




技术的学习是一个不断深入和扩展的过程,在拥有一定的技术基础后,需要不断在应用旧知识的过程中去挖掘新知识,丰富自己对一项技能或者一个领域的认识,主动实现从菜鸟到专家的自我升华。同时,每一个独立的技术领域都包含很多方面。就拿Oracle来说,内核研究、架构分析、故障处理、性能优化等各方面都是完整的模块。对于一个做运维的人来说,当然要求每个方面的知识都要有所了解,有全局的概念。但最重要的,是要发现自己的特长,找到最合适的方向深入探究,样样通不如一样精。我最初在接触Oracle的时候,也是全面攻击,但随着我对一些基础知识的掌握,对于整体架构的了解,我开始去摸索一个具体的方向。作为一个数据运维者,每天都要处理各种各样的故障。最初由于经验不足,虽然感觉各方面的知识都具备,但遇到问题却不会分析。因为任何一个简单的故障,都会涉及运维的很多方面,除了数据库本身,还包含存储或者网络等其他各种因素。但我渐渐发现,在处理故障的过程中,我会重新梳理自己的知识树。每次完整地处理一个故障后,就会对各方面的知识有更全面的认识。有时候这种完善来自于技术细节,有时候会给我一个更广阔的眼界去认识我所面对的数据,这让我很快成长。而这样的成长过程,除了在故障中去锻炼,其他任何方式都代替不了。也许有人会问我学习或者分析问题的方法技巧。我要说,学习技术只有一个方法,那就是常反思常总结。也许某些技术是短期不变的,但对于技术的认识一定要随着我们学习的深入不断变化。接下来,我通过几个真实案例的分享,来跟大家简单介绍我分析、解决问题的思路。这几个案例包含数据运维的很多方面。其中前三篇关于内存及参数的管理,接下来两篇是有关SQL及索引的性能,最后是使用数据泵和ogg进行迁移的时候遇到的故障分析。希望这几个案例能够对今后大家处理各类故障有所帮助。
13.1 一波三折:释放内存导致数据库崩溃的案例
这是我一个运营商客户的案例。其现象大致是某天凌晨某RAC节点实例被重启了,通过如下的告警日志我们可以发现RAC集群的节点2实例被强行终止掉了,以下是详细的日志信息。
Mon Sep 28 02:00:00 2015
Errors in file /oracle/admin/xxx/bdxxx/xxx2_j000_7604.trc:
ORA-12012: error on auto execute of job 171538
ORA-06550: line ORA-06550: line 4, column 3:
PLS-00905: object XSQD.E_SP_DL_CRM_TERMINAL_MANAGER is invalid
ORA-06550: line 4, column 3:
PL/SQL: Statement ignored, column :
**Mon Sep 28 02:03:18 2015**
Errors in file /oracle/admin/xxx/udxxx/xxx2_ora_6810.trc:
ORA-00600: internal error code, arguments: [KGHLKREM1], [0x679000020], [], [], [], [], [], []
.....
Trace dxxxing is performing id=[cdmp_20150928023925]
Mon Sep 28 02:39:32 2015
Errors in file /oracle/admin/xxx/bdxxx/xxx2_lmd0_24228.trc:
ORA-00600: internal error code, arguments: [KGHLKREM1], [0x679000020], [], [], [], [], [], []
**Mon Sep 28 02:39:32 2015**
LMD0: terminating instance due to error 482
Mon Sep 28 02:39:33 2015
Shutting down instance (abort)
License high water mark = 145
Mon Sep 28 02:39:37 2015
Instance terminated by LMD0, pid = 24228
Mon Sep 28 02:39:38 2015
从上面的数据库告警日志来看,数据库实例2从2:03就开始报错ORA-00600 [KGHLKREM1],一直持续到2:39,lmd0进程开始报同样的错误,紧接着LMD0进程强行把数据库实例2终止掉了。如果参照上述ORA-00600错误,直接搜索Oracle MOS,可能会搜到以下结果,Bug 14193240 : LMS SIGNALED ORA-600[KGHLKREM1] DURING BEEHIVE LOAD。但是这个Bug很容易被排除,根据系统监控就可以直接排除。在故障期间系统负载是非常低的。
这里我们需要注意,从告警日志来看,从2:03就开始报错,然而直到lmd0进程报错时,实例才被其终止掉。不难看出,数据库节点2的lmd0报错才是问题的关键。那么我们首先来分析数据库节点2的lmd0 进程的trace文件内容。
*** 2015-09-28 02:39:24.291
***** Internal heap ERROR KGHLKREM1 addr=0x679000020 ds=0x60000058 *****
***** Dxxx of memory around addr 0x679000020:
678FFF020 00000000 00000000 00000000 00000000 [................]
…..
679000030 00000000 00000000 00000000 00000000 [................]
Repeat 254 times
Recovery state: ds=0x60000058 rtn=(nil) *rtn=(nil) szo=0 u4o=0 hdo=0 off=0
Szo:
UB4o:
Hdo:
Off:
Hla: 0
******************************************************
HEAP Dxxx heap name="sga heap" desc=0x60000058
extent sz=0x47c0 alt=216 het=32767 rec=9 flg=-126 opc=4
parent=(nil) owner=(nil) nex=(nil) xsz=0x0
ds for latch 1: 0x60042f70 0x600447c8 0x60046020 0x60047878
……省略部分内容
ksedmp: internal or fatal error
ORA-00600: internal error code, arguments: [KGHLKREM1], [0x679000020], [], [], [], [], [], []
----- Call Stack Trace -----
calling call entry argument values in hex
location type point (? means dubious value)
-------------------- -------- -------------------- ----------------------------
ksedst()+31 call ksedst1() 000000000 ? 000000001 ?
7FFF41D71F90 ? 7FFF41D71FF0 ?
7FFF41D71F30 ? 000000000 ?
ksedmp()+610 call ksedst() 000000000 ? 000000001 ?
7FFF41D71F90 ? 7FFF41D71FF0 ?
7FFF41D71F30 ? 000000000 ?
ksfdmp()+21 call ksedmp() 000000003 ? 000000001 ?
7FFF41D71F90 ? 7FFF41D71FF0 ?
7FFF41D71F30 ? 000000000 ?
kgerinv()+161 call ksfdmp() 000000003 ? 000000001 ?
7FFF41D71F90 ? 7FFF41D71FF0 ?
7FFF41D71F30 ? 000000000 ?
kgesinv()+33 call kgerinv() 0068966E0 ? 2AF92650E2C0 ?
7FFF41D71FF0 ? 7FFF41D71F30 ?
000000000 ? 000000000 ?
kgesin()+143 call kgesinv() 0068966E0 ? 2AF92650E2C0 ?
7FFF41D71FF0 ? 7FFF41D71F30 ?
000000000 ? 000000000 ?
kghnerror()+342 call kgesin() 0068966E0 ? 2AF92650E2C0 ?
7FFF41D71FF0 ? 7FFF41D71F30 ?
000000002 ? 679000020 ?
kghadd_reserved_ext call kghnerror() 0068966E0 ? 060000058 ?
ent()+1039 005AE1C14 ? 679000020 ?
000000002 ? 679000020 ?
kghget_reserved_ext call kghadd_reserved_ext 0068966E0 ? 060000058 ?
ent()+250 ent() 060042F70 ? 060042FB8 ?
000000000 ? 000000000 ?
kghgex()+1622 call kghget_reserved_ext 0068966E0 ? 060003B98 ?
ent() 060042F70 ? 000000B10 ?
000000000 ? 000000000 ?
kghfnd()+660 call kghgex() 0068966E0 ? 060003B98 ?
060042F70 ? 000002000 ?
000000AC8 ? 06000D600 ?
kghprmalo()+274 call kghfnd() 0068966E0 ? 060003B98 ?
060042F70 ? 000000AB8 ?
000000AB8 ? 06000D600 ?
从上面的信息来看,确实heap 存在错误的情况。根据这个错误堆栈可以在MOS上再次匹配,这时找到文档号1070812.1的文章:ORA-600 [KGHLKREM1] On Linux Using Parameter drop_cache On hugepages Configuration,此次故障跟描述基本上一致。
***** Internal heap ERROR KGHLKREM1 addr=0x679000020 ds=0x60000058 *****
***** Dxxx of memory around addr 0x679000020:
678FFF020 00000000 00000000 00000000 00000000 […]
Repeat 255 times
679000020 60001990 00000000 00000000 00000000 […`…]
679000030 00000000 00000000 00000000 00000000 […]
Repeat 254 times
其中地址[0x679000020] 后面的内容也均为0,跟文档描述一样。其次,文章中提到使用了linux 内存释放机制以及同时启用了hugepage配置。根据文档描述,这应该是Linux Bug。通过检查对比2个节点配置,发现节点2的配置确实不同。
–节点1
[oracle@xxx-DS01 ~]$ cat /proc/sys/vm/drop_caches
0
–节点2
[oracle@xxx-DS02 ~]$ cat /proc/sys/vm/drop_caches
3
当drop_caches 设置为3时,会触发linux的内存清理回收机制,可能出现内存错误的情况。然而我们检查配置发现并没有修改。
oracle@xxx-DS02 bdxxx]$ cat /etc/sysctl.conf
# Kernel sysctl configuration file for Red Hat Linux
#
# For binary values, 0 is disabled, 1 is enabled. See sysctl(8) and
# sysctl.conf(5) for more details.
# Controls IP packet forwarding
net.ipv4.ip_forward = 0
# Controls source route verification
net.ipv4.conf.default.rp_filter = 1
# Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0
# Controls the System Request deBugging functionality of the kernel
kernel.sysrq = 0
# Controls whether core dxxxs will append the PID to the core filename
# Useful for deBugging multi-threaded applications
kernel.core_uses_pid = 1
# Controls the use of TCP syncookies
net.ipv4.tcp_syncookies = 1
# Controls the maximum size of a message, in bytes
kernel.msgmnb = 65536
# Controls the default maxmimum size of a mesage queue
kernel.msgmax = 65536
# Controls the maximum shared segment size, in bytes
kernel.shmmax = 68719476736
# Controls the maximum number of shared memory segments, in pages
kernel.shmall = 4294967296
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default = 1048576
net.core.rmem_max = 1048576
net.core.wmem_default = 262144
net.core.wmem_max = 262144
vm.nr_hugepages=15800
既然没有修改配置文件,那么为什么会出现这种情况呢?
我怀疑是有人手工执行了echo 3 > /proc/sys/vm/drop_caches命令来强制释放内存导致。接下来查看到了最近几分钟的操作记录,发现了如下的蛛丝马迹。
[root@xxx-DS02 ~]# history|grep echo
22 2015-09-29 16:12:42 root echo 3 > /proc/sys/vm/drop_caches
71 2015-09-29 16:12:42 root echo 0 > /proc/sys/vm/drop_caches
73 2015-09-29 16:12:42 root echo 3 > /proc/sys/vm/drop_caches
79 2015-09-29 16:12:42 root echo 0 > /proc/sys/vm/drop_caches
311 2015-09-29 16:12:42 root echo 3 > /proc/sys/vm/drop_caches
329 2015-09-29 16:12:42 root echo 0 > /proc/sys/vm/drop_caches
1001 2015-09-29 16:12:49 root history|grep echo
1005 2015-09-29 16:14:55 root history|grep echo
很明显root 用户确实执行了内存释放的操作。然而运维人员却否认执行过类似操作,这说明事情并不是如此简单。我们进一步检查数据库操作系统日志发现如下信息。
Sep 29 00:00:12 xxx-DS02 kernel: Bug: soft lockup - CPU#1 stuck for 10s! [rel_mem.sh:13887]
Sep 29 00:00:12 xxx-DS02 kernel: CPU 1:
……
Sep 29 00:00:12 xxx-DS02 kernel: Pid: 13887, comm: rel_mem.sh Tainted: G 2.6.18-194.el5 #1
Sep 29 00:00:12 xxx-DS02 kernel: RIP: 0010:[
Sep 29 00:00:12 xxx-DS02 kernel: RSP: 0018:ffff8112f5f71da8 EFLAGS: 00000207
……
Sep 29 00:00:12 xxx-DS02 kernel:
Sep 29 00:00:12 xxx-DS02 kernel: Call Trace:
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
Sep 29 00:00:12 xxx-DS02 kernel: [
我们可以看出,原来是由于调用了rel_mem.sh 脚本引发了这个问题,这个调用甚至导致CPU 1 挂起了10秒。对于Oracle RAC而言,当CPU 出现挂起,那么极有可能导致LMS等进程也挂起,进而引发数据库故障。
既然是调用了shell脚本,而客户的运维人员又没有主动做过任何操作,因此我怀疑很可能是之前部署了crontab 脚本,经过检查发现确实存在相关脚本,如下所示。
[root@xxx-DS02 ~]# crontab -l
00 00 * * * /home/oracle/ht/rel_mem.sh
[root@xxx-DS02 ~]# cat /home/oracle/ht//rel_mem.sh
#!/bin/bash
#mkdir /var/log/freemem
time=date +%Y%m%d
used=free -m | awk 'NR==2' | awk '{print $3}'
free=free -m | awk 'NR==2' | awk '{print $4}'
echo “===========================” >> /var/log/freemem/mem$time.log
date >> /var/log/freemem/mem$time.log
echo “Memory usage | [Use:{free}MB]” >> /var/log/freemem/mem$time.log
if [ $free -le 71680 ];then
sync && echo 3 > /proc/sys/vm/drop_caches
echo “OK” >> /var/log/freemem/mem$time.log
free >> /var/log/freemem/mem$time.log
else
echo “Not required” >> /var/log/freemem/mem$time.log
fi
到这里我们已经清楚了原因,到此这个案例已经告一段落了。最后我们还应该深入思考,为什么客户要部署这样一个脚本呢?只有一种解释,说明这个数据库节点之前可能面临内存使用居高不下的问题。既然如此,那么就进一步检查一下目前系统的内存使用情况。
[root@xxx-DS02 ~]# free -m
total used free shared buffers cached
Mem: 128976 127808 1168 0 245 88552
-/+ buffers/cache: 39010 89966
Swap: 15999 194 15805
我们可以看到操作系统物理内存为128GB,而其中cache 内存就占据了88GB。Linux 文件系统的cache分为2种:page cache和 buffer cache。page cache是用于文件inode等操作的,而buffer cache是用于块设备的操作。上述 free -m 命令中的cached 88552 全是page cache。目前数据库实例的内存分配之后也就40GB。
SQL> show parameter sga
NAME TYPE VALUE
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 30G
sga_target big integer 30G
SQL> show parameter pga
NAME TYPE VALUE
pga_aggregate_target big integer 10G
由此可见,操作系统物理内存之所以看上去那么高,并非Oralce本身所消耗,大部分为文件系统cache所消耗。而对于Linux的文件系统缓存,我们是可以通过调整操作系统内核参数来加快回收的,并不需要使用前面提到的强制清理回收内存的暴力解决方式。
根据Oracle metalink相关文档建议,通过设置如下参数来避免文本中的问题。
sysctl -w vm.min_free_kbytes=1024000
sysctl -w vm.vfs_cache_pressure=200
sysctl -w vm.swappiness=40
其中min_free_kbytes参数表示操作系统至少保留的空闲物理内存大小,单位是KB。vm.vfs_cache_pressure 参数用来控制操作系统对内存的回收,默认值为100,通过增加该值大小,可以加快系统对文件系统cache的回收。而最后的参数vm.swappiness则是控制swap交换产生的趋势程度,默认值为100。通过将该值调得更低一些,可以降低物理内存和disk之间产生交换的概率。但是Redhat 官方白皮书中明确提出,不建议将该值设置为10或者更低的值。实际上,通过我们的调整之后,据后续观察,该系统至今未再出现实例宕机的情况。这个案例告诉我们,在一个复杂的系统中,通过单一的手段进行粗暴的问题处理是危险的。正确的途径应该是,找出问题的根源,从源头对症下药,如此才能高枕无忧。
13.2 层层深入:DRM引发RAC的故障分析
在2015年1月13日凌晨3:44左右,某客户的一套集群数据库的节点1出现crash。检查该节点的告警日志,我们发现了如下内容。
Errors in file /home/oracle/app/admin/XXXX/bdump/XXXX1_lmon_10682988.trc:
ORA-00481: LMON process terminated with error
Tue Jan 13 03:44:43 2015
USER: terminating instance due to error 481
Tue Jan 13 03:44:43 2015
Errors in file /home/oracle/app/admin/XXXX/bdump/XXXX1_lms0_27525728.trc:
ORA-00481: LMON process terminated with error
.......省略部分内容
Tue Jan 13 03:44:44 2015
Errors in file /home/oracle/app/admin/XXXX/bdump/XXXX1_lgwr_33489026.trc:
ORA-00481: LMON process terminated with error
Tue Jan 13 03:44:44 2015
Doing block recovery for file 94 block 613368
Tue Jan 13 03:44:45 2015
Shutting down instance (abort)
License high water mark = 1023
Tue Jan 13 03:44:49 2015
Instance terminated by USER, pid = 19333184
Tue Jan 13 03:44:55 2015
Instance terminated by USER, pid = 33554510
Tue Jan 13 03:45:46 2015
Starting ORACLE instance (normal)
sskgpgetexecname failed to get name
从上述的告警日志来看,在凌晨3:44:43时间点,节点1的LMON进程出现异常被终止,抛出ORA-00481错误。接着节点1的数据库实例被强行终止。对于Oracle RAC 数据库故障,我们在进行分析时,首先要对Oracle RAC的一些核心进程原理有所了解才行,这样才能深入本质。这里我们简单描述Oracle RAC的几个核心进程的基本原理,例如LMON、LMS和LMD等。
对于Oracle 的LMON进程,其作用主要是监控RAC的GES(Global Enqueue Service)信息。当然其作用不仅仅局限于此,还负责检查集群中各个Node的健康情况。当有节点出现故障的时候,LMON进程负责进行reconfig以及GRD(global resource Directory)的恢复等。
我们知道RAC的脑裂机制,如果IO fencing是Oracle本身来完成,也就是说由Clusterware来完成。那么当LMON进程检查到实例级别出现脑裂时,会通知Clusterware来进行脑裂操作,当然LMON进程其并不会等待Clusterware的处理结果。当等待超过一定时间,LMON进程会自动触发IMR(instance membership recovery),这实际上也就是我们所说的Instance membership reconfig。
既然提到LMON进程的检测机制,那么LMON如何去检查集群中每个节点的健康状态呢?其中主要分为如下几种。
(1)网络心跳 (主要是通过ping进行检测)。
(2)控制文件磁盘心跳,其实就是每个节点的CKPT进程每三秒更新一次控制文件的机制。
Oracle RAC核心进程LMD主要负责处理全局缓存服务(保持块缓冲区在实例间一致)处理锁管理器服务请求。它向一个队列发出资源请求,这个队列由LMS进程处理。同时LMD 还负责处理全局死锁的检测、解析,并监视全局环境中的锁超时(这就是为什么我们经常看到数据库alert log中LMD进程发现全局死锁的原因)。
如果是Oracle 11gR2 rac环境,那么还存在一个新的核心进程,即LMBH进程。该进程是Oracle 11R2版本引入的一个进程,该进程的主要作用是负责监控LMD、LMON、LCK和LMS等核心进程,防止这些Oracle核心后台进程spin(stuck)或被阻塞。该进程会定时地将监控的信息打印输出在相应的trace文件中,便于我们进行诊断。这也是11gR2一个亮点。当LMBH进程发现其他核心进程出现异常时,会尝试发起一些kill动作。如果一定时间内仍然无法解决,那么将触发保护,将实例强行终止掉,当然这是为了保证RAC节点数据的完整性和一致性。
从上述的日志分析,我们可以看出,节点1实例是被LMON进程强行终止的,而LMON进程由于本身出现异常才采取了这样的措施。那么节点1的LMON进程为什么会出现异常呢?通过分析节点1数据库实例LMON进程的trace 内容,我们可以看到如下内容。
*** 2015-01-13 03:44:18.067
kjfcdrmrfg: SYNC TIMEOUT (1295766, 1294865, 900), step 31
Submitting asynchronized dump request [28]
KJC Communication Dump:
state 0x5 flags 0x0 mode 0x0 inst 0 inc 68
nrcv 17 nsp 17 nrcvbuf 1000
reg_msg: sz 456 cur 1235 (s:0 i:1235) max 5251 ini 3750
big_msg: sz 8240 cur 263 (s:0 i:263) max 1409 ini 1934
rsv_msg: sz 8240 cur 0 (s:0 i:0) max 0 tot 1000
rcvr: id 1 orapid 7 ospid 27525728
… 略部分内容
send proxy: id 16 ndst 1 (1:16 )
GES resource limits:
ges resources: cur 0 max 0 ini 39515
ges enqueues: cur 0 max 0 ini 59069
ges cresources: cur 4235 max 7721
gcs resources: cur 4405442 max 5727836 ini 7060267
gcs shadows: cur 4934515 max 6358617 ini 7060267
KJCTS state: seq-check:no timeout:yes waitticks:0x3 highload no
…省略部分内容
kjctseventdump-end tail 238 heads 0 @ 0 238 @ -744124571
sync() timed out - lmon exiting
kjfsprn: sync status inst 0 tmout 900 (sec)
kjfsprn: sync propose inc 68 level 85020
kjfsprn: sync inc 68 level 85020
kjfsprn: sync bitmap 0 1
kjfsprn: dmap ver 68 (step 0)
… 略部分内容
DUMP state for lmd0 (ospid 27198128)
DUMP IPC context for lmd0 (ospid 27198128)
Dumping process 6.27198128 info:
从上面LMON进程的trace信息来看,LMON进程检测到了DRM在进行sync同步时出现了timeout,最后LMON强制退出了。既然如此,那么我们应该继续分析为什么DRM会出现timeout。另外根据前面讲述的原理,Oracle DRM的操作主要进程是LMD进程来完成,那么我们来分析节点1实例的LMD进程的trace内容,是否能看出蛛丝马迹。
*** 2015-01-13 03:44:43.666
lmd abort after exception 481
KJC Communication Dump:
state 0x5 flags 0x0 mode 0x0 inst 0 inc 68
nrcv 17 nsp 17 nrcvbuf 1000
reg_msg: sz 456 cur 1189 (s:0 i:1189) max 5251 ini 3750
big_msg: sz 8240 cur 261 (s:0 i:261) max 1409 ini 1934
rsv_msg: sz 8240 cur 0 (s:0 i:0) max 0 tot 1000
rcvr: id 1 orapid 7 ospid 27525728
… …省略部分内容
send proxy: id 7 ndst 1 (1:7 )
send proxy: id 16 ndst 1 (1:16 )
GES resource limits:
ges resources: cur 0 max 0 ini 39515
ges enqueues: cur 0 max 0 ini 59069
ges cresources: cur 4235 max 7721
gcs resources: cur 4405442 max 5727836 ini 7060267
gcs shadows: cur 4934515 max 6358617 ini 7060267
KJCTS state: seq-check:no timeout:yes waitticks:0x3 highload no
GES destination context:
GES remote instance per receiver context:
GES destination context:
我们可以看到,当LMON进程遭遇ORA-00481错误之后,LMD进程也被强制abort终止掉了。从LMD 进程的trace文件来看,出现了tickets 等待超时的情况,而且日志中Oracle也告诉我们,在该故障时间点,系统负载并不高。
从上述内容来看,我们似乎并没有得到十分有价值信息。由于LMON进程被强制终止掉之前,触发了一个process dump,因此我们进一步来分析进程dump,继续寻找蛛丝马迹。
*** 2015-01-13 03:44:18.114
Dump requested by process [orapid=5]
REQUEST:custom dump [2] with parameters [5][6][0][0]
Dumping process info of pid[6.27198128] requested by pid[5.10682988]
Dumping process 6.27198128 info:
*** 2015-01-13 03:44:18.115
Dumping diagnostic information for ospid 27198128:
OS pid = 27198128
loadavg : 1.71 1.75 2.33
swap info: free_mem = 13497.62M rsv = 96.00M
alloc = 342.91M avail = 24576.00M swap_free = 24233.09M
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
240001 A oracle 19530440 10682988 10 65 20 16ae3ea590 1916 03:44:18 - 0:00 /usr/bin/procstack 27198128
242001 T oracle 27198128 1 1 60 20 7412f4590 108540 Dec 29 - 569:20 ora_lmd0_XXXX1
procstack: open(/proc/27198128/ctl): Device busy
*** 2015-01-13 03:44:18.420
LMD进程的processstate dmp 似乎也没有太多有价值的内容。不过我们至少可以肯定的是,系统的资源使用很正常。
通过上述的分析,我们可以看到ORA-00481错误的产生是关键,而这个错误是LMON进程产生的。ORA-00481错误在Oracle MOS文档(1950963.1)中有非常详细的描述,针对本文DRM操作没有结束的情况,一般有如下2种原因。
(1)实例无法获得LE(Lock Elements)锁。
(2)tickets不足。
根据文档描述,我们从数据库两个节点的LMS进程trace中没有发现如下的类似关键信息。
Start affinity expansion for pkey 81885.0
Expand failed: pkey 81885.0, 229 shadows traversed, 153 replayed 1 retries
因此,我们可以排除第一种可能性。我们从LMD进程的trace文件中可以看到如下类似信息。
GES destination context:
Dest 1 rcvr 0 inc 68 state 0x10041 tstate 0x0
batch-type quick bmsg 0x0 tmout 0x20f0dd31 msg_in_batch 0
tkt total 1000 avl 743 sp_rsv 242 max_sp_rsv 250
seq wrp 0 lst 268971339 ack 0 snt 268971336
sync seq 0.268971339 inc 0 sndq enq seq 0.268971339
batch snds 546480 tot msgs 5070830 max sz 88 fullload 85 snd seq 546480
pbatch snds 219682271 tot msgs 267610831
sndq msg tot 225339578 tm (0 17706)
sndq msg 0 maxlmt 7060267 maxlen 149 wqlen 225994573
sndq msg 0 start_tm 0 end_tm 0
这里的tkt total 表示目前数据库实例总的tickets数据为1000,当前可用的tickets为743. 因此我们可以排除ticket不足的导致DRM没有完成的情况。
换句话讲,上述ORA-00481错误的产生,本身并不是Oracle RAC的配置问题导致。对于LMON进程检查到DRM操作出现超时,最后导致实例崩溃。超时的原因通常有如下几种。
(1)操作系统Load极高,例如CPU极度繁忙,导致进程无法获得CPU资源。
(2)进程本身处理异常,比如进程挂起。
(3)网络问题,比如数据库节点之间通信出现异常。
(4)Oracle DRM Bug。
从上面的信息来看,系统在出现异常时,操作系统的Load是很低的,因此第一点我们可以直接排除。
我们现在的目的是需要分析出LMON进程检查到了什么异常,以及为什么会出现异常。LMON进程在abort之前进行了dump,那么是否能够从相关dump 中找到一些有价值的线索呢?
PROCESS 5:
----------------------------------------
SO: 700001406331850, type: 2, owner: 0, flag: INIT/-/-/0x00
(process) Oracle pid=5, calls cur/top: 7000014054d75e0/7000014054d75e0, flag: (6) SYSTEM
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 0 0 24
last post received-location: ksasnd
last process to post me: 700001405330198 1 6
last post sent: 0 0 24
last post sent-location: ksasnd
last process posted by me: 7000014023045d0 1 2
(latch info) wait_event=0 bits=0
Process Group: DEFAULT, pseudo proc: 70000140336dd88
O/S info: user: oracle, term: UNKNOWN, ospid: 10682988
OSD pid info: Unix process pid: 10682988, image: oracle@tpihxdb1 (LMON)
…省略部分内容
----------------------------------------
SO: 7000014064d88c8, type: 4, owner: 700001406331850, flag: INIT/-/-/0x00
(session) sid: 1652 trans: 0, creator: 700001406331850, flag: (51) USR/- BSY/-/-/-/-/-
DID: 0001-0005-00000006, short-term DID: 0000-0000-00000000
txn branch: 0
oct: 0, prv: 0, SQL: 0, pSQL: 0, user: 0/SYS
service name: SYS$BACKGROUND
last wait for ‘ges generic event’ blocking sess=0x0 seq=35081 wait_time=158 seconds since wait started=0
=0, =0, =0
Dumping Session Wait History
for ‘ges generic event’ count=1 wait_time=158
=0, =0, =0
…
----------------------------------------
SO: 7000013c2f52018, type: 41, owner: 7000014064d88c8, flag: INIT/-/-/0x00
(dummy) nxc=0, nlb=0
----------------------------------------
SO: 7000014035cb1e8, type: 11, owner: 700001406331850, flag: INIT/-/-/0x00
(broadcast handle) flag: (2) ACTIVE SUBSCRIBER, owner: 700001406331850,
event: 5, last message event: 70,
last message waited event: 70, next message: 0(0), messages read: 1
channel: (7000014074b6298) system events broadcast channel
scope: 2, event: 129420, last mesage event: 70,
publishers/subscribers: 0/915,
messages published: 1
----------------------------------------
SO: 7000014054d75e0, type: 3, owner: 700001406331850, flag: INIT/-/-/0x00
(call) sess: cur 7000014064d88c8, rec 0, usr 7000014064d88c8; depth: 0
----------------------------------------
SO: 7000014036e3060, type: 16, owner: 700001406331850, flag: INIT/-/-/0x00
(osp req holder)
从上面LMON进程本身的dump来看,节点1实例的LMON进程状态是正常的,最后发送消息给LMON进程的是SO: 700001405330198,SO即为state obejct。搜索该SO,我们可以发现为LMD进程。
PROCESS 6:
----------------------------------------
SO: 700001405330198, type: 2, owner: 0, flag: INIT/-/-/0x00
(process) Oracle pid=6, calls cur/top: 7000014054d78a0/7000014054d78a0, flag: (6) SYSTEM
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 0 0 104
last post received-location: kjmpost: post lmd
last process to post me: 700001402307510 1 6
last post sent: 0 0 24
last post sent-location: ksasnd
last process posted by me: 700001407305690 1 6
(latch info) wait_event=0 bits=0
Process Group: DEFAULT, pseudo proc: 70000140336dd88
O/S info: user: oracle, term: UNKNOWN, ospid: 27198128 (DEAD)
OSD pid info: Unix process pid: 27198128, image: oracle@tpihxdb1 (LMD0)
…省略部分内容
----------------------------------------
SO: 7000014008a8d00, type: 20, owner: 700001405330198, flag: -/-/-/0x00
namespace [KSXP] key = [ 32 31 30 47 45 53 52 30 30 30 00 ]
----------------------------------------
SO: 7000014074a73d8, type: 4, owner: 700001405330198, flag: INIT/-/-/0x00
(session) sid: 1651 trans: 0, creator: 700001405330198, flag: (51) USR/- BSY/-/-/-/-/-
DID: 0000-0000-00000000, short-term DID: 0000-0000-00000000
txn branch: 0
oct: 0, prv: 0, SQL: 0, pSQL: 0, user: 0/SYS
service name: SYS$BACKGROUND
last wait for ‘ges remote message’ blocking sess=0x0 seq=25909 wait_time=163023 seconds since wait started=62
waittime=40, loop=0, p3=0
Dumping Session Wait History
for ‘ges remote message’ count=1 wait_time=163023
waittime=40, loop=0, p3=0
…省略部分内容
------------process 0x7000014036e3ba0--------------------
proc version : 0
Local node : 0
pid : 27198128
lkp_node : 0
svr_mode : 0
proc state : KJP_NORMAL
Last drm hb acked : 0
Total accesses : 31515
Imm. accesses : 31478
Locks on ASTQ : 0
Locks Pending AST : 0
Granted locks : 2
从LMON和LMD进程的process dump来看,进程本身状态是正常的。因此我们可以排除进程挂起导致出现Timeout的可能性。同时我们可以看到LMD进程一直在等待ges remote message,很明显这是和另外一个数据库节点进行通信。因此我们要分析问题的根本原因,还需要分析节点2数据库实例的一些信息。
首先我们来分析节点2实例的数据库告警日志。
Tue Jan 13 03:39:14 2015
Timed out trying to start process PZ96.
Tue Jan 13 03:44:44 2015
Trace dumping is performing id=[cdmp_20150113034443]
Tue Jan 13 03:44:48 2015
Reconfiguration started (old inc 68, new inc 70)
List of nodes:
1
Global Resource Directory frozen
* dead instance detected - domain 0 invalid = TRUE
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
从节点2的数据库告警日志来看,在3:44:48时间点,实例开始进行reconfig操作,这与整个故障的时间点是符合的。告警日志中本身并无太多信息,我们接着分析节点2数据库实例的LMON进程trace信息。
*** 2015-01-13 03:18:53.006
Begin DRM(82933)
……省略部分内容
End DRM(82933)
*** 2015-01-13 03:23:55.896
Begin DRM(82934)
……省略部分内容
End DRM(82934)
*** 2015-01-13 03:29:00.374
Begin DRM(82935)
…省略部分内容
sent syncr inc 68 lvl 85020 to 0 (68,0/38/0)
synca inc 68 lvl 85020 rcvd (68.0)
*** 2015-01-13 03:44:45.191
kjxgmpoll reconfig bitmap: 1
*** 2015-01-13 03:44:45.191
kjxgmrcfg: Reconfiguration started, reason 1
kjxgmcs: Setting state to 68 0.
*** 2015-01-13 03:44:45.222
Name Service frozen
kjxgmcs: Setting state to 68 1.
kjxgfipccb: msg 0x110fffe78, mbo 0x110fffe70, type 22, ack 0, ref 0, stat 34
kjxgfipccb: Send cancelled, stat 34 inst 0, type 22, tkt (1416,80)
……省略部分内容
kjxggpoll: change poll time to 50 ms
* kjfcln: DRM aborted due to CGS rcfg.
* ** 2015-01-13 03:44:45.281
从上述LMON进程的日志来看,在故障时间点之前,数据库一直存在大量的DRM操作。并且注意到节点进行reconfiguration时,reason 代码值为1。关于reason值,Oracle Metalink文档有如下描述。
Reason 0 = No reconfiguration
Reason 1 = The Node Monitor generated the reconfiguration.
Reason 2 = An instance death was detected.
Reason 3 = Communications Failure
Reason 4 = Reconfiguration after suspend
从reason =1 来看,数据库实例被强行终止重启也不是通信故障的问题。如果是通信的问题,那么reason值通常应该等于3.reason=1表明这是数据库节点自身监控时触发的reconfig操作。这也与我们前面分析节点1的日志的结论是符合的。
我们从* kjfcln: DRM aborted due to CGS rcfg. 这段关键信息也可以确认,CGS reconfig的原因也正是由于DRM操作失败导致。同时也可以看到,在3:29开始的Begin DRM(82935)操作,一直到3:44出现故障时,这个DRM操作都没有结束(如果结束,会出现End DRM(82935) 类似关键字)。
由此也不难看出,实际上,该集群数据库可能在3:29之后就已经出现问题了。这里简单补充一下Oracle DRM的原理: 在Oracle RAC环境中,当某个节点对某个资源访问频率较高时,而该资源的master节点是不是local节点时,那么可能会触发DRM(Dynamic Resource Management)操作。在Oracle 10gR1引入该特性之前,如果数据库需要更改某个资源的master节点,那么必须将数据库实例重启来完成。很显然,这一特性的引入无疑改变了一切。同时,从Oracle 10gR2开始,又引入了基于object/undo 级别的affinity。这里所谓的affinity,本质上是引入操作系统的概念,即用来表示某个对象的亲和力程度。在数据库来看,即为对某个对象的访问频率程度。
在Oracle 10gR2版本中,默认情况下,当某个对象的被访问频率超过50时,而同时该对象的master又是其他节点时,那么Oracle则会触发DRM操作来修改master节点,这样的好处是可以大幅降低gc grant之类的等待事件。在进程DRM操作的过程中,Oracle会将该资源的相关信息进行临时frozen,然后将该资源在其他节点进行unfrozen,然后更改资源的master节点。这里我们需要注意的是,这里frozen的资源其实是GRD(Global Resource Directory)中的资源。在整个DRM的过程之中,访问该资源的进程都将被临时挂起。正因为如此,当系统出现DRM操作时,很可能导致系统或进程出现异常的。
实际上关于Oracle DRM的Bug也非常多,尤其是Oracle 10gR2版本中。针对本次故障,我们基本上可以认定是如下的Bug导致。
Bug 6960699 - “latch: cache buffers chains” contention/ORA-481/kjfcdrmrfg: SYNC TIMEOUT/ OERI[kjbldrmrpst:!master] (ID 6960699.8)
Dynamic ReMastering (DRM) can be too aggressive at times causing any combination
of the following symptoms :
- “latch: cache buffers chains” contention.
- “latch: object queue header operation” contention
- a RAC node can crash with and ora-481 / kjfcdrmrfg: SYNC TIMEOUT … step 31
- a RAC node can crash with OERI[kjbldrmrpst:!master]
最后建议客户屏蔽Oracle DRM功能之后,经过监控发现运行了相当长一段时间后都没有出现类似问题。
通过这个RAC的案例分析,大家可能注意到,相关的集群日志非常多。在分析过程中,需要保持非常清晰的思路,才能基于问题将这些信息串联起来,最终成为定位和解决问题的重要信息。而事后基于问题的总结和研究,更加是巩固知识、带动我们成长的关键。希望大家能够从中学到故障分析、学习提升的思路和方法。
13.3 始于垒土:应用无法连接数据库问题分析
前不久某运营商客户反映某套业务系统在2016年8月4日凌晨出现过无法访问数据库的情况。当接到客户请求之后我才通过VPN登录进行日志分析。首先我分析数据库告警日志发现,8月4日凌晨54分开始出现unable to spawn jobq slave process相关错误,如下所示。
Thu Aug 04 00:54:10 CST 2016
Process J006 died, see its trace file
Thu Aug 04 00:54:10 CST 2016
kkjcre1p: unable to spawn jobq slave process
Thu Aug 04 00:54:10 CST 2016
Errors in file /oracle/app/oracle/admin/fwktdb/bdump/fwktdb_cjq0_5487.trc:
Process J006 died, see its trace file
Thu Aug 04 00:54:11 CST 2016
kkjcre1p: unable to spawn jobq slave process
Thu Aug 04 00:54:11 CST 2016
Errors in file /oracle/app/oracle/admin/fwktdb/bdump/fwktdb_cjq0_5487.trc:
……
Thread 1 advanced to log sequence 111405 (LGWR switch)
Current log# 3 seq# 111405 mem# 0: /dev/vx/rdsk/datadg02/fwkt_redo1_3_raw_512m
Thu Aug 04 03:09:55 CST 2016
Process J007 died, see its trace file
Thu Aug 04 03:09:55 CST 2016
kkjcre1p: unable to spawn jobq slave process
Thu Aug 04 03:09:55 CST 2016
Errors in file /oracle/app/oracle/admin/fwktdb/bdump/fwktdb_cjq0_5487.trc:
……
Thu Aug 04 06:07:50 CST 2016
Process J002 died, see its trace file
Thu Aug 04 06:07:50 CST 2016
kkjcre1p: unable to spawn jobq slave process
Thu Aug 04 06:07:50 CST 2016
Errors in file /oracle/app/oracle/admin/fwktdb/bdump/fwktdb_cjq0_5487.trc:
从上述告警日志来看,没有明显的ORA相关错误。但是我们细心一点就会发现上述日志中存在一些告警信息,比如kkjcrelp:unable to spawn jobq slave process,该告警也值得我们关注。那么这个告警信息的产生一般有哪些原因呢?根据kkjcrelp:unable to spawn jobq slave process错误来看,一般有以下几种原因。
(1)数据库进程参数processes参数设置偏小。
(2)job 参数job_queue_processes设置过小。
(3)系统资源(CPU/IO/Memory)不足,例如内存不足,导致新产生的进程无法获取资源。
根据经验我们知道,这极有可能是资源的问题。因为如果是数据库实例processes参数设置偏小,那么alert log通常会伴随 ORA-00200 类似的错误,然而我们却并没有发现。因此我们可以很容易的排除第一种可能性。至于第2、3种可能原因,这里我们暂时还无法排除,还需要进一步分析相关日志才能下结论。
既然是应用程序无法访问,那么数据库监听日志应该会有一些相关记录。我继续检查数据库监听日志发现,4日凌晨确实出现了大量的TNS相关错误,如下所示。
04-AUG-2016 01:33:58 * (CONNECT_DATA=(SERVICE_NAME=fwktdb)(CID=(PROGRAM=SigService) (HOST=wljhinas35)(USER=inas))) * (ADDRESS=(PROTOCOL=tcp)(HOST=135.160.9.35)(PORT=48172)) * establish * fwktdb * 12518
TNS-12518: TNS:listener could not hand off client connection
TNS-12547: TNS:lost contact
TNS-12560: TNS:protocol adapter error
TNS-00517: Lost contact
Solaris Error: 32: Broken pipe
04-AUG-2016 01:33:58 *
……
04-AUG-2016 01:34:06 * (CONNECT_DATA=(SERVICE_NAME=fwktdb)(CID=(PROGRAM=WlanService) (HOST=nxwljh1.localdomain)(USER=inas))) * (ADDRESS=(PROTOCOL=tcp)(HOST=135.160.9.42)(PORT=50613)) * establish * fwktdb * 12518
TNS-12518: TNS:listener could not hand off client connection
TNS-12547: TNS:lost contact
TNS-12560: TNS:protocol adapter error
TNS-00517: Lost contact
Solaris Error: 32: Broken pipe
上面这部分内容,我相信大家并不陌生,这是非常常见的一些错误。我相信很多人第一感觉是搜索Oracle MOS,确认TNS-12518 是什么意思,什么原因。想必大家应该会看到这样的文章,ORA-12518 / TNS-12518 Troubleshooting (ID 556428.1)。
该文档描述的解决方案有很多种,这里我大致描述一下,有如下几种。
(1)操作系统时钟问题,建议设置设置如下参数:
stener.ora: INBOUND_CONNECT_TIMEOUT_listenername
SQLnet.ora: SQLNET.INBOUND_CONNECT_TIMEOUT。
(2)操作系统可用内存不足,建议增加内存。
(3)数据库参数processes设置过小,建议调大一些。
(4)启用大内存支持,突破内核的单进程只能消耗1GB内存的限制,这实际上通常是指的windows环境。
(5)PGA内存不足,而SGA设置过大,导致进程内存不足。建议缩小SGA,给PGA预留更多内存。
(6)配置MTS共享模式。
(7)如果监听报错TNS-12518,并进程crash,那么很可能是命中一些因为系统压力过大或者内存溢出等相关oracle Bug,例如6139856。
实际上当我们遇到上述类似错误时,不应该直接往下判断。首先在分析这个问题时,我们要确认一点客户所说是否是真实的。也就是说这个问题之前是否出现过,还是仅仅是8月4日凌晨出现过1次。带这这样的疑问,我继续检查分析监听日志,发现实际上8月3日也出现无法连接数据库的情况。
03-AUG-2016 18:24:48 * (CONNECT_DATA=(SID=fwktdb)(CID=(PROGRAM=JDBC Thin Client) (HOST=jdbc) (USER=bea))) * (ADDRESS=(PROTOCOL=tcp)(HOST=135.161.23.93)(PORT=35059)) * establish * fwktdb * 12518
TNS-12518: TNS:listener could not hand off client connection
TNS-12547: TNS:lost contact
TNS-12560: TNS:protocol adapter error
TNS-00517: Lost contact
Solaris Error: 32: Broken pipe
……
03-AUG-2016 18:24:52 * (CONNECT_DATA=(SERVICE_NAME=fwktdb)(CID=(PROGRAM=SigService)(HOST=wljhinas33)(USER=inas))) * (ADDRESS=(PROTOCOL=tcp)(HOST=135.160.9.33)(PORT=59837)) * establish * fwktdb * 12518
TNS-12518: TNS:listener could not hand off client connection
TNS-12547: TNS:lost contact
TNS-12560: TNS:protocol adapter error
TNS-00517: Lost contact
Solaris Error: 32: Broken pipe
对于Oracle 的错误分析,我给大家的建议都是应该从下往上看,比如下面所列的错误。
TNS-12518: TNS:listener could not hand off client connection
TNS-12547: TNS:lost contact
TNS-12560: TNS:protocol adapter error
TNS-00517: Lost contact
Solaris Error: 32: Broken pipe
Oracle 监听日志在这里其实抛出了一连串的告警信息,我们需要有所判断,确认其中的哪行信息是关键信息,是产生问题的根源。很明显最后一行的Solaris Error:32:Broken pipe 是此问题的关键所在。
针对Solaris error:32 broken pipe错误,这里我不自行进行解释,我选择引用Oracle官方的解释。
The error 32 indicates the communication has been broken while the listener is trying to hand off the client connection to the server process or dispatcher process.
这里我简单解释一下上述文档内容的描述,简单地讲就是:Oracle 监听程序尝试去处理客户端到服务器端进程或者调度器(dispatcher processes)进程之前的连接时,将客户端进程通信强行中断了。那么监听程序为什么要终止连接呢?文档解释说有如下几种可能性原因。
-
One of reason would be processes parameter being low, and can be verified by the v$resource_limit view.
-
In Shared Server mode, check the ‘lsnrctl services’ output and see if the dispatcher has refused any connections, if so, then consider increasing the number of dispatchers.
-
Check the alert log for any possible errors.
-
Memory resource is also another cause for this issue. Check the swap, memory usage of the OS.
-
If RAC/SCAN or listener is running in separate home, check the following note。
从Oracle 文档描述来看,产生该问题原因主要有如下几种。
(1)processes参数设置过小。
(2)共享服务器模式下,dispatcher不足。
(3)内存资源不足。
由于客户这里实际上是Oracle 10.2.0.4 环境,因此就不需要考虑上述第5条描述了。
从上述问题描述的内容来看,与我们之前讲述TNS-12518 错误几种可能性的原因有些类似。那么我们如何去定位这个问题呢?针对类似的问题,我通常的建议是使用最简单的方法:排除法。
首先我们来从数据库层面判断是否可以直接排除第1种可能性原因。我分析了数据库在8月4日凌晨1-2点的AWR数据库,发现数据库进程并没有达到processes参数设置限制,如图13-1所示。

图13-1
所以可以排除第1种可能性原因,同时由于数据库是专用模式,因此也可以排除第2种可能性原因。因此,这里似乎可以大致断定导致此次问题的原因是第3种可能性了,即系统资源使用方面。
我们知道操作系统资源主要分为CPU/IO以及内存资源,接下来从数据库监控角度来判断一下数据库资源在故障期间内的使用情况如何。通过器监控发现,CPU资源消耗正常,swap内存消耗存在一定的波动,但是整体来看也是正常的,如图13-2、图13-3所示。
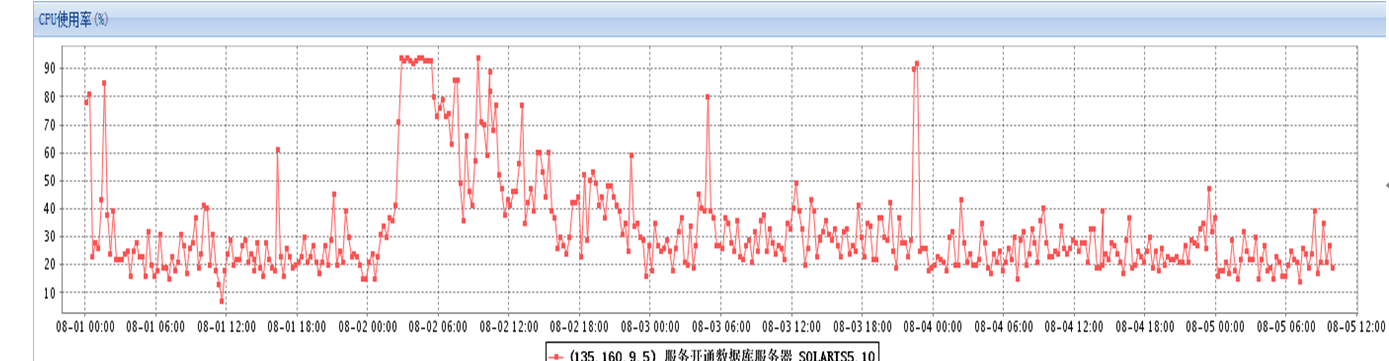
图13-2
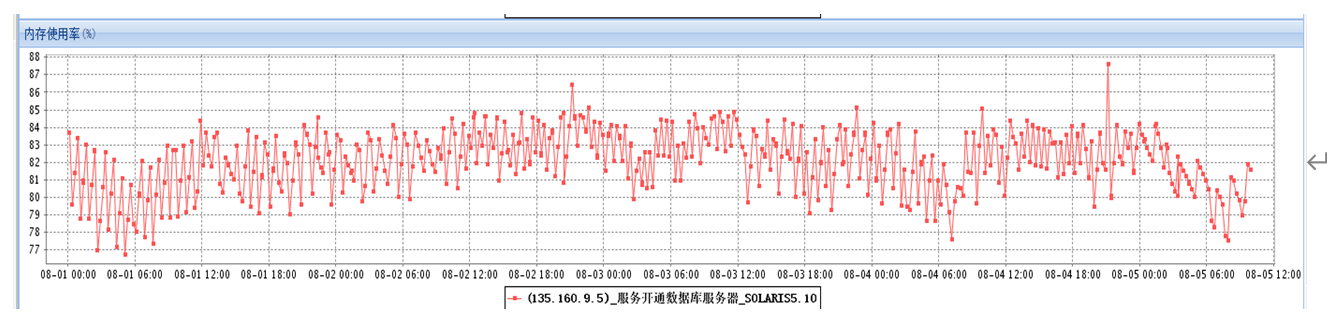
图13-3
基于前面的分析不难看出,系统资源在使用上没有任何问题,没有出现资源过度消耗或资源不足的情况。到这里整个问题的分析似乎陷入了僵局。
Oracle数据库是基于操作系统,因此实际上,当数据库出现异常之后,我们在进行问题分析时,首先应该确认操作系统本身是否正常,比如内核参数设置是否正确等。因此自然而然应该进一步检查数据库服务器操作系统日志是否存在相关蛛丝马迹。
正如心中所想,再检查Solaris 操作系统的日志发现,确实存在相关错误。
Aug 4 00:54:24 nxfwktdb SC[SUNWscor.oracle_server.monitor]:nxfwktdb_rg:ora-fwktdb_rs: [ID 564643 local7.error] Fault monitor detected error DBMS_ERROR: 20 DEFAULT Action=NONE : Max. number of DBMS processes exceeded
Aug 4 00:54:54 nxfwktdb SC[SUNWscor.oracle_server.monitor]:nxfwktdb_rg:ora-fwktdb_rs: [ID 564643 local7.error] Fault monitor detected error DBMS_ERROR: 1045 DEFAULT Action=NONE : Fault monitor user lacks CREATE SESSION privilege; logon denied.
……
Aug 4 02:26:57 nxfwktdb SC[SUNWscor.oracle_server.monitor]:nxfwktdb_rg:ora-fwktdb_rs: [ID 564643 local7.error] Fault monitor detected error DBMS_ERROR: 1045 DEFAULT Action=NONE : Fault monitor user lacks CREATE SESSION privilege; logon denied.
Aug 4 02:28:26 nxfwktdb last message repeated 3 times
Aug 4 02:28:56 nxfwktdb SC[SUNWscor.oracle_server.monitor]:nxfwktdb_rg:ora-fwktdb_rs: [ID 564643 local7.error] Fault monitor detected error DBMS_ERROR: 20 DEFAULT Action=NONE : Max. number of DBMS processes exceeded
从上述日志来看,确实存在processes超过限制的情况。同时还能发现有监控用户由于缺乏权限,仍然在不断尝试登陆数据库,这也是一个安全隐患。针对操作系统日志中的Max number of DBMS processes execeeded 错误信息,Oracle 官方文档有如下类似解释。
There can be several contributors to this failure. Solaris kernel may have resource (memory/cpu) shortage, performance problem or the database itself could be having some issues for example:
detected error DBMS_ERROR: 20 DEFAULT Action=NONE : Max. number of DBMS processes exceeded
说明:参考文档 Solaris Cluster 3.x HA-Oracle Fault Monitor Dumps Core With “Aborting fault monitor child process” or “probe response time exceeded timeout” (ID 1381317.1)
根据Oracle Solaris的文档解释来看,上述错误ERROR 20表示 Solaris 操作系统本身内核资源使用可能存在异常,或者存在性能问题,或者数据库本身可能存在某些问题。这个分析与我们前面的种种分析似乎比较接近。这里我需要说明的是,我期间分析了故障前后的AWR和ASH 相关数据,没有发现明显异常,因此可以断定数据库本身是正常的。
分析到这个层面,我相信大家心中已经有了答案。有没有可能是操作系统本身有问题呢?这里需要注意的是,操作系统本身有问题,并不代表是指的操作系统资源使用有问题,也有可能是Solaris 相关内核参数设置问题。实际上我们通过前面的操作系统监控信息就可以排除系统资源消耗异常的可能性。所以这里我们很有必要对Solaris系统本身的相关内核参数进行全面检查一次,通过检查发现确实存在参数设置不合理的情况,如下所示。
—操作系统内核参数
root@nxfwktdb # cat /etc/system|grep ‘sys’
.
set semsys:seminfo_semmni=100
set semsys:seminfo_semmns=2048
set semsys:seminfo_semmsl=256
set semsys:seminfo_semvmx=32767
set shmsys:shminfo_shmmax=17179869184
set shmsys:shminfo_shmmin=1
set shmsys:shminfo_shmmni=100
set shmsys:shminfo_shmseg=10
root@nxfwktdb # cat /etc/project
system:0::::
user.root:1::::
noproject:2::::
default:3::::
group.staff:10::::
—数据库会话总数
SQL> select count(1) from v$session;
COUNT(1)
----------
1866
对于上述的内核参数,这里我不做过多解释,大家可以参考Oracle官方安装文档,里面有详细的描述。从Soalris 10开始,已经废弃了如下几个参数:
- semsys:seminfo_semmns——操作系统信号灯最大个数;
- shmsys:shminfo_shmmin——共享内存段最小值;
- semsys:seminfo_semvmx——操作系统信号灯的最大值。
同时,从Solaris 10开始,已经不再建议通过修改/etc/system的方式来调整内核参数了。建议通过project的方式来进行控制,而客户这里没有为Oracle用户单独创建project,而使用了默认的default project,如下:
root@nxfwktdb # id -p oracle
uid=101(oracle) gid=100(dba) projid=3(default)
那么我们来进一步检查default project设置是否恰当。其中Solaris 10版本中使用process.max-sem-nsems来替代 semsys:seminfo_semmsl 参数的控制,该参数表示一个信号组中信号灯等最大数量,由于Oracle用户默认使用了default project,因此这里我们来检查default project的设置情况,如下所示。
root@nxfwktdb # prctl -i project default
project: 3: default
NAME PRIVILEGE VALUE FLAG ACTION RECIPIENT
project.max-contracts
privileged 10.0K - deny -
system 2.15G max deny -
project.max-device-locked-memory
privileged 1.96GB - deny -
system 16.0EB max deny -
project.max-port-ids
privileged 8.19K - deny -
system 65.5K max deny -
project.max-shm-memory
privileged 1.56TB - deny -
system 16.0EB max deny -
project.max-shm-ids
privileged 128 - deny -
system 16.8M max deny -
project.max-msg-ids
privileged 128 - deny -
system 16.8M max deny -
project.max-sem-ids
privileged 128 - deny -
system 16.8M max deny -
project.max-crypto-memory
privileged 7.83GB - deny -
system 16.0EB max deny -
project.max-tasks
system 2.15G max deny -
project.max-lwps
system 2.15G max deny -
project.cpu-shares
privileged 1 - none -
system 65.5K max none -
zone.max-lwps
system 2.15G max deny -
zone.cpu-shares
privileged 1 - none - -
我们可以看到default project中定义了project.max-sem-ids,它表示系统中信号组的最大值,即128,表示目前该系统最大default project中所定义的用户创建的最大信号组之和不能超过128。同时/etc/system中的参数semsys:seminfo_semmsl 为256,表示该default project 的每一个信号组最大只能创建256个信号灯。可以通过ipcs 命令直接查看这一点。
root@nxfwktdb # ipcs -sb
IPC status from
T ID KEY MODE OWNER GROUP NSEMS
Semaphores:
s 12 0x4b623218 --ra-r----- oracle dba 256
s 11 0x4b623217 --ra-r----- oracle dba 256
s 10 0x4b623216 --ra-r----- oracle dba 256
s 9 0x4b623215 --ra-r----- oracle dba 256
s 8 0x4b623214 --ra-r----- oracle dba 256
s 7 0x4b623213 --ra-r----- oracle dba 256
s 6 0x4b623212 --ra-r----- oracle dba 256
s 5 0x4b623211 --ra-r----- oracle dba 256
s 4 0x4b623210 --ra-r----- oracle dba 256
s 0 0x71050a00 --ra-ra-ra- root root 1
root@nxfwktdb # ipcs -ma
……
T ID KEY MODE OWNER GROUP CREATOR CGROUP NATTCH SEGSZ CPID LPID ATIME DTIME CTIME
Shared Memory:
m 1 0x333184c8 --rw-r----- oracle dba oracle dba 1870 12884934656 5253 24096 17:07:40 17:07:40 0:36:07
上述查询结果的NSEMS 列即表示每个信号组中最大的信号灯数量。同时从NATTCH的值可以看出,目前当前Oracle用户已经创建了1 870个进程。实际上seminfo_semmsl参数的设置应该是大于processes参数设置的。目前数据库processes参数设置为2 048,且数据库进程已经超过1 850,因此建议将该参数调整的更大一些。
从前面的数据来看,目前default project中所有用户能够消耗的最大信号灯约等于128×256=32 768。尽管这个数值看上去已经够大,其实不然。在操作系统命令来看,一个进程和信号灯等对应关系通常是一对多。而且从查询结果来看Oracle实际上只分配了9个信号组,每组最大的信号灯数量是256。如果根据这个计算也就是9×256=2 304。而目前数据库实例的进程数量已经接近2 000。
因此最后我们建议将seminfo_semmsl 参数调整的更大一些,建议设置为512以上。
以上三则案例基本上跟数据库的内存管理和系统参数设置相关。每一个故障都不是单一方面的问题产生的,也涉及各方面的知识。对于DBA来说,具备完整的技术观非常重要。
13.4 变与不变:应用SQL突然变慢优化分析
去年底,某运营商客户反馈某个核心业务模块突然出现严重性能问题,产生了极为不好的用户体验,客服接到了大量投诉电话。这样的问题,处理起来相对容易一些。首先我们根据v$session.program很容易就可以定位到业务程序,并结合event、SQL_ID和SQL_TEXT 很快就确认是运行较慢的业务SQL语句,经过分析发现是SQL选择了错误的Index,导致执行计划效率不高。这里我通过在客户生产库创建相同的对象,然后执行类似SQL,完全可以重现问题。
首先我们来分析一下出问题的SQL语句,如下所示。
SELECT
SERIAL_NBR
FROM BILLUSER.I_B2O_OWE_C_BAK
WHERE (PROC_TYPE = ‘13’ or PROC_TYPE = ‘14’ or PROC_TYPE = ‘S13’ or
PROC_TYPE = ‘S14’)
AND BEGIN_OWE_DATE >=
TO_DATE(‘2015-12-02 12:00:00’, ‘YYYY/MM/DD HH24:MI:SS’)
AND ACC_NBR = ‘18115258610’
需要说明一点,这里的I_B2O_OWE_C_BAK 表是复制的I_B2O_OWE_C表。
该SQL语句从结构上看很简单,初步怀疑是这个SQL的执行计划可能存在异常,这里我们首先来分析一下执行计划,如下所示。
Plan hash value: 239766388
-----------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.59 | 3049 |
|* 1 | TABLE ACCESS BY INDEX ROWID| I_B2O_OWE_C_BAK | 1 | 1 | 0 |00:00:00.59 | 3049 |
|* 2 | INDEX RANGE SCAN | I_B2O_OWE_C_BAK_BDATE| 1 | 3 | 19871 |00:00:00.01 | 236 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter((TO_NUMBER(“ACC_NBR”)=:SYS_B_6 AND INTERNAL_FUNCTION(“PROC_TYPE”)))
2 - access(“BEGIN_OWE_DATE”>=TO_DATE(:SYS_B_4,:SYS_B_5))
我相信,有SQL优化经验的同学应该都能看出来,上述的执行计划确实有些异常,SQL通过走Index range scan的方式,最后返回了仅仅1条数据,然而逻辑读的消耗却高达3000之多,这很明显是有问题的。同时我们还可以看出Oracle优化器评估出来的R-rows 和实际的A-rows差距非常大。也正是由于这一点,导致该执行计划选择了I_B20_OWE_C_BAK_BDATE索引后进行回表操作,产生了大量的逻辑读(逻辑读消耗几乎都在回表操作上)。
由于是客户反馈,那么在处理时我们首先想到的是,这个问题SQL是不是真如客户所讲那样,在当天才出现问题,而之前都是正常呢?还是说有可能之前也出现过异常,只是业务没有反馈而已。
要验证这一点,需要查询该SQL_ID的历史执行计划信息。通过查询确认该SQL实际上在12 月 1 日就出现了异常。但是由于当天业务量较小,没有对业务产生实质性的影响,如下所示。
SNAP_ID SQL_ID PLAN_HASH_VALUE OPTIMIZER_ FORCE_MATCHING_SIGNATURE
80546 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
……
80569 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80570 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80571 1pzv7x3nhszva 239766388 ALL_ROWS 8159205349038030075
80571 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80573 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80573 1pzv7x3nhszva 239766388 ALL_ROWS 8159205349038030075
80596 1pzv7x3nhszva 239766388 ALL_ROWS 8159205349038030075
…….
80609 1pzv7x3nhszva 239766388 ALL_ROWS 8159205349038030075
80609 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80610 1pzv7x3nhszva 239766388 ALL_ROWS 8159205349038030075
80610 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80623 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
80624 1pzv7x3nhszva 1247210496 ALL_ROWS 8159205349038030075
其中快照ID的对应的时间段信息如下所示。
SNAP_ID BEGIN_INTERVAL_TI
80546 20151129 23:00:34
80547 20151130 00:00:48
……
80569 20151130 22:00:02
80570 20151130 23:00:20
80571 20151201 00:00:40
80572 20151201 01:00:59
80573 20151201 02:00:16
80574 20151201 03:00:38
……
80596 20151202 01:01:00
…….
80609 20151202 14:00:49
80610 20151202 15:00:16
80611 20151202 16:00:50
80612 20151202 17:00:19
其中plan_hash_value 为239766388 的执行计划为错误的执行计划。当产生错误的执行计划之后,由于Oracle bind peeking 的问题,就可能导致数据库在之后的一段时间内一直沿用错误的执行计划。
我开始怀疑可能是统计信息的问题,由于客户后续已经重新收集了统计信息。因此现在我想,是否可以将统计信息还原到出问题之前的某天,然后执行SQL语句,看其执行计划是怎么样的。
实际上Oracle本身就提供了这样一个功能,利用DBMS_STATS可以将表的统计信息还原到过去某个时间点,操作步骤如下所示。
SQL> exec dbms_stats.restore_table_stats(ownname=>‘BILLUSER’,tabname=>‘I_B2O_OWE_ C_BAK’,AS_OF_TIMESTAMP=>‘01-DEC-15 12.09.22.020077 AM +08:00’);
PL/SQL procedure successfully completed.
SQL> select owner,table_name,COLUMN_NAME,NUM_DISTINCT,DENSITY,NUM_BUCKETS,LAST_ ANALYZED,HISTOGRAM from dba_tab_col_statistics where table_name=‘I_B2O_OWE_C_BAK’;
OWNER TABLE_NAME COLUMN_NAME NUM_DISTINCT DENSITY NUM_BUCKETS LAST_ANALYZED HISTOGRAM
BILLUSER I_B2O_OWE_C_BAK SOURCE 0 0 0 2015-11-17 00:10:25 NONE
BILLUSER I_B2O_OWE_C_BAK TDBS 3 3.4099E-08 3 2015-11-17 00:10:25 FREQUENCY
BILLUSER I_B2O_OWE_C_BAK SERIAL_NBR 14663108 6.8198E-08 1 2015-11-17 00:10:25 NONE
BILLUSER I_B2O_OWE_C_BAK PROC_TYPE 5 3.4099E-08 5 2015-11-17 00:10:25 FREQUENCY
BILLUSER I_B2O_OWE_C_BAK PROD_ID 2326397 4.2985E-07 1 2015-11-17 00:10:25 NONE
BILLUSER I_B2O_OWE_C_BAK CREATE_DATE 5660648 1.3521E-06 254 2015-11-17 00:10:25 HEIGHT BALANCED
BILLUSER I_B2O_OWE_C_BAK BEGIN_OWE_DATE 5833484 7.9253E-07 254 2015-11-17 00:10:25 HEIGHT BALANCED
BILLUSER I_B2O_OWE_C_BAK STATE 3 3.4099E-08 3 2015-11-17 00:10:25 FREQUENCY
BILLUSER I_B2O_OWE_C_BAK STATE_DATE 5927070 6.3963E-07 254 2015-11-17 00:10:25 HEIGHT BALANCED
BILLUSER I_B2O_OWE_C_BAK ACC_NBR 2306453 1.2826E-06 254 2015-11-17 00:10:25 HEIGHT BALANCED
BILLUSER I_B2O_OWE_C_BAK PRODUCT_TYPE 3 3.4099E-08 3 2015-11-17 00:10:25 FREQUENCY
BILLUSER I_B2O_OWE_C_BAK BILLING_MODE_ID 3 .333333333 1 2015-11-17 00:10:25 NONE
BILLUSER I_B2O_OWE_C_BAK AREA_CODE 5 .2 1 2015-11-17 00:10:25 NONE
BILLUSER I_B2O_OWE_C_BAK JRFS 0 0 0 2015-11-17 00:10:25 NONE
—基于列的详细统计信息
COLUMN_NAME DATA_TYPE M NUM_VALS NUM_NULLS DNSTY LOW_V HI_V
SERIAL_NBR NUMBER Y 14663,108 0 0.0000 118812796 142619179
PROC_TYPE VARCHAR2 Y 5 0 0.0000 11 15
PROD_ID NUMBER Y 2326,397 0 0.0000 10282208 561259458
CREATE_DATE DATE Y 5660,648 0 0.0000 2015-2-10 21:50:52 2015-11-16 23:53:30
BEGIN_OWE_DATE DATE N 5833,484 0 0.0000 2015-2-10 21:50:51 2015-11-16 23:55:26
STATE VARCHAR2 Y 3 0 0.0000 101 3
STATE_DATE DATE Y 5927,070 0 0.0000 2015-2-10 23:0:47 2015-11-16 23:59:41
ACC_NBR VARCHAR2 Y 2306,453 0 0.0000 13309500000 18995499998
PRODUCT_TYPE NUMBER Y 3 0 0.0000 401731 403094
BILLING_MODE_ID NUMBER N 3 0 0.3333 1 4
AREA_CODE VARCHAR2 N 5 0 0.2000 0951 0955
JRFS VARCHAR2 N 0 14765,004 0.0000
TDBS NUMBER Y 3 0 0.0000 0 2
SOURCE VARCHAR2 N 0 14765,004 0.0000
通过还原统计信息之后,发现该表的统计信息最新值实际上是11月17日凌晨,也就是说从11月17日到12月1日,该表的统计信息都没有发现发现过变动(实际上到12月1日客户感觉到出问题之后,手工收集过统计信息)。由于最近半月数据变化比较大,但统计信息却并没有更新,说明统计信息过旧也可能导致Oracle 仍然沿用旧的统计信息进行执行计划评估,进而产生错误的执行计划。至少目前为止我们还不能排除这个可能性。
这里首先来看一下Oracle card的计算公式,如下所示。
= 基数计算公式 :1/num_distinct*(num_rows-num_nulls)
>= 基数计算公式:((high_value-limit)/(high_value-low_value)+1/num_distinct)*(num_rows- num_nulls)
对于该问题SQL的索引,如下所示。
OWNER TABLE_NAME INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS CLUSTERING_FACTOR DISTINCT_KEYS
BILLUSER I_B2O_OWE_C_BAK I_B2O_OWE_C_BDATE_BAK 2 42001 15833626 7108231 6150468
BILLUSER I_B2O_OWE_C_BAK I_B2O_OWE_C_ACCNBR_BAK 2 50751 15833626 15723479 2421731
那么根据Oracle Card计算公式,对于两个索引的估算情况如下所示。
 对于其中的索引I_B2O_OWE_C_ACCNBR_BAK,由于SQL的过滤条件为 = 符号。当统计信息不变的情况之下,根据公式所计算的Card值都是不变的。
 对于索引 I_B2O_OWE_C_BDATE_BAK,由于其过滤条件是 >=符号。根据Card的计算公式,是需要通过high value等值来进行计算的。
这里我们怀疑极有可能跟这个BDATE 时间列的high value等统计信息有关系,为了验证这个观点,这里我进行了如下的测试验证过程。
情况一:当时间条件取值大于high value时。
SQL> SELECT /*+ gather_plan_statistics */ SERIAL_NBR FROM BILLUSER.I_B2O_OWE_C_BAK WHERE (PROC_TYPE=‘13’ or PROC_TYPE=‘14’ or
2 PROC_TYPE=‘S13’ or PROC_TYPE=‘S14’) AND BEGIN_OWE_DATE >=
3 TO_DATE(‘2015-11-16 23:56:00’,‘YYYY/MM/DD HH24:MI:SS’) AND ACC_NBR =‘18909502122’
4 /
no rows selected
SQL> select * from table(dbms_xplan.display_cursor(NULL,NULL,‘ALLSTATS’));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------
SQL_ID 4fjrp8d5gqz1z, child number 0
-------------------------------------
SELECT /*+ gather_plan_statistics */ SERIAL_NBR FROM BILLUSER.I_B2O_OWE_C_BAK WHERE (PROC_TYPE=‘13’ or
PROC_TYPE=‘14’ or PROC_TYPE=‘S13’ or PROC_TYPE=‘S14’) AND BEGIN_OWE_DATE >= TO_DATE('2015-11-16
23:56:00’,‘YYYY/MM/DD HH24:MI:SS’) AND ACC_NBR =‘18909502122’
Plan hash value: 3356388844
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:06.29 | 450K| 8861 |
|* 1 | TABLE ACCESS BY INDEX ROWID| I_B2O_OWE_C_BAK | 1 | 1 | 0 |00:00:06.29 | 450K| 8861 |
|* 2 | INDEX RANGE SCAN | I_B2O_OWE_C_BDATE_BAK | 1 | 3 | 1068K|00:00:00.01 | 2838 | 0 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter((“ACC_NBR”=‘18909502122’ AND INTERNAL_FUNCTION(“PROC_TYPE”)))
2 - access(“BEGIN_OWE_DATE”>=TO_DATE(’ 2015-11-16 23:56:00’, ‘syyyy-mm-dd hh24:mi:ss’))
情况二:当时间条件取值不超过high value时。
SQL> SELECT /*+ gather_plan_statistics */ SERIAL_NBR FROM BILLUSER.I_B2O_OWE_C_BAK WHERE (PROC_TYPE=‘13’ or PROC_TYPE=‘14’ or
2 PROC_TYPE=‘S13’ or PROC_TYPE=‘S14’) AND BEGIN_OWE_DATE >=
3 TO_DATE(‘2015-11-16 23:52:00’,‘YYYY/MM/DD HH24:MI:SS’) AND ACC_NBR =‘18909502122’
4 /
no rows selected
SQL> select * from table(dbms_xplan.display_cursor(NULL,NULL,‘ALLSTATS’));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------
SQL_ID 6vrh3x0qqnxnh, child number 0
-------------------------------------
SELECT /*+ gather_plan_statistics */ SERIAL_NBR FROM BILLUSER.I_B2O_OWE_C_BAK WHERE (PROC_TYPE=‘13’ or
PROC_TYPE=‘14’ or PROC_TYPE=‘S13’ or PROC_TYPE=‘S14’) AND BEGIN_OWE_DATE >= TO_DATE('2015-11-16
23:52:00’,‘YYYY/MM/DD HH24:MI:SS’) AND ACC_NBR =‘18909502122’
Plan hash value: 1431363508
-----------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 0 |00:00:00.40 | 36 | 35 |
|* 1 | TABLE ACCESS BY INDEX ROWID| I_B2O_OWE_C_BAK | 1 | 1 | 0 |00:00:00.40 | 36 | 35 |
|* 2 | INDEX RANGE SCAN | I_B2O_OWE_C_ACCNBR_BAK | 1 | 7 | 33 |00:00:00.03 | 3 | 2 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter((“BEGIN_OWE_DATE”>=TO_DATE(’ 2015-11-16 23:52:00’, ‘syyyy-mm-dd hh24:mi:ss’) AND
INTERNAL_FUNCTION(“PROC_TYPE”)))
2 - access(“ACC_NBR”=‘18909502122’)
从上面的测试验证可以看出,当where 条件的时间列取值超过该列的high value时,Oracle 选择了错误的Index。而当时间列取值小于该列的high value时,Oracle 则会选择正确的执行计划。
当取值小于high value时,此时BEGIN_OWE_DATE的选择性为 ((high_value-limit)/(high_value-low_value)+1/num_distinct)即为(2015-11-16 23:55:26 - 2015-11-16 23:50:00 )/(2015-11-16 23:55:26-2015-2-10 21:50:51)+ (7.9253E-07)= 0.000013691。这样计算出来的结果表明begin_owe_date列的选择性要比accnbr列的选择性低。这种情况下Oracle会选择正确的索引。当取值大于high value时,begin_owe_date 列的选择性所计算出来的只要比accnbr要高,这样就会导致Oracle 选择错误的索引。
为什么会出现这样奇怪的情况呢? 实际上是因为当谓词条件取值超过high value时,此时Oracle无法判断,只能进行猜测。而这种情况之下,通常都会导致所计算出来的Card不合理,导致SQL选择错误的执行计划。尤其是针对date列、sequence等情况,相对要常见得多,这是Oracle CBO的一个老问题。
实际上,为了避免这种情况出现,我们要尽可能地保证统计信息的准确性,这样可以最大程度降低地执行计划改变的风险。同时也要改变一种错误的认识,即统计信息不改变,SQL****的执行计划不一定一成不变,而事实往往恰恰相反,很可能改变。
当然,对于前面的问题,要解决是相对简单的。由于我们确认ACCNBR列的选择性永远都是非常高的,因此可以通过SQL Profile来固定这个执行计划,可以确保后续的稳定性。
最后针对前面这个SQL执行计划改变的案例进简单总结。由于11月16日至11月30日该业务表数据变动不大,未触发Oracle 对表进行统计信息收集的阈值(数据变更超过10%)时,导致统计信息一直未进行更新。直到12月1日凌晨,随着大量数据的加载和更新,超过统计信息收集的阈值后,Oracle进行了统计信息收集。然而由于Oracle 默认的统计信息收集Job是每周一到周六的晚上22点才进行收集,因此这就会出现一天时间的间隔。在该间隔时间段内,由于统计信息不准确,SQL语句索引列的high value值过旧的问题,导致Oracle 优化器评估出的Card值较小,最后选择了错误的执行计划。
13.5 实践真知:INSERT入库慢的案例分析
某次,运营商客户的计费库反应其入库程序很慢,应用方通过监控程序发现主要慢在对于几个表的插入操作上。按照我们的通常理解,insert应该是极快的,为什么会很慢呢?难道是大量的redo日志产生或者undo不足?
据客户反馈,在反应之前应用程序都是正常的,这个问题是突然出现的,而且是每个月中下旬开始出现慢的情况。这让我百思不得其解。 通过检查event也并没有发现什么奇怪的地方,于是我通过10046 跟踪了应用的入库程序,如下即是应用方反应比较慢的表的插入操作,经过验证确实非常慢。
INSERT INTO XXXX_EVENT_201605C (ROAMING_NBR,…,OFFER_INSTANCE_ID4)
VALUES (:ROAMING_NBR,…:OFFER_INSTANCE_ID4)
call count cpu elapsed disk query current rows
Parse 17 0.00 0.00 0 0 0 0
Execute 18 1.06 27.41 4534 518 33976 4579
Fetch 0 0.00 0.00 0 0 0 0
total 35 1.06 27.41 4534 518 33976 4579
……
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
db file sequential read 4495 0.03 24.02
gc current grant 2-way 2301 0.00 0.77
SQL*Net more data from client 795 0.00 0.02
…
latch: gcs resource hash 1 0.00 0.00
以上分析可以发现,插入了4579条数据,一共花了27.41秒。其中有24.02秒消耗在db file sequential read上。很明显这是索引的读取操作,实际上检查10046 trace 裸文件,发现等待的对象确实是该表上的2个索引。同时从上面10046 trace可以看出,该SQL执行之所以很慢,主要是因为存在了大量的物理读,其中4579条数据的插入,物理读为4534。这说明什么问题呢? 这说明,每插入一条数据大概产生一个物理读,而且都是index block的读取。 如下是10046 trace跟踪产生的裸文件内容。
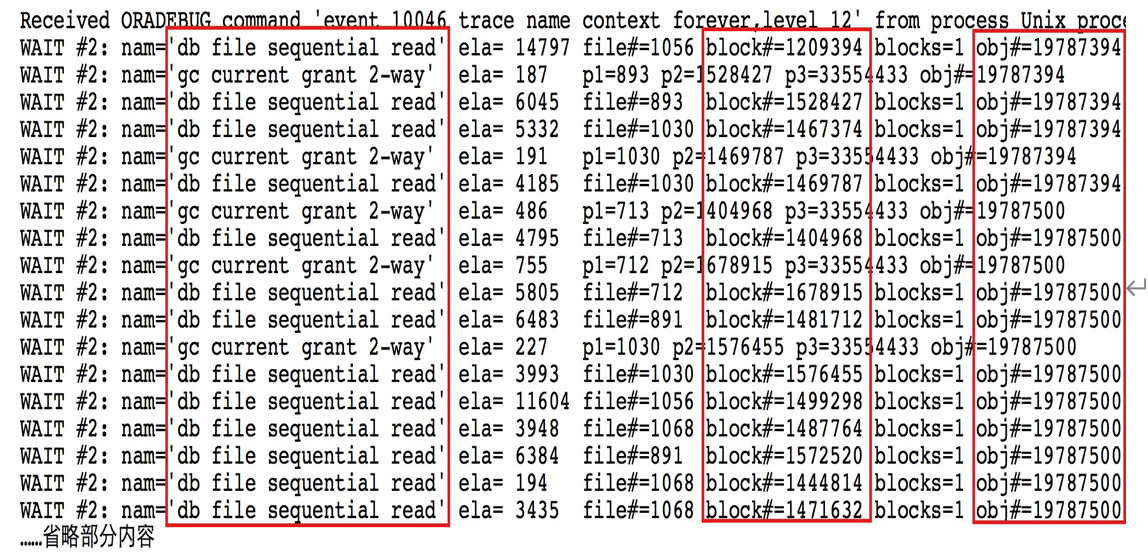

很明显,通过将该index cache移到keep 池可以解决该问题。 实际上也确实如此,通过cache后,应用反馈程序快了很多。 那么对该问题,这里其实有几个疑问,为什么这里的SQL insert时物理读如此之高?这里我进一步来检查者2个Index的情况,如下所示。


通过以上数据可以发现,顺序读等待最高的2个恰好其clustering_factor比较高。有没有可能跟这个有关系呢?
要解释这个问题,其实并不容易。首先这里我们需要理解Oracle B-tree Index的结构,如图13-4所示。
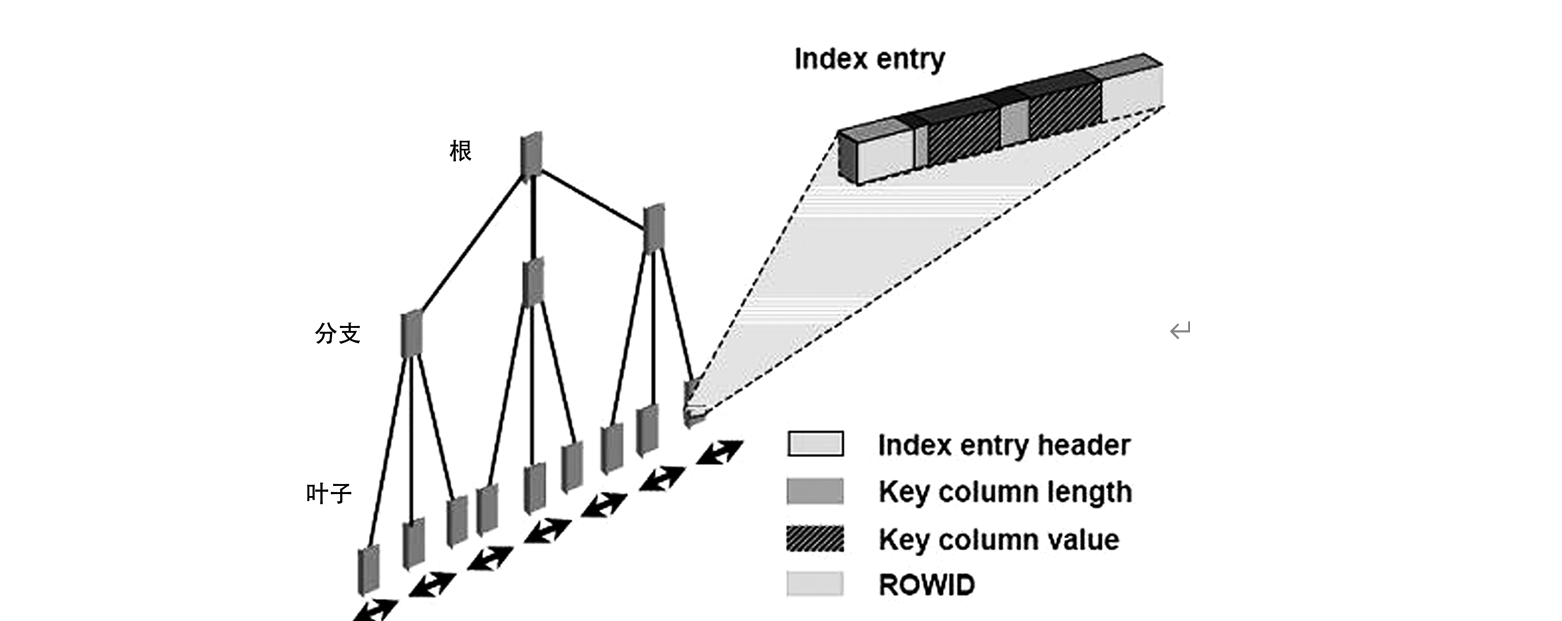
图13-4
当Oracle向index branch block或leaf block中插入数据时,其实都是等价的,Oracle这里其实并不需要进行代价的估算。随机选择branch block或者leaf block,让其插入键值即可。所以这里其实也就跟我们前面提到的Index 聚簇因子没有任何关系了。实际上我通过创建测试表,分别模拟聚簇因子大和小的情况,进行多次插入以及10046 trace跟踪分析,发现时间几乎一致。从测试来看也可以排除其影响。
不过Index 聚簇因子也是一直表现形式。当聚簇因子与表的行数非常接近时,说明数据分散程度比较高。假设现在现在有一个表Test,表上创建了一个Index IDX1。当向表中插入数据时,Oracle会进行index的同步维护,也就是需要同时向index block中插入键值。如果此时IDX1 索引的离散读非常高,那么也就是说每次插入数据时Oracle 在cache 中命中index block的概率可能就非常低,这样就不得不进行物理读操作,进而影响插入的效率。
想到这一点,我相信大多数人已经知道如何处理该问题了。最简单的方式就是将整个Index 缓存到内存中。这样就可以避免在插入数据时进行大量物理读操作了。
那么如何解释客户说的每个月中下旬这个应用模块就开始慢的问题呢? 结合前面的分析,其实这一点我们很容易解释。每个月初客户都会创建类似的空表,当数据量很小的情况下,Index 也是非常小的。即使index 键值非常离散,那么index block在cache 中缓存的可能性都比较大。因为索引比较小,而SGA的buffer cache 够大。然而随着时间的推移,数据量越来越大,index也会越拉越大,这也就降低了index block被cache的几率。
根据客户的业务特点,每个月都会创建类似的表和Index,因此我部署了一个脚本具体如下所示。
#!/usr/bin/sh
export ORACLE_BASE=/oracle/app/oracle
export ORACLE_HOME=/oracle/app/oracle/product/102
export ORACLE_SID=xx
export ORACLE_TERM=xterm
export NLS_LANG=American_america.zhs16gbk
export PATH=ORACLE_HOME/bin:PATH
C_DATE=date +%Y%m
SQLplus “/as sysdba” << EOF
alter index BILL.I1_ILE_DATA_EVENT_${C_DATE}A storage (buffer_pool keep);
alter index BILL.I1_ILE_DATA_EVENT_${C_DATE}B storage (buffer_pool keep);
alter index BILL.I1_ILE_DATA_EVENT_${C_DATE}C storage (buffer_pool keep);
alter index BILL.I1_ILE_DATA_EVENT_${C_DATE}D storage (buffer_pool keep);
alter index BILL.I1_ILE_DATA_EVENT_${C_DATE}E storage (buffer_pool keep);
alter index BILL.I2_ILE_DATA_EVENT_${C_DATE}A storage (buffer_pool keep);
alter index BILL.I2_ILE_DATA_EVENT_${C_DATE}B storage (buffer_pool keep);
alter index BILL.I2_ILE_DATA_EVENT_${C_DATE}C storage (buffer_pool keep);
alter index BILL.I2_ILE_DATA_EVENT_${C_DATE}D storage (buffer_pool keep);
alter index BILL.I2_ILE_DATA_EVENT_${C_DATE}E storage (buffer_pool keep);
EXIT;
EOF
通过这样的方式临时解决了该问题。而且从2016年5月解决之后至今客户没有再反馈过该业务模块有问题,看来是彻底解决了这个问题。
其实这里还有一个问题。一般来讲,物理内存都是有限的,而且SGA的keep 池不可能设置得过大。同时如果缓存的Index 比较多,比较大,那么Oracle的keep pool对于缓存对象的处理机制是如何的?
通过以下测试来探索一下Keep池对于缓存的对象的处理机制。
(1)创建2个测试表,并创建好相应的index,如下所示。
SQL> conn roger/roger
SQL> create table t_insert as select * from sys.dba_objects where 1=1;
SQL> create index idx_name_t on t_insert(object_name);
SQL> analyze table t_insert compute statistics for all indexed columns;
SQL> select INDEX_NAME,BLEVEL,LEAF_BLOCKS,DISTINCT_KEYS,CLUSTERING_FACTOR,NUM_ROWS from dba_indexes where table_name=‘T_INSERT’;
INDEX_NAME BLEVEL LEAF_BLOCKS DISTINCT_KEYS CLUSTERING_FACTOR NUM_ROWS
IDX_NAME_T 1 246 29808 24664 49859
SQL> alter system set db_keep_cache_size=4m;
SQL> create table t_insert2 as select * from sys.dba_objects where 1=1;
SQL> create index idx_name_t2 on t_insert2(object_name);
SQL> insert into t_insert select * from sys.dba_objects;
……多次insert
SQL> commit;
从前面的信息我们可以看出,object_name上的index聚簇因子比较高,说明其数据分布比较离散。
(2)我们现在将index都cache 到keep 池中,如下所示。
SQL> alter index idx_name_t storage (buffer_pool keep);
SQL> alter index idx_name_t2 storage (buffer_pool keep);
SQL> alter system flush buffer_cache;
这里需要注意的是,仅仅执行alter 命令是不够的,还需要手工将index block读取到keep池中,如下所示。
SQL> conn /as sysdba
SQL> @get_keep_pool_obj.SQL
no rows selected
SQL> select /*+ index(idx_name_t,t_insert) */ count(object_name) from roger.t_insert;
COUNT(OBJECT_NAME)
------------------
99721
SQL> @get_keep_pool_obj.SQL
SUBCACHE OBJECT_NAME BLOCKS
KEEP IDX_NAME_T 499
DEFAULT T_INSERT 431
SQL> select /*+ index(idx_name_t2,t_insert2) */ count(object_name) from roger.t_insert2;
COUNT(OBJECT_NAME)
------------------
99723
SQL> @get_keep_pool_obj.SQL
SUBCACHE OBJECT_NAME BLOCKS
KEEP IDX_NAME_T 40
KEEP IDX_NAME_T2 459
DEFAULT T_INSERT2 522
DEFAULT T_INSERT 431
SQL> select /*+ index(idx_name_t,t_insert) */ count(object_name) from roger.t_insert;
COUNT(OBJECT_NAME)
------------------
99721
SQL> @get_keep_pool_obj.SQL
SUBCACHE OBJECT_NAME BLOCKS
KEEP IDX_NAME_T 467
KEEP IDX_NAME_T2 32
DEFAULT T_INSERT2 522
DEFAULT T_INSERT 431
通过上述的多次简单测试可以看出,keep pool对于缓存的block的清除机制是先进先出原则。这相对于Oracle Buffer Cache 的机制来讲,要简单许多。
最后针对这个问题,可以总结一下,产生类似问题的原因可能有哪些呢? 实际上可能有很多种,如下所示。
(1)Index 碎片过于严重。
(2)Index next extent 分配问题。
(3)Buffer Cache 设置偏小。
(4)Index分区方式不合理。
(5)Redo、undo相关问题
上述方面内容都可能产生本文中提到的问题,只不过表现形式可能不同而已。这是一个常规而又隐秘的问题,我们通常容易忽视它,但是又很容易出现产生一些问题。这些问题会对业务系统性能产生重大影响,希望能够引起大家的重视。
13.6 按图索骥:Expdp遭遇ORA-07445的背后
据某客户反馈,其管理的某套数据库由于非正常关机重启之后,通过expdp进行数据导出发现报错,当报错之后,expdp数据导出命令直接终止退出,报错信息如下所示。
处理对象类型 SCHEMA_EXPORT/JOB
. . 导出了 “STATS”.“T_REPORT_MONTH_TEMPS” 988.2 MB 1292221 行
ORA-39014: 一个或多个 worker 进程已过早地退出。
ORA-39029: worker 进程 1 (进程名为 “DW01”) 过早地终止
ORA-31672: Worker 进程 DW01 意外停止。
作业 “SYS”.“SYS_EXPORT_SCHEMA_04” 因致命错误于 23:58:10 停止
此时我让客户检查数据库告警日志,发现有如下ORA-07445错误。
Errors in file /u01/app/oracle/admin/orcl/bdump/orcl_dw01_28608.trc:
ORA-07445: 出现异常错误: 核心转储 [klufprd()+321] [SIGSEGV] [Address not mapped to object] [0x000000000] [] []
通过分析上面的信息,可以得到如下几个结论。
(1)expdp的写进程报错,因为日志产生的进程是dw01进程。
(2)dw进程报错的原因是遭遇了ora-07445 [klufprd()+321]错误。
(3)[klufprd()+321] 这个函数非常少见。但是从前面2点可以知道这肯定与buffer cache有关系。
客户咨询,有没有什么好的解决方法。实际上当想到上述几点之后,脑海中马上就出现了一个临时解决方案。就是,通过alter system flush buffer_cache 刷新缓存之后,然后再次进行expdp数据导出操作。
据客户反馈,在进行flush buffer_cache之后,再次运行expdp数据导出命令,发现expdp 操作仍然会报类似错误,但是expdp 不会异常终止,会继续完成后面其他对象的导出。通过临时解决方法,能实现这一点,基本上也算告一段落了,至少客户导出数据的目标是实现了。
然而对于我而言,作为一个好奇心很重的DBA,势必要弄清楚,Oracle这里为什么会发生ORA-07445错误。为什么expdp会异常终止退出,这些目前来看都是谜团。
进一步检查日志,发现有如下错误。
*** SESSION ID:(2760.1968) 2016-04-08 00:14:14.347
row 01808438.0 continuation at
file# 6 block# 33784 slot 14 not found
KDSTABN_GET: 0 … ntab: 1
curSlot: 14 … nrows: 14
*** 2016-04-08 00:14:14.348
ksedmp: internal or fatal error
ORA-00600: internal error code, arguments: [kdsgrp1], [], [], [], [], [], [], []
Current SQL statement for this session:
SELECT /+NESTED_TABLE_GET_REFS+/ “STATS”.“T_REPORT_MONTH”.* FROM “STATS”.“T_REPORT_MONTH”
----- Call Stack Trace -----
擦亮眼睛发现,这里提到的这个表,恰好就是expdp报错所遇到的表,只不过我们在刷新buffer cache之后,expdp可以跳过这个表继续完成其他对象的导出。从上述的信息来看,这里确实存在一些错误。当然,客户也意识到了这样一点,习惯性的通过dbv 自带工具对该表所在的数据文件进行坏块检查,然而却并没有发现文件中存在数据坏块。
从这里的信息来看,Oracle发现所需要的这行记录row 01808438.0 应该在file 6 block 33784 中找到,但是却并没有发现。(注意,这里的file 6 block 33784 本身是完好的,因为dbv检测并没有发现坏块)。
那么这里的row 01808438.0 表示什么含义呢?
其实这是表示的nrid,这可以理解为一个指针。其中前面一部分是表现rdba地址,后面表现行编号。
那么针对这个问题,我们如何进一步进行分析呢?其实很简单,分别将block 33784以及rdba 01808438(16进制)进行dump,然后进行块级别分析。如下是rdba地址转换的脚本。
SQL> SELECT dbms_utility.data_block_address_block(25199672) “BLOCK”,
2 dbms_utility.data_block_address_file(25199672) “FILE”
3 FROM dual;
BLOCK FILE
33848 6
由于前面的报错日志中提到的是row 01808438.0 ,那么我们首先来分析file 6 block 33848的dump。
Block header dump: 0x01808438
Object id on Block? Y
seg/obj: 0xc03d01 csc: 0xb37.78b5ae28 itc: 3 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1807d8a ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000a.02d.000cdc5c 0x00809c91.6507.21 --U- 2 fsc 0x0001.78b6a4b1
0x02 0x000a.014.000cdd00 0x00806957.650d.15 --U- 2 fsc 0x0000.78b6ec5d
0x03 0x000a.025.000cdd5d 0x00801e50.650f.0a --U- 2 fsc 0x0000.78b71584
data_block_dump,data header at 0x1fb2f87c
===============
tsiz: 0x1f80
hsiz: 0x34
pbl: 0x1fb2f87c
bdba: 0x01808438
76543210
flag=--------
ntab=1
nrow=17
frre=-1
fsbo=0x34
fseo=0xd2
avsp=0x33b
tosp=0x33c
0xe:pti[0] nrow=17 offs=0
0x12:pri[0] offs=0x1e34
…
0x30:pri[15] offs=0x6e2
0x32:pri[16] offs=0x583
block_row_dump:
tab 0, row 0, @0x1e34
tl: 332 fb: --H-F— lb: 0x0 cc: 79
nrid: 0x018083f8.e
col 0: [ 5] c4 04 5a 27 1b
col 1: [ 7] 47 59 30 32 30 30 31
col 2: [ 4] c3 15 11 04
col 3: [12] 31 38 37 33 34 34 32 30 30 30 30 36
col 4: [12] 31 34 30 34 34 34 32 30 30 30 30 31
col 5: [30]
……省略部分内容
上述的dump信息表示的是rdba 地址01808438的第0行,也就是我们大家所理解的第一行数据。我们可以发现在这行记录中,行头存在一个nrid地址(0x018083f8.e)。 既然这里提到nrid,那么我们就有必要来解释一下。当出现行迁移或者行链接时,数据块内用nrid来标示下一个rowid地址。
首先我们说一下Oracle的行迁移。行迁移分为几种情况,最常见的一种其实是数据块内的。一个数据块中单条记录的最大列数是255列,当一行记录的列超过255时,其他的列数据库会被Oracle 分成另外一个row piece存在同一个数据块中(当然也有可能存到其他数据块)。也就是说超过255列的行数据,会被分成多个row piece。而当我们读取这个行数据时,怎么知道是一个完整的整体呢?答案就是nrid。Oracle 通过nrid来将这多个row piece 串在一起,组成一个完整的行数据。另外其中常见情况就是更新时,数据块内剩余空间不足容纳更新之后的列数据时,也会产生行迁移。
而行链接通常是一个数据块不足以容纳一条数据,需要申请多个数据块来容纳一条记录,而这种情况通常都是lob的使用场景下才会出现。正因为如此,大家所见的场景通常其实都是行迁移,而非行链接。
想到这一点,那么我们再回头去看下前面的错误。row 01808438.0 表示这个数据块的第0行,而该数据块的第0行所存在的nrid地址是0x018083f8.e; 那么我们进一步到0x018083f8数据块中去寻找第e行记录,却发现结果是这样的。
Object id on Block? Y
seg/obj: 0xc03d01 csc: 0xb37.78bb5e9f itc: 3 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1807d8a ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000a.013.000cdc01 0x01c02834.6573.33 --U- 2 fsc 0x0000.78cbf31d
0x02 0x000a.001.000cda7a 0x0080150a.64d3.21 C— 0 scn 0x0b37.78b584df
0x03 0x000a.01e.000cdade 0x00801510.64d3.13 C-U- 0 scn 0x0b37.78b99f21
data_block_dump,data header at 0x2b4fc709007c
===============
tsiz: 0x1f80
hsiz: 0x2e
pbl: 0x2b4fc709007c
bdba: 0x018083f80x018083f8
76543210
flag=--------
ntab=1
nrow=14
frre=-1
fsbo=0x2e
fseo=0x568
avsp=0x53a
tosp=0x53a
0xe:pti[0] nrow=14 offs=0
0x12:pri[0] offs=0x1d78
0x14:pri[1] offs=0x1c37
…
0x2a:pri[12] offs=0x6c2
0x2c:pri[13] offs=0x568
block_row_dump:
tab 0, row 0, @0x1d78
tl: 520 fb: -----L-- lb: 0x0 cc: 255
…省略部分内容
tab 0, row 13, @0x568
tl: 346 fb: --H-F— lb: 0x1 cc: 79
nrid: 0x018083f8.c
col 0: [ 5] c4 04 5a 3a 0a
col 1: [ 7] 47 59 30 32 30 30 31
col 2: [ 4] c3 15 11 04
…
col 76: [ 1] 80
col 77: [ 1] 80
col 78: [ 1] 80
end_of_block_dump
End dump data blocks tsn: 6 file#: 6 minblk 33784 maxblk 33784
可以发现,我们定位到0x018083f8数据块的第e行(也就是第14行),其实就是该数据块的最后一行数据。然而我们发现该行数据也存在一个nrid。该nrid是0x018083f8.c,这表示该33784数据块第12行记录。和第13行是组合成一条完整行记录的。
换句话说,我们前面报错的那条记录,应该有2个row piece,其中一个row piece 是存在的,其中一个row piece 本应该存在在33784 数据块中。但是存在33784中的这个row piece的nrid 是指向另外一行记录。很明显这是不匹配的。
正是因为如此,由于对应的row piece不正确,Oracle才报了上述的错误。
实际上遇到该错误之后,大多数人都会以为是索引的问题,通过drop 重建可以解决,然而这里的问题比较特殊。本质上是表自身的某条数据有问题, 所以这就是为什么客户重建索引会报错的原因。
SQL> CREATE INDEX “STATS”.“MONTHINDEX_STATUS2” ON “STATS”.“T_REPORT_MONTH” (“TARGET_298”, “UNIT_LEVEL”, “TARGET_VAL”, “MONTH_FLG”)
2 TABLESPACE “STATDATA” ;
第 1 行出现错误:
ORA-00600: 内部错误代码, 参数: [kdsgrp1], [], [], [], [], [], [], []
最后我们清楚原因之后就可以很好解决这个问题了。通过rowid的方式跳过这行有问题的记录,将其他数据取出,重建表即可。
13.7 城门失火:Goldengate引发的数据库故障
2014年11月8日21点左右某客户的数据库集群出现swap耗尽的情况,导致数据库无法正常使用。检查数据库日志,发现相关的错误如下所示。
Sat Nov 08 20:50:23 CST 2014
Process startup failed, error stack:
Sat Nov 08 20:50:41 CST 2014
Errors in file /oracle/product/10.2.0/admin/xxx/bdump/xxx1_psp0_1835540.trc:
ORA-27300: OS system dependent operation:fork failed with status: 12
ORA-27301: OS failure message: Not enough space
ORA-27302: failure occurred at: skgpspawn3
Sat Nov 08 20:50:41 CST 2014
Process m000 died, see its trace file
根据数据库alert log的报错信息,我们可以知道从20:50左右开始出现ORA-27300、ORA-27301错误。根据Oracle MOS 文档Troubleshooting ORA-27300 ORA-27301 ORA-27302 errors [ID 579365.1]的描述可以知道,这个错误产生的原因就是内存不足导致。出现该错误的主机为Oracle RAC的1节点。该主机物理内存大小为96GB,Oracle SGA配置为30GB,PGA配置为6GB,操作系统Swap配置为16GB。
正常情况下,物理主机的内存是可以满足正常使用的。由于在20:56开始出现无法fork 进程,即使无法分配内存资源,说明在该时间点之前物理主机的内存使用已经出现问题了。通过Nmon 监控数据可以发现,实际上从当天下午18点左右,操作系统物理内存free memory就开始大幅下降如图13-5所示。
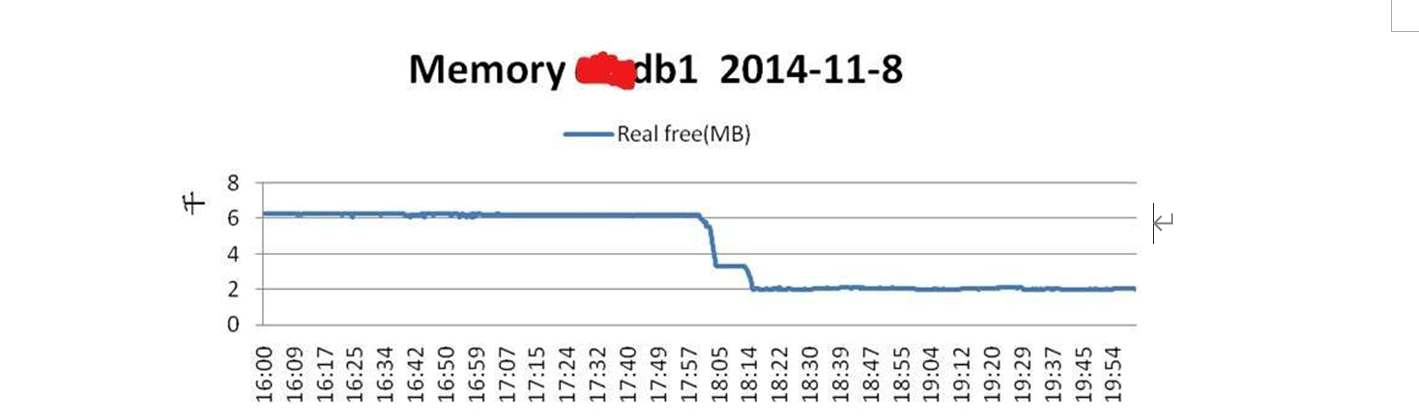
图13-5
从图13-5可以看出,数据库主机节点1的物理内存大约从18:01开始突然下降得很厉害,到18:14左右时,物理内存free Memory已经不足2GB了。而该主机的物理内存中,大部分为Process%所消耗,如图13-6所示。
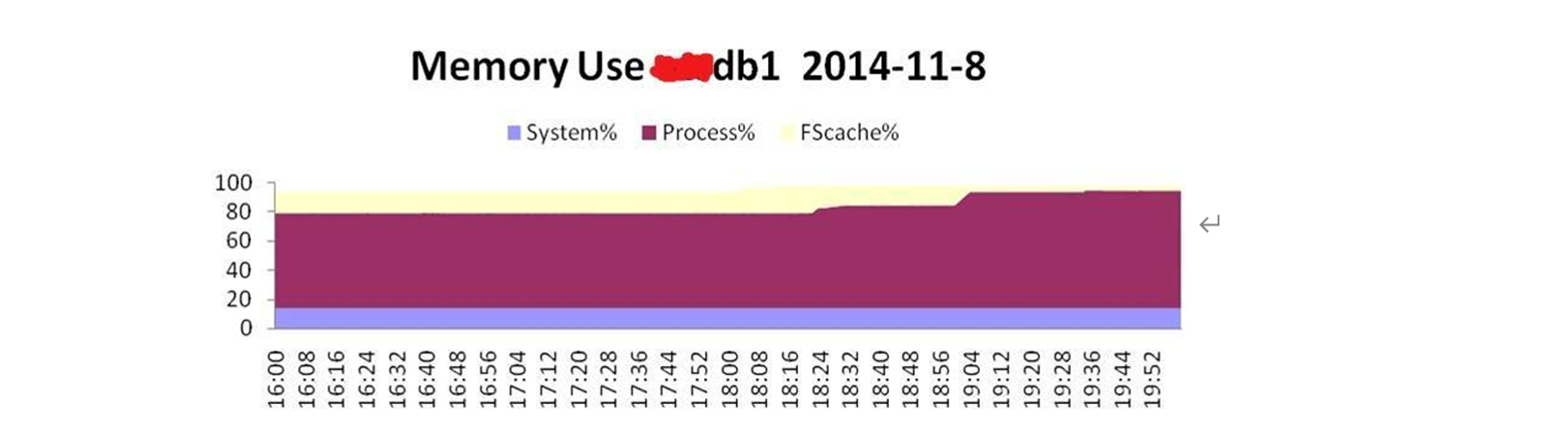
图13-6
可以看到,该节点从18:20左右Process% 消耗的内存开始突然增加,到19:52时,基本上消耗了所有的物理内存。这里需要注意的,这里的Process% 内存消耗,是指该主机上的所有应用程序的进程消耗,包括Oracle的所有进程,以及其他应用程序的进程。
然而我根据Oracle 的AWR历史数据进行查询,发现并没有明显的会话消耗内存很高的情况。
SQL> select INSTANCE_NUMBER,SNAP_ID,STAT_NAME,value from dba_hist_osstat
2 where stat_name like ‘VM%’ and snap_id > 13550 and snap_id < 13559
3 order by 1,2;
INSTANCE_NUMBER SNAP_ID STAT_NAME VALUE
1 13551 VM_IN_BYTES 4691725926408
1 13551 VM_OUT_BYTES 14798577905664
1 13552 VM_OUT_BYTES 14799491960832
1 13552 VM_IN_BYTES 4691727376392
1 13553 VM_OUT_BYTES 14800572719088
1 13553 VM_IN_BYTES 4691727429624
1 13554 VM_IN_BYTES 4691777949696
1 13554 VM_OUT_BYTES 14820690083832
1 13555 VM_OUT_BYTES 14857568350200
1 13555 VM_IN_BYTES 4693160173560
1 13556 VM_OUT_BYTES 14876324397048
1 13556 VM_IN_BYTES 4695865995264
1 13558 VM_OUT_BYTES 14882330329080
1 13558 VM_IN_BYTES 4829460062208
2 13551 VM_OUT_BYTES 2273165344776
2 13551 VM_IN_BYTES 347420766216
2 13552 VM_OUT_BYTES 2273229529104
2 13552 VM_IN_BYTES 347420766216
2 13553 VM_OUT_BYTES 2273286496272
2 13553 VM_IN_BYTES 347420766216
2 13554 VM_OUT_BYTES 2324453691408
2 13554 VM_IN_BYTES 347433598968
2 13555 VM_IN_BYTES 347559141384
2 13555 VM_OUT_BYTES 2383075213320
2 13556 VM_IN_BYTES 347674648584
2 13556 VM_OUT_BYTES 2430000705552
2 13557 VM_IN_BYTES 473531183112
2 13557 VM_OUT_BYTES 2499316277256
2 13558 VM_OUT_BYTES 2507250249744
2 13558 VM_IN_BYTES 473575673856
看到上列数据不要惊讶,上列数据为累积数据,我们需要前后相减进行计算。
16:00 --17:00点:
SQL> select (4691727376392-4691725926408)/1024/1024 from dual;
(4691727376392-4691725926408)/1024/1024
---------------------------------------
1.3828125
SQL> select (14799491960832-14798577905664)/1024/1024 from dual;
(14799491960832-14798577905664)/1024/1024
-----------------------------------------
871.710938 —换出的内存,单位为M.
17:00 --18:00点:
SQL> select (4691727429624-4691727376392)/1024/1024 from dual;
(4691727429624-4691727376392)/1024/1024
---------------------------------------
.050765991
SQL> select (14800572719088-14799491960832) /1024/1024 from dual;
(14800572719088-14799491960832)/1024/1024
-----------------------------------------
1030.69139 —换出的内存,单位为M.
18:00 --19:00点:
SQL> select (4691777949696-4691727429624)/1024/1024 from dual;
(4691777949696-4691727429624)/1024/1024
---------------------------------------
48.1796951
SQL> select (14820690083832-14800572719088)/1024/1024 from dual;
(14820690083832-14800572719088)/1024/1024
-----------------------------------------
19185.4141 —换出的内存,单位为M.
19:00 --20:00点:
SQL> select (4693160173560-4691777949696)/1024/1024 from dual;
(4693160173560-4691777949696)/1024/1024
---------------------------------------
1318.1914
SQL> select (14857568350200-14820690083832)/1024/1024 from dual;
(14857568350200-14820690083832)/1024/1024
-----------------------------------------
35169.8555
20:00 --21:00点:
SQL> select (4695865995264-4693160173560)/1024/1024 from dual;
(4695865995264-4693160173560)/1024/1024
---------------------------------------
2580.47266
SQL> select (14876324397048-14857568350200)/1024/1024 from dual;
(14876324397048-14857568350200)/1024/1024
-----------------------------------------
17887.1602
从查询结果来看,Oracle 确实检查到了大量的换页操作,从18点~19点开始。但是我查询数据库18~21点的AWR数据却并没有发现有非常大的SQL操作。
SQL> select INSTANCE_NUMBER,snap_id,sum(SHARABLE_MEM)/1024/1024 from dba_hist_SQLstat
2 where snap_id > 13550 and snap_id < 13558
3 group by INSTANCE_NUMBER,snap_id order by 1,2;
INSTANCE_NUMBER SNAP_ID SUM(SHARABLE_MEM)/1024/1024
1 13551 28.9083166
1 13552 30.0213976
1 13553 28.7059259
1 13554 29.1716347
1 13555 29.1961374
1 13556 35.6658726
2 13551 19.5267887
2 13552 20.9447975
2 13553 23.5789862
2 13554 21.0861912
2 13555 22.5129433
2 13556 23.0631037
2 13557 21.7776823
据业务了解,数据库节点2节点每周六会进行一次批量的操作,这可能会产生影响。基于这一点,我们分析了节点2节点的nmon数据,发现内存使用率也非常高,如图13-7所示。
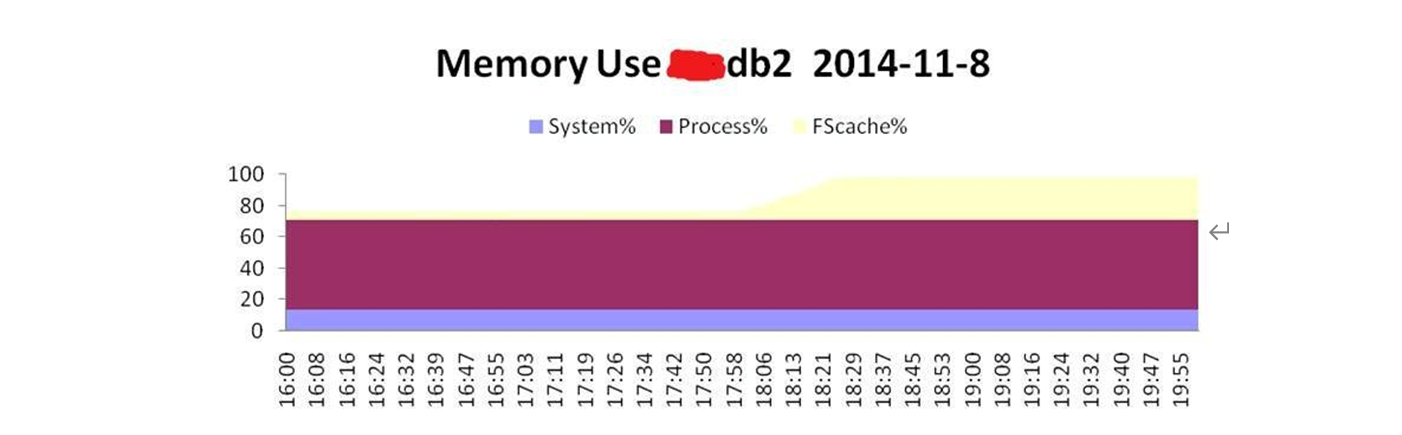
图13-7
从节点2的数据来看,内存的变化也是在18:00左右。然而变化的却是FScache%, Process%的指标是没有变化的。根据这一点可以判断,在该时间段内数据库产生了大量的归档日志,进而导致文件系统cache所占的内存比例大幅上升。进一步检查数据库发现确实这段时间产生的日志相对较多。
由于在该时间段产生了大量的操作,因此就可能就会产生大量的gc 等待。从节点2的awr数据来看,确实产生了大量的gc等待事件,如下所示。
Event Waits Time(s) Avg Wait(ms) % Total Call Time Wait Class
gc buffer busy 11,042,588 20,687 2 28.1 Cluster
gc current block 2-way 1,113,439 16,922 15 23.0 Cluster
gc current block congested 19,115 10,336 541 14.1 Cluster
CPU time 9,914 13.5
gc cr multi block request 6,430,854 3,965 1 5.4 Cluster
那么这里有没有可能是由于大量gc 的产生,导致Oracle RAC的核心进程LMS等进程的负载增加,导致内存消耗的剧增呢?实际上,这一点是可以排除的。如果是Oracle的进程内存消耗较高,那么节点2的内存消耗变动,在18:00左右开始上升的应该是Process%,而不是FScache%.
到这里我们可以总结如下两点。
(1)节点1 内存耗光,主要是Process %消耗。
(2)节点2的内存的变化主要是发生在FScache%。
基于这两点,我们可以排除是数据库本身的进程消耗的大量内存导致swap被耗尽。在进一步分析时,发现于节点1部署了Oracle Goldengate同步软件,所以我怀疑极有可能是该软件导致。基于这个猜想,我进行了简单分析。如下是ogg的report信息。
2014-11-08 18:01:38 INFO OGG-01026 Rolling over remote file ./dirdat/nt006444.
2014-11-08 18:03:43 INFO OGG-01026 Rolling over remote file ./dirdat/nt006445.
…省略部分内容
2014-11-08 20:38:18 INFO OGG-01026 Rolling over remote file ./dirdat/nt006551.
2014-11-08 20:52:02 INFO OGG-01026 Rolling over remote file ./dirdat/nt006553.
我们可以发现,在故障时间段内该进程的操作明显要比其他时间段要频繁得多。从18点到20:38,Goldengate 抽取进程产生的trail文件超过100个。由于ogg本身也是部署在Oracle用户下,因此这也不难解释为什么节点1从该时间点开始内存的消耗会突然增加,而且nmon监控显示是Process%消耗增加。通过Nmon的监控数据,我们也可以发现paging的操作主要是goldengate的extract进程导致,如图13-8所示。

图13-8
Goldengate进程之所以会消耗大量的内存,是因为extract进程首先需要将数据读取到本地节点的内存中(即Goldengate的cachesize)。然后将cache中的数据解析为Goldengate特有的日志格式,并写入到trail文件中。通常情况下,当遭遇大事务时,Goldengate extract进程消耗的内存会大幅增加,因为Goldengate默认是以事务为单位(如果没有大事务拆分处理的话)。上面数据是截取的部分内容。从时间点来看,和之前的nmon监控内存的变化是完全符合的。这可以完美解释为什么查询节点1的AWR数据发现从18点之后开始出现大量swap,但是数据库本身的却查不到内存消耗高的进程。因此最终确认导致此次故障的最本质原因是由于Goldengate抽取进程消耗大量内存,最后产生大量的swap,进而最终影响了业务。不过这里我并不推荐大家通过设置cachesize参数来控制goldengate 进程的内存消耗,这样有可能降低Goldengate 的处理能力。但是我们可以通过其他手段来处理这个问题,比如将大事务进程拆分等。以上是在我工作中遇到的比较经典的一些的案例,在此与大家分享,希望对大家的成长有帮助。也祝愿大家能够找到适合自己的兴趣点和学习方法。
