




我最早在论坛上注册的ID是ORA-600,后来这个网名成为了大家对我们的称呼,使用的人超过知道我名字的人,而且李轶楠三个字以各种错误方法被拼写。
14.1 我的职业生涯与思考
我的职业生涯可以简单概括为:5年开发,5年漂泊,5年创业。因偶然的机缘了解到Oracle,并全面转行进入Oracle领域。在成长过程中ITPUB给了我一个大舞台,在这里不仅认识了很多的朋友,共同探讨一些技术问题,交流一些心得体会。在技术能力提高的同时,也弥补了去现场机会较少的短板,通过交流与案例讨论,极大提高了自己技术服务的能力。随着在论坛上经验和知名度的积累,我得到越来越多客户的认可,也开始为有需要的朋友和客户做一些打包的维护项目服务。在这些服务的过程中,我逐渐意识到随着运维需求的增加和客户服务意识的增强,客户对于专业服务团队在数据库服务领域的需求越来越迫切,因此有了创业的念头。我希望和朋友们一起合作,把服务做大作强,同时也希望能够通过这种方式,把我们的一些服务理念带给客户,为客户带来一些不一样的服务感受,真正从专业服务中得到一些获益。在社区的氛围里,在对行业的认识之下,我最终选择加入恩墨团队,走上创业的道路。
14.2 如何看待企业运维
随着企业信息化的发展,越来越多的大型行业、企业用户对信息化的要求变得更高。他们不再局限于能做什么,而更强调能做到什么、能得到什么。尤其是一些行业用户,经过多年的信息化发展,分散式管理已经不再适合他们的需求。他们开始强调集中管理、综合应用,所以越来越多的项目开始变得大型化、规模化、集中化。在这样的需求下,如何保障这种应用系统能稳定、高效、可靠地运行,就变得非常重要。在大型应用系统中,由于业务量、数据量的巨大,很容易造成前期规划不当,中期维护复杂,后期调整难度大的情况。因此,必须在前期就要尽可能考虑全面。
我们一直希望把DBA的工作从简单的后台维护和救火,转换到前期的规划设计上。DBA在一个项目的生命周期中应该是无处不在的,一个有丰富经验,尤其是有过项目开发经验的DBA,对于项目生命周期的各个环节中可能出现的情况感受颇深。因此,不论项目的前期、中期还是后期,DBA都应该积极参与,尽其能力为项目的性能提供理念、方法和思路。
- 在项目的前期,主要是需求分析、架构设计、应用设计等工作。在这个过程中,DBA可以参与或者提供建议。在需求分析时,DBA可以提供业务、技术实现手段的评判,对一些需求进行适度的限制以保障优化方法的实现;在架构规划时,可以根据用户对高可用、容灾、健壮性、性能等多方面的要求,提供RAC、HA、DG、OGG、使用版本、硬件资源需求等多方面的数据库架构规划;在应用设计阶段,对应用的需求评估,确定使用前台语言实现还是使用PL/SQL实现,并设计E-R模型,构建应用的数据模型。项目前期的更多工作集中在规划设计上,虽然这时并不需要DBA去做什么,但DBA的经验对于前期设计的准确性与完整性有很大的帮助。
- 项目的中期主要是代码开发、数据库部署、性能测试等工作。在代码开发阶段,DBA将会辅助开发人员制定代码规范和数据规范,并对高效SQL进行评估,确保在大数据需求下高质量的SQL代码,现在我们把这个环境的工作称为SQL审核。同时通过对需求的了解和代码的掌握,确定应用对数据库的资源需求特性和资源消耗量。在此基础上,更准确地规划存储、网络、主机、中间件等资源,并且合理配置数据库,为不同需求构建不同类型的表,在相应字段上构建索引以满足各种查询需求。而对于性能测试阶段,DBA则需要做更细节的监控和精细分析工作。通过各种测试数据的分析,确定目前系统仍然存在的潜在风险,从稳定、可靠、高效等多方位确定调整方案,确保系统上线后的平稳运行。
- 项目的后期主要就是运维,这就是大家认为的传统意义上DBA应该做的事情。日常运维中最主要的就是监控、预警和巡检、优化。通过对系统的理解,DBA可以设定一些监控点和阈值(也可以通过定期巡检来审核),通过这些方法提前发现和排除系统潜在的隐患,以保证系统的正常运行。
可以说,DBA的参与对整个系统的性能和稳定性都有着非常重大的意义,所以别再把DBA当作大厦的救火器,其实他是大厦的脊梁。
14.3 对性能问题的认识
说到性能问题,大部分人可能都抱有性能就是数据库性能的一个错误观点。其实性能问题绝不能简单地说成是数据库性能,而应该考虑的是整体应用性能,因此,需要优化的地方涉及应用系统的各个环节,就像前面所讲,不论是前期的规划设计,还是中期的运维调整,还是后期的SQL分析,都是性能的一部分。所以在项目整个生命期内,从需求分析、架构设计、应用设计、数据库设计、存储规划、网络规划、中间件规划到代码开发、数据库部署等各个环节,都需要考虑性能的影响。性能问题与数据量有关,但并没有绝对值。影响性能的因素很多,数据量、并发量、主机配置、网络环境、应用架构、代码质量等等都会对性能带来很大影响。我所见过的最小的一个数据库,最大的单表数据量仅有几M,也就是10万条数据左右,整个数据库不到200M的数据,并发会话只有100左右,但最慢的查询一次就要执行十几分钟,所以很难简单地说数据量多大就要考虑性能优化。既然影响性能的因素很多,而其中不少因素又是在系统上线后很难调整的,所以前期规划设计的优化肯定很重要。如果前期不做好,即使系统上线运行了,在一段时间之后,各种性能问题也会随后出现,而到了那个时候,就会发现很多优化方法都受到了种种限制,以至于无法顺利实施,这就是前期没有考虑性能问题所带来的隐患。因此,前期规划设计绝对不能忽视,必须提前考虑各种设计方案在性能上的影响,综合平衡多方面的需求。很多人认为,现在Oracle的技术越来越成熟,功能也越来越完备,这样对于Oracle的开发会变得更加的简单,不需要多高的技术水平就可以用Oracle完成数据库的建设。我并不同意这种观点。要想系统的性能可控、预测和度量,就不要把希望寄托在别人身上。不需要优化的系统,只是在系统负载量不大、业务不繁忙的时候才可能存在,所有大型系统都必须摒弃这个观点。现在很多数据库都在通过各种技术手段使开发简单化、实施傻瓜化,这是技术发展的一个必然阶段。任何用户都不希望使用的是一个自己搞不定的软件,但是傻瓜式的构建只适合傻瓜式(或者叫通用性)的需求。这种开发和实施的自动化、简单化,实际上是数据库软件智能化的一个发展过程,但这种智能化目前为止还非常弱,不论是自动诊断还是自动调整,都有很大的局限性和延迟性。如果大型系统完全依赖于自动管理与调整,将会有非常多的问题发生。同时目前我们所用到的自动化与智能化仅限于数据库内,而一套应用系统需要考虑健壮性、可用性、高效性、安全性等各个方面。这些方面能否满足需求,并不仅仅是通过数据库的自动化就能解决的,需要考虑系统、架构、需求、代码、存储、网络等多个环节, 因此,绝对不要认为数据库技术发展了,我们就可以放松系统规划设计、代码优化、存储调整等一系列技术需求。数据库技术发展,仅仅意味着Oracle希望能减轻我们的工作,并不能根本上改变系统优化的模式。
14.4 学习方法
在学习技术的过程中,我认为勤奋、自学是非常重要的,汗水永远是成功的基石。为了工作,去Google寻找答案。但为了自己,看书和试验更重要。不要说你没有环境可以测试,所以学不会。环境是可以自己创造的,你可以装虚拟机,你也可以在网上与别人讨论他们的案例,这都是产生学习环境的基本方法,说没有环境就学不会,那只是逃避的借口。与别人的交流和讨论是快速成长的必要手段。多看书,多练习,踏踏实实地学习,脚踏实地才能够逐步起飞。DBA是个好职业,但DBA不是终点,而是另一个起点。事实证明,很多经验丰富的DBA,逐渐成为系统运维的管理者,或者企业级架构师,它们在另外的岗位上,很好的运用他们的DBA经验为企业的IT发展提供着必要的技术、经验支撑。
14.5 所有奇异的故障都有一个最简单的本质
在数据的世界里,任何奇异的事情都可能发生。也许司空见惯的一个现象会在某场景下导致严重的数据库故障,这就要求运维者要时刻保持警惕,要细致、耐心地分析现象,并通过表象认识事物的本质。接下来我们通过两个真实案例认识运维中的诡异故障。并通过这两个案例的分析跟大家分享我在处理问题中的一般思路。供大家参考和学习。在案例分享之前,先跟大家普及一下故障分析的常规思路,也便于初学者在遇到问题的时候知道从何处入手。
- 辨识问题。在遇到故障时,首先要辨识一下当前的场景主要是性能问题还是真的故障。
- 对待性能问题。如果是性能问题,那就需要收集当时的系统性能信息与数据库性能信息,如awr、ash,或者系统的nmon、top之类采样信息。
- 对待故障问题。如果是故障,那就要检查数据库的告警日志与跟踪文件了。非常典型的就是alert_
.log,这里面往往给了我们进一步追踪痕迹的指引。除此之外,各个进程的trace文件,asm的trace文件以及RAC的各种log、trace文件都会给出一些故障的原因或者印记。 - 官方信息检索。另外,当遭遇这些问题的时候,如果有MOS账号的话,建议首先去MOS中查看是否有故障相关的Bug或者技术文章,这既是快速诊断问题、解决问题的途径,也是DBA快速成长的重要手段。所有奇异的故障的奇异之处都在于——你对深层的技术本质不够理解。当我们了解了技术的本质之后,你会发现所有奇异的故障原本都很简单。
14.6 案例一:意料之外的RAC宕机祸首——子游标
这个案例是关于一次子游标过多导致的RAC节点宕机的故障。子游标与实例宕机会有什么关系?我们通过具体的案例看看如何从表象入手,抽丝剥茧,层层深入发现线索,并逐步还原犯罪场景,找出实例宕机的真实原因。
14.6.1 信息采集,准确定位问题
某天晚上,我们接到客户的电话,说某一核心系统有一个节点挂了,实例自动重启。虽然没有影响业务,但这种无缘无故的重启发生在核心系统上,直接威胁到业务运行,希望我们能协助尽快找到原因。听到客户的描述,心里第一个反应是:还好,只是单节点重启,问题本身应该不严重,至少对业务影响并不大。客户目前急需的是快速给出问题的原因,以便根据情况作出后续的规避措施,所以需要尽快拿到现场的一些数据来做分析。毕竟分析所需要的信息数据距离故障时间越近,精准度就越高,越有利分析。
从客户处得到的故障信息如下所示。
当然只听客户描述是不够的。于是,我们远程登录了客户的服务器,开始做进一步检查。以下是收录的关键线索。最核心的是节点2的告警日志,部分内容如下所示。
Fri Jun 26 20:24:52 2015
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_p001_13581.trc (incident=204565):
**ORA-00600:** 内部错误代码, 参数: **[kksfbc-wrong-kkscsflgs], [39913467504], [33], [], [], [], [], [], [], [], [], []**
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl2/incident/incdir_204565/ orcl2_p001_13581_i204565.trc
。。。。。
**Fri Jun 26 21:50:26 2015**
**LCK0 (ospid: 29987) waits for latch 'object queue header operation' for 77 secs.**
**Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_lmhb_29939.trc (incident=204141):**
**ORA-29771: process MMON (OSID 29967) blocks LCK0 (OSID 29987) for more than 70 seconds**
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl2/incident/incdir_204141/orcl2_lmhb_29939_i204141.trc
**MMON (ospid: 29967) is blocking LCK0 (ospid: 29987) in a wait**
**LMHB (ospid: 29939) kills MMON (ospid: 29967).**
Please check LMHB trace file for more detail.
**Fri Jun 26 21:51:06 2015**
**Restarting dead background process MMON**
Fri Jun 26 21:51:06 2015
MMON started with pid=213, OS id=16612
**Fri Jun 26 21:54:10 2015**
**LMS1 (ospid: 29929) waits for latch 'object queue header operation' for 81 secs.**
**LCK0 (ospid: 29987) has not called a wait for 85 secs.**
**Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_lmhb_29939.trc (incident=204142):**
**ORA-29770: global enqueue process LMS1 (OSID 29929) is hung for more than 70 seconds**
Fri Jun 26 21:54:20 2015
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_lmhb_29939.trc (incident=204143):
ORA-29770: global enqueue process LCK0 (OSID 29987) is hung for more than 70 seconds
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl2/incident/incdir_204142/orcl2_lmhb_29939_i204142.trc
**ERROR: Some process(s) is not making progress.**
**LMHB (ospid: 29939) is terminating the instance.**
Please check LMHB trace file for more details. Please also check the CPU load, I/O load and other system properties for anomalous behavior
ERROR: Some process(s) is not making progress.
LMHB (ospid: 29939): terminating the instance due to error 29770
**Fri Jun 26 21:54:21 2015**
**opiodr aborting process unknown ospid (26414) as a result of ORA-1092**
Fri Jun 26 21:54:21 2015
ORA-1092 : opitsk aborting process
**Fri Jun 26 21:54:21 2015**
**System state dump is made for local instance**
System State dumped to trace file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_ diag_29889.trc
**Instance terminated by LMHB, pid = 29939**
在告警日志中我们发现一个很明显的ORA-600错误,同时也发现一些其他的ORA报错,见上面着重标识部分。于是我们对这些错误分别进行了分析。
ORA-600 [kksfbc-wrong-kkscsflgs] (Doc ID 970885.1) 确实是一个Bug,在MOS上有详细说明,如表14-1所示。
表14-1
| Bug | Fixed | Description |
|---|---|---|
| 9067282 | 11.2.0.1.2, 11.2.0.1.BP01, 11.2.0.3, 12.1.0.1 | ORA-600 [kksfbc-wrong-kkscsflgs] can occur |
| 9066130 | 10.2.0.5, 11.1.0.7.2, 11.2.0.2, 12.1.0.1 | OERI [kksfbc-wrong-kkscsflgs] / spin with multiple children |
| 8828328 | 11.2.0.1.1, 11.2.0.1.BP04, 11.2.0.2, 12.1.0.1 | OERI [kksfbc-wrong-kkscsflgs] |
| 8661168 | 11.2.0.1.1, 11.2.0.1.BP01, 11.2.0.2, 12.1.0.1 | OERI[kksfbc-wrong-kkscsflgs] can occur |
但MOS上并未说明该Bug会导致实例宕机,这个600错误看来应该与此次重启关系不大。好吧,作为一个问题记下来就是了。在故障时间点,LMHB 进程check发现MMON进程阻塞了LCK0进程,超过70秒,因此尝试kill MMON进程,该进程被kill之后将会自动重启。可以看到在在6月26日21:51:06 时间点,MMON进程重启完成。接下来,在6月26日21:54:10,LMS1进程报错无法获得latch(object queue header operation) 超过85秒。[3]为了更清楚地理清线索,我们根据节点2的告警日志信息,整理出如下的时间流。
Jun 26 20:24:52 ORA-00600 [kksfbc-wrong-kkscsflgs]
Jun 26 21:50:26 LCK0 (ospid: 29987) waits for latch 'object queue header operation' for 77 secs
MMON (OSID 29967) blocks LCK0 (OSID 29987) for more than 70 seconds
MMON (ospid: 29967) is blocking LCK0 (ospid: 29987) in a wait
LMHB (ospid: 29939) kills MMON (ospid: 29967)
Jun 26 21:51:06 MMON started with pid=213, OS id=16612
Jun 26 21:54:10 LMS1 (ospid: 29929) waits for latch 'object queue header operation' for 81 secs
LCK0 (ospid: 29987) has not called a wait for 85 secs
ORA-29770: global enqueue process LMS1 (OSID 29929) is hung for more than 70 seconds
Jun 26 21:54:20 ORA-29770: global enqueue process LCK0 (OSID 29987) is hung for more than 70 seconds
ERROR: Some process(s) is not making progress.
LMHB (ospid: 29939) is terminating the instance
LMHB (ospid: 29939): terminating the instance due to error 29770
从最后的信息可以看出,在21:54:20时间点,LMHB进程强行终止了数据库实例。而终止实例的原因是LMHB进程发现LCK0进行hung住了,而且超过了70秒。从前面的信息也可以看出,实际上在21:54:10时间点,LCK0进程就已经没有活动了,而且在该时间点LMS1进程也一直在等待latch。很明显,如果LMS1进程无法正常工作,Oracle为了保证集群数据的一致性,为了避免脑裂,必然将问题节点强行驱逐重启。
14.6.2 层层分析,揪出罪魁祸首
在故障日志中,LMS1进程一直处于等待状态,那么LMS1在等什么呢?LCK0为什么被Hung住了?我们通过更详细的信息来分析。
首先让我们来看看LMS1到底在干什么?
检查orcl2_lmhb_29939_i204142.trc,而该trace 文件产生的时间点是6月26日21:54:10。
SO: 0x9a1175160, type: 2, owner: (nil), flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x9a1175160, name=process, file=ksu.h LINE:11459, pg=0
(process) Oracle pid:14, ser:1, calls cur/top: 0x9b17e5330/0x9b17e0e60
flags : (0x6) SYSTEM flags2: (0x100), flags3: (0x0) intr error: 0, call error: 0, sess error: 0, txn error 0 intr queue: empty
ksudlp FALSE at location: 0
(post info) last post received: 0 0 116
last post sent-location: ksl2.h LINE:2160 ID:kslges
last process posted by me: 9811032c8 1 14
(latch info) wait_event=0 bits=a
Location from where call was made: kcbo.h LINE:890 ID:kcbo_unlink_q_bg:
**waiting for 993cfec60 Child object queue header operation level=5 child#=117**
**Location from where latch is held: kcl2.h LINE:3966 ID:kclbufs:**
**Context saved from call: 0**
**state=busy(shared) [value=0x4000000000000001] wlstate=free [value=0]**
**waiters [orapid (seconds since: put on list, posted, alive check)]:**
**14 (95, 1435326858, 4) 21 (94, 1435326858, 7)**
**waiter count=2**
**gotten 73961423 times wait, failed first 4752 sleeps 1927**
**gotten 33986 times nowait, failed: 4**
**possible holder pid = 36 ospid=29987**
on wait list for 993cfec60
holding (efd=5) 9b59be480 Child gc element level=3 child#=20
Location from where latch is held: kcl2.h LINE:3535 ID:kclbla: Context saved from call: 0
state=busy(exclusive) [value=0x200000000000000e, holder orapid=14] wlstate=free [value=0]
holding (efd=5) 9b45cac50 Child cache buffers chains level=1 child#=61221
Location from where latch is held: kcl2.h LINE:3140 ID:kclbla: Context saved from call: 0
state=busy(exclusive) [value=0x200000000000000e, holder orapid=14] wlstate=free [value=0]
Process Group: DEFAULT, pseudo proc: 0x9b11ca008
O/S info: user: oracle, term: UNKNOWN, ospid: 29929
OSD pid info: Unix process pid: 29929, image: oracle@ebtadbsvr2 (LMS1)
从LMS1进程的信息来看,LMS1 进程所等待的资源(object queue header operation)正被ospid=29987 持有,那么29987又是什么呢?
进一步分下ospid=29987 是什么?让我们接着往下看。
SO: 0x9911283b0, type: 2, owner: (nil), flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x9911283b0, name=process, file=ksu.h LINE:11459, pg=0
(process) Oracle pid:36, ser:2, calls cur/top: 0x9b17e58e0/0x9b17e58e0
flags : (0x6) SYSTEM flags2: (0x0), flags3: (0x0) intr error: 0, call error: 0, sess error: 0, txn error 0 intr queue: empty
ksudlp FALSE at location: 0
(post info) last post received: 0 0 35
last post received-location: ksr2.h LINE:603 ID:ksrpublish
last process to post me: 981110608 118 0
last post sent: 0 0 36
last post sent-location: ksr2.h LINE:607 ID:ksrmdone
last process posted by me: 9911283b0 2 6
(latch info) wait_event=0 bits=20
**holding (efd=3) 993cfec60 Child object queue header operation level=5 child#=117**
**Location from where latch is held: kcl2.h LINE:3966 ID:kclbufs:**
**Context saved from call: 0**
**state=busy(shared) [value=0x4000000000000001] wlstate=free [value=0]**
**waiters [orapid (seconds since: put on list, posted, alive check)]:**
**14 (95, 1435326858, 4)**
**21 (94, 1435326858, 7)**
waiter count=2
Process Group: DEFAULT, pseudo proc: 0x9b11ca008
O/S info: user: oracle, term: UNKNOWN, ospid: 29987
**OSD pid info: Unix process pid: 29987, image: oracle@ebtadbsvr2 (LCK0)**
最后一句很明显地告诉我们,29987原来就是LCK0进程。这意味着LMS1 进程所等待的资源正被LCK0 进程所持有。而同时还有另外一个进程orapid=21 也在等待该进程。通过分析我们发现,orapid=21,是DBW2进程,即数据库写进程。[4]
从数据库告警日志来看,在6月26日21:54:10 有提示LCK0 进程已经超过85秒没有响应。
LCK0 (ospid: 29987) has not called a wait for 85 secs
根据时间点来计算,大概在6月26日21:52:45点左右开始,LCK0进程即没有响应了。那么很明显,我们只要知道LCK0进程为什么会hung,就知道了此次故障的原因。
那么来看看LCK0的trace文件,能不能看到一些线索。LCK0进程的trace信息如下所示。```
*** 2015-06-26 21:50:29.329 Process diagnostic dump for oracle@ebtadbsvr2 (LCK0), OS id=29987,
pid: 36, proc_ser: 2, sid: 1729, sess_ser: 3
-----------------------------------------------
loadavg : 6.47 26.96 34.97
Memory (Avail / Total) = 10598.05M / 64421.55M
Swap (Avail / Total) = 20256.00M / 20479.99M
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
0 S oracle 29987 1 0 76 0 - 10541946 semtim Apr05 ? 01:25:21 ora_lck0_orcl2
Short stack dump:
ksedsts()+461<-ksdxfstk()+32<-ksdxcb()+1782<-sspuser()+112<-__restore_rt()<-semop()+7<-skgpwwait()+156<-kslgess()+1799<-ksl_get_shared_latch()+620<-kclbufs()+272<-kclanticheck()+412<-kclahrt()+88<-ksbcti()+212<-ksbabs()+1732<-kclabs()+186<-ksbrdp()+923<-opirip()+623<-opidrv()+603<-sou2o()+103<-opimai_real()+266<-ssthrdmain()+214<-main()+201<-__libc_start_main()+244<-_start()+36
*** 2015-06-26 21:54:18.438
Process diagnostic dump for oracle@ebtadbsvr2 (LCK0), OS id=29987,
pid: 36, proc_ser: 2, sid: 1729, sess_ser: 3
-------------------------------------------------------------------------------
loadavg : 2.04 13.34 27.63
Memory (Avail / Total) = 9519.06M / 64421.55M
Swap (Avail / Total) = 20256.00M / 20479.99M
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
0 R oracle 29987 1 0 85 0 - 10541965 ? Apr05 ? 01:26:55 ora_lck0_orcl2
Short stack dump:
ksedsts()+461<-ksdxfstk()+32<-ksdxcb()+1782<-sspuser()+112<-__restore_rt()<-kcbo_get_next_qheader()+255<-kclbufs()+321<-kcldirtycheck()+231<-kclahrt()+93<-ksbcti()+212<-ksbabs()+1732<-kclabs()+186<-ksbrdp()+923<-opirip()+623<-opidrv()+603<-sou2o()+103<-opimai_real()+266<-ssthrdmain()+214<-main()+201<-__libc_start_main()+244<-_start()+36
从上述LCK0进程的几个时间点的信息来看,第一个时间点21:50:29,wchan 为semtim。wchan,表示进程sleeping的等待表现形式。semtim表示在该时间点,LCK0 进程一直处于sleep状态。所谓的sleep状态,是进程持有的资源是不会释放的。
而在第2个时间点21:54:18,LCK0进程的wchan状态是“?”,这表示未知,如果是为空,则表示该进程处理running状态。在21:50到21:52 时间段内,LCK0进程仍然没有恢复正常。那么LCK0到底被什么阻塞了(或者说它需要的资源被谁占用了)?
同时也可以看到内存和swap都空闲很多,CPU也并不很忙。
继续检查trace,在21:50时间点我们发现,LCK0进程是被MMON进程锁阻塞了。```
SO: 0x9d10f97c0, type: 2, owner: (nil), flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x9d10f97c0, name=process, file=ksu.h LINE:11459, pg=0
(process) Oracle pid:31, ser:1, calls cur/top: 0x965657408/0x9b17e3f18
flags : (0x2) SYSTEM flags2: (0x20), flags3: (0x0) intr error: 0, call error: 0, sess error: 0, txn error 0 intr queue: empty
ksudlp FALSE at location: 0
(post info) last post received: 0 0 35
last post received-location: ksr2.h LINE:603 ID:ksrpublish
last process to post me: 9911283b0 2 6
last post sent: 0 0 26
last post sent-location: ksa2.h LINE:282 ID:ksasnd
last process posted by me: 9911283b0 2 6
(latch info) wait_event=0 bits=26
**holding (efd=7) 993cfec60 Child object queue header operation level=5 child#=117**
Location from where latch is held: kcbo.h LINE:884 ID:kcbo_link_q:
Context saved from call: 0
state=busy(exclusive) [value=0x200000000000001f, **holder orapid=31]** wlstate=free [value=0]
waiters [orapid (seconds since: put on list, posted, alive check)]:
36 (82, 1435326627, 1) 21 (81, 1435326627, 1)
waiter count=2
holding (efd=7) 9b5a5d630 Child cache buffers lru chain level=2 child#=233
Location from where latch is held: kcb2.h LINE:3601 ID:kcbzgws:
Context saved from call: 0
state=busy [holder orapid=31] wlstate=free [value=0]
holding (efd=7) 9c2a99938 Child cache buffers chains level=1 child#=27857
Location from where latch is held: kcb2.h LINE:3214 ID:kcbgtcr: fast path (cr pin):
Context saved from call: 12583184
state=busy(exclusive) [value=0x200000000000001f, holder orapid=31] wlstate=free [value=0]
Process Group: DEFAULT, pseudo proc: 0x9b11ca008
O/S info: user: oracle, term: UNKNOWN, ospid: 29967
OSD pid info: Unix process pid: 29967, image: oracle@ebtadbsvr2 (MMON)
从上面的trace可以看到,之前一直被等待的993cfec60 资源(Child object queue header operation)正被 MMON进程持有。
21:50:29的时候LCK0在等待MMON释放资源,而此时MMON出现异常,因此在21:51:06 MMON 进程被LMHB强制重启。然后在重启后,由于MMON的异常,导致21:54:18该资源仍无法被LCK0 进程正常持有,最终导致21:54:20LMHB进程强制重启了整个实例。
因此,最终的罪魁祸首是MMON****进程。```
Fri Jun 26 21:50:26 2015
LCK0 (ospid: 29987) waits for latch ‘object queue header operation’ for 77 secs.
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl2/trace/orcl2_lmhb_29939.trc (incident=204141):
ORA-29771: process MMON (OSID 29967) blocks LCK0 (OSID 29987) for more than 70 seconds
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl2/incident/incdir_204141/ orcl2_lmhb_29939_i204141.trc
MMON (ospid: 29967) is blocking LCK0 (ospid: 29987) in a wait
LMHB (ospid: 29939) kills MMON (ospid: 29967).
Please check LMHB trace file for more detail.
Fri Jun 26 21:51:06 2015
Restarting dead background process MMON
Fri Jun 26 21:51:06 2015
MMON started with pid=213, OS id=16612
MMON进程Oracle是用于进行AWR信息收集的。既然案情发生的原因与它有关,那么接下来的分析自然是查看它的相关trace了。
检查MMON的相关trace 可以看到,MMON进程负责处理对象的统计信息。从trace中可以看到大量的游标包含了太多的子游标。
User=b1456358 Session=c146d760 ReferenceCount=1 Flags=CNB/[0001] SavepointNum=558d5760
LibraryHandle: Address=2f79eb08 Hash=3dec6f4a LockMode=N PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name= select time_mp, scn, num_mappings, tim_scn_map from smon_scn_time where scn = (select max(scn) from smon_scn_time where scn <= :1)
FullHashValue=c36d5a579fdc3e19733192893dec6f4a Namespace=SQL AREA(00) Type=CURSOR(00) Identifier=1038905162 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=23741 LoadCount=107 ActiveLocks=1 TotalLockCount=6093 TotalPinCount=1
Counters: BrokenCount=1 RevocablePointer=1 KeepDependency=106 KeepHandle=106 BucketInUse=6092 HandleInUse=6092
Concurrency: DependencyMutex=2f79ebb8(0, 0, 0, 0) Mutex=2f79ec30(0, 87578, 0, 0)
Flags=RON/PIN/TIM/PN0/DBN/[10012841]
WaitersLists:
Lock=2f79eb98[2f79eb98,2f79eb98]
Pin=2f79eba8[2f79eb78,2f79eb78]
Timestamp: Current=04-05-2015 09:48:42
LibraryObject: Address=dff3bc60 HeapMask=0000-0001-0001 Flags=EXS[0000] Flags2=[0000] PublicFlags=[0000]
ChildTable: size=‘112’
Child: id=‘0’ Table=dff3cb60 Reference=dff3c5b0 Handle=2f79e908
Child: id=‘1’ Table=dff3cb60 Reference=dff3c8e0 Handle=2f4e2d90
Child: id=‘2’ Table=dff3cb60 Reference=df3e7400 Handle=2f8c9e90
Child: id=‘3’ Table=dff3cb60 Reference=df3e76e8 Handle=2f8abce8
…
…
Child: id=‘101’ Table=dc86f748 Reference=df02d368 Handle=288e6460
Child: id=‘102’ Table=dc86f748 Reference=dd65c3e0 Handle=274d0b40
Child: id=‘103’ Table=dc86f748 Reference=dd65c6c8 Handle=29aa92f8
Child: id=‘104’ Table=dc86f748 Reference=dd65c9b8 Handle=26f3a460
Child: id=‘105’ Table=dc86f748 Reference=dd65ccd0 Handle=25c02dd8
NamespaceDump:
Parent Cursor: SQL_id=76cckj4yysvua parent=0x8dff3bd48 maxchild=106 plk=y ppn=n
Current Cursor Sharing Diagnostics Nodes:
…
…
Child Node: 100 ID=34 reason=Rolling Invalidate Window Exceeded(2) size=0x0
already processed:
Child Node: 101 ID=34 reason=Rolling Invalidate Window Exceeded(2) size=0x0
already processed:
类似上面的信息非常多。很明显,上述文游标(parent cursor)包含了大量的子游标,这是为什么在20点~21点(节点2还未重启前的时段)的awr报告中出现大量cursor: mutex S 的原因,表14-2是这个时段的等待事件。
表14-2
| Event | Waits | Time(s) | Avg wait (ms) | % DB time | Wait Class |
| ----------------------------- | -------------- | ---------- | -------------- | ---------- | --------------- |
| DB CPU | | 47,072 | | 93.05 | |
| **cursor: mutex S** | **31,751,317** | **18,253** | **1** | **36.08** | **Concurrency** |
| **gc cr multi block request** | **359,897** | **1,281** | **4** | **2.53** | **Cluster** |
| **gc buffer busy acquire** | **10,465** | **686** | **66** | **1.36** | **Cluster** |
| **library cache lock** | **9,285** | **550** | **59** | **1.09** | **Concurrency** |
在MMON正常通过内部SQL收集系统信息时,根本不应该出现这种情况,而此时MMON进程却出现异常,这个异常看来应该是与cursor子游标过多有关了。
最后数据库实例被强行终止的原因是LCK0进程出现异常导致LMHB进程强行终止instance,在最后instance终止之前的diag dump中,LCK0进程的状态仍然是hang的状态,同时也阻塞了3个其他session,如下所示。```
SO: 0x9914dbce8, type: 4, owner: 0x9911283b0, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x9911283b0, name=session, file=ksu.h LINE:11467, pg=0
(session) **sid: 1729** ser: 3 trans: (nil), creator: 0x9911283b0
flags: (0x51) USR/- flags_idl: (0x1) BSY/-/-/-/-/-
flags2: (0x408) -/- DID: , short-term DID: txn branch: (nil)
oct: 0, prv: 0, SQL: (nil), pSQL: (nil), user: 0/SYS
ksuxds FALSE at location: 0
service name: SYS$BACKGROUND
Current Wait Stack:
**Not in wait; last wait ended 1 min 39 sec ago**
There are 3 sessions blocked by this session.
Dumping one waiter:
inst: 2, sid: 1009, ser: 1
wait event: 'latch: object queue header operation'
p1: 'address'=0x993cfec60 p2: 'number'=0xa2 p3: 'tries'=0x0
row_wait_obj#: 4294967295, block#: 0, row#: 0, file# 0
min_blocked_time: 81 secs, waiter_cache_ver: 14285
Wait State:
fixed_waits=0 flags=0x20 boundary=(nil)/-1
对于数据库进程,如果状态不是dead,而是busy,而且持有latch不释放,那么这意味着该进程已被挂起,LCK0 持有的latch是object queue header operation。oracle mos文档关于该event 的描述如下:Scans of the object queue in the buffer cache can hold the “object queue header operation”。
14.6.3 对症下药,排除数据故障
基于上述的分析,我们最终判断,LCK0 进程出现问题的原因与游标子游标过多有关。同时,这又与在11.2.0.1版本上的child cursor总数阈值限制过高有关。实际在版本10g中就引入了该Cursor Obsolescence游标废弃特性,10g的child cursor 的总数阈值是1024,即子游标超过1024即被过期,但是这个阈值在11g的初期版本中被移除了。这就导致出现一个父游标下大量子游标即high version count的发生,由此引发了一系列的版本11.2.0.3之前的cursor sharing 性能问题。这意味着版本11.2.0.1和11.2.0.2的数据库,将可能出现大量的Cursor: Mutex S 和 library cache lock等待事件这种症状,进而诱发其他故障的发生。因此,通常我们建议11.2.0.4以下的版本应尽快将数据库版本升级到11.2.0.4(11.2.0.3中默认就有_cursor_obsolete_threshold了,而且默认值为100),或者通过_cursor_features_enabled 和106001 event来强制控制子游标过多的情况。
14.6.4 深入总结,一次故障长久经验
该案例的分析还是有些曲折,因为常见导致单节点故障最常见的情况主要是心跳、节点资源之类,而该案例的诱发原因相对有些诡异。先是出现了ora-600错误,然后又报了kill MMON的信息,这都让案情分析有些扑朔迷离,当然,最终我们还是找出了问题的主要根源。
通过该起案件我们可以得到如下几点体会。
- 数据库版本的选择绝对是影响系统稳定性的关键要点。
- 不要以为性能问题只是影响用户体验,有些性能问题是会诱发系统一系列问题的。
- 问题的分析不要想当然,通过trace逐步递进,结合原理与经验,才能更为准确的确定问题。
- 子游标过多千万不能小视,最好能找出根源并解决它。如果确实不好解决,那么可通过设置隐含参数_cursor_features_enabled 和106001 event强制失效子游标的方式来防止子游标过多的情况,操作如下所示。
SQL> alter system set event='106001 trace name context forever,level 1024' scope=spfile;
正常重启数据库即可。
14.7 案例二:异常诡异的SQL性能分析
2015年9月末的一天,客户告知其核心数据库突然发生了一个诡异现象,甚至导致业务系统该功能无法正常处理。经过简单询问,发现仅仅是一条SQL导致的,而很诡异的是,这条SQL在第二次执行时,执行计划会发生了变化,导致执行效率极低,影响业务运行。根据客户的陈述,该问题可随时重现,无论换个会话还是换个客户端工具都会受到影响。即使把共享池flush掉,再次执行SQL仍然会发生同样的现象。
14.7.1 信息收集
下面我们就来看看案情现场重现。
一条SQL在同一个会话中执行两次,第一次执行时间为10秒。但第二次执行时效率很低,执行时间超过1分钟。下面是SQL文本。
SELECT /*bbbbb*/A.C_DOC_NO AS C_PLY_APP_NO, A.C_PLY_NO AS C_PLY_NO, B.N_PRM AS N_PRM,
NVL(TO_CHAR(A.T_APP_TM, 'YYYY-MM-DD HH24:MI:SS'), CHR(0)) AS T_APP_TM,
A.C_BLG_DPT_CDE AS C_DPT_CDE, A.C_PROD_NO AS C_PROD_NO,
NVL(B.C_APP_NME, CHR(0)) AS C_APP_NME, NVL(B.C_APP_TEL, CHR(0)) AS C_APP_TEL
FROM T_PLY_UNDRMSG A, T_PLY_BASE B, T_FIN_PLYEDR_COLDUE C
WHERE 1 = 1
AND ROWNUM < 1000
AND A.C_DOC_NO = B.C_PLY_APP_NO AND A.C_DOC_NO = C.C_PLY_APP_NO(+)
AND A.C_SOURCE = '1'
AND A.C_SEND_MRK NOT IN ('2')
AND DECODE(TRIM(C.C_OPT_NO), CHR(0), NULL, TRIM(C.C_OPT_NO)) IS NULL
AND (NVL(C.C_PRM_TYP, CHR(0)) IN (CHR(0), 'R1'))
AND (NVL(C.C_ARP_FLAG, CHR(0)) IN (CHR(0), '0', '3', '4')) AND (NVL(C.N_TMS, 0) IN (0, 1))
AND B.C_HAND_PER = '1012337'
AND A.T_APP_TM BETWEEN
TO_DATE('2015-09-29 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2015-09-30 23:59:59', 'YYYY-MM-DD HH24:MI:SS')
AND A.T_INPUT_TM BETWEEN
TO_DATE('2015-09-29 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2015-09-30 23:59:59', 'YYYY-MM-DD HH24:MI:SS')
观察该SQL执行计划信息,发现第二次执行计划发生了变化。其中T_PLY_BASE表的索引扫描变成了分区表扫描,而且驱动表和被驱动表也发生了改变,第二次执行计划中的COST也是在这里出现了明显增高。
第一次执行计划如图14-1所示。
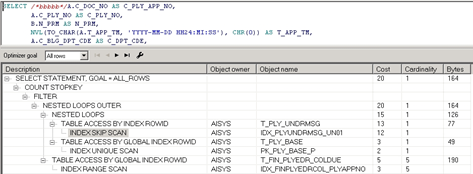
图14-1
第二次执行计划如下所示。```
call count cpu elapsed disk query current rows
Parse 1 0.02 0.04 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 57.00 626.79 1043187 1816768 0 0
total 3 57.02 626.83 1043187 1816768 0 0
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 413
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
0 0 0 COUNT STOPKEY (cr=0 pr=0 pw=0 time=12 us)
0 0 0 FILTER (cr=0 pr=0 pw=0 time=9 us)
0 0 0 NESTED LOOPS OUTER (cr=0 pr=0 pw=0 time=9 us cost=78029 size=164328 card=1002)
0 0 0 NESTED LOOPS (cr=0 pr=0 pw=0 time=8 us cost=77047 size=27468 card=218)
0 0 0 PARTITION RANGE ALL PARTITION: 1 20 (cr=0 pr=0 pw=0 time=7 us cost=76262 size=19747 card=403)
0 0 0 PARTITION LIST ALL PARTITION: 1 7 (cr=1476837 pr=852917 pw=0 time=486948524 us cost=76262 size=19747 card=403)
0 0 0 TABLE ACCESS FULL T_PLY_BASE PARTITION: 1 140 (cr=1786130 pr=1015408 pw=0 time=614908158 us cost=76262 size=19747 card=403)
0 0 0 TABLE ACCESS BY INDEX ROWID T_PLY_UNDRMSG (cr=0 pr=0 pw=0 time=0 us cost=4 size=77 card=1)
0 0 0 INDEX RANGE SCAN PK_PLY_UNDRMSG_HIST_20131203 (cr=0 pr=0 pw=0 time=0 us cost=3 size=0 card=1)(object id 406120)
0 0 0 TABLE ACCESS BY GLOBAL INDEX ROWID T_FIN_PLYEDR_COLDUE PARTITION: ROW LOCATION ROW LOCATION (cr=0 pr=0 pw=0 time=0 us cost=5 size=190 card=5)
0 0 0 INDEX RANGE SCAN IDX_FINPLYEDRCOL_PLYAPPNO (cr=0 pr=0 pw=0 time=0 us cost=3 size=0 card=5)(object id 180111)
很明显,的确是第二个执行计划出现了问题,导致了性能的严重下降。但是问题是,为什么同一个SQL第二次执行时执行计划会变呢?甚至同一个SQL连续两次执行也是如此?
理论上同一个会话上执行的同一个SQL,第二次执行为软解析(或者软软解析),此时数据库应该重用执行计划,而不是产生新的执行计划。
### 14.7.2 新特性分析
在11g上出现了一些新特性,而其中一个典型会导致SQL执行计划发生改变的场景就是**ACS****(自适应游标adaptive_cursor_sharing****)**。但ACS典型出现的场景应该是使用了绑定变量的SQL,但该SQL并未使用绑定,数据库中也并未通过corsor_sharing参数强制绑定,看起来应该不是ACS,那么是什么原因呢?在11g不但出现了ACS这样的自动优化新特性,还出现了另一个自动优化特性**基数反馈**(**Cardinality Feedback****)。**而通过执行计划中的信息与基数反馈特性的对比,基本可以推断该问题是由11g新特性统计信息Feedback导致的Bug,只需要关闭该特性再做验证即可确认。参考MOS Statistics (Cardinality) Feedback - Frequently Asked Questions (文档 ID 1344937.1),文档有对11GR2 Statistics Feedback新功能引起执行计划变化的描述、如何确认及解决方法。本次问题就是典型11g新特性——统计信息Feedback导致的Bug,这样的问题相对比较常见,我们一般推荐关闭自适应游标共享和统计信息回馈(事实上我们已经总结了不少应该关闭或者调整的新特性),通过两个参数就可以动态关闭它们。在我们很多其他客户的核心库中均已进行过设置,不会对系统造成损害,建议大多数11g核心系统最好关闭。在执行了以下处理后,SQL执行不但恢复正常,而且运行效率进一步得到了提高。
#### 1.优化参数
关闭自适应游标共享和统计信息回馈11g新特性。
alter system set “_optimizer_use_feedback” = false scope = both;
alter system set “_optimizer_adaptive_cursor_sharing” = false scope = both;
#### 2.优化索引
同时也对这条SQL的执行计划相关索引进行了优化。建议在表T_UND_RMSG的T_INPUT_TM列上的创建单列索引,这样就避免了出现跳扫的执行计划(同时还可将该SQL执行计划强制失效),或者通过comment命令使相关SQL强制重新解析(注意,这两种方法都会将该表的所有SQL执行计划全部过期失效,代价较高)。```
Create index xxxx on T_UND_RMSG(T_INPUT_TM);
Comment on table T_UND_RMSG is ‘xxxx’;
当然,在11g上有一个更为推荐的方法——DBMS_SHARED_POOL.PURGE,这种方法将只失效特定执行计划异常的子游标,下面给出参考样例。
select address, hash_value from v$SQLarea where SQL_id = 'a6aqkm30u7p90';
ADDRESS HASH_VALUE
---------------- ----------
C000000EB7ED3420 3248739616
exec dbms_shared_pool.purge('C000000EB7ED3420,3248739616','C');
14.8 总结
以上两则案例从表面上看都是有些诡异的,但作为一个专业的DBA,一定要耐心细致,通过表象的层层分析发现故障的本质。除此而外,视而不见是运维的癌症,运维无小事,任何异常的现象,哪怕再小,都是值得深入分析和探究的。希望以上分享的案例对大家有所帮助。
[1] 潜台词是这不是个案,以前的重启意味着这个问题一直存在。
[2] 看到每个大版本的第一个小版本,总是觉得这种系统会Bug缠身。虽然夸大了点,但我们确实遇到了不少这种小版本的Bug。
[3] LMHB是11gR2中引入的后台进程,官方文档介绍是Global Cache/Enqueue Service Heartbeat Monitor,Monitor the heartbeat of LMON, LMD, and LMSn processes,LMHB monitors LMON, LMD, and LMSn processes to ensure they are running normally without blocking or spinning。该进程负责监控LMON、LMD、LMSn等RAC关键的后台进程,保证这些background process不被阻塞或spin。 LMHB是Lock Manager Heartbeat的缩写。
[4]这里解释一下,orapid是oracle中的进程id,而pid则是os上的进程id。所以orapid=21从v$process中可以查到是dbw2,而orapid=14是LMS1.
