




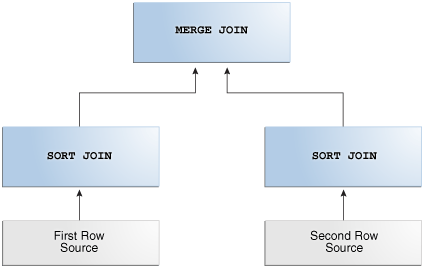
排序合并联接是嵌套循环联接的一种变体。
如果联接中的两个数据集尚未排序,则数据库将它们排序。这些是SORT JOIN操作。对于第一个数据集中的每一行,数据库将根据匹配的行探测第二个数据集并将其连接起来,并将其起始位置基于上一次迭代中进行的匹配。这就是MERGE JOIN操作。
- 当优化器考虑排序合并联接时 : 哈希联接需要一个哈希表和该表的一个探针,而排序合并联接则需要两种排序。
- 排序合并联接的工作方式 : 与嵌套循环联接一样,排序合并联接读取两个数据集,但是在尚未对它们进行排序时对其进行排序。对于第一数据集中的每一行,数据库在第二数据集中找到起始行,然后读取第二数据集,直到找到不匹配的行。
- 分类合并连接控制 :
USE_MERGE提示指示使用排序合并连接的优化。
9.2.3.1当优化器考虑排序合并联接时
哈希联接需要一个哈希表和该表的一个探针,而排序合并联接则需要两种排序。
当满足以下任一条件时,优化程序可以选择排序合并联接而不是哈希联接来联接大量数据:
- 联接两个表之间的条件不是等值连接,即,使用一个不等式条件如
<,<=,>,或>=。与排序合并相比,哈希联接需要一个相等条件。
- 由于其他操作需要排序,因此优化程序发现使用排序合并更便宜。
如果存在索引,则数据库可以避免对第一个数据集进行排序。但是,无论索引如何,数据库始终对第二个数据集进行排序。
与嵌套连接相比,排序合并具有与散列连接相同的优点:数据库访问PGA中的行而不是SGA中的行,从而避免了在数据库缓冲区高速缓存中重复锁存和读取块的需要,从而减少了逻辑I / O。通常,散列连接的性能优于排序合并连接,因为排序非常昂贵。但是,与哈希联接相比,排序合并联接具有以下优点:
- 初始排序后,将优化合并阶段,从而更快地生成输出行。
- 当哈希表不能完全放入内存中时,排序合并比哈希联接更具成本效益。
内存不足的哈希联接需要将哈希表和其他数据集都复制到磁盘。在这种情况下,数据库可能必须多次从磁盘读取。在排序合并中,如果内存无法容纳这两个数据集,则数据库会将这两个数据集都写入磁盘,但每个数据集最多读取一次。
9.2.3.2排序合并联接的工作方式
与嵌套循环联接中一样,排序合并联接读取两个数据集,但是在尚未对它们进行排序时对其进行排序。对于第一数据集中的每一行,数据库在第二数据集中找到起始行,然后读取第二数据集,直到找到不匹配的行。
在伪代码中,用于排序合并的高级算法可能如下所示:
READ data_set_1 SORT BY JOIN KEY TO temp_ds1
READ data_set_2 SORT BY JOIN KEY TO temp_ds2
READ ds1_row FROM temp_ds1
READ ds2_row FROM temp_ds2
WHILE NOT eof ON temp_ds1,temp_ds2
LOOP
IF ( temp_ds1.key = temp_ds2.key ) OUTPUT JOIN ds1_row,ds2_row
ELSIF ( temp_ds1.key <= temp_ds2.key ) READ ds1_row FROM temp_ds1
ELSIF ( temp_ds1.key => temp_ds2.key ) READ ds2_row FROM temp_ds2
END LOOP
例如,下表显示了两个数据集中的排序值:temp_ds1和temp_ds2。
表9-3排序的数据集
| temp_ds1 | temp_ds2 |
|---|---|
| 10 | 20 |
| 20 | 20 |
| 30 | 40 |
| 40 | 40 |
| 50 | 40 |
| 60 | 40 |
| 70 | 40 |
| 。 | 60 |
| 。 | 70 |
| 。 | 70 |
如下表所示,数据库首先读取10in temp_ds1,然后读取in中的第一个值temp_ds2。因为20in temp_ds2高于10in temp_ds1,所以数据库停止读取temp_ds2。
表9-4在temp_ds1中从10开始
| temp_ds1 | temp_ds2 | 行动 |
|---|---|---|
| 10 [从这里开始] | 20 [从这里开始] [从这里停止] | temp_ds2中的20高于temp_ds1中的10。停止。从temp_ds1中的下一行重新开始。 |
| 20 | 20 | |
| 30 | 40 | |
| 40 | 40 | |
| 50 | 40 | |
| 60 | 40 | |
| 70 | 40 | |
| 。 | 60 | |
| 。 | 70 | |
| 。 | 70 |
数据库前进到中的下一个值temp_ds1,即20。temp_ds2如下表所示,数据库继续进行。
表9-5在temp_ds1中从20开始
| temp_ds1 | temp_ds2 | 行动 |
|---|---|---|
| 10 | 20 [从这里开始] | 比赛。继续到temp_ds2中的下一个值。 |
| 20 [从这里开始] | 20 | 比赛。继续到temp_ds2中的下一个值。 |
| 30 | 40 [在这里停止] | temp_ds2中的40高于temp_ds1中的20。停止。从temp_ds1中的下一行重新开始。 |
| 40 | 40 | |
| 50 | 40 | |
| 60 | 40 | |
| 70 | 40 | |
| 。 | 60 | |
| 。 | 70 | |
| 。 | 70 |
数据库前进到下一行中temp_ds1,这是30。数据库从其上一个匹配项的编号开始,该编号为20,然后继续temp_ds2查找匹配项,如下表所示。
表9-6在temp_ds1中从30开始
| temp_ds1 | temp_ds2 | 行动 |
|---|---|---|
| 10 | 20 | |
| 20 | 20 [从最后一场比赛开始] | temp_ds2中的20低于temp_ds1中的30。继续到temp_ds2中的下一个值。 |
| 30 [从这里开始] | 40 [在这里停止] | temp_ds2中的40高于temp_ds1中的30。停止。从temp_ds1中的下一行重新开始。 |
| 40 | 40 | |
| 50 | 40 | |
| 60 | 40 | |
| 70 | 40 | |
| 。 | 60 | |
| 。 | 70 | |
| 。 | 70 |
数据库前进到下一行中temp_ds1,这是40。如下表所示,数据库temp_ds2从中最后一次匹配的编号开始,该编号为20,然后继续temp_ds2查找匹配项。
表9-7在temp_ds1中从40开始
| temp_ds1 | temp_ds2 | 行动 |
|---|---|---|
| 10 | 20 | |
| 20 | 20 [从最后一场比赛开始] | temp_ds2中的20低于temp_ds1中的40。继续到temp_ds2中的下一个值。 |
| 30 | 40 | 比赛。继续到temp_ds2中的下一个值。 |
| 40 [从这里开始] | 40 | 比赛。继续到temp_ds2中的下一个值。 |
| 50 | 40 | 比赛。继续到temp_ds2中的下一个值。 |
| 60 | 40 | 比赛。继续到temp_ds2中的下一个值。 |
| 70 | 40 | 比赛。继续到temp_ds2中的下一个值。 |
| 。 | 60 [在这里停止] | temp_ds2中的60高于temp_ds1中的40。停止。从temp_ds1中的下一行重新开始。 |
| 。 | 70 | |
| 。 | 70 |
数据库将以这种方式继续运行,直到与70in中的最终数据库匹配为止temp_ds2。这种情况表明,数据库在读取时temp_ds1不需要读取中的每一行temp_ds2。与嵌套循环连接相比,这是一个优势。
示例9-5使用索引排序合并联接
以下查询在该列上连接employees和departments表department_id,department_id并按以下顺序对行进行排序:
SELECT e.employee_id, e.last_name, e.first_name, e.department_id,
d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
的查询DBMS_XPLAN.DISPLAY_CURSOR显示该计划使用排序合并联接:
--------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes |Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0| SELECT STATEMENT | | | | 5(100)| |
| 1| MERGE JOIN | |106 | 4028 | 5 (20)| 00:00:01 |
| 2| TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
| 3| INDEX FULL SCAN | DEPT_ID_PK | 27 | | 1 (0)| 00:00:01 |
|*4| SORT JOIN | |107 | 2354 | 3 (34)| 00:00:01 |
| 5| TABLE ACCESS FULL | EMPLOYEES |107 | 2354 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
这两个数据集是departments表格和employees表格。因为索引是按departments表对表进行department_id排序的,所以数据库可以读取该索引并避免排序(第3步)。数据库只需要对employees表进行排序(第4步),这是最消耗CPU的操作。
示例9-6不带索引的排序合并联接
在列上连接employees和departments表department_id,department_id并按以下顺序对行进行排序。在此示例中,您指定NO_INDEX并USE_MERGE强制优化器选择排序合并:
SELECT /*+ USE_MERGE(d e) NO_INDEX(d) */ e.employee_id, e.last_name, e.first_name,
e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
的查询DBMS_XPLAN.DISPLAY_CURSOR显示该计划使用排序合并联接:
--------------------------------------------------------------------------------
| Id| Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
| 1 | MERGE JOIN | | 106 | 9540 | 6 (34)| 00:00:01|
| 2 | SORT JOIN | | 27 | 567 | 3 (34)| 00:00:01|
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 567 | 2 (0)| 00:00:01|
|*4 | SORT JOIN | | 107 | 7383 | 3 (34)| 00:00:01|
| 5 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7383 | 2 (0)| 00:00:01|
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
因为departments.department_id忽略了索引,所以优化程序执行排序,这使步骤2和步骤3的合并成本增加了67%(从3到5)。
9.2.3.3排序合并联接控件
该USE_MERGE提示指示优化器使用排序合并联接。
在某些情况下,用USE_MERGE提示覆盖优化器可能是有意义的。例如,优化器可以选择对表进行全面扫描,并避免查询中的排序操作。但是,由于通过索引和单个块读取来访问大表,而不是通过全表扫描来更快地访问,因此增加了成本。
