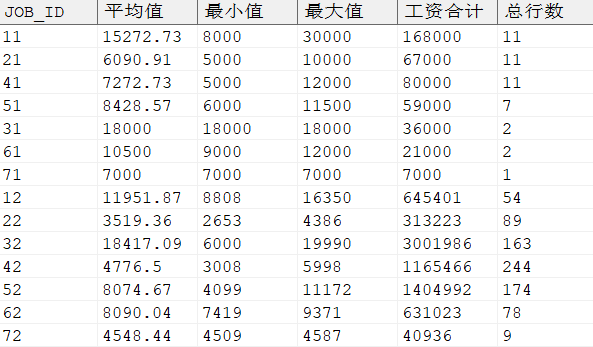
SELECT job_id, AVG (salary) AS 平均值, MIN (salary) AS 最小值, MAX (salary) AS 最大值, SUM (salary) AS 工资合计, COUNT (*) AS 总行数 FROM dmhr.employee GROUPBY job_id;
输出结果:
注意
当表中没有数据时,不加 group by 会返回一行数据,加了 group by 无数据返回。
建立空表,示例语句如下所示:
CREATETABLE dmhr.employee2 ASSELECT * FROM dmhr.employee WHERE1 = 2;
不加 group by,示例语句如下所示:
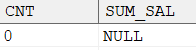
SELECTCOUNT (*) AS cnt, SUM (salary) AS sum_sal FROM dmhr.employee2 WHERE job_id = 11;
输出结果:
增加 group by,示例语句如下所示:
SELECTCOUNT (*) AS cnt, SUM (salary) AS sum_sal FROM dmhr.employee2 WHERE job_id = 11 GROUPBY job_id;
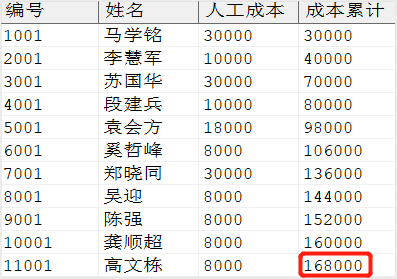
SELECT employee_id AS 编号, employee_name AS 姓名, salary AS 人工成本, SUM (salary) OVER (ORDERBY employee_id) AS 成本累计 FROM dmhr.employee WHERE job_id = 11;
输出结果:
通过结果可以看出,分析函数“sum (salary) over (order by employee_id)”的结果 (168000) 是排序“over (order by employee_id)”后第一行到当前行的所有工资之和。
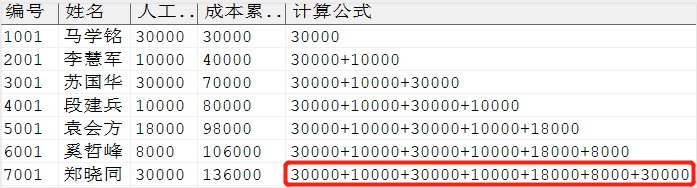
为了形象地说明这一点,我们用 listagg 模拟出每一行是哪些值相加。示例语句如下所示:
//使用 listagg 函数模拟员工总成本的累加值
SELECT employee_id AS 编号, employee_name AS 姓名, salary AS 人工成本, SUM (salary) OVER (ORDERBY employee_id) AS 成本累计, (SELECTLISTAGG (salary, '+') WITHINGROUP (ORDERBY employee_id) FROM dmhr.employee b WHERE b.job_id = 11AND b.employee_id <= a.employee_id) 计算公式 FROM dmhr.employee a WHERE job_id = 11 ORDERBY employee_id;
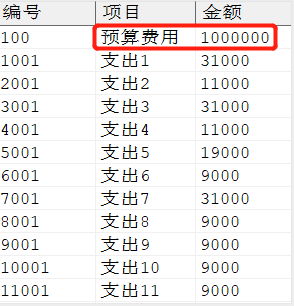
INSERTINTO dmhr.detail VALUES(100,'预算费用',1000000); commit; INSERTINTO dmhr.detail SELECT employee_id as 编号,'支出' || rownumas 项目, salary+1000as 金额 FROM dmhr.employee WHERE job_id=11; commit;
//查询
SELECT * FROM dmhr.detail;
输出结果:
这是模拟的一个消费流水账,假设已经预交费用 1000000,需要得到每笔费用的余额。
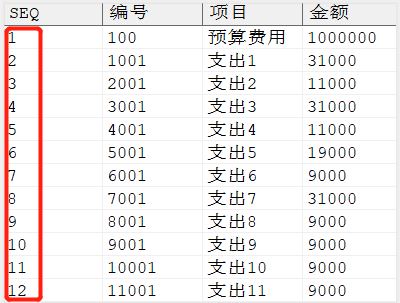
对流水账排序并生成序号,示例语句如下所示:
SELECTROWNUMAS seq, a.* FROM ( SELECT 编号, 项目, 金额 FROM dmhr.detail ORDERBY 编号) a;
输出结果:
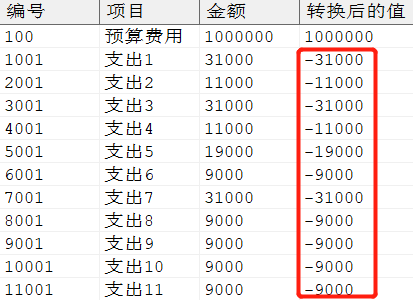
支出金额变成负数,示例语句如下所示:
WITH x AS (SELECTROWNUMAS seq, a.* FROM ( SELECT 编号, 项目, 金额 FROM dmhr.detail ORDERBY 编号) a) SELECT 编号,项目,金额, (CASEWHEN seq = 1THEN 金额 ELSE -金额 END) AS 转换后的值 FROM x;
输出结果:
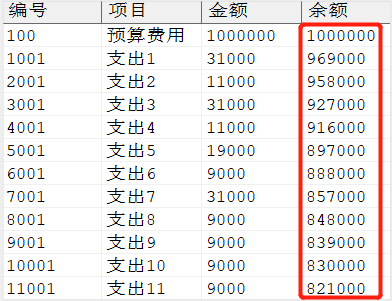
累加得到余额,示例语句如下所示:
WITH x AS (SELECTROWNUMAS seq, a.* FROM ( SELECT 编号, 项目, 金额 FROM dmhr.detail ORDERBY 编号) a) SELECT 编号,项目,金额, SUM (CASEWHEN seq = 1THEN 金额 ELSE -金额 END) OVER (ORDERBY seq) AS 余额 FROM x;
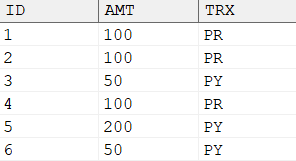
先要求计算每次存/取款后的余额,如果 trx 是 PR,则加上 amt 值代表的金额;否则减去 amt 值代表的金额。这实际上是一个累加问题,我们可以把取款的值先变成负数。
将取款值变成负数,示例语句如下所示:
SELECTid, CASEWHEN trx = 'PY'THEN'取款'ELSE'存款'END 存取类型, amt 金额, (CASEWHEN trx = 'PY'THEN -amt ELSE amt END) AS 余额 FROM v ORDERBYid;
输出结果:
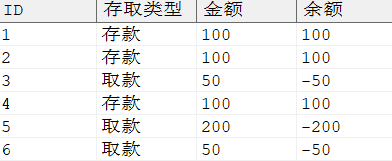
累加处理后的结果,示例语句如下所示:
SELECTid, CASEWHEN trx = 'PY'THEN'取款'ELSE'存款'END 存取类型, amt 金额, SUM (CASEWHEN trx = 'PY'THEN -amt ELSE amt END) OVER (ORDERBYid) AS 余额 FROM v ORDERBYid;
输出结果:
计算出现次数最多的值
使用 partition by 子句查看部门中哪个工资等级的员工最多。
这个问题可分成以下四步进行:
计算不同工资出现的次数,示例语句如下所示:
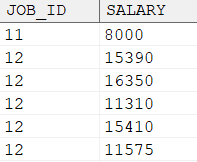
SELECT salary, COUNT (*) AS 出现次数 FROM dmhr.employee WHERE job_id = 11 GROUPBY salary;
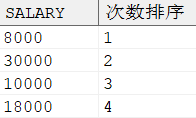
按次数排序生成序号,示例语句如下所示:
SELECT salary, DENSE_RANK () OVER (ORDERBY 出现次数 DESC) AS 次数排序 FROM ( SELECT salary, COUNT (*) AS 出现次数 FROM dmhr.employee WHERE job_id = 11 GROUPBY salary);
输出结果:
根据序号过滤得到需要的结果,示例语句如下所示:
SELECT salary FROM (SELECT salary, DENSE_RANK () OVER (ORDERBY 出现次数 DESC) AS 次数排序 FROM ( SELECT salary, COUNT (*) AS 出现次数 FROM dmhr.employee WHERE job_id = 11 GROUPBY salary) x) y WHERE 次数排序 = 1;
利用 partition by 子句查询各部门哪个工资等级的员工最多,示例语句如下所示:
SELECT job_id, salary FROM (SELECT job_id, salary, DENSE_RANK () OVER (PARTITIONBY job_id ORDERBY 出现次数 DESC) AS 次数排序 FROM ( SELECT salary, job_id, COUNT (*) AS 出现次数 FROM dmhr.employee GROUPBY job_id, salary) x) y WHERE 次数排序 = 1;
输出结果:
部门 12 中各工资档次出现次数都为 1,所以返回所有的数据。
返回最值所在的行数据
如需查询最大工资 (30000) 所在行的员工姓名。
我们可以使用分析函数满足这个需求,还可以同时取最大和最小值。示例语句如下所示:
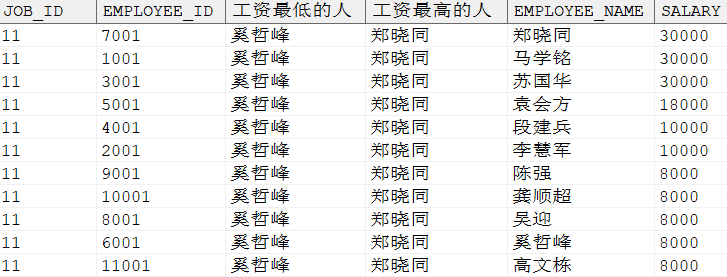
SELECT job_id, employee_id, MAX (employee_name) KEEP (DENSE_RANKFIRSTORDERBY salary) OVER (PARTITIONBY job_id) AS 工资最低的人, MAX (employee_name) KEEP (DENSE_RANKLASTORDERBY salary) OVER (PARTITIONBY job_id) AS 工资最高的人, employee_name, salary FROM dmhr.employee WHERE job_id = 11 ORDERBY1, 6DESC;
输出结果:
从上面的结果来看,此部门工资最低和最高的人都有重复值。keep (…) 部分得到的是一个数据集合,在使用 MAX 的聚集函数后就会仅返回一个字段。
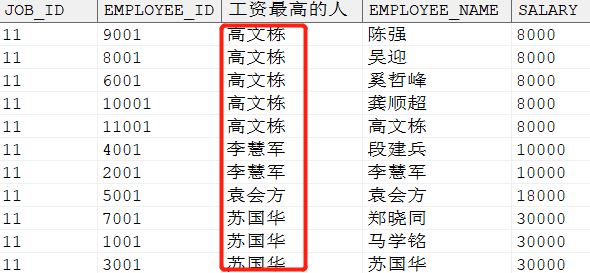
SELECT job_id,employee_id, LAST_VALUE (employee_name) OVER (PARTITIONBY job_id ORDERBY salary) AS 工资最高的人, employee_name,salary FROM dmhr.employee WHERE job_id = 11 ORDERBY1, 5;
输出结果:
当使用 last_value 时,我们发现结果不对,可以看到 first_value 和 last_value 的 order by 是在 over() 中,这实际上与累加模式类似。
求总和的百分比
使用分析函数 SUM() 和 OVER() 计算各部门工资合计及该合计工资占总工资的比例。用 group by 语句可以用到合计工资。
注意
当 OVER() 后不加任何内容时,就是对所有的数据进行汇总。
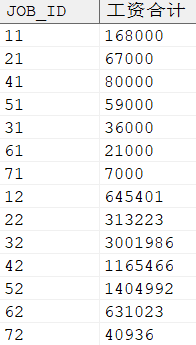
分组汇总,示例语句如下所示:
SELECT job_id, SUM (salary) 工资合计 FROM dmhr.employee GROUPBY job_id;
输出结果:
通过分析函数获取总合计,示例语句如下所示:
SELECT job_id, 工资合计, SUM (工资合计) OVER () AS 总合计 FROM ( SELECT job_id, SUM (salary) 工资合计 FROM dmhr.employee GROUPBY job_id) x;