




问:数据库是否需要参数调整?
答:系统参数一定要调,而且还要合理的调,但调好了并不一定能解决所有的问题。参数调整是性能优化的必要条件,但不是充分条件。
问:参数调整的方式是否一样?
答:业务特征不同,参数调整的方向也不同,OLTP 和 OLAP 优化方向不同。
本文主要介绍数据库参数优化相关方法以及优化建议。
数据库参数获取
首先我们需要获取数据库参数信息。
- 通过 V$DM_INI 系统视图获取 dm.ini 参数信息
| 列 | 数据类型 | 说明 |
|---|---|---|
| PARA_NAME | VARCHAR (128) | 参数名称 |
| PARA_VALUE | VARCHAR (256) | 系统参数值 |
| MIN_VALUE | VARCHAR (256) | 最小值 |
| MAX_VALUE | VARCHAR (256) | 最大值 |
| MPP_CHK | CHAR(1) | 是否检查 MPP 节点间参数一致性。Y 是,N 否 |
| SESS_VALUE | VARCHAR (256) | 会话参数值 |
| FILE_VALUE | VARCHAR (256) | INI 文件中参数值 |
| DESCRIPTION | VARCHAR (256) | 参数描述 |
- 通过性能监控工具获取 dm.ini 参数信息
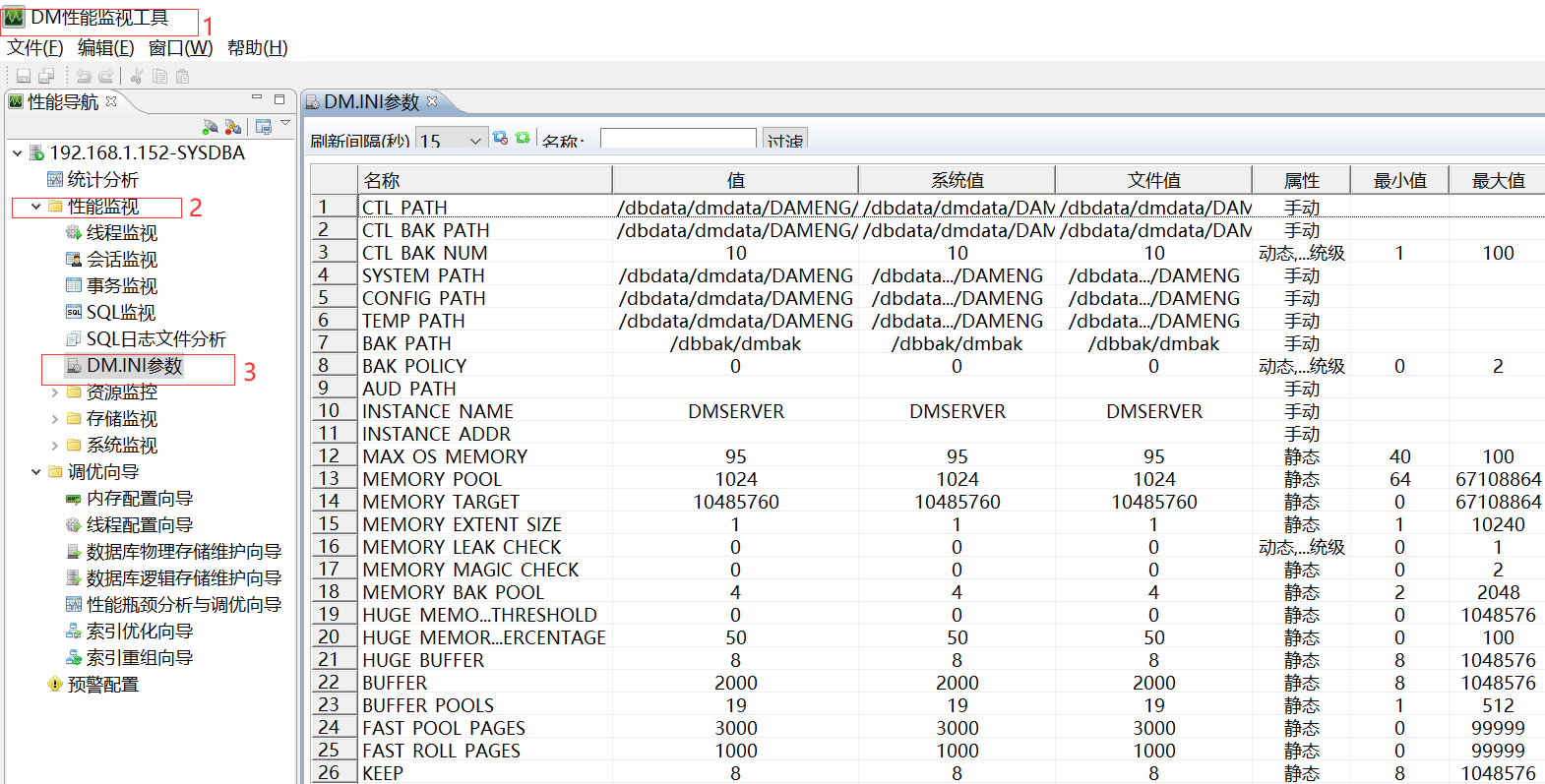
资源类参数配置建议
- 通过获取数据库服务器的配置和业务场景需求我们可以进行资源类参数配置优化。
| 参数 | 调整范围说明 |
|---|---|
| BUFFER | 内存足够的情况下,可根据数据文件的大小调整,内存不充足的情况下,可调整为可用物理内存的 60%~80% |
| BUFFER_POOLS | 高并发 OLTP 场景下,可根据客户端的并发连接数或者中间件连接池的大小进行调整 |
| MAX_BUFFER | 系统最大缓冲区大小,以兆为单位。通常设置为与 BUFFER 相同 |
| RECYCLE | 当排序缓冲区及哈希缓冲区不足的情况下,系统会优先使用 RECYCLE 缓冲区,RECYCLE 缓冲区不够,再刷临时表空间。在 OLAP 场景下,如果存在大表之间的关联查询,可以将值调大,尽可能不要使用临时表空间 |
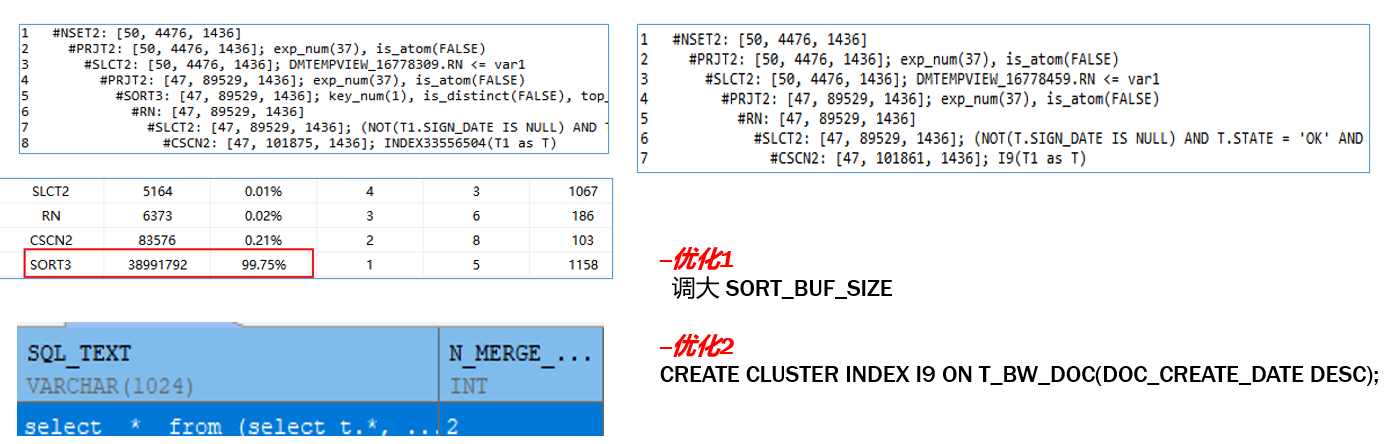
| SORT_BUF_SIZE | 排序缓存区最大值。可以适当调大,如果在动态性能视图 v$SORT_HIST0RY 和 v$MTAB_USED_HISTORY 中监控到外排序,则适当调大建索引时可调大。通常不超过 20 MB |
| DICT_BUF_SIZE | 字典缓冲区大小。如果数据库中对象数量较多,或者存在大量分区表,可适当调大 |
| HJ_BUF_GL0BAL_SIZE | HASH 连接操作符的数据总缓存大小 (>= HJ_BUF_SIZE)。内存足够的情况下,可以适当调大。实际使用大小,由包含 HASH JOIN 操作符的 SQL 并发数决定 |
| HJ_BUF_SIZE | 单个 HASH 连接操作符的数据总缓存大小。在 OLTP 环境中,建议采用默认值。在 OLAP 环境下,可以根据参与 HASH JOIN 的数据量调大 |
| HJ_BLK_SIZE | 默认 1 即可,如果 HJ_BUE_SIZE 很大也可适当调大 |
| HAGR_BUF_GLOBAL_SIZE | HAGR、DIST、集合操作、SPL2、NTTS2 以及 HTAB 操作符的数据总缓存大小 (>=HAGR_BUF_SIZE),系统级参数,以兆为单位 |
| HAGR_BUF_SIZE | 单个 HAGR、DIST、集合操作、SPL2、NTTS2 以及 HTAB 操作符的数据总缓存大小。监控 V$SORT_HISTORY,判断是否需要调整 |
| OLAP_FLAG | 用联机分析处理,0:不启用;1:启用;2:不启用,同时倾向于使用索引范围扫描。该参数会影响到计划的生成。在 OLTP 环境下,通常保持默认值 2 |
| MAX_PARALLEL_DEGREE | 设置最大并行任务个数。建议设置为 6~8 |
| PARALLEL_POLICY | 用来设置并行策略。0 表示不支持并行;1 表示自动配置并行工作线程个数(与物理 CPU 核数相同);2 表示手动设置并行工作线程数。建议设置为 2 手动并行 |
| IO_THR_GROUPS | 表示 IO 线程组个数。建议值>=8,提升 IO 效率 |
| HIO_THR_GROUPS | HUGE 缓冲区 I0 线程组数目。使用 HUGE 表的业务场景,建议值>=8,提升 HUGE 表的 I0 效率 |
查询优化参数
下面我们可以通过案例来进行查询优化参数优化。
- SORT_BUF_SIZE
计算 select sqrt(row_cnt)*sqrt(bdta_size)*row_size*1.0/1024*1.0/1024;v$sort_history SF_SI 函数,如下图所示:
- TOP_ORDER_OPT_FLAG
语句内含有 TOP + ORDER,且 ORDER BY 列属于索引前导列,如下所示:
CREATE INDEX IND1 ON T1(C1, C2); |

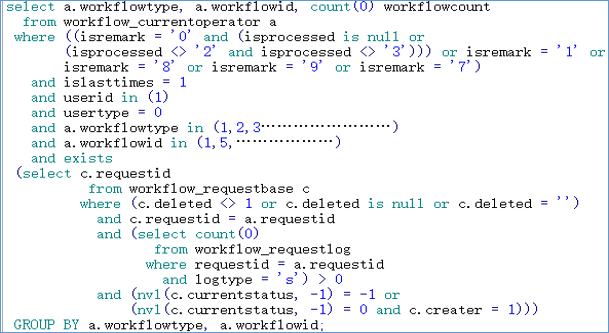
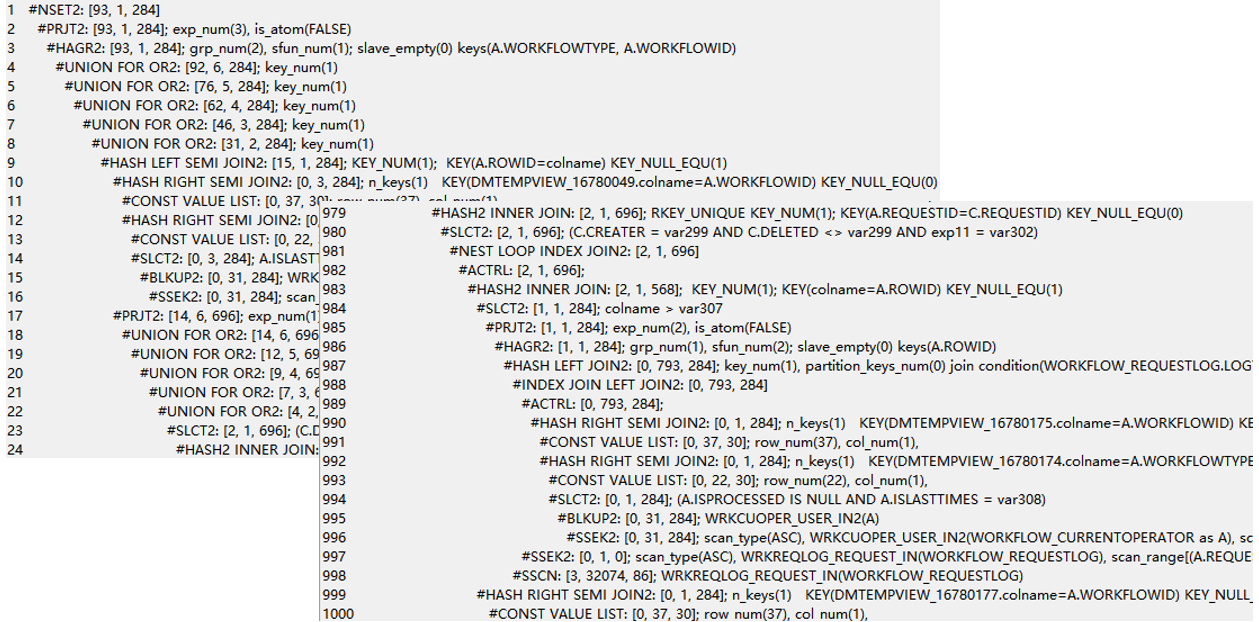
- OPTIMIZER_OR_NBEXP
OR 表达式的优化方式如下:
- 0:不优化。
- 1:生成UNION_FOR_OR 操作符时,优化为无 KEY 比较方式。
- 2:OR 表达式优先考虑整体处理方式。
- 4:相关子查询的 OR 表达也优考虑整体处理方式。
- 7:表示同时进行 1、2、4 优化。
如果性能问题的 SQL 语句存在 OR 条件,则一定要重视,性能问题是否与 OR 表达式有关系。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
