




1 编写目的
GBase 8a V95版本的集群一致性服务gcware与V86版本比有很大改变,基础协议从虚同步协议改为Raft协议,集群的高可用性得到了更大的提升。
不同现场部署时,不可避免的由于服务器、网络等环境差异导致的一些部署上的问题,通过这篇文章对常见的问题及排查方法进行总结,方便客户现场更快速的定位问题。
2 适合对象
重点面向技术支持、测试人员。
3 现象描述、原因分析及解决办法
3.1 执行gcadmin卡住
3.1.1 现象描述
执行gcadmin,长时间不返回,如下图所示。

3.1.2 原因分析
3.1.2.1 检查各个coor节点(V952)或者gcware(V953)节点的gcware服务是否启动
通过ps -ef|grep gcware查看gcware服务是否启动,下图信息表示gcware服务未启动

解决办法:
V952版本:gcluster_services all start
V953版本:gcware_services all start
下图表示gcware服务正常启动

3.1.2.2 检查防火墙是否关闭
查看各个coor节点的gcware.log,发现一直在刷下面的日志,“vote req from”表示在不停的发起选举,2160502976表示本节点的nodeid,且nodeid一直是同一个,即每个节点的gcware服务只能收到自己的投票信息,出现这种情况,表示系统的防火墙未关闭。
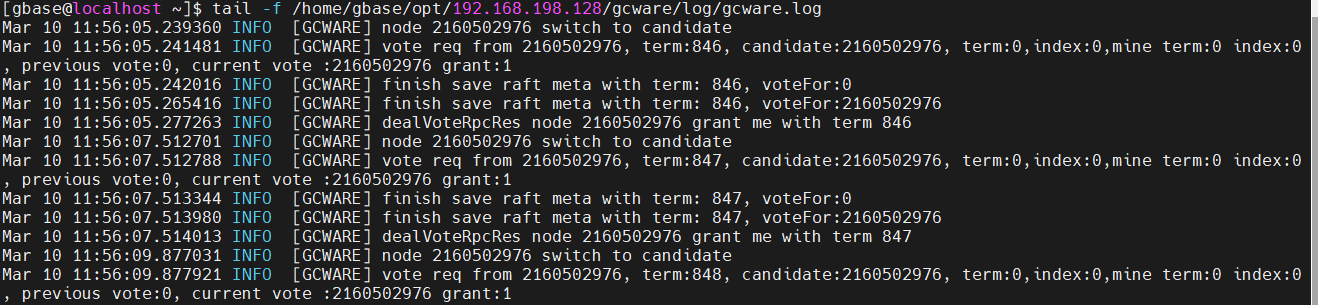
解决办法:
(1)客户现场如果允许关闭防火墙,则通过系统命令关闭防火墙解决。
(2)客户端现场如果不允许关闭防火墙,则需要设置防火墙规则,允许5918和5919端口的tcp和udp消息正常通信,其中5918端口用于不同节点gcware服务之间通信,比如leader选举、数据同步、心跳消息,5919端口用于gcluster服务访问gcware服务。
3.1.2.3 一个gcware节点被同时添加到多个集群中
通过cat $GCWARE_BASE/config/gcware.conf命令查看配置文件中member包含的成员ip
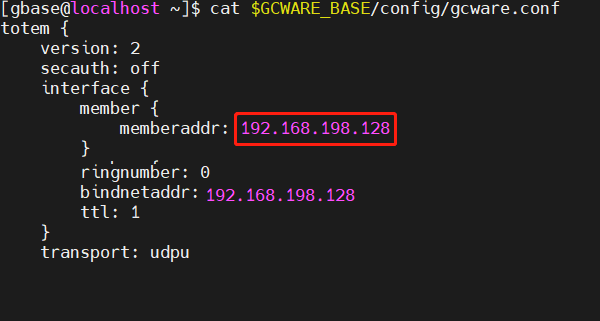
在其中一个节点上通过tcpdump -i eth0 port 5918命令抓包,查看是否存在不属于member列表中ip的消息,如下图所示,收到了不属于member列表的消息。

解决办法:
停止集群服务,修改$GCWARE_BASE/config/gcware.conf配置文件,确保一个gcware节点只被加到一个集群中,之后重启集群服务即可。
3.1.2.4 集群中feventlog数量达到几十万,引起gcware分裂
查看gcware.log,可以正常收到其他节点gcware服务发送的消息,选出leader后,过一会又分裂,执行gcadmin命令,一会能正常返回,一会又卡住。
执行gcadmin showddlevent、gcadmin showdmlevent和gcadmin showdmlstorageevent查看集群中是否包含几十万条feventlog。
解决办法:
(1)部分feventlog不重要,可以通过gcadmin rmfeventlog ip命令删除
(2)集群部署了多个coordinator节点时,先执行gcmonit.sh stop命令将各个coordinator节点的监控服务停掉,然后执行gcluster_services gcrecover stop命令,只剩下一个或几个coordinator节点上的gcrecover服务,具体剩下几个,根据不再引起gcware分裂为止。
(3)以上2点还解决不了问题,需反馈给南大通用技术支持或者拨打电话:400-013-9696,寻求技术解决。
3.2 gcadmin显示其中一个gcware服务的状态为CLOSE
3.2.1 现象描述
查看gcware服务的进程号在不停的变,如下图所示:

查看gcware.log,看到“raft node init fail”关键字。
3.2.2 原因分析
gcluster访问gcware写入的信息,比如scn、tableid、lock、failover和feventlog等信息先写入REDOLOG,达到10万条或者REDOLOG文件大小达到512MB时,会将REDOLOG中的信息刷到SNAPSHOT中,当服务器异常断电时,可能会存在REDOLOG文件损坏的情况,这时会导致gcware服务无法正常启动。
3.2.3 解决办法
3.2.3.1 集群中部署了多个gcware服务节点
可以通过从leader节点拷贝gcware持久化目录的方式恢复,详细说明如下:
(1)在各个gcware节点执行grep -E "switch to leader" $GCWARE_BASE/log/gcware.log命令,“switch to leader with term:”关键字后,数据大的节点为leader节点,如下图所示,看到term最大的是1004,表示nodeid为2328275136的节点为leader节点。


(2)停止REDOLOG文件损坏节点的gcware服务,并将$GCWARE_BASE/data/gcware目录mv走,之后将leader节点的整个$GCWARE_BASE/data/gcware目录拷贝到REDOLOG文件损坏的节点上,最后启动REDOLOG文件损坏节点的gcware服务即可。


3.2.3.2 集群中只部署了一个gcware服务节点
由于只有一个gcware节点,没有高可用,所以出现REDOLOG文件损坏时,无法通过从其他好的节点拷贝持久化文件的方式来恢复,只能通过删除最后一个损坏的REDOLOG文件的方式恢复,可能会丢失一些信息,比如feventlog或者failover导致集群服务恢复正常后,数据不一致,恢复方法如下。
(1)停止集群所有服务。
(2)执行ll $GCWARE_BASE/data/gcware/命令,找到该目录下REDOLOG后面编号最大的那个,这里最大的是REDOLOG.79。
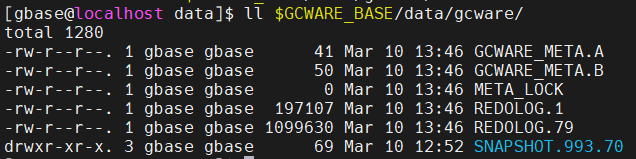
(3)删除REDOLOG编号最大的文件。
(4)通过gcluster_services gcware start(V952) 或gcware_services gcware start(V953)命令,只启动gcware服务。
(5)待gcadmin正常返回后,通过gcware的python接口将scn和tableid初始化为更大的值,避免由于REDOLOG文件中记录了之前申请过的scn或tableid,导致新建的表与原有的表tableid或scn重复,命令如下。
[gbase@localhost data]$ python
Python 2.7.5 (default, Apr 2 2020, 13:16:51)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import gcware
>>> gcware.getscn() 获取当前scn
100000
>>> gcware.gettableid() 获取当前tableid
200000
>>> gcware.initscn(300000) scn重置为更大的值
0
>>> gcware.inittableid(500000) tableid重置为更大的值
0
>>> gcware.getscn() 验证scn是否重置成功
300000
>>> gcware.gettableid() 验证tableid是否重置成功
500000
>>> exit()

(6)启动集群其他服务,gcluster_services all start(V952)或 gcware_services all start gcluster_services all start(V953)
3.2.3.3 少数派gcware节点REDOLOG文件损坏自动恢复
少数派节点REDOLOG文件损坏自动恢复功能,经了解,目前还没有实现该功能,正在开发中,届时只有少数派节点REDOLOG文件损坏将不需要人工介入,系统可以自动恢复正常。
