




此方案显示了如何使用示例架构生成高度平衡的直方图。
假设条件
此方案假定您要在sh.countries.country_subregion_id列上生成高度平衡的直方图。该表有23行。
以下查询显示该country_subregion_id列包含8个不均匀分布的值(包括示例输出):
SELECT country_subregion_id, count(*)
FROM sh.countries
GROUP BY country_subregion_id
ORDER BY 1;
COUNTRY_SUBREGION_ID COUNT(*)
-------------------- ----------
52792 1
52793 5
52794 2
52795 1
52796 1
52797 2
52798 2
52799 9
生成高度平衡的直方图:
- 收集
sh.countries和country_subregion_id列的统计信息,指定的存储桶少于不同的值。注意:
若要模拟创建基于高度的直方图所必需的Oracle Database 11g行为,请将
estimate_percent其设置为非默认值。如果指定非默认百分比,则数据库将创建频率或高度平衡的直方图。例如,输入以下命令:
BEGIN DBMS_STATS.GATHER_TABLE_STATS ( ownname => 'SH' , tabname => 'COUNTRIES' , method_opt => 'FOR COLUMNS COUNTRY_SUBREGION_ID SIZE 7' , estimate_percent => 100 --estimate_percent 不是DBMS_STATSAUTO_SAMPLE_SIZE); END; - 查询该
country_subregion_id列的直方图信息。例如,使用以下查询(包括示例输出):
SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HISTOGRAM FROM USER_TAB_COL_STATISTICS WHERE TABLE_NAME='COUNTRIES' AND COLUMN_NAME='COUNTRY_SUBREGION_ID'; TABLE_NAME COLUMN_NAME NUM_DISTINCT HISTOGRAM ---------- -------------------- ------------ --------------- COUNTRIES COUNTRY_SUBREGION_ID 8 HEIGHT BALANCED优化器选择一个高度平衡的直方图,因为不同值的数量(8)大于存储区的数量(7),并且该
estimate_percent值是非默认值。 - 查询每个不同值占用的行数。
例如,使用以下查询(包括示例输出):
SELECT COUNT(country_subregion_id) AS NUM_OF_ROWS, country_subregion_id FROM countries GROUP BY country_subregion_id ORDER BY 2; NUM_OF_ROWS COUNTRY_SUBREGION_ID ----------- -------------------- 1 52792 5 52793 2 52794 1 52795 1 52796 2 52797 2 52798 9 52799 - 查询该
country_subregion_id列的端点号和端点值。例如,使用以下查询(包括示例输出):
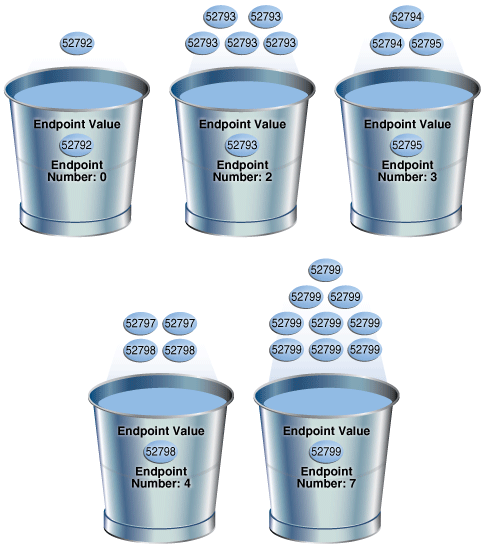
SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE FROM USER_HISTOGRAMS WHERE TABLE_NAME='COUNTRIES' AND COLUMN_NAME='COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 0 52792 2 52793 3 52795 4 52798 7 52799下图显示了高度平衡的直方图。这些值在图中以硬币表示。
图11-4高度直方图
桶号与端点号相同。优化器将每个存储桶中最后一行的值记录为端点值,然后进行检查以确保最小值是第一个存储桶的端点值,最大值是最后一个存储桶的端点值。在此示例中,优化器添加存储桶
0,以使最小值52792为存储桶的端点。优化程序必须将23行平均分配到7个指定的直方图存储桶中,因此每个存储桶大约包含3行。但是,优化器会压缩具有相同端点的存储桶。因此,优化程序将包含所有5个value实例的内容放入bucket中,而不是
1包含2个value实例的52793bucket和2包含3个value52793实例的52793bucket2。类似地,代替具有水桶5,6以及7包含每3个值,其中每个桶作为端点52799,优化看跌期权价值所有9个实例52799成桶7。在此示例中,bucket
3和4包含非流行值,因为当前端点号和先前端点号之间的差为1。优化器根据密度为这些值计算基数。其余的存储桶包含受欢迎的值。优化器根据端点号为这些值计算基数。
也可以看看:
- Oracle Database PL / SQL软件包和类型参考以了解该
DBMS_STATS.GATHER_TABLE_STATS过程 - Oracle数据库参考以了解
USER_TAB_COL_STATISTICS和USER_HISTOGRAMS视图
