




14.1.1关于列组的统计
各个列的统计信息对于确定WHERE子句中单个谓词的选择性很有用。
当WHERE子句在同一表的不同列上包含多个谓词时,单个列统计信息不会显示列之间的关系。这是列组解决的问题。
优化器独立计算谓词的选择性,然后将它们组合。但是,如果各个列之间存在相关性,那么优化器在确定基数估计时就不能考虑该相关性,基数估计是通过将每个表谓词的选择性乘以行数而创建的。
下图对比了在表的cust_state_province和country_id列上收集统计信息的两种方式sh.customers。该图显示了分别DBMS_STATS收集每个列和每个组的统计信息。列组具有系统生成的名称。
图14-1列组统计信息
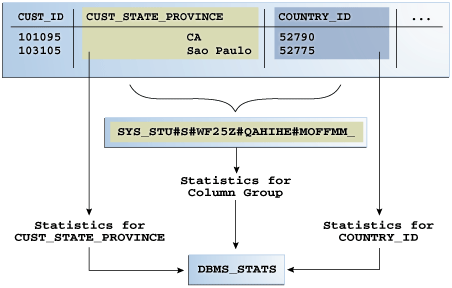
注意:
优化器将列组统计信息用于相等谓词,inlist谓词以及估计GROUP BY基数。
- 为什么需要列组统计信息:示例 此示例演示列组统计信息如何使优化器提供更准确的基数估计。
- 自动和手动列组统计信息 Oracle数据库可以自动或手动创建列组统计信息。
- 列组统计信息的用户界面 几个
DBMS_STATS程序单元具有与列组相关的首选项。
14.1.1.1为什么需要列组统计信息:示例
此示例说明了列组统计信息如何使优化器给出更准确的基数估计。
该DBA_TAB_COL_STATISTICS表的以下查询显示有关在列上cust_state_province和country_id从sh.customers表中收集的统计信息的信息:
COL COLUMN_NAME FORMAT a20
COL NDV FORMAT 999
SELECT COLUMN_NAME, NUM_DISTINCT AS "NDV", HISTOGRAM
FROM DBA_TAB_COL_STATISTICS
WHERE OWNER = 'SH'
AND TABLE_NAME = 'CUSTOMERS'
AND COLUMN_NAME IN ('CUST_STATE_PROVINCE', 'COUNTRY_ID');
示例输出如下:
COLUMN_NAME NDV HISTOGRAM
-------------------- ---------- ---------------
CUST_STATE_PROVINCE 145 FREQUENCY
COUNTRY_ID 19 FREQUENCY
如以下查询所示,有3341个客户居住在加利福尼亚州:
SELECT COUNT(*)
FROM sh.customers
WHERE cust_state_province = 'CA';
COUNT(*)
----------
3341
考虑一个针对该州CA和该ID为52790(USA)的国家/地区的客户进行查询的解释计划:
EXPLAIN PLAN FOR
SELECT *
FROM sh.customers
WHERE cust_state_province = 'CA'
AND country_id=52790;
Explained.
sys@PROD> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1683234692
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 128 | 24192 | 442 (7)| 00:00:06 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 128 | 24192 | 442 (7)| 00:00:06 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
1 - filter("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"=52790)
13 rows selected.
基于对单柱的统计数据country_id和cust_state_province列,优化程序估计加州客户在美国的查询将返回128行。实际上,有3341个客户居住在加利福尼亚州,但是优化器并不知道加利福尼亚州在美国所在的国家,因此假设两个谓词都减少了返回的行数,从而大大低估了基数。
您可以优化意识到值之间的现实世界的关系country_id,并cust_state_province通过收集列组统计信息。这些统计信息使优化器可以给出更准确的基数估计。
14.1.1.2自动和手动列组统计信息
Oracle数据库可以自动或手动创建列组统计信息。
优化器可以使用SQL计划指令来生成更优化的计划。如果DBMS_STATS首选项AUTO_STAT_EXTENSIONS设置为ON(默认值为OFF),则SQL plan指令可以根据工作负载中谓词的使用情况自动触发列组统计信息的创建。您可以设置AUTO_STAT_EXTENSIONS使用SET_TABLE_PREFS,SET_GLOBAL_PREFS或SET_SCHEMA_PREFS程序。
当您要手动管理列组统计信息时,请DBMS_STATS按以下方式使用:
- 检测列组
- 创建先前检测到的列组
- 手动创建列组并收集列组统计信息
也可以看看:
- “ 为特定工作负载检测有用的列组 ”
- “ 创建在工作负载监视期间检测到的列组 ”
- “ 手动创建和收集列组的统计信息 ”
- Oracle Database PL / SQL软件包和类型参考,以了解
DBMS_STATS设置优化程序统计信息的过程
14.1.1.3列组统计信息的用户界面
几个DBMS_STATS程序单元具有与列组相关的首选项。
表14-1与列组相关的DBMS_STATS API
| 计划单位或偏好 | 描述 |
|---|---|
SEED_COL_USAGE Procedure | 遍历指定工作负载中的SQL语句,进行编译,然后为出现在这些语句中的列播种列使用情况信息。 为了确定适当的列组,数据库必须遵守代表性的工作负载。在监视期间,您不需要自己运行查询。相反,您可以 |
REPORT_COL_USAGE Function | 生成一个报告,该报告列出 您可以使用此功能来查看为特定表记录的列使用情况信息。 |
CREATE_EXTENDED_STATS Function | 创建扩展名,扩展名可以是列组或表达式。当用户生成或自动统计信息收集作业收集表的统计信息时,数据库将收集扩展的统计信息。 |
AUTO_STAT_EXTENSIONS Preference | 收集优化程序统计信息时,控制扩展的自动创建,包括列组。使用此设置偏好SET_TABLE_PREFS,SET_SCHEMA_PREFS或SET_GLOBAL_PREFS。当 设置为时 |
也可以看看:
- “ 为表设置人工优化器统计信息 ”
- Oracle Database PL / SQL软件包和类型参考以了解该
DBMS_STATS软件包
