




不管是在关系型还是非关系型数据库中,查询语句的优化在数据库的的优化中占了很大比例。在Oracle中,通过性能视图,可以获取TOPSQL,而在Mysql、PG、Mongodb这些稍小型的数据库中,均只能通过设置慢查询阈值的方式,获取慢SQL。在Mysql中,慢日志有独立的慢日志文件,而PG和Mongo中慢日志都是输出到数据库的运行日志里面。在Mongodb中,数据库在输出慢日志的同时会显示语句执行时的执行计划。
Mongodb慢日志通过如下参数设置:
operationProfiling: mode: slowOp --表示抓取慢查询
slowOpThresholdMs: 200 --抓取执行时间超过200ms的查询
也可以在实例启动后,在数据库层动态的设置慢查询阈值db.setProfilingLevel(1,{ slowms: 200 })。
设置之后,在当前数据库中会产生一个名为system.profile的集合,该集合是一个capped集合,固定大小为1MB,当超过1MB后,会自动覆盖旧数据。使用showprofile可以显示最近的5条慢查询记录以及语句的执行计划。
同时,在配置了慢查询阈值后,mongodb会在运行日志中打印出慢日志,如下: 2020-09-27T01:22:41.310+0800 I WRITE [conn5161055] update res***ce.Resour****gLog command: { q: { _id: ObjectId('5f6f78***d49c') }, u: { _class: "cn.migu.music.re***rce.model.Res**HandingLog", _id: ObjectId('5f6f7 8e126deb942317dd49c'), syncId: "173758523", resourceId: "1115439752", type: "ml_song_material", originalStatus: "1", doneStatus: "0", lastModifiedTime: new Date(1601140961092) }, multi: false, upsert: true } planSummary: IDHACK keysEx amined:1 docsExamined:1 nMatched:1 nModified:1 keysInserted:3 keysDeleted:3 numYields:1 locks:{ Global: { acquireCount: { r: 4, w: 4 } }, Database: { acquireCount: { w: 4 } }, Collection: { acquireCount: { w: 3 } }, oplog: { acquireCo unt: { w: 1 } } } 221ms 2020-09-27T01:22:41.310+ |
由于在Mongodb中没有绑定变量的概念,所以当业务大量执行慢查询时,system.profile集合中存不了多少数据,且可能大都是不同变量的相同语句,同时在数据库运行日志中会出现慢查询刷屏的现象。在这种情况下,建议使用mtools工具的mloginfo对慢查询进行分析和过滤,结果如下:
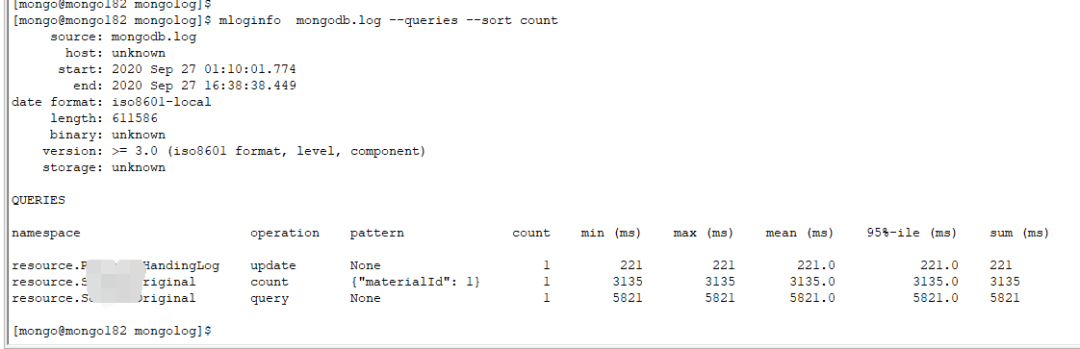
该工具会按照查询条件进行分组统计,相当于oracle的绑定变量,输出结果直观明了。
基本在所有的数据库中,都可以使用explain查看语句的执行计划,Mongodb也不例外,其用法为db.collectionname.find({field_name:***}).explain();
例如:
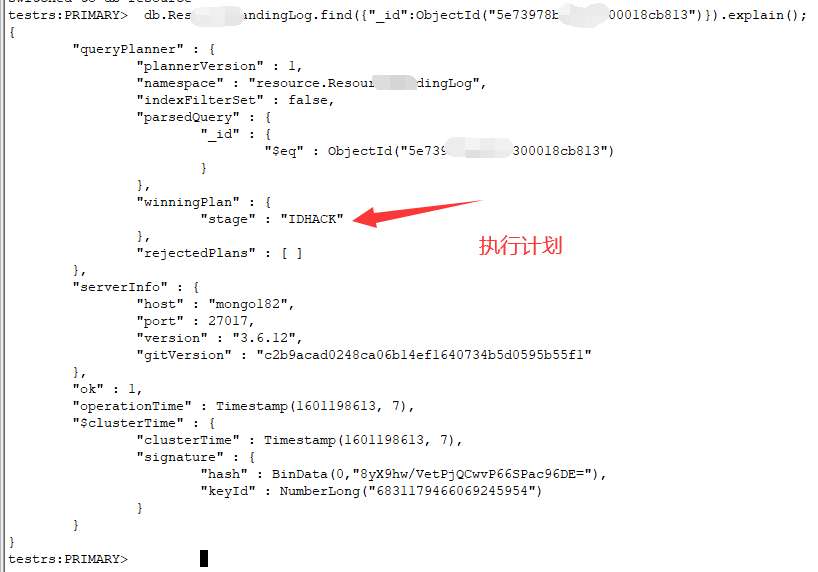
同时也可以使用
db.collectionname.explain().find({field_name:***}).其中,explain支持如下3种模式:
db.Text.explain("queryPlanner").find({"txtId":"5855"});--只生成执行计划,默认模式
db.Text.explain("executionStats").find({"txtId":"5855"});--生成执行计划并执行,显示被拒绝的执行计划,同时显示执行的统计信息
db.Text.explain("allPlansExecution").find({"txtId":"5855"});--包含以上两种模式,并且显示在生成执行计划时被拒绝的执行计划的统计信息,有点类似Oracle10053 event.
对于update和delete等写操作,在explain()时会被执行,但是结果不会应用到数据库。
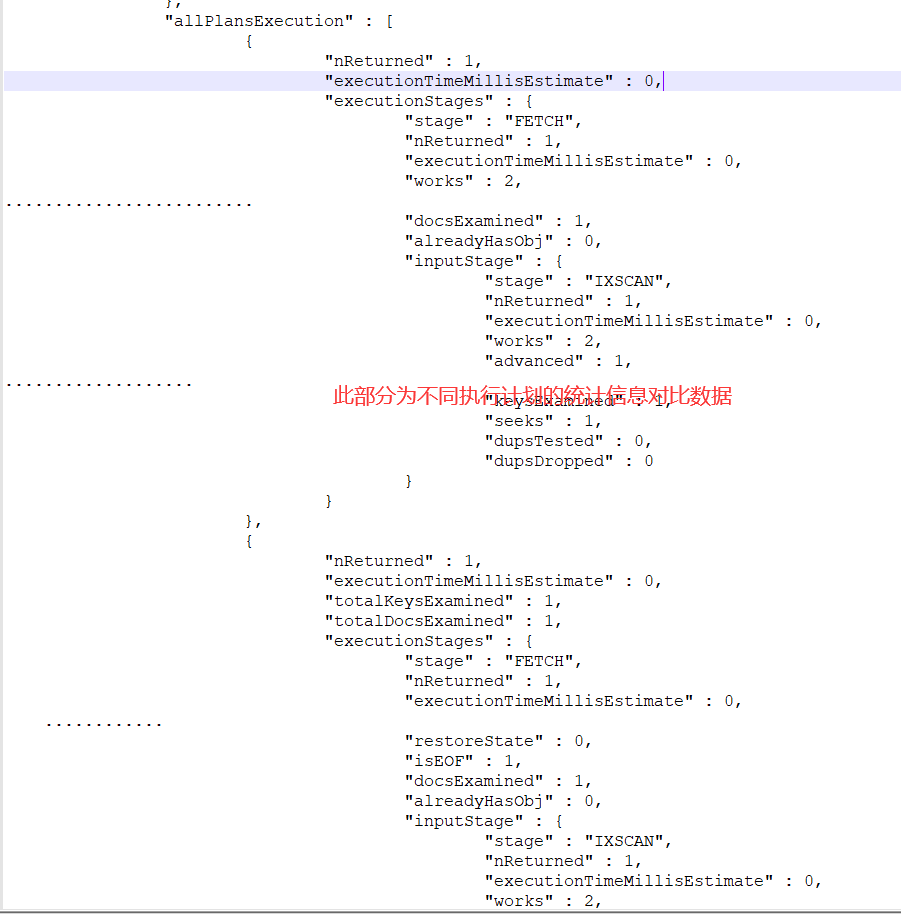
示例(此处不描述输出的各行信息的意思):

Mongodb的执行计划包括全表扫描(COLLSCAN)、索引扫描(IXSCAN)、分片合并(SHARD_MERGE)、_ID过滤(IDHACK),因为_ID列上有一个特殊的唯一索引,所以一般情况下来说如果语句的执行计划是IDHACK,无疑该执行计划是最优的。
