




本章节主要介绍在 DM 数据库中如何使用字符串。
适用场景
| 软件 | 版本 |
|---|---|
| 操作系统 | Redhat 7 及以上版本 |
| DM 数据库 | DM 8.0 及以上版本 |
| CPU 架构 | x86、ARM、龙芯、飞腾等国内外主流 CPU |
操作方法
遍历字符串
遍历字符串方法如下:
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v AS SELECT '天天向上' AS 汉字,'TTXS' AS 首拼 FROM dual; |
- 使用 CONNECT BY 子句,将视图 v 循环显示并给出定位表示,示例语句如下所示:
SELECT v.汉字, v.首拼, LEVEL FROM v CONNECT BY LEVEL <= LENGTH (v.汉字); |
- 通过函数
substr(v.汉字,level,?)得到需要的结果,示例语句如下所示:
SELECT v.汉字,v.首拼,LEVEL,SUBSTR (v.汉字, LEVEL, 1) AS 汉字拆分, |
输出结果:

CONNECT BY 是树形查询中的一个子句,后面的 level 是一个“伪列”,表示树形中的级别层次,通过 level<=4 实现循环 4 次的目的。
在字符串中增加引号
- 将一个单引号换成两个单引号,引入单引号,示例语句如下所示:
SELECT 'girl''day' qmarks FROM DUAL UNION ALL SELECT '''' FROM DUAL; |
- 使用界定符,通过 Q 或者 q 开头,字符串前后使用界定符 “ ‘ ”,示例语句如下所示:
SELECT q'[girl'day]' qmarks FROM DUAL UNION ALL SELECT q'[']' FROM DUAL; |
输出结果:

计算字符出现的次数
使用函数 regexp_count、regexp_replace 或 translate 统计子串个数。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v AS SELECT 'STUDENT,TEACHER,TEAM' AS str FROM DUAL; |
- 使用函数 regexp_count 统计子串个数,示例语句如下所示:
SELECT regexp_count(str,',')+1 as cnt FROM v; |
- 使用 regexp_replace 迂回求值统计子串个数,示例语句如下所示:
SELECT length(regexp_replace(str,'[^,]'))+1 as cnt FROM v; |
- 使用 translate 统计子串个数,示例语句如下所示:
SELECT length(translate(str,',' || str,','))+1 AS cnt FROM v; |
删除字符串中不需要的字符
使用 translate 或者 regexp_replace 在某个字段中去掉不需要的字符。
比如在员工姓名中有 (AEIOU) 的元音字母,去掉元音字母。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v |
- 使用 translate 方法,示例语句如下所示:
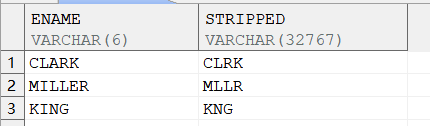
SELECT ename,translate(ename,'1AEIOU','1') stripped1 FROM v; |
- 使用正则函数 regexp_replace [] 内列举的字符替换为空,示例语句如下所示:
SELECT ename,regexp_replace(ename,'[AEIOU]') AS stripped FROM v; |
输出结果:
将字符与数字分离
使用 regexp_replace 正则表达式实现字符串中字符与数字分离。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v |
- 使用 regexp_replace 正则表达式,示例语句如下所示:
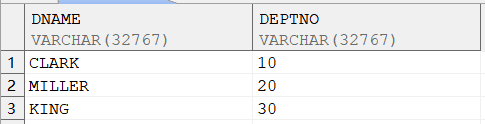
SELECT REGEXP_REPLACE (data, '[0-9]', '') dname, |
输出结果:
查询只包含字母或数字的数据
使用 regexp_like 实现查询只包含字母或者数字型的数据。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v |
在上面的语句中,有些数据包含了空格、逗号、$等字符。现在要求只返回其中只有字母及数字的行。
- 使用 regexp_like 语句,示例语句如下所示:
SELECT data FROM v WHERE REGEXP_LIKE (data, '^[0-9a-zA-Z]+$'); |
注意
- regexp_like(data,’A’) 对应普通的like ‘%A%’。
- 前面加“^”,regexp_like(data,’^A’) 对应普通的like ‘A%’,没有前模糊查询。
- 后面加“$”,regexp_like(data,’A$’) 对应普通的like ‘%A’,没有后模糊查询。
- 前后各加“^$”,regexp_like(data,’^A$’) 对应普通的like ‘A’,变成精确查询。
按字符串中的数字排序
通过正则表达式或者 translate 函数实现按字符串中的数值排序。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v |
- 用正则表达式替换非数字字符,示例语句如下所示:
SELECT data, TO_NUMBER (REGEXP_REPLACE (data, '[^0-9]', '')) AS deptno |
- 使用
translate函数,直接替换掉非数字字符,示例语句如下所示:
SELECT data, |
创建分隔列表
通过 listagg 分析函数实现多行字段的合并显示。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v |
- 使用 listagg 分析函数实现合并显示,示例语句如下所示:
SELECT deptno,SUM (sal) AS total_sal, |
输出结果:
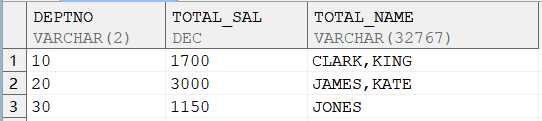
同 sum 一样,listagg 函数也起到汇总结果作用。sum 将数值结果累计求和,而 listagg 是把字符串的结果连在一起。
提取子串
通过 regexp_substr 实现第 n 个子串的分割。
比如在”CLARK,KATE,JAMES”字符串中提取出“KATE”。
- 创建测试视图,示例语句如下所示:
CREATE OR REPLACE VIEW v AS SELECT 'CLARK,KATE,JAMES''CLARK,KATE,JAMES' AS name; |
- 使用
regexp_substr分割子串,示例语句如下所示:
SELECT REGEXP_SUBSTR (v.name,'[^,]+',1,2) AS 子串 FROM v; |
参数 1:“^”在方括号里表示否的意思,+ 表示匹配 1 次以上。第二个参数表示匹配不包含逗号的多个字符。
参数 2:“1”表示从第一个字符开始。
参数 3:“2”表示第二个能匹配目标的字符串,也就是 KATE。
分解 IP 地址
使用 regexp_substr 实现字符串拆分。比如将 IP 地址“192.168.1.111”中的各段取出来,示例语句如下所示:
SELECT REGEXP_SUBSTR (v.ip,'[^.]+',1,1)a, |
输出结果:

参考文档
更多 SQL 语言使用说明,请参考《DM_SQL 语言使用手册》,手册位于数据库安装路径 /dmdbms/doc 文件夹下。如有其他问题,请在社区内咨询。
