




在Oracle数据库中,自适应查询优化使优化器可以对执行计划进行运行时调整,并发现可以带来更好统计信息的其他信息。
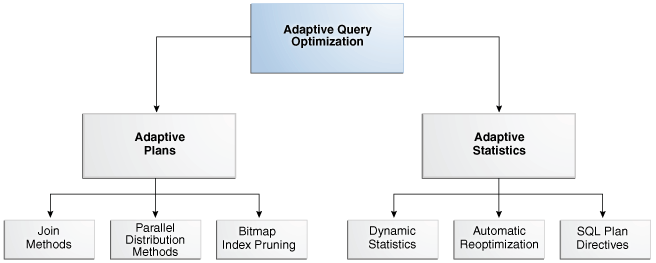
当现有统计信息不足以生成最佳计划时,自适应优化会很有帮助。下图显示了自适应查询优化的功能集。
图4-6自适应查询优化
4.4.1自适应查询计划
一种自适应的查询计划使优化,使执行过程中语句的计划作出决定。
自适应查询计划使优化器可以在运行时修复某些类型的问题。默认情况下会启用自适应计划。
4.4.1.1关于自适应查询计划
自适应查询计划包含多个预定子计划和一个优化器统计信息收集器。根据执行期间收集的统计信息,动态计划协调器会在运行时选择最佳计划。
动态计划
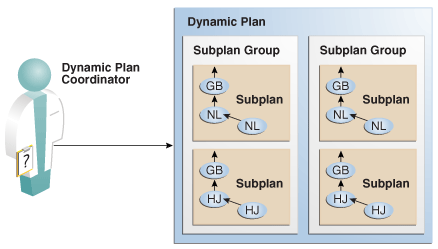
要在运行时更改计划,自适应查询计划使用动态计划,它表示为一组子计划组。甲子规划组是一组子规划。甲子规划是一项计划,优化器可以切换到如在运行时可替换的部分。例如,嵌套循环联接可以在执行期间切换为哈希联接。
优化器决定在运行时使用哪个子计划。当收到与子计划组相关的新统计值的通知时,协调器会将其分派给该子组的处理程序功能。
图4-7动态计划协调器
优化器统计收集器
一个优化统计收集器是关键点,与基数和直方图收集运行时间统计插入一个有计划的行来源。这些统计信息可帮助优化程序在多个子计划之间做出最终决定。收集器还支持高达内部阈值的可选缓冲。
对于并行缓冲统计信息收集器,每个并行执行服务器都会收集统计信息,并行查询协调器会汇总这些统计信息,然后将其发送给客户端。在这种情况下,客户是所收集统计信息(例如动态计划)的使用者。每个客户端都指定要在每个并行服务器或查询协调器上执行的回调函数。
4.4.1.2自适应查询计划的目的
优化程序基于执行期间获得的统计信息来适应计划的能力可以极大地提高查询性能。
自适应查询计划很有用,因为由于基数估计错误,优化器有时会选择次优的默认计划。优化程序根据实际执行统计信息在运行时选择最佳计划的能力可以使最终计划更为优化。选择最终计划后,优化器将其用于后续执行,从而确保不会重用次优计划。
4.4.1.3自适应查询计划如何工作
对于第一次执行语句,优化器使用默认计划,然后存储自适应计划。除非满足特定条件,否则数据库将使用自适应计划进行后续执行。
在第一次执行语句期间,数据库将执行以下步骤:
- 数据库开始使用默认计划执行该语句。
- 统计信息收集器收集有关正在进行的执行的信息,并缓冲子计划接收的一些行。
对于并行缓冲统计信息收集器,每个从属进程都收集统计信息,查询协调器将这些统计信息汇总后再发送给客户端。
- 根据收集器收集的统计信息,优化器选择一个子计划。
动态计划协调器决定在运行时为所有此类子计划组使用哪个子计划。当收到与子计划组相关的新统计值的通知时,协调器会将其分派给该子组的处理程序功能。
- 收集器停止收集统计信息并缓冲行,从而允许行通过。
- 数据库将自适应计划存储在子游标中,以便语句的下一次执行可以使用它。
在后续执行子游标时,除非满足以下条件之一,否则优化器将继续使用相同的自适应计划,在这种情况下,它将为当前执行选择一个新计划:
- 当前计划已超出共享池的期限。
- 不同的优化器功能(例如,自适应游标共享或统计信息反馈)会使当前计划无效。
4.4.1.3.1自适应查询计划:联接方法示例
此示例说明了优化器如何根据运行时收集的信息来选择其他计划。
以下查询显示order_items和prod_info表的联接。
SELECT product_name
FROM order_items o, prod_info p
WHERE o.unit_price = 15
AND quantity > 1
AND p.product_id = o.product_id此语句的自适应查询计划显示了两种可能的计划,一种具有嵌套循环联接,另一种具有哈希联接:
SELECT * FROM TABLE(DBMS_XPLAN.display_cursor(FORMAT => 'ADAPTIVE'));
SQL_ID 7hj8dwwy6gm7p, child number 0
-------------------------------------
SELECT product_name FROM order_items o, prod_info p WHERE
o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id
Plan hash value: 1553478007
-----------------------------------------------------------------------------
| Id | Operation | Name |Rows|Bytes|Cost (%CPU)|Time|
-----------------------------------------------------------------------------
| 0| SELECT STATEMENT | | | |7(100)| |
| * 1| HASH JOIN | |4| 128 | 7 (0)|00:00:01|
|- 2| NESTED LOOPS | |4| 128 | 7 (0)|00:00:01|
|- 3| NESTED LOOPS | |4| 128 | 7 (0)|00:00:01|
|- 4| STATISTICS COLLECTOR | | | | | |
| * 5| TABLE ACCESS FULL | ORDER_ITEMS |4| 48 | 3 (0)|00:00:01|
|-* 6| INDEX UNIQUE SCAN | PROD_INFO_PK |1| | 0 (0)| |
|- 7| TABLE ACCESS BY INDEX ROWID| PROD_INFO |1| 20 | 1 (0)|00:00:01|
| 8| TABLE ACCESS FULL | PROD_INFO |1| 20 | 1 (0)|00:00:01|
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
5 - filter(("O"."UNIT_PRICE"=15 AND "QUANTITY">1))
6 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
Note
-----
- this is an adaptive plan (rows marked '-' are inactive)
如果数据库可以避免扫描很大一部分,则嵌套循环联接是更可取的,因为数据库prod_info的行由联接谓词过滤。但是,如果只过滤了很少的行,则最好在散列连接中扫描正确的表。
下图显示了自适应过程。对于前面示例中的查询,默认计划的自适应部分包含两个子计划,每个子计划使用不同的联接方法。优化程序将根据连接左侧的基数自动确定每种连接方法何时最佳。
统计信息收集器将缓冲来自order_items表的足够多的行,以确定要使用的联接方法。如果行数低于优化器确定的阈值,则优化器将选择嵌套循环联接;否则,将选择嵌套循环联接。否则,优化器选择哈希联接。在这种情况下,来自order_items表的行计数高于阈值,因此优化器为最终计划选择哈希联接,并禁用缓冲。
图4-8自适应联接方法
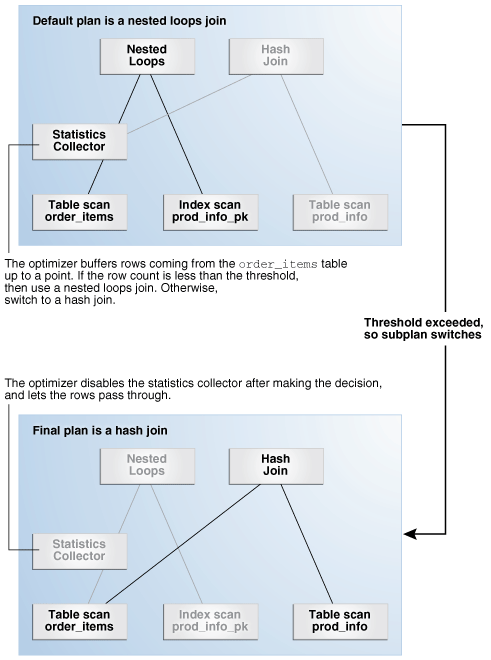
Note执行计划的该部分指示该计划是否为自适应的,以及计划中的哪些行为非活动状态。
也可以看看:
- “ 控制自适应优化 ”
- “ 显示自适应查询计划:教程 ”的扩展示例显示了自适应查询计划
4.4.1.3.2自适应查询计划:并行分配方法
通常,并行执行需要重新分配数据以执行诸如并行排序,聚合和联接之类的操作。
Oracle数据库可以使用许多不同的数据分发方法。数据库根据操作中要分配的行数和并行服务器进程数选择方法。
例如,考虑以下替代情况:
- 许多并行服务器进程分配的行很少。
数据库可以选择广播分发方法。在这种情况下,每个并行服务器进程都会接收结果集中的每一行。
- 很少有并行服务器进程分布许多行。
如果在数据重新分发期间遇到数据倾斜,则可能会对语句的性能产生不利影响。数据库更有可能选择散列分布,以确保每个并行服务器进程接收相等数量的行。
所述混合散列分配技术是不决定最终的数据分发方法,直到执行时间的自适应并行数据分配。优化器在操作的生产方将统计收集器插入并行服务器进程的前面。如果行数小于阈值(定义为并行度(DOP)的两倍),则数据分发方法从哈希切换为广播。否则,分发方法是哈希。
广播分配
下图描述了departments和employees表之间的混合哈希联接,其中一个查询协调器指导8个并行服务器进程:P5-P8是生产者,而P1-P4是使用者。每个生产者都有自己的消费者。
图4-9 DOP为4的自适应查询
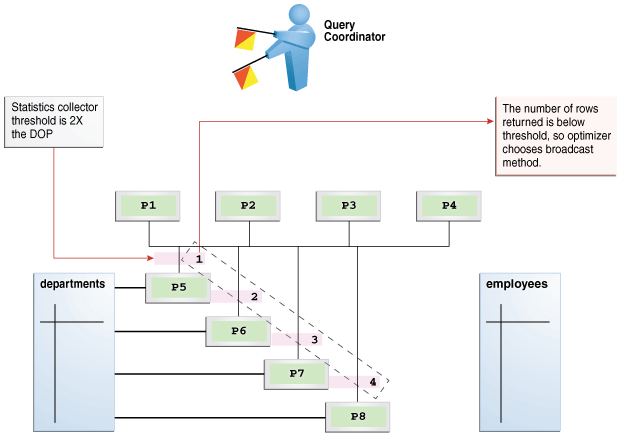
数据库在每个扫描departments表的生产者进程的前面插入一个统计信息收集器。查询协调器汇总收集的统计信息。分发方法基于运行时统计信息。在图4-9中,行数低于阈值(8),该阈值是DOP(4)的两倍,因此优化器为departments表选择一种广播技术。
混合哈希分配
考虑一个返回更多行的示例。在下面的计划中,阈值为8,是指定DOP 4的两倍。但是,由于统计信息收集器(步骤10)发现行数(27)大于阈值(8),因此优化程序选择了混合哈希分布而不是广播分布。(时间列应显示为00:00:01,但显示为0:01使计划适合该页面。)
i也可以看看:
Oracle Database VLDB和分区指南,以了解有关并行数据重新分配技术的更多信息
4.4.1.3.3自适应查询计划:位图索引修剪
自适应计划修剪索引不会显着减少匹配行的数量。
当优化器生成星形转换计划时,它必须选择正确的位图索引组合,以尽可能有效地减少相关的rowid集。如果存在许多索引,则某些索引可能不会显着减少rowid集,但在查询执行过程中仍会带来可观的处理成本。自适应计划可以通过不使用降低性能的索引来解决此问题。
示例4-2位图索引修剪
在此示例中,您发出以下星形查询,该查询将cars事实表与多个维度表(包括示例输出)连接在一起:
SELECT /*+ star_transformation(r) */ l.color_name, k.make_name,
h.filter_col, count(*)
FROM cars r, colors l, makes k, models d, hcc_tab h
WHERE r.make_id = k.make_id
AND r.color_id = l.color_id
AND r.model_id = d.model_id
AND r.high_card_col = h.high_card_col
AND d.model_name = 'RAV4'
AND k.make_name = 'Toyota'
AND l.color_name = 'Burgundy'
AND h.filter_col = 100
GROUP BY l.color_name, k.make_name, h.filter_col;
COLOR_NA MAKE_N FILTER_COL COUNT(*)
-------- ------ ---------- ----------
Burgundy Toyota 100 15000
下面的示例执行计划显示该查询在步骤12和步骤17中没有为位图节点生成任何行。自适应优化器确定使用CAR_MODEL_IDX和CAR_MAKE_IDX索引过滤行效率低下。该查询未使用计划中以破折号(-)开头的步骤。
-----------------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT GROUP BY NOSORT | |
| 2 | HASH JOIN | |
| 3 | VIEW | VW_ST_5497B905 |
| 4 | NESTED LOOPS | |
| 5 | BITMAP CONVERSION TO ROWIDS | |
| 6 | BITMAP AND | |
| 7 | BITMAP MERGE | |
| 8 | BITMAP KEY ITERATION | |
| 9 | TABLE ACCESS FULL | COLORS |
| 10 | BITMAP INDEX RANGE SCAN | CAR_COLOR_IDX |
|- 11 | STATISTICS COLLECTOR | |
|- 12 | BITMAP MERGE | |
|- 13 | BITMAP KEY ITERATION | |
|- 14 | TABLE ACCESS FULL | MODELS |
|- 15 | BITMAP INDEX RANGE SCAN | CAR_MODEL_IDX |
|- 16 | STATISTICS COLLECTOR | |
|- 17 | BITMAP MERGE | |
|- 18 | BITMAP KEY ITERATION | |
|- 19 | TABLE ACCESS FULL | MAKES |
|- 20 | BITMAP INDEX RANGE SCAN | CAR_MAKE_IDX |
| 21 | TABLE ACCESS BY USER ROWID | CARS |
| 22 | MERGE JOIN CARTESIAN | |
| 23 | MERGE JOIN CARTESIAN | |
| 24 | MERGE JOIN CARTESIAN | |
| 25 | TABLE ACCESS FULL | MAKES |
| 26 | BUFFER SORT | |
| 27 | TABLE ACCESS FULL | MODELS |
| 28 | BUFFER SORT | |
| 29 | TABLE ACCESS FULL | COLORS |
| 30 | BUFFER SORT | |
| 31 | TABLE ACCESS FULL | HCC_TAB |
-----------------------------------------------------------
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
- star transformation used for this statement
- this is an adaptive plan (rows marked '-' are inactive)
4.4.1.4启用自适应查询 参数
默认情况下会启用自适应查询计划。
设置以下初始化参数后,将启用自适应计划:
OPTIMIZER_ADAPTIVE_PLANS是TRUE(默认)OPTIMIZER_FEATURES_ENABLE是12.1.0.1或以后OPTIMIZER_ADAPTIVE_REPORTING_ONLY是FALSE(默认)
自适应计划控制以下优化:
- 嵌套循环和哈希联接选择
- 星型转换位图修剪
- 自适应并行分配方法
也可以看看:
- “ 控制自适应优化 ”
- Oracle数据库参考以了解更多信息
OPTIMIZER_ADAPTIVE_PLANS
