




前言
对于数据库性能调优,每个厂商都有自己的独门调试利器,有些人测试成了猪,有些测试成了牛,到底是牛还是猪?除了与产品有关系,还与人有关系,你只把产品的一成功力发挥出来,CPU和内存都空闲着呢。OceanBase发布了3.1.2版本,由于OceanBase一直宣称自己的tpcc是世界上第一,而且tpc-h也有不俗的成绩。赶上这段时间没有那么忙了,俺偷偷把公司测试三个节点相关的hadoop服务关掉了,用来探索引测试OceanBase的性能。由于三个节点的硬件配置太低了,而且阵容配搭也不合理,所以我的目的由最初的OceanBase数据库极限性能测试,变成OceanBase数据库性能测试。安装一个数据库后,如何保障它是最佳的工作性能状态,一个数据库性能受限于哪些因素?从哪些方面可对它进行优化,基于官方的调优参数探索调研OceanBase。
安装&环境结构
安装前检查
测试硬件方面有没有问题。
ps -eaf | grep -v ssh,除了22端口,把其它无用的进程和服务都关了,为了节省内存
分布式集群的操作与节点的磁盘IO和网络有关,测试三个节点的硬盘IO及网络IO,如下,通过dd顺序写得出硬盘的的IO,通过在节点1传输文件 到节点2,后面再测试从节点2传到节点3。可以得出分布式集群的写操作巅峰值是 179MB,节点网络传输用了scp协议实测77.7MB,逼近千兆网络125M的写性能。
结论,三个节点的硬件状态健康正常。下面的测试要把CPU忙起来,内存使用100%,网络尽可能打满。

安装产品
安装,我是官方的一键安装工具obd来进行安装的
安装参考以下两个
https://www.modb.pro/db/334676
https://mp.weixin.qq.com/s?__biz=MzU3OTc2MDQxNg==&mid=2247483820&idx=1&sn=35996d4e46d8703628986e9d7380f4f5
安装的体验要比TiDB差,自动化布署工具Tiup安装,输入指定名称、参数,例如Tiup 名称 参数,马上就可以安装一套集群。但是obd需要指定一个XML,我要编辑XML文件,千军万马找到属于我的座位,把IP填进去。tidb没有纷繁复杂那么多选项参数,集群配置一目了然,建议这点向TiDB看齐。
我的目标是做性能优化,要尽可以了解数据库参数。如果我把cpu_count设置成为16,那么数据库安装成功后,数据库会把你的服务器识别成16个核。实际上,我是8个核,为了实验的准确性,我选择重装,把3.1.2社区版卸载。
卸载还是很简单的事,第一步是停止服务,第二步手动rm删除 ob三个相关的文件。笔者查看obd的help,反覆查阅没有卸载的提示。
相关数据库参数的功能说明,社区的功能还是挺到位,当前3.1.2社区版show parameters一共768个参数。例如下面通过社区网站 ,输入cpu_count查阅回车,就知道这个参数是什么,应该设成什么。
官方建议设置0,0意味着OB会从内核读有多少个CPU,而不是从XML你设置的参数读取有多少个CPU。
社区
https://open.oceanbase.com/search?q=syslog_io_bandwidth_limit&scope=oceanbase-site
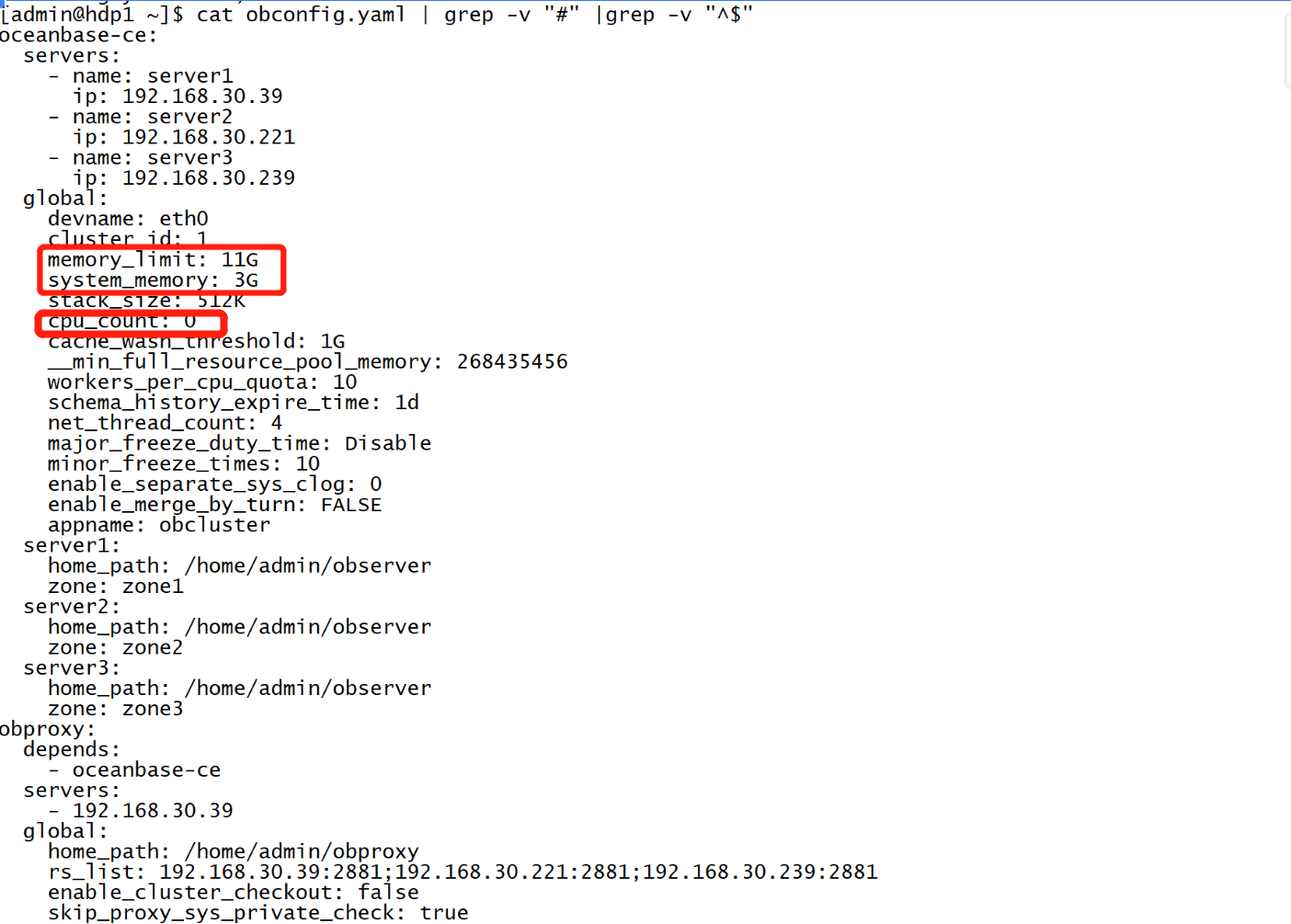
除了cpu_count,还有memor_limit、system_memory重要参数 。下图,cpu_count为0,observer识别6个核,实际我是8 个核 ,另外两个预留操作系统了。memor_limit为11G,system_memory为3G,因此observer识别了8G。
OceanBase的资源管理目前只能对CPU和内存进行管理,资源池总和是6C3,8G3,我们看到下面cpu_free和mem_free对应的3.5和6,谁占用了资源?
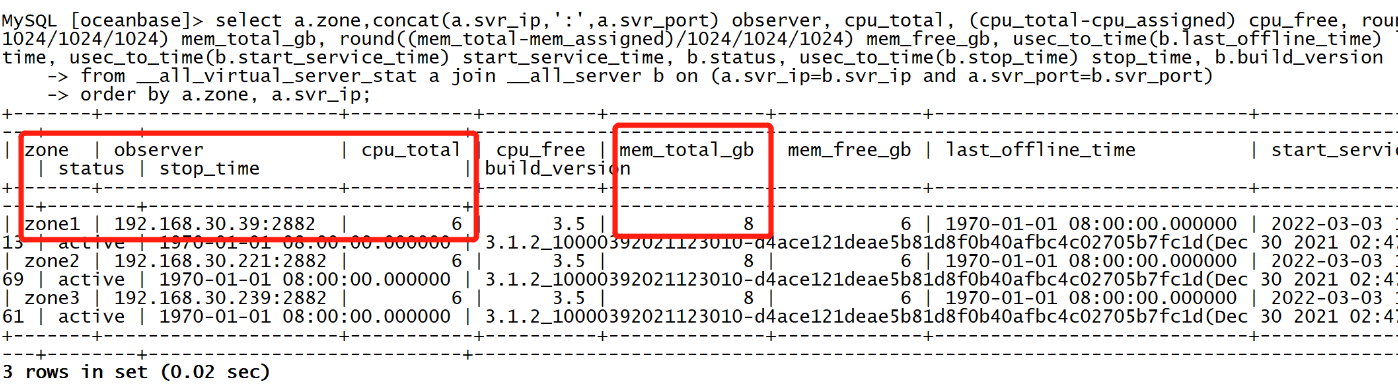
系统初始化的sys租户占用了资源,OceanBase默认会创建一个sys_pool资源池,sys_pool默认绑定sys租户。min_cpu是2.5,max_cpu是5, max_mem_gb和min_mem_gb是2G内存,正好与分配的资源对应上。sys租户的资配分配最小保障从zone1的指定主机拿2c和2g,从zone2的指定主机拿2c和2g,从zone3的指定主机拿2c和2g,最大可以使用5c和2G。
集群物理环境如下
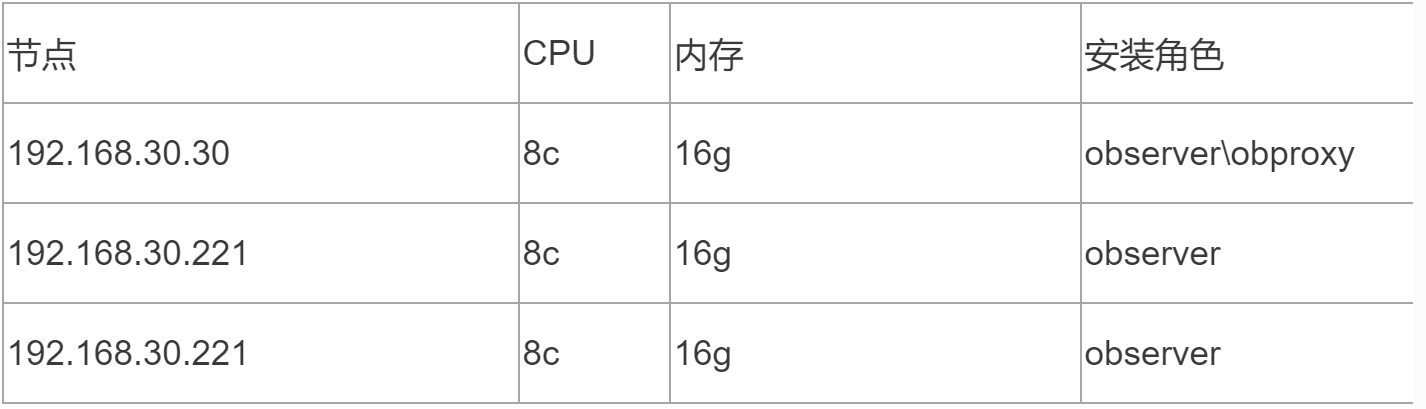
我只有三个机器,只能把observer和obproxy安装在一块了,obproxy可以理解数据库的长资源池,按理应该独立分开,另外找一个主机安装。尴尬的地方在这里,我只有三个低配的机器,很有限的资源,实际上我能用的sys租户最多占用集群的15个CPU,6G内存。下面再看数据库服务端的参数配置。
数据库调优思路
目前主流数据库技术有B树和LSM两种流派,两者的共同点对数据处理具有以下技术环节 是否缓冲、是否不可变性、是否有顺序,三个属性贯穿了数据的生命周期。缓冲一词在Oracle里面指的是SGA,在postgres里面指的shared_buffer,在MySQL的innodb里面叫做Innodb_buffer_pool,缓冲下面还有很多相关的小指标,缓冲的作用就是尽可能利用内存,尽量减少访问硬盘,缓存的数据对象下一步转换,它是转换成一个不可变的对象还是可变的对象,决定持久化到硬盘里面是是有序的数据格式文件还是无序的数据格式文件。
LSM与B树不同,B树是页面为基本单位的有序的堆存储结构,LSM的持久化却是无序的sstable文件,而且LSM的缓存数据即memtable,转储后是一个不可变的数据对象,B树却是可变的数据对象。 我们要找出OceanBase从内存缓存到数据不可变性,数据不可变化到数据落盘持久形成无序sstable文件涉及到的指标参数,归类如下。
缓存
memory_chunk_cache_size 用于设置内存分配器缓存的内存块容量。当 memory_chunk_cache_size 配置项的值为 0 时,表示系统自适应。
alter system set memory_chunk_cache_size =‘0’;
memstore_limit_percentage 用于设置租户使用 memstore 的内存占其总可用内存的百分比。
alter system set memstore_limit_percentage = 80;
/*
parallel_max_servers推荐设置为测试租户分配的resource unit cpu数的10倍
如测试租户使用的unit配置为:create resource unit $unit_name max_cpu 26
那么该值设置为260
parallel_server_target推荐设置为parallel_max_servers * 机器数0.8
那么该值为2603*0.8=624
*/
set global parallel_max_servers=260;
set global parallel_servers_target=624;
write_throttling_trigger_percentage 用于设置写入速度的阈值。
alter system set writing_throttling_trigger_percentage=100 tenant=xxx;
不可变性
enable_merge_by_turn 用于设置是否开启轮转合并策略。
alter system set enable_merge_by_turn = False;
merger_warm_up_duration_time 用于设置合并时,新版基线数据的预热时间。
alter system set merger_warm_up_duration_time='0';
merger_switch_leader_duration_time 用于设置每日合并时批量切主的时间间隔。
alter system set merger_switch_leader_duration_time='0';
large_query_worker_percentage 用于设置预留给处理大查询的工作线程百分比。
alter system set large_query_worker_percentage=10;
minor_merge_concurrency 用于设置小合并时的并发线程数。
alter system set minor_merge_concurrency=30;
minor_freeze_times 用于设置多少次小合并触发一次全局合并。值为 0 时,表示关闭小合并。
alter system set minor_freeze_times=500;
minor_compact_trigger 用于控制分层转储触发向下一层下压的阈值。当该层的 Mini SSTable 总数达到设定的阈值时,所有 SSTable 都会被下压到下一层,组成新的 Minor SSTable。
alter system set minor_compact_trigger=5;
use_large_pages 用于管理数据库使用的内存大页。
alter system set use_large_pages='true';
freeze_trigger_percentage 用于设置触发全局冻结的租户使用内存阈值。
alter system set freeze_trigger_percentage = 30;
memory_limit_percentage 用于设置系统总可用内存大小占总内存大小的百分比。
alter system set memory_limit_percentage = 85;
write_throttling_maximum_duration 通过控制内存分配进度,控制写入速度。即指定在触发写入限速后,剩余 memstore 内存分配完所需的时间。
alter system set writing_throttling_maximum_duration='1h';
cpu_quota_concurrency 用于设置租户的每个 CPU 配额所允许的最大并发数。
alter system set cpu_quota_concurrency = 4;
minor_warm_up_duration_time 用于设置小合并产生新转储文件的预热时间。
alter system set minor_warm_up_duration_time = 0;
minor_freeze_times 用于设置多少次小合并触发一次全局合并。值为 0 时,表示关闭小合并。
alter system set minor_freeze_times=500;
minor_compact_trigger 用于控制分层转储触发向下一层下压的阈值。
当该层的 Mini SSTable 总数达到设定的阈值时,所有 SSTable 都会被下压到下一层,组成新的 Minor SSTable。
alter system set minor_compact_trigger=3;
sys_bkgd_io_high_percentage 用于设置系统后台 IO 最高占用百分比。
alter system set sys_bkgd_io_high_percentage = 90;
用于 ha_gts 的刷新,刷新频率由配置项 gts_refresh_interval 控制。
alter system set gts_refresh_interval='500us';
major_freeze_duty_time 用于设置每日定时冻结和合并的触发时刻。
alter system set major_freeze_duty_time='disable';
zone_merge_concurrency 用于设置在合并时,支持多少个 Zone 并发。当值为 0 时,由系统根据部署情况自动选择最佳并发度。
alter system set zone_merge_concurrency=0;
有序的sstable
alter system set max_kept_major_version_number=1;
sys_bkgd_io_high_percentage 用于设置系统后台 IO 最高占用百分比。
alter system set sys_bkgd_io_high_percentage = 90;
sys_bkgd_io_low_percentage 用于设置系统后台 IO 最少占用的百分比。
alter system set sys_bkgd_io_low_percentage = 70;
merge_thread_count 用于设置每日合并工作的线程数。
alter system set merge_thread_count = 45;
merge_stat_sampling_ratio 用于设置合并时候数据列统计信息的采样率。
alter system set merge_stat_sampling_ratio = 1;
write_throttling_trigger_percentage 用于设置写入速度的阈值。
alter system set writing_throttling_trigger_percentage=75 tenant=xxx;
write_throttling_maximum_duration 通过控制内存分配进度,控制写入速度。即指定在触发写入限速后,剩余 memstore 内存分配完所需的时间。
alter system set writing_throttling_maximum_duration='15m';
##为频繁空查的宏块建立bloomfilter并缓存,减少磁盘IO和CPU消耗,提升写入性能
bf_cache_priority 用于设置 Bloom Filter 缓存优先级。
alter system set bf_cache_priority = 10;
user_block_cache_priority 用于设置数据块缓存在缓存系统中的优先级。
alter system set user_block_cache_priority=5;
其它管理指标
alter system set trx_try_wait_lock_timeout='0ms';
large_query_threshold 用于设置查询执行时间的阈值。超过时间的请求可能被暂停,暂停后自动被判断为大查询,执行大查询调度策略。
alter system set large_query_threshold='1s';
trace_log_slow_query_watermark 用于设置查询的执行时间阈值,如果查询的执行时间超过该阈值,则被认为是慢查询,慢查询的追踪日志会被打印到系统日志中。
alter system set trace_log_slow_query_watermark='500ms';
syslog_io_bandwidth_limit 用于设置系统日志所能占用的磁盘 IO 带宽上限,超过带宽上限容量的系统日志将被丢弃。
alter system set syslog_io_bandwidth_limit='30m';
enable_async_syslog 用于设置是否启用系统日志异步写。
alter system set enable_async_syslog=true;
builtin_db_data_verify_cycle 用于设置数据坏块自检周期,单位为天。当值为 0 时表示不检查。
alter system set builtin_db_data_verify_cycle = 0;
enable_syslog_recycle 用于设置是否开启回收系统日志的功能。
alter system set enable_syslog_recycle='True';
max_syslog_file_count 用于设置在回收日志文件之前可以容纳的日志文件数量。
alter system set max_syslog_file_count=100;
ob_plan_cache_percentage 用于设置计划缓存可以使用的租户内存资源的百分比。
set global ob_plan_cache_percentage=20;
enable_perf_event 用于设置是否开启性能事件的信息收集功能。
alter system set enable_perf_event='false';
micro_block_merge_verify_level 用于设置合并时宏块的校验级别。
0:表示不做校验
1:表示验证编码算法,将读取编码后的微块以确保数据正确
2:表示验证编码和压缩算法,除编码验证外,还将对压缩块进行解压缩以确保数据正确
3:表示验证编码,压缩算法和丢失写保护
alter system set micro_block_merge_verify_level=0;
builtin_db_data_verify_cycle 用于设置数据坏块自检周期,单位为天。当值为 0 时表示不检查。
alter system set builtin_db_data_verify_cycle=20;
_flush_clog_aggregation_buffer_timeout 配置说明设置 Clog 日志聚合的等待时间。对于大量并发 Insert/Update 的事务,适当增加等待时间能够提高性能,但是有可能会增加事务的延迟。
alter system set _flush_clog_aggregation_buffer_timeout='1ms';
net_thread_count 用于设置网络 I/O 线程数。
alter system set net_thread_count=4;
ob_query_timeout 用于设置查询超时间,单位是微秒。
set global ob_query_timeout=36000000000;
ob_trx_timeout 用于设置事务超时间,单位为微秒。
set global ob_trx_timeout=36000000000;
max_allowed_packet 用于设置最大网络包大小,单位是 Byte。
set global max_allowed_packet=67108864;
ob_sql_work_area_percentage 用于 SQL 执行的租户内存百分比限制。
set global ob_sql_work_area_percentage=100;
server_permanent_offline_time 用于设置节点心跳中断的时间阈值,即节点心跳中断多久后认为其被永久下线,永久下线的节点上的数据副本需要被自动补足。
alter system set server_permanent_offline_time='36000s';
weak_read_version_refresh_interval 用于设置弱一致性读版本号的刷新周期,影响弱一致性读数据的延时。
alter system set weak_read_version_refresh_interval=0;
1 ms ~ 5 ms,最佳值需要根据实现业务进行调整。如果业务rt较长,可以适当调大该值
alter system set _ob_get_gts_ahead_interval = '5ms';
merge_stat_sampling_ratio 用于设置合并时候数据列统计信息的采样率。
alter system set merge_stat_sampling_ratio = 0;
enable_sql_audit 用于设置是否开启 SQL 审计功能。
alter system set enable_sql_audit=false;
max_syslog_file_count 用于设置在回收日志文件之前可以容纳的日志文件数量。
alter system set max_syslog_file_count=100;
enable_syslog_recycle 用于设置是否开启回收系统日志的功能。
alter system set enable_syslog_recycle='True';
ob_enable_batched_multi_statement 用于设置是否启用批处理多条语句的功能。
alter system set ob_enable_batched_multi_statement=true tenant=all;
用于 KV Cache 的内存清洗。通过配置项 _cache_wash_interval 来控制检测周期,默认是 200ms,取值范围为 [1ms,1m]。
alter system set _cache_wash_interval = '1m';
plan_cache_evict_interval 用于设置执行计划缓存的淘汰时间间隔。
alter system set plan_cache_evict_interval = '30s';
enable_one_phase_commit 用于设置是否开启事务提交一阶段优化的功能。
alter system set enable_one_phase_commit=false;
schema_history_expire_time 用于设置元数据历史数据过期时间。
alter system set schema_history_expire_time='1d';
enable_syslog_wf 用于设置是否把 WARN 以上级别的系统日志打印到一个单独的日志文件中。
alter system set enable_syslog_wf=false;
server_permanent_offline_time 用于设置节点心跳中断的时间阈值,即节点心跳中断多久后认为其被永久下线,永久下线的节点上的数据副本需要被自动补足。
alter system set server_permanent_offline_time='36000s';
enable_sql_operator_dump 用于设置是否允许 SQL 处理过程的中间结果写入磁盘以释放内存。
alter system set enable_sql_operator_dump=True;
enable_clog_persistence_compress 用于设置是否开启事务日志落盘压缩。
alter system set enable_clog_persistence_compress = true;
clog_persistence_compress_func 用于设置事务日志落盘压缩算法。
alter system set clog_persistence_compress_func = "zstd_1.0";
cache_wash_threshold 用于设置触发缓存清理的容量阈值。如果内存空间小于指定值时,内存空间将被清理。
alter system set cache_wash_threshold='30g';
server_data_copy_out_concurrency 用于设置单个节点迁出数据的最大并发数。
alter system set server_data_copy_out_concurrency=1000;
server_data_copy_in_concurrency 用于设置单个节点迁入数据的最大并发数。
alter system set server_data_copy_in_concurrency=1000;
clog_transport_compress_all 用于设置事务日志传输时是否压缩。
alter system set clog_transport_compress_all=false;
_clog_aggregation_buffer_amount
配置说明设置 Clog 日志聚合的 Buffer 数量。该配置项的值大于 0 会开启 Clog 日志聚合功能。开启 Clog 日志聚合功能会增加内存的消耗
alter system set _clog_aggregation_buffer_amount=4
enable_early_lock_release 用于设置是否开启提前解行锁的功能。
alter system set enable_early_lock_release=false ;
enable_perf_event 用于设置是否开启性能事件的信息收集功能。
alter system set enable_perf_event=false;
enable_auto_leader_switch 用于设置是否开启自动切主。
alter system set enable_auto_leader_switch=false;
plan_cache_evict_interval 用于设置执行计划缓存的淘汰时间间隔。
alter system set plan_cache_evict_interval = '30s';
enable_one_phase_commit 用于设置是否开启事务提交一阶段优化的功能。
alter system set enable_one_phase_commit=false;
enable_monotonic_weak_read 用于设置是否开启单调读。
alter system set enable_monotonic_weak_read = false;
obproxy
enable_strict_kernel_release是否需要校验 OS kernel。
取值范围:
true:仅 5u/6u/7u 规格的 RedHat 操作系统支持校验。
false:不校验 OS kernel,但 Proxy 可能不稳定。
alter proxyconfig set enable_strict_kernel_release=false;
automatic_match_work_thread
是否根据 CPU 核数自动创建工作线程。如果该选项为 true,上限为 work_thread_num。
alter proxyconfig set automatic_match_work_thread=false;
关闭压缩,减少 OBProxy 对 CPU 的占用。需要重启 OBProxy 机器才能生效。
alter proxyconfig set enable_compression_protocol=false; --关闭压缩,降低cpu%
命令行安装的 OBProxy 若没有显式指定 OBProxy 的内存,则 proxy_mem_limited的默认 值为 800 MB,您可以先尝试调整为 2 GB。
alter proxyconfig set proxy_mem_limited='4G'; --防止oom
示例语句如下所示,一般修改配置项slow_transaction_time_threshold即可,配置项 slow_proxy_process_time_threshold默认值为 2 ms,该值适用于绝大多数场景。
alter proxyconfig set slow_proxy_process_time_threshold='500ms';
OBServer 的 V2 协议开关,默认值为 false
alter proxyconfig set enable_ob_protocol_v2=false;
syslog_level 用于设置系统日志级别。
alter proxyconfig set syslog_level='error';
是否需要校验 OS kernel。 取值范围: * true:仅 5u/6u/7u 规格的 RedHat 操作系统支持校验。 * false:不校验 OS kernel,但 Proxy 可能不稳定。
alter proxyconfig set enable_strict_kernel_release=false;
是否根据 CPU 核数自动创建工作线程。如果该选项为 true,上限为 work_thread_num。
alter proxyconfig set automatic_match_work_thread=false;
OBProxy 工作线程数。 当 automatic_match_work_thread 为true 时,表示最大工作线程数。
alter proxyconfig set work_thread_num=128;
enable_monotonic_weak_read 用于设置是否开启单调读。
alter system set enable_monotonic_weak_read = false;
上述参考官方的sysbench测试、tpc-h测试以及tpcc的最佳实践需要用上的数据库参数指标,根据笔者理解的关键数据库性能优化指标缓存相关的指标、不可变性相关的指标、sstable相关的指标做了抽象理解,可能笔者在这里的分类有些偏差。
总结
- 尽可能提高数据转储能力【包括线程、容量、延长时间、】
- 尽可能提高数据计算处理能力【包括线程、缓存、百分比、】
- 提高缓存相应的指标需求【包括obproxy以及minor】
- 尽可能避开大数据合并【major以及轮转合并】
- 可选,根据系统特性选择【压缩、功能特性专项】
- 关闭与数据处理无关的东西,争取更多的系统资源【例如日志压缩、中间日志压缩】
副本分布和详细数据分布
数据分布同样是影响数据库性能的一个因素,Oceanbase通过TableGroup控制有相关性的一组表在物理存储上的临近关系,避够跨网络活动,例如tablegroup=‘tpcc_group’ partition by hash(s_w_id) partitions 128;
以下命令发现在leader多集中在zone1,租户的bmsql_confg、bmsql_item以及sbtest1至sbtest10的表相关的主副本都集中在Zone1,流量汇聚到Zone1,假设运行OLTP业务场景的操作可以大大减少跨网络操作。
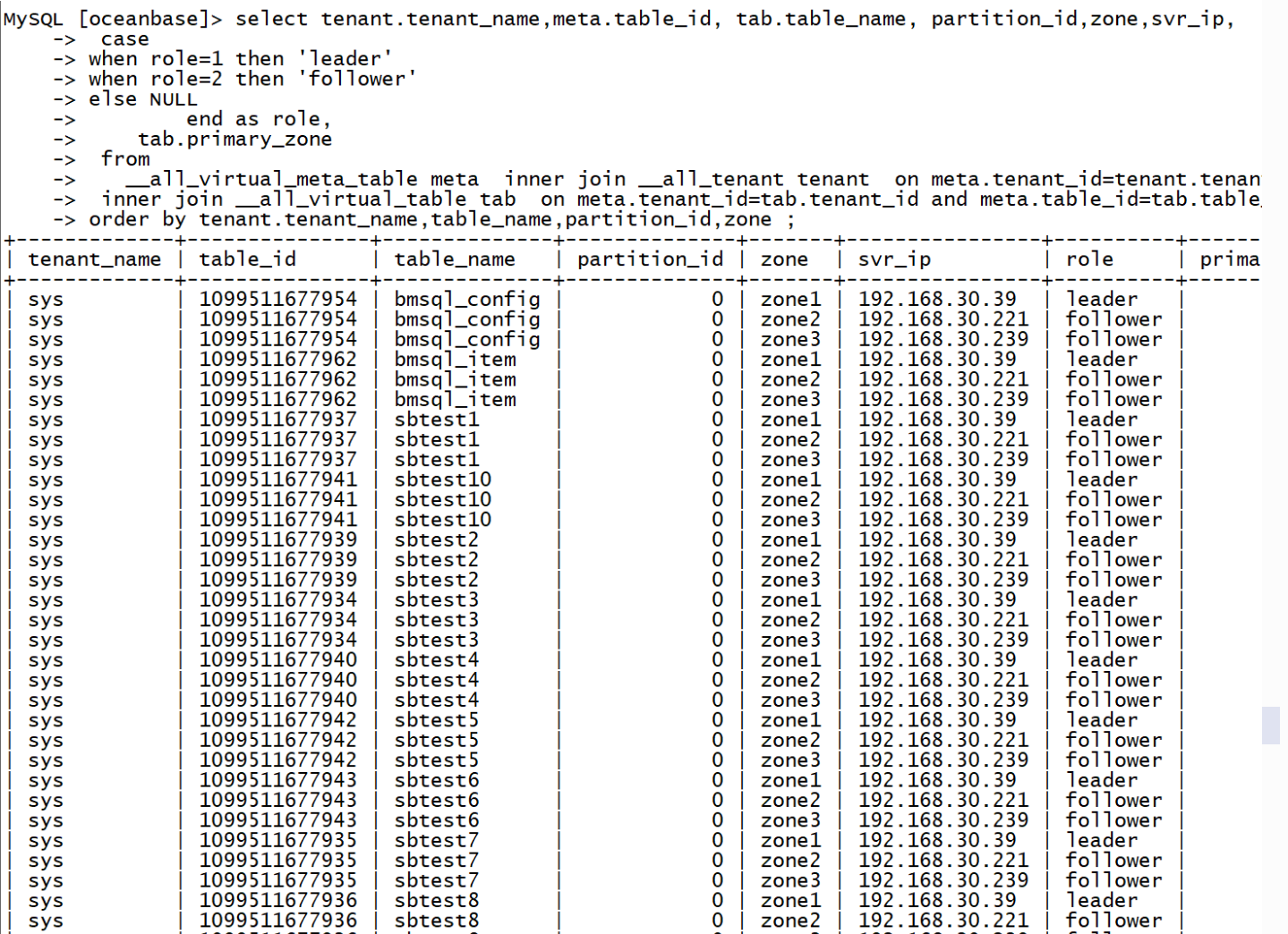
检查一下数据落地分布均匀情况。输入以下命令检测表分区的数据分布均匀不均匀,是否存在一个分区容量太大,另外一个分区数量太小。
select p.partition_id,p.row_count
from oceanbase.gv$partition p,oceanbase.gv$table t
where t.table_id=p.table_id
and t.tenant_id=‘租户’
and t.table_name=‘表名’
and p.role=1;
合并与布隆过滤数
确认OceanBase工作不会受外部进程的影响,然后确认里面不会受到内部的影响。LSM的过程中,尤其增量数据与基线数据要耗费大量的IO,以下命令可以确认没有发生合并行为。

sstable还涉及到一个重要性能参数布隆过滤数,前面说到LSM持久化到硬盘上将是无序的sstable基线数据文件,如果数据不在内存,OceanBase需要遍历较多的sstable文件。而B树正好相方,因为所有的文件都是有序摆放,因此读的时候,可以较少的IO读写完成任务。而写数据的时候,特别是增加数据或删除数据都会引起页合并或页分裂,反而写会差一点。B树擅长读多写少的业务场景,LSM擅长写多读少的业务,那么LSM怎么去增强读的性能,答案就是布隆过滤数算法,通过布隆过滤数可以找出查找的最大可能性在哪一个sstable文件上,不至于全部的硬盘文件都搜索一遍,开启布隆过滤数应该会增加CPU的负荷,会读会好一点,但是对修改、删除不好,hbase等sstable的存储组织均支持布隆过滤数。OceanBase默认没有开启布隆过滤数,TPCC的场景测试。官方OceanBase也没有开启布隆过滤数, 开启布隆过滤数的方法如下。
create table test_bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24),
PRIMARY KEY (s_w_id, s_i_id)
)tablegroup=‘tpcc_group’ use_bloom_filter=true compression = ‘zstd_1.3.8’ partition by hash(s_w_id) partitions 128;
索引分区
索引和分区,这个没啥好说了,主键索引建立在唯一的ID上面,分区与搜索关键词关联,索引分区完全是应用建模的事情,OceanBase提供全局索引和本地索引两种方式,没有那一种索引更快的说法。本质上,本地索引指向的数据在实体组管理的副本构建,而全局索引指向的数据在跨实体组管理的副本外构建。真正应用时,可以设一个本地索引和全局索引,然后跑查询计划,看看哪一边的代价更高,然后设不同的索引。OceanBase的官方tpc-h测试有些表用的是本地索引,tpc-h跑的是批处理,本地索引的设计,更数据容易均匀分布在多个节点上,让计算贴近数据。见下。
create index I_L_ORDERKEY on lineitem(l_orderkey) local;
create index I_L_SHIPDATE on lineitem(l_shipdate) local;
其它特性
OceanBase与Oracle一样,支持强行启用并行度来执行当前SQL,通过启用多线程处理提高处理能力。以下
SELECT /*+ parallel(96) */ —增加 parallel 并发执行
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price
最后的开始
分布式数据库的性能首先第一与硬盘IO、网络吞吐【接入层、汇聚层、核心层】、CPU、内存有关系,第二与数据库的关键核心参数有关系, 第三与数据库的活动状态有关系,第四与数据分布和数据计算算子有关系,第五与逻辑建模和应用建模有关系。
到底要不要展开做tpc-h测试,按照我现在掌握的全面情况,无论是进行tpc-h测试还是tpcc测试、sysbench ,即使我调优调得再好都会把OceanBase测成渣,因为当前的sys租户合计最多占用集群的15个CPU,6G内存,远远低于总体性能,1不能发挥硬件总体性能威力, 2不能发挥分布式原有威力,搞不好还不如调优好的一个基于8C、16G的mysql单体数据库。
下面有时间将展开测试去综合调优。
