本章节主要介绍在 DM 数据库中如何使用分区表。
使用分区技术有以下好处:
- 减少所有数据损坏的可能性,一个表空间损坏不影响其他表空间,提高可用性。
- 大大减少恢复时间。
- 将同一个表中的数据分布在不同的磁盘上,均衡磁盘上的 I/O 操作。
- 提高表的可管理性、可利用性和访问效率。
适用场景
| 软件 |
版本 |
| 操作系统 |
Redhat 7 及以上版本 |
| DM 数据库 |
DM 8.0 及以上版本 |
| CPU 架构 |
x86、ARM、龙芯、飞腾等国内外主流 CPU |
DM 支持的分区类型
创建分区表的限制
- DM 默认类型的表(索引组织表)创建分区表的时候,主键列必须在分区范围内。
- DM 的堆表上创建分区时,各个分区需要放在相同的表空间上。
如果表上存在聚集索引且索引键为主键,并希望各个分区放置在不同表空间上,优化 IO ,则必须在主键列中加入分区键,参考如下建表语句:
//创建表空间
CREATE TABLESPACE tbs_p1 DATAFILE '/dm/data/DM1_NEW/p1.dbf' SIZE 32;
CREATE TABLESPACE tbs_p2 DATAFILE '/dm/data/DM1_NEW/p2.dbf' SIZE 32;
CREATE TABLESPACE tbs_p3 DATAFILE '/dm/data/DM1_NEW/p3.dbf' SIZE 32;
CREATE TABLESPACE tbs_pmax DATAFILE '/dm/data/DM1_NEW/pmax.dbf' SIZE 32;
//创建分区表
CREATE TABLE dmhr.rp_emp
(
employee_id INT,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT pk_emp PRIMARY KEY (employee_id, hire_date),
CONSTRAINT emp_dept_fk1 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE (hire_date)
(PARTITION p1 VALUES LESS THAN ('2011-1-1') TABLESPACE tbs_p1,
PARTITION p2 VALUES LESS THAN ('2015-1-1') TABLESPACE tbs_p2,
PARTITION p3 VALUES LESS THAN ('2016-1-1') TABLESPACE tbs_p3,
PARTITION pmax VALUES LESS THAN (MAXVALUE) TABLESPACE tbs_pmax)
|
创建各类分区表
范围分区
按照指定列的值所在的范围来创建分区。例如:以员工的入职时间为分区键创建范围分区,以年为间隔。示例语句如下:
//创建范围分区,以 hire_date 为分区键,同时增加 MAXVALUE 分区。
CREATE TABLE dmhr.rp_hiredt_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk1 UNIQUE (email),
CONSTRAINT emp_dept_fk1 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE(hire_date)
(
PARTITION p1 VALUES LESS THAN ('2007-1-1'),
PARTITION p2 VALUES LESS THAN ('2008-1-1'),
PARTITION p3 VALUES LESS THAN ('2009-1-1'),
PARTITION p4 VALUES LESS THAN ('2010-1-1'),
PARTITION p5 VALUES LESS THAN ('2011-1-1'),
PARTITION p6 VALUES LESS THAN ('2012-1-1'),
PARTITION p7 VALUES LESS THAN ('2013-1-1'),
PARTITION p8 VALUES LESS THAN ('2014-1-1'),
PARTITION p9 VALUES LESS THAN ('2015-1-1'),
PARTITION p10 VALUES LESS THAN ('2016-1-1'),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORAGE (NOBRANCH
);
|
插入数据并提交,示例语句如下:
INSERT INTO dmhr.rp_hiredt_emp SELECT * FROM dmhr.employee;
COMMIT;
|
判断一张表是否为分区表,如果 partitioned 字段为 yes ,该表为分区表。示例语句如下:
SELECT partitioned FROM dba_tables WHERE table_name='RP_HIREDT_EMP';
|
查看表的分区状态,示例语句如下:
SELECT partitioning_type, partition_count, partitioning_key_count,
def_tablespace_name,status FROM dba_part_tables;
|
输出结果:

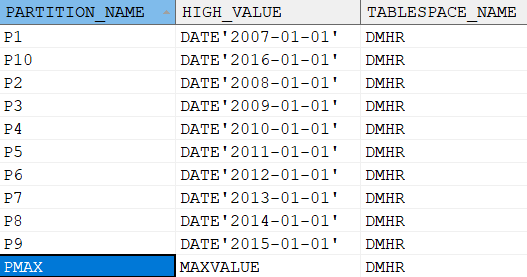
查看所有的表分区,示例语句如下:
SELECT partition_name, high_value, tablespace_name FROM dba_tab_partitions
WHERE table_name='RP_HIREDT_EMP';
|
输出结果:
列表分区
按照公司员工的职位 (job_id) 创建列表分区,示例语句如下:
CREATE TABLE dmhr.lp_job_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk2 UNIQUE (email),
CONSTRAINT emp_dept_fk2 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY LIST (job_id)
(PARTITION p1 VALUES ('11','12','21','22'),
PARTITION p2 VALUES ('31','32','41','42'),
PARTITION p3 VALUES ('51','52','61','62'),
PARTITION p4 VALUES ('71','72','81','82'),
PARTITION pmax VALUES (DEFAULT))
STORAGE (NOBRANCH);
|
插入数据并提交,示例语句如下:
INSERT INTO dmhr.lp_job_emp SELECT * FROM dmhr.employee;
COMMIT;
|
查询各分区的行数和累加行数,示例语句如下:
WITH p AS
(SELECT 'P1' AS pars, COUNT(*) AS num FROM dmhr.lp_job_emp PARTITION (P1)
UNION ALL
SELECT 'P2', COUNT(*) FROM dmhr.lp_job_emp PARTITION (P2)
UNION ALL
SELECT 'P3', COUNT(*) FROM dmhr.lp_job_emp PARTITION (P3)
UNION ALL
SELECT 'P4', COUNT(*) FROM dmhr.lp_job_emp PARTITION (P4))
SELECT pars, num, SUM(num) OVER(order by pars rows unbounded preceding)
row_sum FROM p;
|
输出结果:
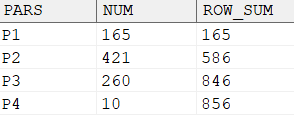
哈希分区
按照员工的 email 将员工信息数据 department 打散到 4 个分区中。示例语句如下:
CREATE TABLE dmhr.hp_email_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk3 UNIQUE (email),
CONSTRAINT emp_dept_fk3 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY HASH (email)
(PARTITION p1, PARTITION p2, PARTITION p3, PARTITION p4)
STORAGE (NOBRANCH);
|
插入数据并提交,示例语句如下:
INSERT INTO dmhr.hp_email_emp SELECT * FROM dmhr.employee;
COMMIT;
|
查询各分区的行数和累加行数,示例语句如下:
WITH p AS
(SELECT 'P1' AS pars, COUNT(*) AS num FROM dmhr.hp_email_emp PARTITION (P1)
UNION ALL
SELECT 'P2', COUNT(*) FROM dmhr.hp_email_emp PARTITION (P2)
UNION ALL
SELECT 'P3', COUNT(*) FROM dmhr.hp_email_emp PARTITION (P3)
UNION ALL
SELECT 'P4', COUNT(*) FROM dmhr.hp_email_emp PARTITION (P4))
SELECT pars, num, SUM(num) OVER(order by pars rows unbounded preceding)
row_sum FROM p;
|
输出结果:
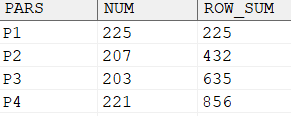
可以看出数据在哈希表的各个分区上分布比较均匀。
组合分区
组合分区是指范围分区、列表分区或哈希分区的两两组合,以下介绍其中一种组合分区 range-hash。
员工的雇佣时间为主分区键,从 2007 年起,每 3 年划分一个分区,每个分区包含 2 个 hash 子分区。示例语句如下:
CREATE TABLE dmhr.rhp_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk4 UNIQUE (email),
CONSTRAINT emp_dept_fk4 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE (hire_date)
SUBPARTITION BY HASH (email)
SUBPARTITION TEMPLATE (SUBPARTITION p1 , SUBPARTITION p2 )
(
PARTITION p1 VALUES LESS THAN ('2010-1-1'),
PARTITION p2 VALUES LESS THAN ('2013-1-1'),
PARTITION p3 VALUES LESS THAN ('2016-1-1'),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORAGE (NOBRANCH);
|
查询每个主分区下的子分区,示例语句如下:
SELECT partition_name,
subpartition_count,
composite,
high_value,
tablespace_name
FROM dba_tab_partitions
WHERE table_name = UPPER ('rhp_emp')
ORDER BY partition_position;
|
输出结果:

查询组合分区子分区的键信息,示例语句如下:
SELECT name,object_type,column_name,column_position FROM user_subpart_key_columns;
|

通过系统表 user_subpart_key_columns 查询组合分区子分区的键信息,必须以 dmhr 用户登录库。
间隔分区
间隔分区可以在输入相应分区的数据后自动创建分区,是范围分区的扩展。例如:将 dmhr 用户下 employee 表中员工信息按入职时间以年为间隔转换为分区表。
创建分区表 emp_part,起始分区时间为小于 2007 年 1 月 1 日。示例语句如下:
CREATE TABLE dmhr.emp_part
(
EMPLOYEE_ID INT PRIMARY KEY,
EMPLOYEE_NAME VARCHAR (20),
IDENTITY_CARD VARCHAR (18),
EMAIL VARCHAR (50) NOT NULL,
PHONE_NUM VARCHAR (20),
HIRE_DATE DATE NOT NULL,
JOB_ID VARCHAR (10) NOT NULL,
SALARY INT,
COMMISSION_PCT INT,
MANAGER_ID INT,
DEPARTMENT_ID INT
)
PARTITION BY RANGE (hire_date)
INTERVAL ( 「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」 【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。 |





