




记我的职业成长之路(盖国强)
题记
这是某移动运营商在SQL线下审核项目中,协助开发商完善数据库性能的过程。以往开发商遇到此问题总是怀疑是数据库的Bug,试图尝试重启Tuxedo、Weblogic,严重时甚至重启实例来缓解问题。经过下面的详细分析,你会发现事实并非如此。
9.1 详细诊断过程
这是对于两个节点的RAC环境,数据库版本为11.2.0.4 for HP-UX IA(64-bit)。在2014年11月5日16点至18点间,节点一的CPU使用率从平时的40%增长到60%左右,部分业务办理缓慢甚至超时。经过详细分析,发现是一个低效的、高并发的核心业务的SQL语句引起的。
通过询问业务人员得知,业务系统从17:00至17:30感觉慢得更为明显,因此我们导出了该时间段节点二的AWR报告。
图9-1显示了实例名为crmdb21的采样时间、数据库版本、CPU个数和内存大小等概要信息,通过简单的换算DB Time和Elapsed可知(2807.24/29.7=94),这台64 Cores的小型机的确很忙。
如图9-2所示,Load Profile中的Logical read(blocks)973915.2/Per Second表明平均每秒产生的逻辑读blocks数约为97万,每秒的逻辑读约有7.6G(973915*db_block_size=7.6GB/s),一般来说,逻辑读高CPU的使用率也会随之升高,通常会在Top 10中出现诸如latch: cache buffers chains、db file scattered read等事件。
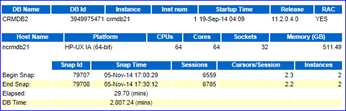
图9-1
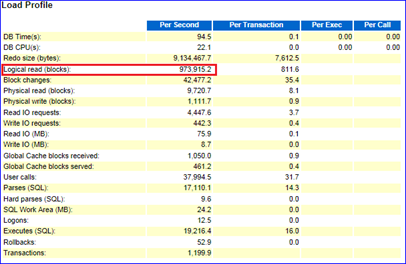
图9-2
如图9-3所示,在Top 10 Foregrand Events by Total Wait Time的部分,可以看到在该时间段的主要等待事件是latch:cache buffers chains 和 db file sequential read。它们的%DB Time分别占到38.9%和24.3%。后者代表单块读,是一种比较常见的物理IO等待事件,通常在数据块从磁盘读入到相连的内存空间中时发生,也可能是SQL语句使用了selectivity不高的索引,从而导致访问了过多不必要的索引块或者使用了错误的索引,这些等待说明SQL语句的执行计划可能不是最优的。前者是导致数据库逻辑读高的根本原因,由此推断某个或者某些SQL语句出现了性能衰变。在接下来的SQL Statistics部分,分别截取了SQL ordered by Elapsed Time和 SQL ordered by Gets。如图9-4和9-5所示,可以发现SQL Id=g5z291fcmwz08的语句分别占了42.50%的DB Time和35.19%的逻辑读,而其他SQL所占的DB Time和逻辑读分别在0.1%~5%。由此可以确定,就是该SQL语句影响系统性能,但还需要详细了解该SQL的执行计划、绑定变量和当时的逻辑读等信息。图9-4显示了该SQL的文本。
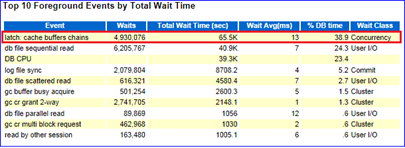
图9-3
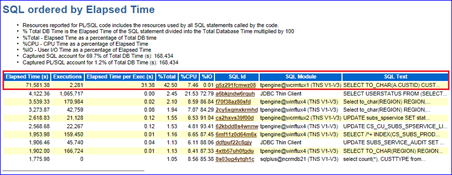
图9-4
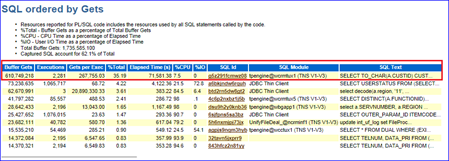
图9-5
SELECT TO_CHAR(A.CUSTID) CUSTID,
TO_CHAR(A.REGION) REGION,
A.CUSTNAME CUSTNAME,
A.SHORTNAME SHORTNAME,
A.CUSTTYPE CUSTTYPE,
A.VIPTYPE VIPTYPE,
TO_CHAR(A.FOREIGNER) FOREIGNER,
A.CUSTCLASS1 CUSTCLASS1,
A.CUSTCLASS2 CUSTCLASS2,
A.NATIONALITY NATIONALITY,
A.ADDRESS ADDRESS,
A.CERTID CERTID,
A.CERTTYPE CERTTYPE,
A.CERTADDR CERTADDR,
A.LINKMAN LINKMAN,
A.LINKPHONE LINKPHONE,
A.HOMETEL HOMETEL,
A.OFFICETEL OFFICETEL,
A.MOBILETEL MOBILETEL,
A.POSTCODE POSTCODE,
A.LINKADDR LINKADDR,
A.EMAIL EMAIL,
A.HOMEPAGE HOMEPAGE,
TO_CHAR(A.ISMERGEBILL) ISMERGEBILL,
A.ORGID ORGID,
A.CREATEDATE CREATEDATE,
A.NOTES NOTES,
A.STATUS STATUS,
A.STATUSDATE STATUSDATE,
A.RESPONSECUSTMGR RESPONSECUSTMGR,
A.CURRENTCUSTMGR CURRENTCUSTMGR,
A.CREDITLEVEL CREDITLEVEL,
TO_CHAR(A.INLEVEL) INLEVEL,
A.REGSTATUS REGSTATUS,
A.OWNERAREAID OWNERAREAID,
A.CERTSTARTDATE CERTSTARTDATE,
A.CERTENDDATE CERTENDDATE,
A.COUNTRYID COUNTRYID
FROM CUSTOMER A, PERSON_CUSTOMER B
WHERE A.CUSTID = B.CUSTID
AND A.CUSTTYPE = :CUSTTYPE
AND A.CERTID = :CERTID
AND A.CERTTYPE IN ('BusinessLicence')
ORDER BY DECODE(A.STATUS, 'stcmNml', 0, 1) ASC
通过分析可以导出该SQL Report。如图9-6所示,记录了故障时间段SQL Id=g5z291fcmwz08的SQL概要信息。如图9-7所示,可以发现该SQL在30分钟内执行了2281次,单次的逻辑读在267755.03,由此很可能认为这个SQL始终没有走到合适的索引或者是全表扫描。值得关注的是267755.03这个数字,它是一个平均值,很有可能被平均,换句话说,有时单次逻辑读很小、有时可能还会大于这个平均值。如图9-8所示的执行计划中,先通过索引IDX_CUSTOMER_CERTID过滤出2条数据,之后回CUSTOMER表得到1条记录,再通过结果集去驱动查询主键PK_CM_CU_INDIVIDUAL,最后通过嵌套循环返回结果集。看上去每一步的Rows和Cost都非常理想,实际上存在4点值得关注的隐患。
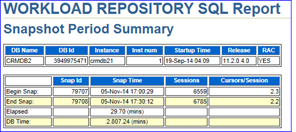
图9-6
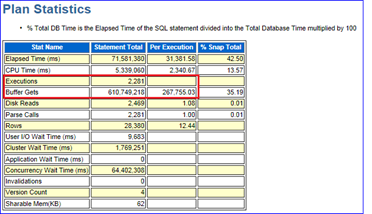
图9-7
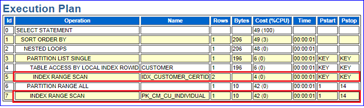
图9-8
(1)Rows或Cost仅代表一个估算值。
(2)谓词条件中用到的索引列都是绑定变量,在遇到绑定变量+窥视关闭(该数据库窥视关闭)时,即使有直方图信息,优化器在估算时总是认为数据分布是平均的。
(3)在扫描索引PK_CM_CU_INDIDUAL时,扫描了1到14个分区。
(4)CUSTOMER表返回的记录数稍有偏差,将会增加与PK_CM_CU_INDIDUAL索引循环的次数,也会影响整个查询的性能。
在继续往下分析之前,开发人员抛出一个疑问,为什么同一个SQL在其他两个库都正常,而在这个库却出现了问题?通过以下查询不难发现,这个SQL在每一个库的单次平均逻辑读都相似,见图9-9。从执行次数上看,其他两个库基本维持在几十或上百次,而在故障库中峰值高达2281次,这同样是故障点的执行次数。这表明该SQL的性能是低效的,对数据库造成的性能冲击也是随着执行次数的增加而愈演愈烈的。
select *
from (select BEGIN_INTERVAL_TIME,
a.instance_number,
plan_hash_value,
EXECUTIONS_DELTA exec,
round(BUFFER_GETS_DELTA / EXECUTIONS_DELTA) per_get,
round(ROWS_PROCESSED_DELTA / EXECUTIONS_DELTA, 1) per_rows,
round(ELAPSED_TIME_DELTA / EXECUTIONS_DELTA / 1000000, 2) time_s,
round(DISK_READS_DELTA / EXECUTIONS_DELTA, 2) per_read
from dba_hist_SQLstat a, DBA_HIST_SNAPSHOT b
where a.snap_id = b.snap_id
and EXECUTIONS_DELTA <> 0
and a.instance_number = b.instance_number
and a.SQL_id = ‘g5z291fcmwz08’
order by 1 desc)
where rownum < 30;
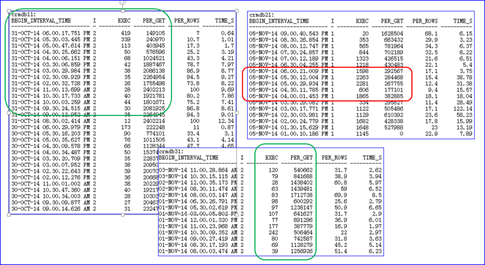
图9-9
谓词条件中用到了绑定变量,需要找到当时的绑定变量值来看真实的执行计划。
select name,value_string,last_captured From dba_hist_SQLbind
Where SQL_id= ’g5z291fcmwz08’ Order by last_captured desc
NAME VALUE_STRING LAST_CAPTURED
------------- ---------------------- -----------------
:CERTID 1xxx1159440(20141025) 2014/11/5 18:27
:CUSTTYPE 1 2014/11/5 18:27
:CUSTTYPE 1 2014/11/5 18:17
:CERTID 3xxxxxxxx0402040 2014/11/5 18:05
:CUSTTYPE 1 2014/11/5 18:05
:CERTID 3xxxxxxxx402044 2014/11/5 17:47
:CUSTTYPE 1 2014/11/5 17:47
:CERTID 3xxxxxxxx402045 2014/11/5 16:50
:CUSTTYPE 1 2014/11/5 16:50
:CERTID 3xxxxxxxx402056 2014/11/5 16:00
:CUSTTYPE 1 2014/11/5 16:00
:CERTID 3xxxxxxxx402045 2014/11/5 15:50
:CUSTTYPE 1 2014/11/5 15:50
在上述分析中提到,“如果CUSTOMER表返回的记录数稍有偏差,将会增加与PK_CM_CU_INDIDUAL索引循环的次数,从而影响整个查询的性能”。在回表之前先通过索引字段CERTID过滤数据,该字段的数据分布非常重要。即该字段的值是否存在数据倾斜至关重要,下面对其进行统计。
select CERTID, count(*)
from tbcs.CUSTOMER partition(p_l_1) a
where CERTID in ('1xxxxxx00402045',
'1xxxxxx9440(20141025)',
'3xxxxxx00402040',
'3xxxxxx00402056',
'3xxxxxx00402045',
'3xxxxxx00402044',
'1xxxxxx4473(20141025)')
group by CERTID;
CERTID COUNT(*)
----------------------- -----------
1xxxxxx9440(20141025) 1
1xxxxxx4473(20141025) 1
3xxxxxx00402040 45
3xxxxxx00402044 14
3xxxxxx00402045 59084
3xxxxxx00402056 1
3xxxxxx00402045 4
结果很明显,该字段使用过的值出现了严重的数据倾斜。我们把3xxxxxx00402045代入WHERE条件,通过/+gather_plan_statistics/查看优化器的估计值与真实值之间的差异。在扫描IDX_CUSTOMER_CERTID索引时,估算值是1,而实际值是59106,回表之后的记录数依然是59106,这表明至少要和下面的索引关联59106次,被驱动表恰巧共有14个分区,循环的次数就变成了59106×14 次,这也是单次逻辑高达2503731的原因,如图9-10所示。
说明,/+gather_plan_statistics/这个提示会记录每一步操作中真实返回的行数(A-Rows)、逻辑读(Buffers)和耗费的时间(A-Time)。
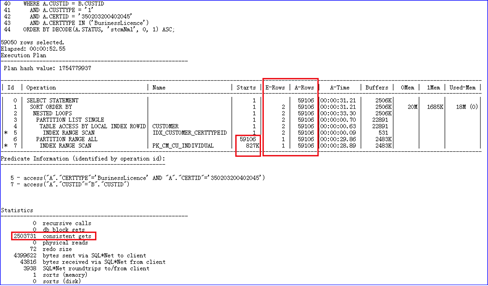
图9-10
同时也测试了一个不倾斜的值进行对比(3xxxxxx00402044),发现逻辑读只有760,这说明了该SQL被执行的次数越多,逻辑读就会被平均得更小,如图9-11所示。
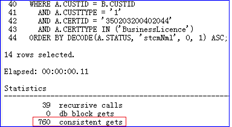
图9-11
经过以上分析可知,数据倾斜、全分区扫描、执行次数三者相加之和的增加使得该SQL的性能影响了整个系统。接下来从两个方面对其进行优化。
(1)从SQL方面。
编写一个新SQL专门针对倾斜值,用HASH JOIN替代默认的NEST LOOP。
(2)从业务方面。
1)检查倾斜数据的合理性。
2)在访问PERSON_CUSTOMER表时,可以增加分区字段加以限制,从而避免扫描多余的分区。
3)梳理业务场景。
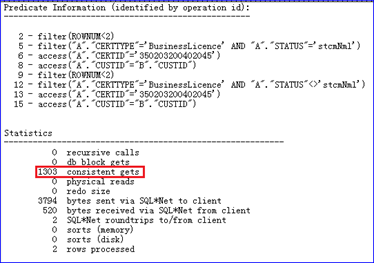
通过和开发人员、业务人员反复沟通确认,该条SQL在业务场景和数据倾斜上都是可以修正和清理的。在完全满足业务场景的前提下,开发人员对SQL做了调整,通过改写union all和rownum <2,有效合理地控制了返回的记录数,逻辑读也从26万降低到了1303,性能提升了近200倍,如图9-12所示。从中发现,这个案例的优化过程也是围绕技术和业务反复优化的过程。
select ….
FROM CUSTOMER A, PERSON_CUSTOMER B
WHERE A.CUSTID = B.CUSTID
AND A.CUSTTYPE = :CUSTTYPE
AND A.CERTID = :CERTID
AND A.CERTTYPE IN ('BusinessLicence')
AND A.STATUS = 'stcmNml'
AND ROWNUM < 2
union all
select …
FROM CUSTOMER A, PERSON_CUSTOMER B
WHERE A.CUSTID = B.CUSTID
AND A.CUSTTYPE = :CUSTTYPE
AND A.CERTID = :CERTID
AND A.CERTTYPE IN ('BusinessLicence')
AND A.STATUS != 'stcmNml'
AND ROWNUM < 2
9.2 总结
在移动运营商SQL审核项目的交付过程中,和大家分享以下几点。
(1)在AWR、SQL Report中Per所对应的往往是平均值,需要结合执行计划和数据分布来分析该平均值是否真实可靠。
(2)当全分区扫描出现在执行计划中时,需要结合业务判断其合理性。
(3)绑定变量的历史值和其数据分布能够提高分析问题的精确性。
(4)提高SQL的性能存在着多种优化方法,随着系统本身和系统架构的推进,SQL优化需要结合技术、数据特点、业务场景等要素综合分析,从而才能给客户提出一套完整、全面、可执行的优化方案。
