




Oracle云基础设施 (OCI) Vision正式发布,这是一种计算机视觉服务,可让客户在由深度学习模型支持的非结构化图像中发掘信息。
OCI Vision是一种Serverless的云原生服务,可通过REST API 提供基于深度学习预构建的和自定义的计算机视觉模型。OCI Vision 可帮助我们识别和定位对象、提取文本,并从收据等业务文档中识别表格、文档类型和键值对等。无需数据科学经验即可使用OCI Vision的预构建或自定义功能。
我们可以通过 Oracle Cloud Console、Python 和Java中的OCI软件开发人员工具包 (SDK) 或OCI CLI访问该服务。
图像AI功能:
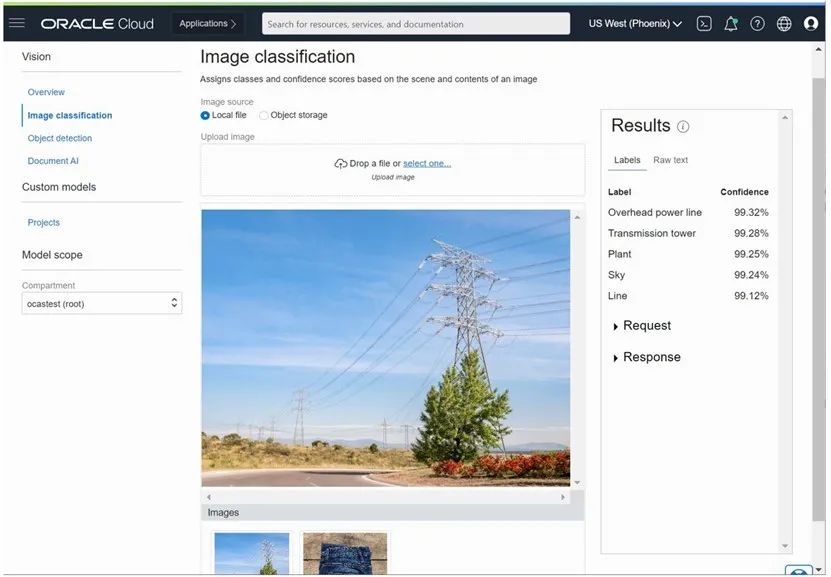
图像分类:根据整体场景为图像分配标签,例如“天空”、“水”和“纺织品”。
对象检测:定位和识别图像中的对象,例如公共汽车、盒子或人。
文本识别和OCR:从图像中定位并识别文本信息,例如停车标志中的“Stop”或车牌中的“XY3497”。
文档AI功能:
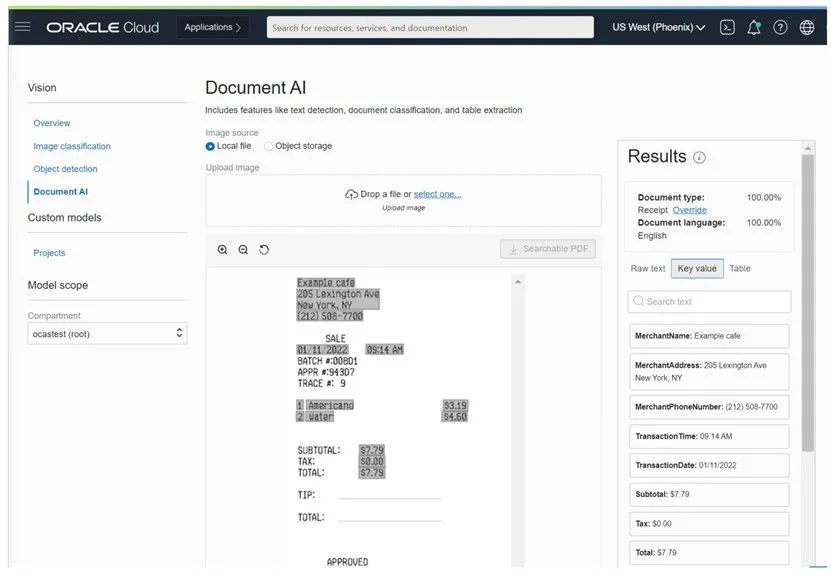
文本识别和OCR:在字或行级别从图像中定位和数字化文本信息。
键值提取:从收据中提取预定义的键值对信息列表,例如 fieldLabel:“TransactionDate”和 fieldValue:“01/11/2022”。
表格提取:以表格形式提取内容,维护单元格的行列关系,如单元格文本:“2,098,221” rowIndex:14 columnIndex:2。
文档分类:根据视觉外观、高级特征和提取的关键字将文档分类为不同的类型,例如发票、收据和简历。
OCI Vision支持创建自定义图像分类和对象检测模型。
训练和底层模型基础设施都通过OCI Vision进行管理。
1) 要使用OCI Vision服务训练自定义模型,请从标记数据集开始。我们可以使用 OCI 数据标记服务轻松标记原始图像。
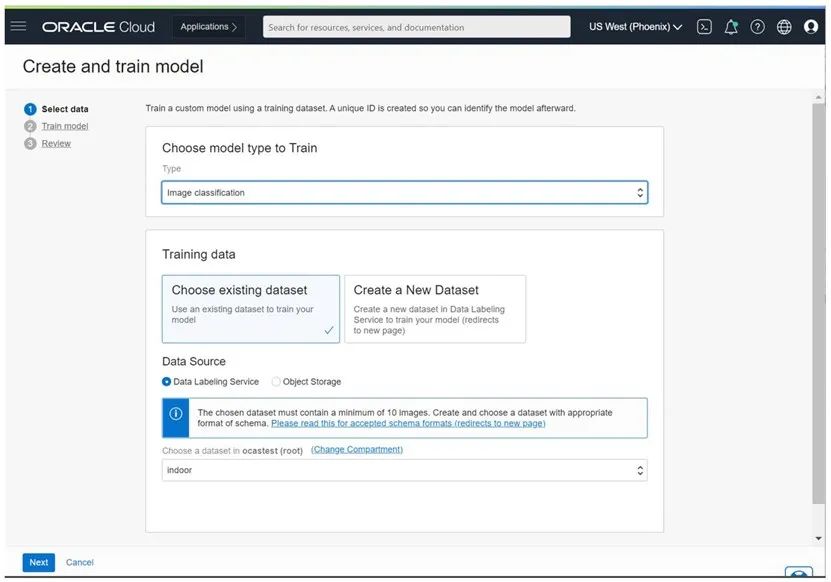
2) 选择模型类型和数据集后,为模型命名并选择训练持续时间。默认为“推荐”。
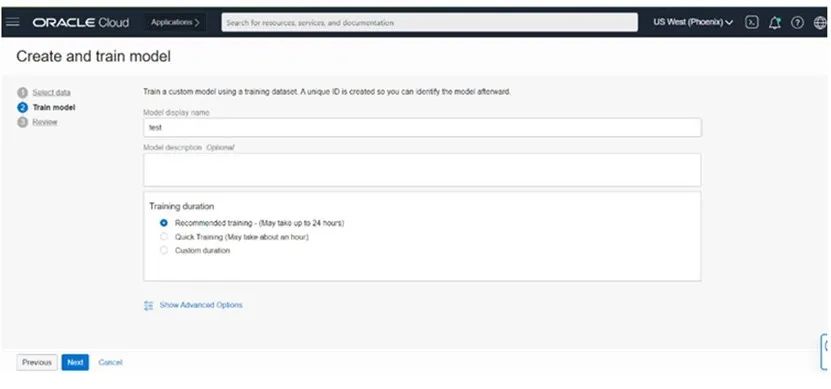
3) 开始训练新模型后,模型训练进度、日志和最终质量指标等都将在“模型详细信息”页面上展示。我们还可以使用“分析”选项在新图像上测试新训练的模型。
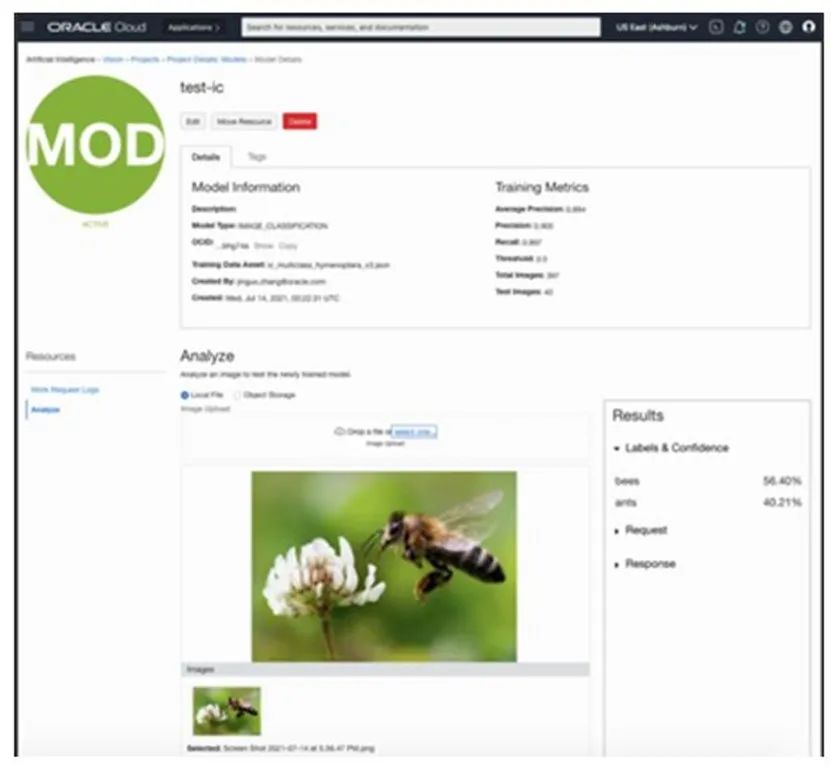
4) 要调用自定义视觉模型,请将模型OCID作为模型ID字段的一部分包含在您的输入请求中。以下示例显示了调用自定义图像分类模型的JSON请求:
{
"analyzeImageDetails": {
"compartmentId":"ocid1.tenancy.oc1..xxxx",
"image": {
"source":"INLINE",
"data":"......"
},
"features": [
{
"modelId":"ocid1.aivisionmodel.oc1.iad.amaaaaaapheaxxxxxxxxxxx",
"featureType":"IMAGE_CLASSIFICATION",
"maxResults": 5
}
]
}
}
计算机视觉应用场景存在于许多行业,包括金融服务、制造、运输和零售等等。
自动化后台任务:对文档进行分类、检测表格并从收据等文档中提取所需信息,以自动化业务工作流程,包括员工费用报告和报销。
数字资产管理:使用元数据描述基于图像的文件,包括文档类型、文本和对象,以便在数字资产管理系统或更大的数据仓库中更好地索引和检索。
检测视觉异常:根据变色、撕裂、生锈、变形或破损等视觉外观将产品或设备分类为标准产品或缺陷产品,并自动检测有缺陷的材料以标记维修需求。

作者简介
唐承波,甲骨文云架构团队资深解决方案专家,专注于甲骨文PaaS云平台相关产品及架构解决方案,具有13+年的IT行业从业经验,擅长大数据和分布式系统的架构与开发。熟悉电信,公共安全行业。您可以通过chengbo.tang@oracle.com与他联系。
