启用增量统计信息维护后,仅DBMS_STATS收集统计信息并为更改的分区创建概要。数据库还自动将分区级别的概要合并为全局概要,并从分区级别的统计信息和全局概要中导出全局统计信息。
通过从分区级别的统计信息派生一些全局统计信息,数据库在计算全局统计信息时避免了全表扫描。例如,全局级别的行数是分区的行数之和。甚至全局直方图也可以从分区直方图导出。
但是,数据库无法从分区级统计信息(包括列的NDV)中得出所有统计信息。以下示例显示了表中两个分区的NDV:
表13-3两个分区的NDV
| 宾语 | 列值 | NDV |
|---|---|---|
| 分区1 | 1,3,3,4,5 | 4 |
| 分区2 | 2,3,4,5,6 | 5 |
通过将各个分区的NDV相加来计算表中的NDV,将得出NDV为9,这是不正确的。因此,需要一种更准确的技术:提要。
- 分区级别提要 : 是特殊类型的统计量的该轨道的不同值(NDV),用于在分区中的每个列中的数字。您可以将提要视为对不同值进行采样的内部管理结构。
- NDV算法:自适应采样和HyperLogLog : 从Oracle Database 12c第2版(12.2)开始,HyperLogLog算法可以提高NDV(不同值的数量)计算性能,还可以减少概要所需的存储空间。
- 使用提要聚合全局统计信息:在本示例中,数据库收集
sales表的最初六个分区的统计信息,然后为每个分区(S1,S2等等)创建提要。该数据库通过汇总分区级别的统计信息和概要来创建全局统计信息。
13.3.8.2.1分区级概要
概要是跟踪不同值(NDV)的数目用于在分区中的每个列特殊类型的统计量。您可以将提要视为对不同值进行采样的内部管理结构。
通过合并分区级别的提要,数据库可以为每个列准确地导出全局级别的NDV。在表13-3所示的示例中,数据库可以使用摘要将列的NDV计算为6。
每个分区都以增量模式维护一个大纲。将新分区添加到表后,您只需要收集新分区的统计信息。数据库通过将新的分区概要与现有分区的概要聚合在一起,自动更新全局统计信息。随后的统计信息收集操作比不使用概要时要快。
数据库存储数据的提纲字典表WRI$_OPTSTAT_SYNOPSIS_HEAD$,并WRI$_OPTSTAT_SYNOPSIS$在SYSAUX表空间中。该DBA_PART_COL_STATISTICS字典视图包含分区列统计信息。如果该NOTES列包含关键字INCREMENTAL,则此列具有概要。
也可以看看:
Oracle数据库参考以了解更多信息DBA_PART_COL_STATISTICS
13.3.8.2.2 NDV算法:自适应采样和HyperLogLog
从Oracle Database 12c第2版(12.2)开始,HyperLogLog算法可以提高NDV(不同值的数量)计算性能,并且还可以减少摘要所需的存储空间。
用于计算NDV的传统算法使用自适应采样。概要是不同值的样本。在计算NDV时,数据库最初将每个不同的值存储在哈希表中。每个不同的值都占用一个不同的哈希桶,因此具有5000个不同值的列具有5000个哈希桶。然后,数据库将哈希存储桶的数量减半,然后继续将结果减半,直到剩下少量存储桶。该算法是“自适应的”,因为采样率根据哈希表拆分的数量而变化。
为了计算该列的NDV,数据库使用以下公式,其中B是在执行所有拆分后剩余的哈希桶数,而S是拆分数:
NDV = B * 2^S自适应采样会产生准确的NDV统计数据,但会带来以下后果:
- 概要占用大量磁盘空间,尤其是当表具有许多列和分区并且每列的NDV高时。
例如,一个60列的表可能具有300,000个分区,平均每个列的NDV为5,000。在此示例中,每个分区都有300,000个条目(60 x 5000)。概要表总共有900亿个条目(300,000平方),至少占用720 GB的存储空间。
- 概要的批量处理可能会对性能产生负面影响。
在数据库重新收集陈旧分区的统计信息之前,它必须删除关联的概要。批量删除的速度可能很慢,因为它会生成大量的撤消和重做数据。
与动态采样相反,HyperLogLog算法使用随机技术。尽管该算法很复杂,但基本的见识是,在随机值流中,n个不同的值平均间隔为1 / n。因此,如果您知道流中的最小值,则可以粗略估计不同值的数量。例如,如果值的范围是0到1,并且观察到的最小值是0.2,则这些数字平均平均间隔为.2,因此NDV估算值为5。
HyperLogLog算法扩展并校正了原始估计。数据库将哈希函数应用于每个列值,从而产生一组与列具有相同基数的哈希值。对于基本估计,NDV等于2 n,其中n是在哈希值的二进制表示形式中观察到的尾随零的最大数量。数据库通过使用部分输出来将值拆分为不同的哈希桶,从而完善了其NDV估算值。
与自适应采样相比,HyperLogLog算法的优势在于:
- 新算法的准确性与原始算法相似。
- 所需的内存明显较低,这通常会导致摘要大小大大减少。
当存在许多分区时,摘要可能会变得很大,并且它们的NDV值很高。使用HyperLogLog算法的概要更加紧凑。创建和删除概要会影响批处理运行时间。任何管理分区的操作过程都会减少运行时间。
该DBMS_STATS首选项APPROXIMATE_NDV_ALGORITHM确定数据库用于NDV计算的算法。
也可以看看:
《 Oracle Database PL / SQL软件包和类型参考》以了解APPROXIMATE_NDV_ALGORITHM首选项
13.3.8.2.3使用概要汇总全局统计信息:示例
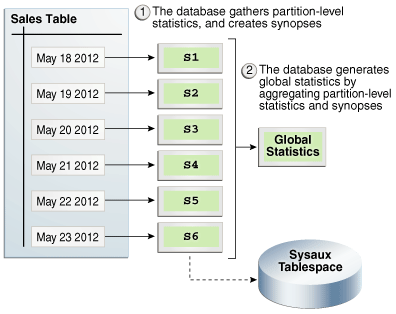
在此示例中,数据库收集sales表的最初六个分区的统计信息,然后为每个分区(S1,S2等)创建概要。该数据库通过汇总分区级别的统计信息和概要来创建全局统计信息。
图13-2汇总统计
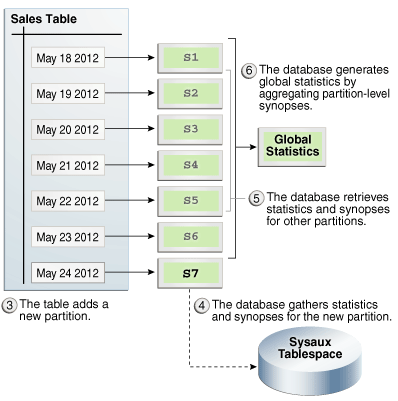
下图显示了一个新分区,其中包含5月24日的数据,该分区已添加到sales表中。数据库收集新添加的分区的统计信息,检索其他分区的概要,然后汇总概要以创建全局统计信息。
图13-3添加分区后汇总统计信息