




本章节将介绍 SQL 优化工作中两个至关重要的概念,统计信息和索引。通过本章节您将了解到统计信息和索引在 SQL 执行过程中是如何影响运行效率,以及我们该如果通过统计信息和索引对 SQL 进行优化。
何为统计信息
统计信息主要是描述数据库中表和索引的大小数以及数据分布状况等的一类信息。比如:表的行数、块数、平均每行的大小、索引的高度、叶子节点数以及索引字段的行数等。
统计信息对于 CBO(基于代价的优化器)生成执行计划具有直接影响。例如在嵌套循环中需要选择小表作为驱动表,两个关联表哪个是小表完全取决于统计信息中记录的数据量信息。此外,访问一个表是否要走索引,关联查询能否采用其它关联方式等都是 CBO 基于统计信息确定的。因此,统计信息的准确是生成最优执行计划的必要前提。
统计信息收集方法
收集统计信息的方法如下所示:
--收集指定用户下所有表所有列的统计信息: |
警告统计信息收集过程中将对数据库性能造成一定影响,避免在业务高峰期收集统计信息。
自动收集统计信息
DM 数据库支持统计信息的自动收集,当全表数据量变化超过设定阈值后可自动更新统计信息。
--打开表数据量监控开关,参数值为 1 时监控所有表,2 时仅监控配置表 |
--函数各参数介绍 |
何为索引
在谈索引之前,我们先来想象一下在图书馆的借书流程。
在图书馆内的查询终端中,输入书名就能查到对应的唯一标识索书号,类似于 P163-33/143 这样的一个编码,书架上的书都是按照这个编码进行排序的。有了这个编码再去对应的书架上,很快就能找到对应的书在书架的具体位置了。
即使图书馆有再多的书,通过这种方法也能够在 10 分钟以内找到你要的书。但如果所有图书是毫无规则的摆放呢?最坏情况下需要检查每个书架的每一本数才能找到想要的书。这个索书号就相当于数据库中的索引,可以在最短时间内定位到数据所在行,减小时间开销。
索引存储结构
了解索引的存储结构对于正确使用和优化索引有很大帮助,最常见的索引结构为 B* 树索引,存储结构如下图所示:
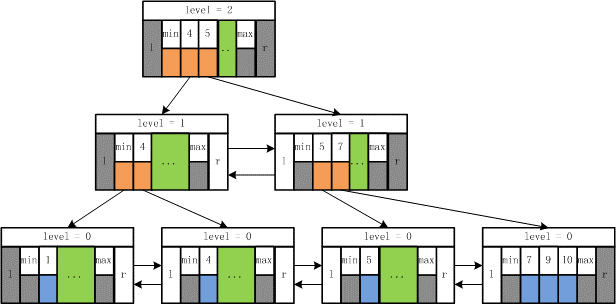
最顶层的为根节点,最底层的为叶子节点,中间层为内节点。实际使用当中一般不止 3 层(取决于数据量大小),除根节点以及叶子节点以外仅为内节点。对于一个 m 阶(本例中 m=2)的 B*树 存储结构有以下几个特点:
- 每个结点最多有 m 个子结点。
- 除了根结点和叶子结点外,每个结点最少有 m/2(向上取整)个子结点。
- 如果根结点不是叶子结点,那根结点至少包含两个子结点。
- 所有的叶子结点都位于同一层。
- 每个结点都包含 k 个元素,这里 m/2 ≤ k < m,这里 m/2 向下取整。
- 每个节点中的元素从小到大排列。
- 每个元素左结点的值都小于或等于该元素,右结点的值都大于或等于该元素。
- 所有的非叶子节点只存储关键字信息。
- 所有的叶子结点中包含了全部元素的信息。
- 所有叶子节点之间都有一个链指针。
可以看出在该存储结构中查找特定数据的算法复杂度为 O(log2N),查找速度仅与树高度有关。
对于聚集索引叶子节点存储的元素是数据块即为整行数据,对于非聚集索引叶子节点存储的元素是索引字段的所对应的聚集索引的值或 rowid,如果需要获取其它字段信息需要根据聚集索引的值或 rowid 回表 (BLKUP) 进行查询。
索引适用范围
在以下场景下可考虑创建索引:
- 仅当要通过索引访问表中很少的一部分行(1%~20%)。
- 索引可覆盖查询所需的所有列,不需额外去访问表。
注意对于一个表来说索引并非越多越好,过多的索引将影响该表的 DML 效率。
存在下列情况将导致无法使用索引:
- 组合索引中,条件列中没有组合索引的首列。
- 条件列带有函数或计算。
索引排序是按照字段值进行排序的,字段值通过函数或计算后的值索引无法获取。 - 索引过滤性能不好时。
如对一张 10 万条记录的表进行条件查询,获取 5 万条数据,通过索引进行查找效率低于全表扫描,将放弃使用索引。
