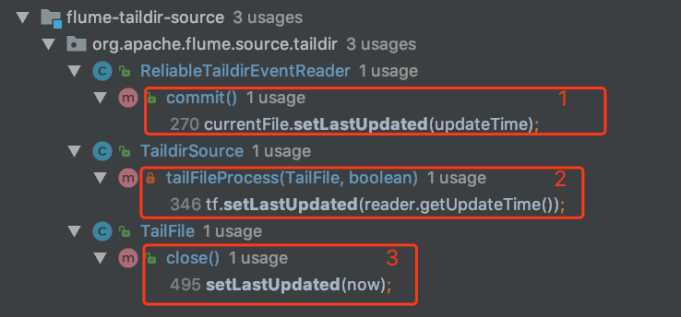
图5 lastUpdate变量被更新的三处逻辑
1. 读取数据封装成event写入channel之后;
2. 多行场景下,当缓冲buffer里有数据时;
3. 关闭文件句柄时,将lastUpdate设置为当前时间。
再结合我们的实际输出,发现在关闭文件句柄时,将lastUpdate设置为当前时间了,而这个时间比文件的最后修改时间要晚,即tf.lastUpdate>f.lastModified,因此needTail设置为false,从而认为文件没有更新内容,flume不再读取文件,而此后文件内容一直未再更新,所以出现数据丢失的情况。
上面是我们定位问题的倒推思路,为了更清楚的描述问题原因,我们根据时间发生的先后,展示lastUpdate变量的变化,说明丢数发生原因:
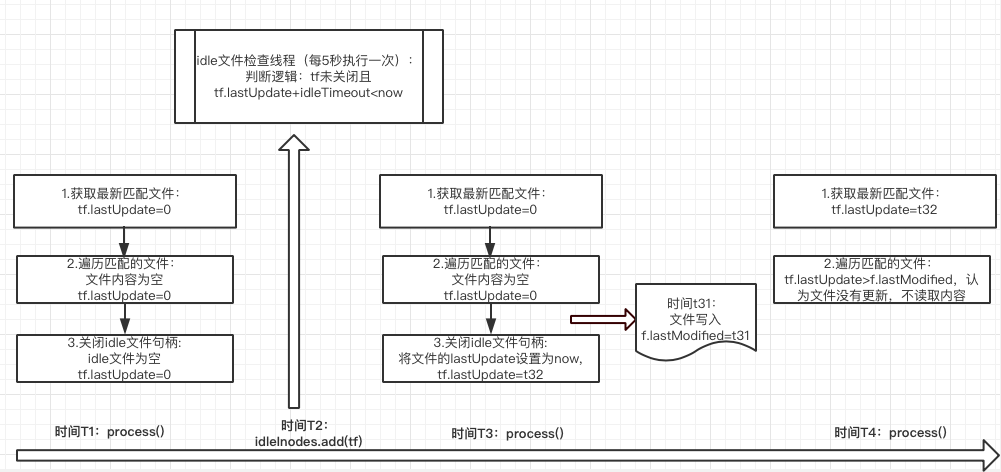
图6 根据时间先后,图示丢数问题发生原因
T1时刻:lastUpdate初始值为0,文件无内容追加,执行步骤2之后,文件不在空闲文件列表中,因此不执行关闭文件句柄close()操作,lastUpdate的值不变,仍是0;
T2时刻:idle文件检查线程执行,由于tf.lastUpdate+idleTimout < now,将该文件放入到空闲文件列表中;
T3时刻:步骤1执行完后lastUpdate仍然为0,执行步骤2时,文件仍然无内容追加,执行完步骤2之后的时刻t32文件开始追加内容(将13行心跳数据全部写入,那么文件的最后更新时间lastModified是t32),再之后运行到步骤3,由于此时文件在空闲文件列表中,因此进入到关闭文件句柄close的操作中,将lastUpdate设置为t32;
T4时刻:执行到步骤3,根据tf.lastUpdate=t32 > f.lastModified,因此认为文件没有更新,不读取文件内容,而此后文件也一直未更新。
03
解决方案和效果
在释放句柄close()函数中增加判断,如果是多行的情况下,不更新lastUpdate变量,而不是多行的情况下,仍保留原生代码里的逻辑。
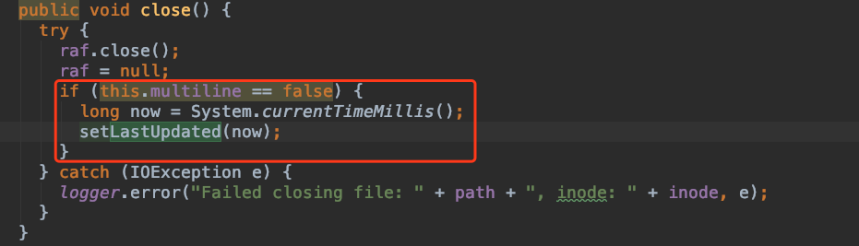
图7 修改关闭文件句柄的逻辑
另外是在process()逻辑中,在读取文件数据的条件中增加一个条件,记录的文件读取位置比文件的长度要小时,也可以进入读取数据的函数tailFileProcess()。
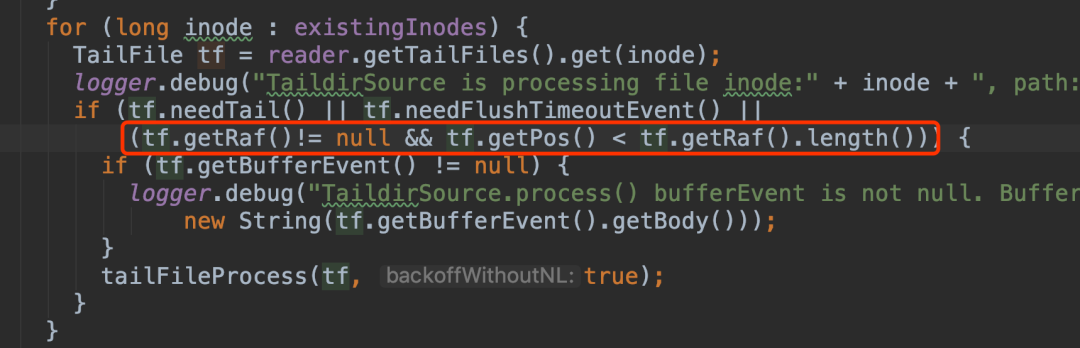
图8 修改进入读取文件的条件
在更新上述逻辑后,重新编译部署在生产部分机器上,丢数问题不再出现。
04
提出猜想
提出猜想:为什么Flume 1.7原生代码里在释放句柄的时候要把文件lastUpdate设置为当前时间,是否也会丢数?
我们先来看一下原生代码里,关于lastUpdate这个变量是如何更新的:
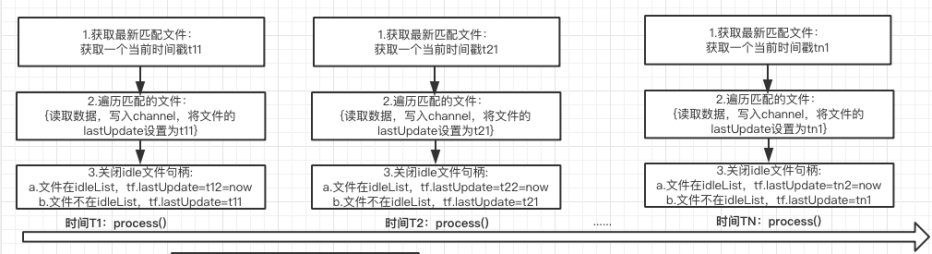
图9 原生Flume中lastUpdate更新流程
TaildirSource中循环执行process()函数,在process()函数中,首先获取匹配文件,这时候会记录一个时间戳tn,接下来遍历文件的时候,读到数据后封装成event写入channel,会将文件的lastUpdate设置为tn,最后关闭空闲文件句柄时,若文件在空闲文件列表idleList中,lastUpdate会设置成当前时间,否则lastUpdate仍为tn。
但是如果发生类似我们丢数时发生的场景(下图10示例),在步骤2之后,有文件出现追加,即文件的最后更新时间f.lastModified=tx < t2,但是在步骤3之后文件内容不再更新,那么flume根据逻辑tf.lastUpdate > f.lastModified判断文件没有被更新,因此在时间tx追加的数据不会被读取,除非文件在之后有内容追加使得f.lastModified>tf.lastUpdate。因此笔者推测在某些情况下,原生Flume在处理数据时仍会出现丢数的问题。
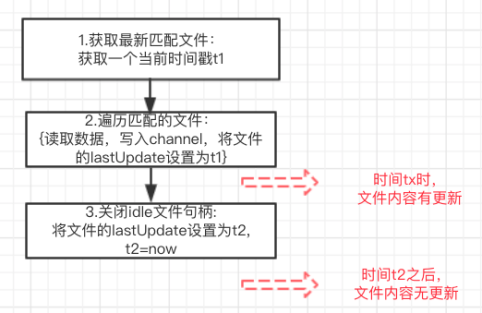
图10 丢数场景
有读者可能会疑惑,文件在tx时间更新,那么根据空闲文件的定义,进入步骤3时,该文件不应该在空闲文件列表idleList中,那么就不会进入到关闭文件句柄的close()函数中,这可能是Flume官方的处理逻辑。也就是说在步骤3时,不应该放在空闲文件列表中的文件被放进去了,这跟idle文件检查线程有关,它是单独的线程,定时每5秒执行一次,步骤3时获取到的idleList并不是最新的数据,会导致可能刚刚更新的文件也被放了空闲文件列表idleList中。
那这块在close()函数中设置lastUpdate逻辑能否去掉?笔者认为是可以的,因为Flume读取到文件的具体哪个位置是用pos变量记录的,这个lastUpdate作用是为了大致判断文件是否更新,为了验证该想法,在删除这块逻辑后运行TaildirSource所有的test,的确也是可以通过的。另外我们有个疑问,为什么不直接用pos位置和文件长度相比较来判断文件是否更新,我们猜想是在某些情况下,例如文件空闲后关闭句柄,无法得知文件长度,因此无法仅仅凭此判断文件是否更新。
05
猜想得到验证
在整理第一季度缺陷报告时,我们发现了Flume社区的一个Issue(Flume-3083:Taildir source can miss events if file updated in same second as file close.),证明了我们的猜想是对的,原生Flume1.7上是会丢数的,且该Issue提出人和我们的分析一致。为了更靠近社区以及考虑未来升级的问题,我们将自己Fix的一版代码进行了修改,并已经过测试环境验证后部署到生产环境。最新代码已在github上开源,欢迎大家和我们探讨交流https://github.com/tinawenqiao/flume/tree/trunk-cmbc。

文乔
2012年硕士毕业后加入民生银行生产运营部系统管理中心,天眼日志平台主要参与人,目前
在开源软件支持组负责Flume、Kafka的源码研究和工具开发等相关工作。微信tinawenqiao,邮箱wenqiao@cmbc.com.cn。


作者:文乔
编辑:民生文化建设小组
