




一个索引范围扫描是值的有序扫描。
扫描中的范围可以是有界的,也可以是无界的。优化器通常为具有高选择性的查询选择范围扫描。
默认情况下,数据库以升序存储索引,并以相同顺序对其进行扫描。例如,与所述谓词的查询department_id >= 20使用范围扫描返回行排序由索引关键字20,30,40,等。如果多个索引条目具有相同的键,则数据库按rowid升序返回它们,因此0,AAAPvCAAFAAAAFaAAa后跟0,AAAPvCAAFAAAAFaAAg,依此类推。
一个索引范围扫描降是相同的索引范围扫描不同的是在降序数据库返回的行。通常,当按降序对数据进行排序时,或者当查找小于指定值的值时,数据库将使用降序扫描。
8.3.3.1当优化器考虑索引范围扫描时
对于索引范围扫描,索引键必须有多个值。
具体来说,优化器在以下情况下考虑索引范围扫描:
- 在条件中指定索引的一个或多个前导列。
条件指定一个或多个表达式和逻辑(布尔)运算符的组合,并返回的值
TRUE,FALSE或UNKNOWN。条件的示例包括:department_id = :iddepartment_id < :iddepartment_id > :idAND索引中前导列的上述条件的组合,例如department_id > :low AND department_id < :hi。注意:
为了使优化程序考虑范围扫描,表格的通配符搜索
col1 LIKE '%ASD'不得处于领先地位。
- 索引键可以是0、1或更多值。
小费:
如果需要排序的数据,请使用该ORDER BY子句,并且不要依赖索引。如果索引可以满足ORDER BY子句,则优化器使用此选项,从而避免排序。
当索引可以满足ORDER BY DESCENDING子句时,优化器认为索引范围扫描会下降。
如果优化器选择全表扫描或其他索引,则可能需要提示来强制执行此访问路径。在和提示指示使用特定的索引优化。 INDEX(tbl_alias ix_name)INDEX_DESC(tbl_alias ix_name)
也可以看看:
Oracle Database SQL语言参考以了解有关INDEX和INDEX_DESC提示的 更多信息
8.3.3.2索引范围扫描如何工作
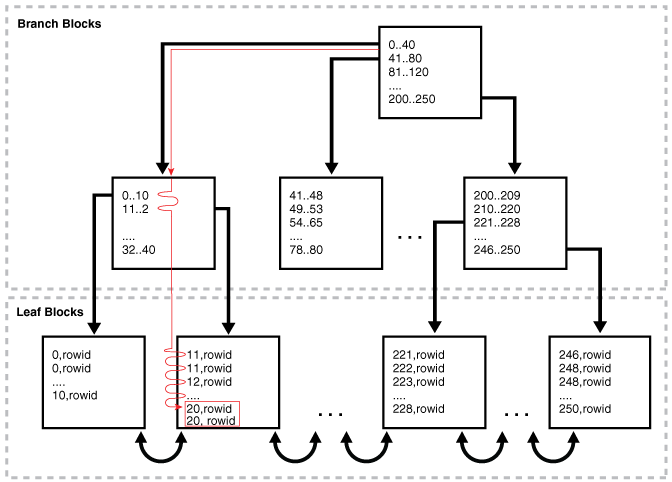
在索引范围扫描期间,Oracle数据库从根目录转到分支目录。
通常,扫描算法如下:
- 读取根块。
- 读取分支块。
- 交替执行以下步骤,直到检索到所有数据:
- 读取一个叶子块以获得一个rowid。
- 读取表块以检索行。
注意:
在某些情况下,索引扫描会读取一组索引块,对行标识进行排序,然后读取一组表块。
因此,要扫描索引,数据库将在各个叶块之间向后或向前移动。例如,对ID在20到40之间的扫描将找到第一个叶子块,该叶子块的最低键值为20或更大。扫描通过叶节点的链接列表进行水平扫描,直到找到大于40的值,然后停止。
下图说明了使用升序进行的索引范围扫描。一条语句请求在列中具有非唯一索引employees值的记录。在此示例中,存在2个部门索引条目。 20department_id20
图8-5索引范围扫描
8.3.3.3索引范围扫描:示例
本示例employees使用索引范围扫描从表中检索一组值。
以下语句查询部门20中薪水大于的员工的记录1000:
SELECT *
FROM employees
WHERE department_id = 20
AND salary > 1000;
前面的查询具有低基数(返回几行),因此该查询使用department_id列上的索引。数据库扫描索引,从employees表中获取记录,然后将salary > 1000过滤器应用于这些获取的记录以生成结果。
SQL_ID brt5abvbxw9tq, child number 0
-------------------------------------
SELECT * FROM employees WHERE department_id = 20 AND salary > 1000
Plan hash value: 2799965532
-------------------------------------------------------------------------------------------
|Id | Operation | Name |Rows|Bytes|Cost(%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
|*1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEES | 2 | 138 | 2 (0)|00:00:01|
|*2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX| 2 | | 1 (0)|00:00:01|
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SALARY">1000)
2 - access("DEPARTMENT_ID"=20)8.3.3.4索引范围扫描降序:示例
本示例使用索引以employees排序顺序从表中检索行。
以下语句20以降序查询部门中员工的记录:
SELECT *
FROM employees
WHERE department_id < 20
ORDER BY department_id DESC;
该先前查询的基数较低,因此该查询使用department_id列上的索引。
SQL_ID 8182ndfj1ttj6, child number 0
-------------------------------------
SELECT * FROM employees WHERE department_id < 20 ORDER BY department_id DESC
Plan hash value: 1681890450
--------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time |
--------------------------------------------------------------------------------
| 0| SELECT STATEMENT | | | | 2 (100)| |
| 1| TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 2|138| 2 (0)|00:00:01|
|*2| INDEX RANGE SCAN DESCENDING| EMP_DEPARTMENT_IX | 2| | 1 (0)|00:00:01|
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPARTMENT_ID"<20)数据库查找包含最大键值20或小于此值的第一个索引叶块。然后,扫描通过叶节点的链接列表向左水平进行。数据库从每个索引条目中获取行ID,然后检索该行ID指定的行。
