




引言
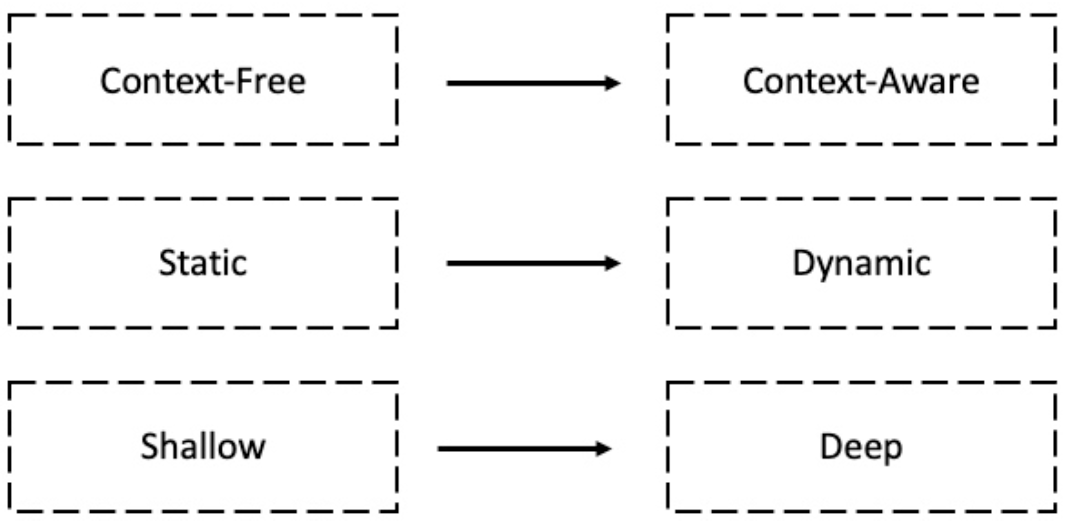
预训练语言模型简述
预训练语言模型的其实可以追溯到静态词向量的研究。从最初的One-Hot向量、词袋模型、tf-idf到后来的Word2Vec[1]、FastText[2,3]等方法,研究者通过建模token的统计概率信息,或者上下文的统计概率信息来对语言进行统计学建模。
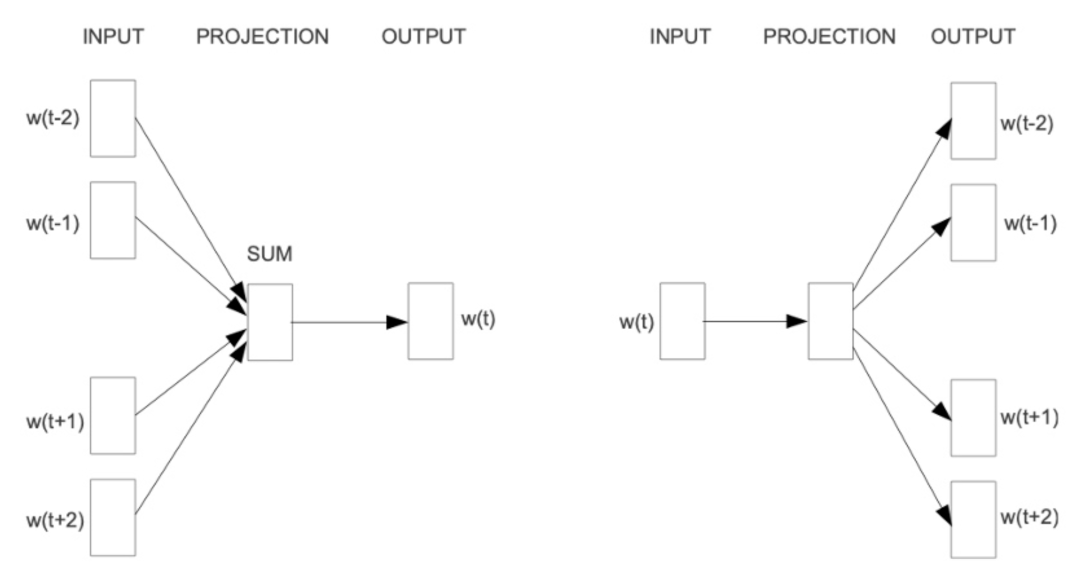
例如,上图为word2vec提出的两种经典方法CBOW与Skip-gram,它们分别通过“使用周围的词来预测中心词”以及“使用中心词来预测周围的词”这两种方法,使用滑动窗口的方法对窗口大小长度的序列进行上下文建模,最终在训练过程中通过梯度下降的方法优化句子中每个词的词嵌入(embedding)。相比于最初的One-Hot向量表示、词袋模型、tf-idf等传统统计学方法,word2vec等静态词向量方法能够更好地考虑到词的上下文语义信息,同时可以减少传统方法遇到的维度灾难问题。但是,这种静态的词嵌入表示方法也有不少的缺点,最典型的问题是词与词嵌入是一对一的表示,无法正确表示在不同上下文中出现的一词多义信息,即便到了后来研究者提出了一些效果更好的模型(Glove[4])也没能解决这种静态词向量的固有问题。
为了解决上述静态词嵌入表示的问题,研究者提出了基于语言模型嵌入(Embedding from LanguageModels, ELMo)的方法[5],使用长短时记忆神经网络(LSTM)分别对文本的正向和反向进行语言模型建模:
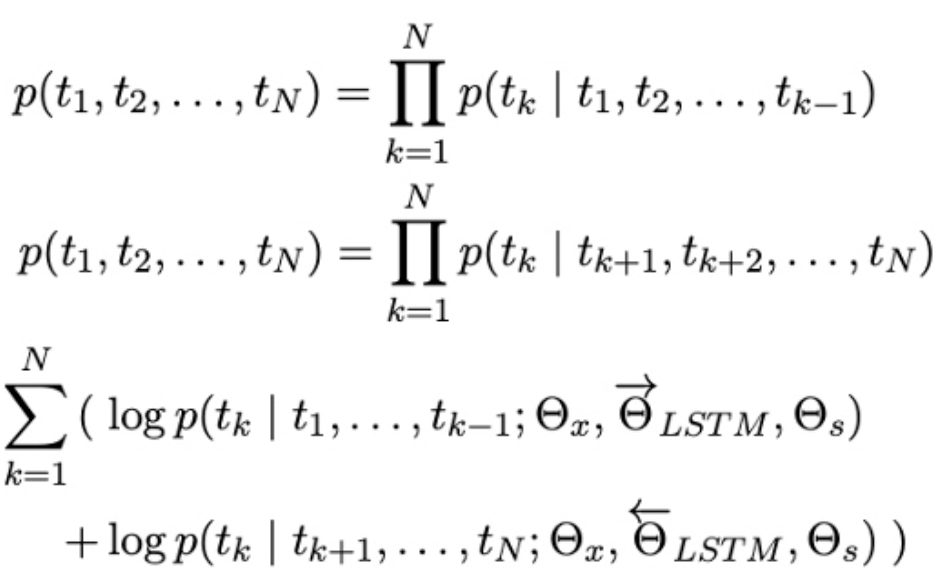
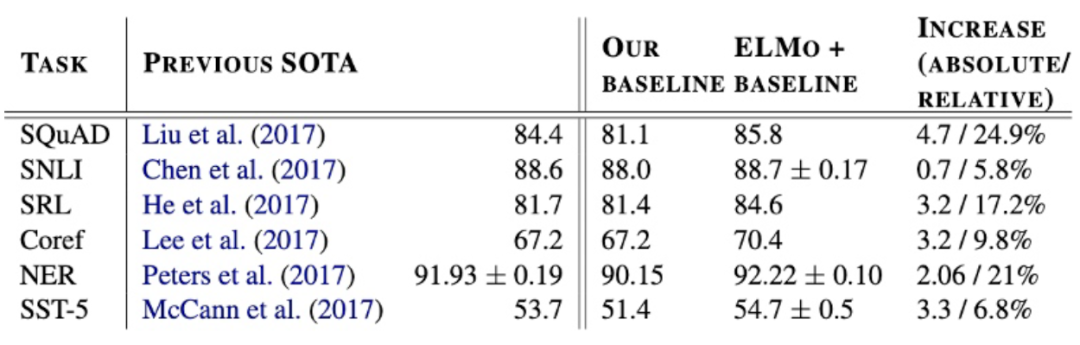
通过语言模型任务进行预训练后,迁移到其它NLP任务中进行微调,在多个benchmark数据集上都得到了显著的提升:
同时,作者也通过实验对ELMo的消岐能力进行了分析,发现ELMo能够有效地区分多义词。自此以ELMo为代表的各种预训练语言模型开始不断出现,并不断提升各个NLP子任务的效果。
2017年Google提出了用于机器翻译任务的Transformer[6],Transformer基于多头自注意力机制实现,解决了之前LSTM类型模型无法很好处理长距依赖的问题并且更易于进行并行运算,在预训练语言模型领域也展现出了强大的能力,之后的预训练语言模型代表作BERT[7]、GPT[8]均是基于Transformer模型构建的。
Google于2018提出的BERT是预训练语言模型的经典之作。BERT由多层Transformer Encoder模块堆叠构成,作者为其设置了两种预训练任务:Masked Language Model(MLM)与Next Sentence Prediction(NSP),采用两阶段预训练-微调范式,如下图所示:
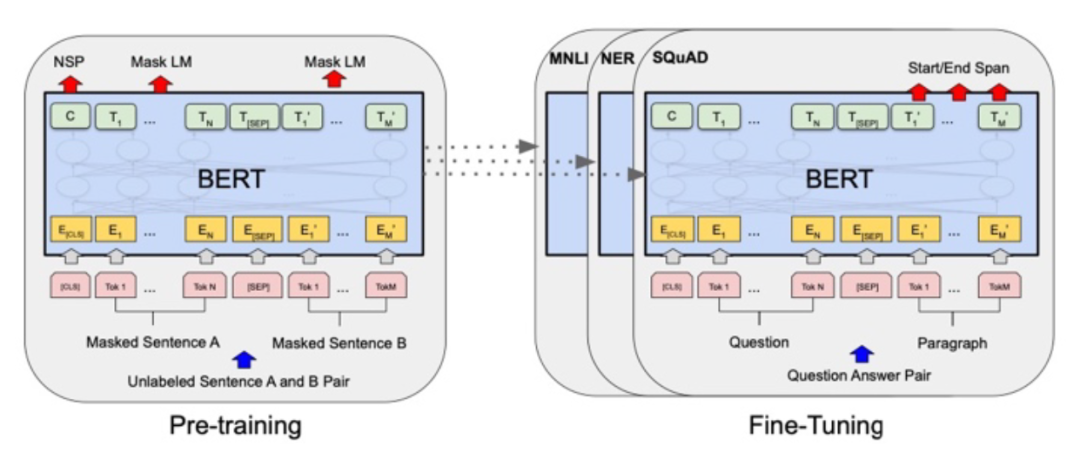
其中,MLM来自于完形填空任务(Cloze),将一句完整的话中间的某些token抹去,让模型通过上下文来还原该token;NSP为句子对匹配任务,将两个句子拼接后传入模型中,让模型判断这两个句子是否在原语料中为连续关系。得益于这两个预训练任务,BERT在token层面与sentence层面都能通过大规模的无标注语料进行自监督训练,从而获得优秀的预训练模型参数,在迁移至下游NLP任务微调时,可以取得非常好的效果。
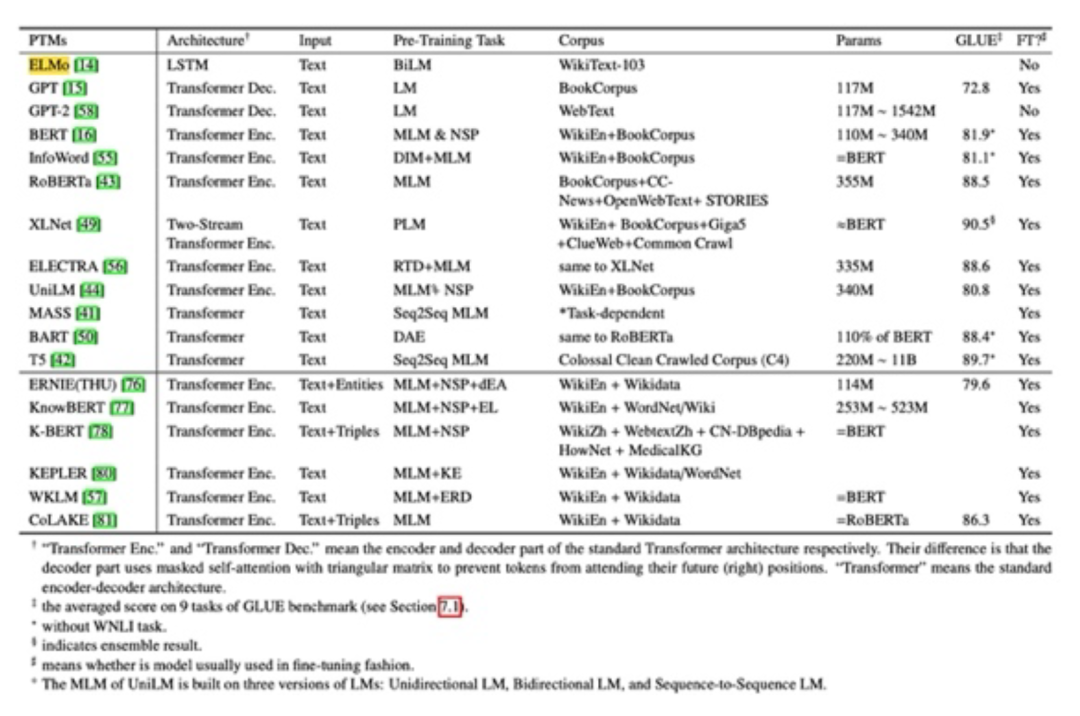
在BERT的基础上,研究者们对预训练语言模型的可能性进行了进一步的探索:有使用更大的预训练数据集的、有定义更合理的预训练任务的、以及还有各种尝试引入外部知识强化预训练语言模型的(如K-BERT[9]、thu-ERNIE[10]等)、还有引入特定语种的语言特性的(如baidu-ERNIE[11]、BERTwwm[12]等)、以及最近出现的通过提示(prompt)指导预训练语言模型从而提升效果减少训练数据的工作。邱锡鹏老师等对预训练语言模型进行了详尽的综述[13],下表展示了部分典型的预训练语言模型的模型架构、预训练任务、语料、参数量等信息:
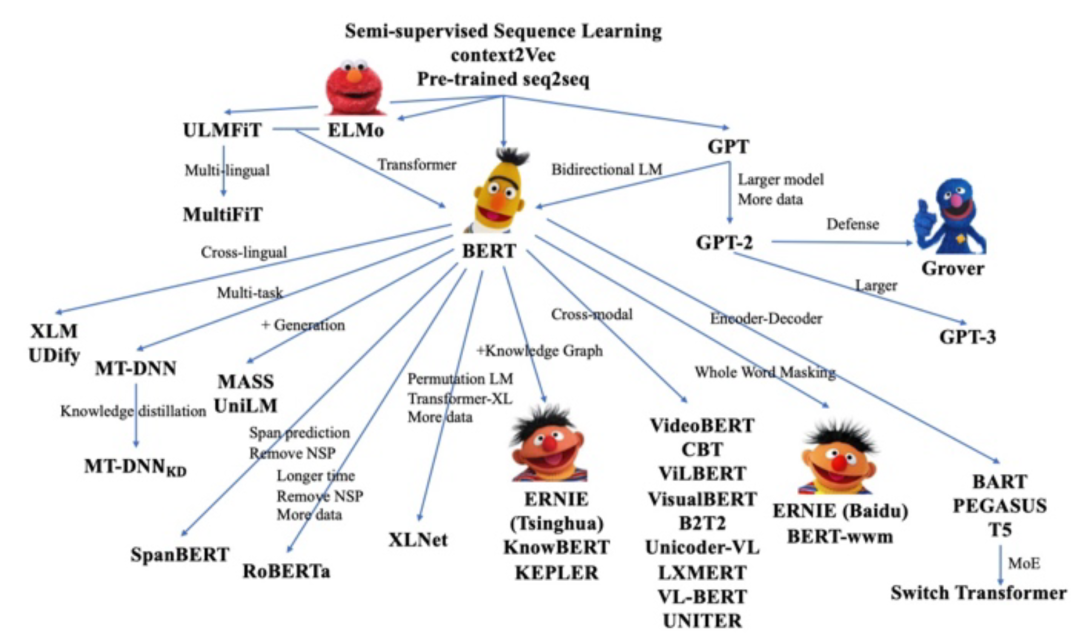
THUNLP实验室也对预训练模型的过去、现在及将来进行了总结与展望[14],下图展示了部分典型预训练语言模型的“族谱”:
在预训练语言模型的训练过程中,模型通过自监督学习任务在非常大规模的语料库上进行了训练,除了学习到了语言模型之外,是否也能通过学习捕获到一定的规律,从而掌握文本中所蕴涵的事实类知识呢?如果预训练语言模型能掌握一些知识,应该如何从模型中把需要的知识查询出来呢?研究者们对此进行了探索性的研究。
LanguageModels as Knowledge Bases?
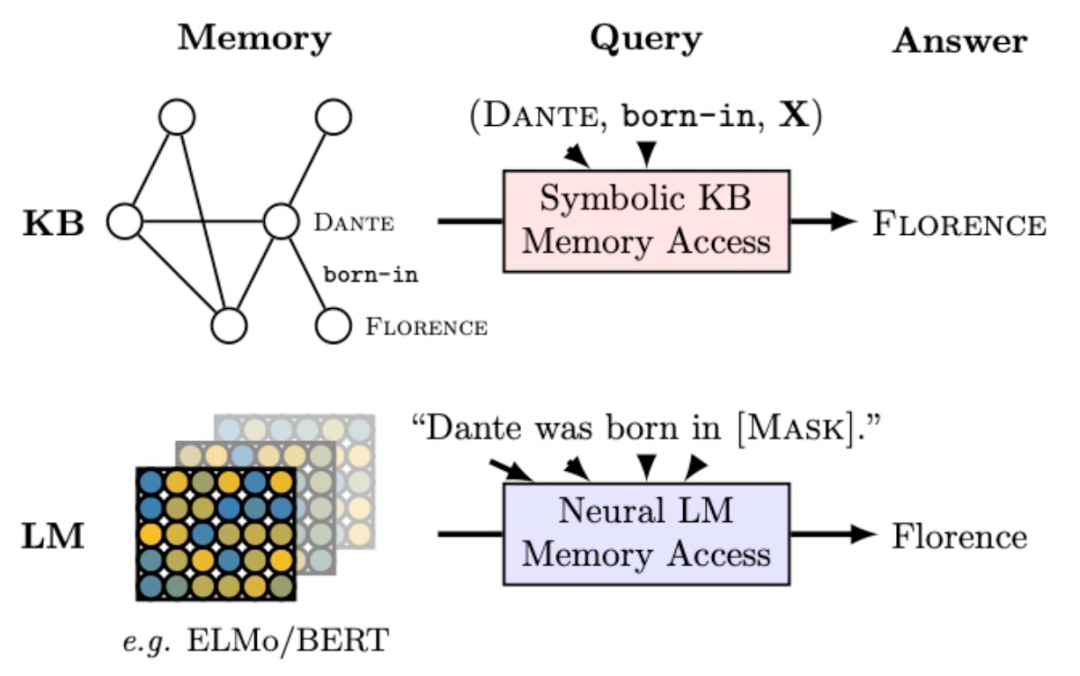
作者将设定的探针测试命名为LAMA(LAnguage Model Analysis)Probe,用来检测语言模型中包含了多少的事实类与常识类的知识。作者收集了GoogleRE等知识源,通过构造模板将知识三元组构造成模型能接收的完形填空的形式。例如,GoogleRE中包含“place of birth”关系的数据,作者定义了“[S] was born in [O]”这样的模板用于填充。同理,对于常识类的知识,作者也定义了类似的模板,设定包含常识类三元组的数据将宾语mask掉,例如对于“CapableOf”(有...能力)的常识类数据,作者构造为“[S] can [O]”。下表展示了部分作者构造的数据形式:

通过上述的操作,并对数据进行筛选(排除掉不符合MLM范式的多token类型的数据等)后整合得到了最终的LAMA探针测试数据集。
为了评估预训练语言模型在LAMA上的效果,作者设定了几个baseline用于对比:
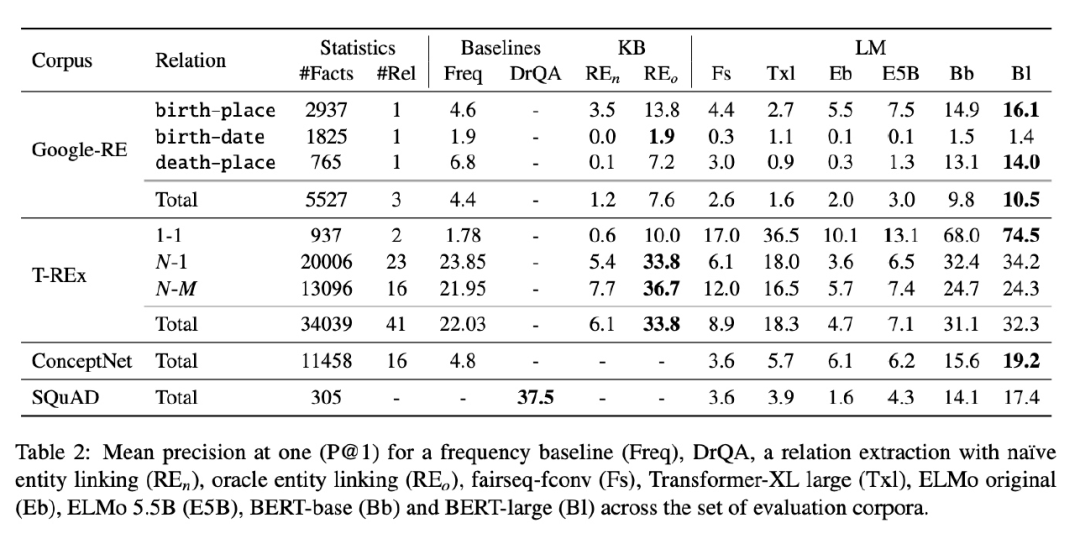
此工作主要是探索性质的,作者也没有对于预训练语言模型在预训练阶段捕获知识的能力进行详尽的测试(可以通过在LAMA数据集上预训练或continuous learning实现),而是着重探究了已经训练好的预训练语言模型中包含的事实类或常识类知识,并且从文章结构上看作者更加偏向于如何构造和分析LAMA这样的探针测试。从结果上看,虽然指标并不高,但可以说明预训练语言模型是有一定从大规模语料中提炼这些知识的能力的。但此文的限制也相当多,例如需要人工精心构建的模板、提前将不合适的类型或数据筛去等。
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
此工作[16]由Google提出,发表于EMNLP 2020。此文使用了Google自家的T5预训练语言模型[17]作为基础模型。T5模型将所有NLP任务都归结转化为了text-to-text的任务,包括相似度等任务也是以seq2seq的方式生成的结果。而传统的MLM任务在T5中以类似Span Boundary Detection的形式存在,如下图所示:
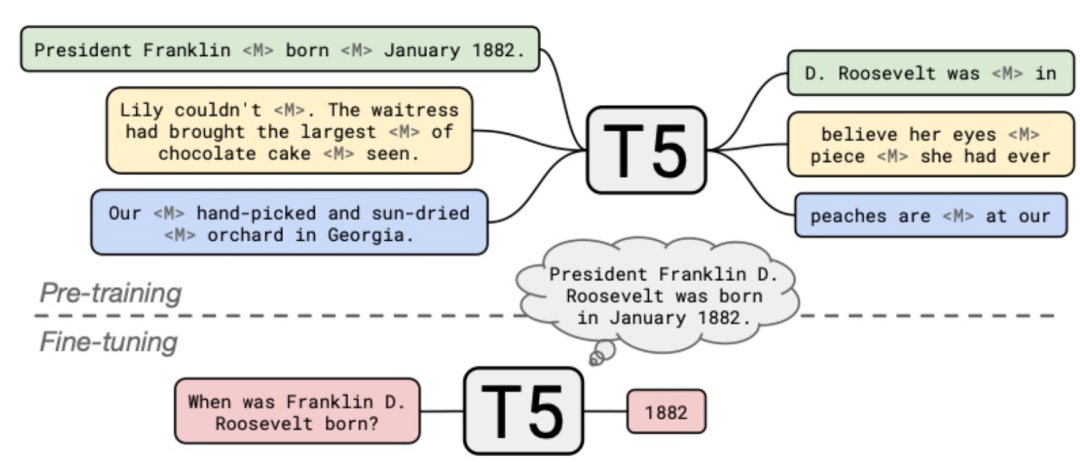
在一般的问答任务中,通常会提供一个问题与一段包含问题答案的文档,通过模型在文档中找到问题的答案。而此工作基于T5 text-to-text的范式,以“闭卷”(closed-book)的形式在没有对应答案的上下文的情况下直接向模型输入问题以获取对应的答案。这样的问题设定可以说是在考验预训练语言模型在fine-tune的过程中能学到什么,以及考验模型能存储住多少知识。
实验
此文直接使用了QA任务中常用的几个数据集:NQ、WebQuestion和TriviaQA。在这几个数据上,作者使用T5模型进行text-to-text的微调,将问题做为输入并将字面量答案作为预测目标。进行fine-tune后,在测试集上进行评估,得到结果如下表所示:
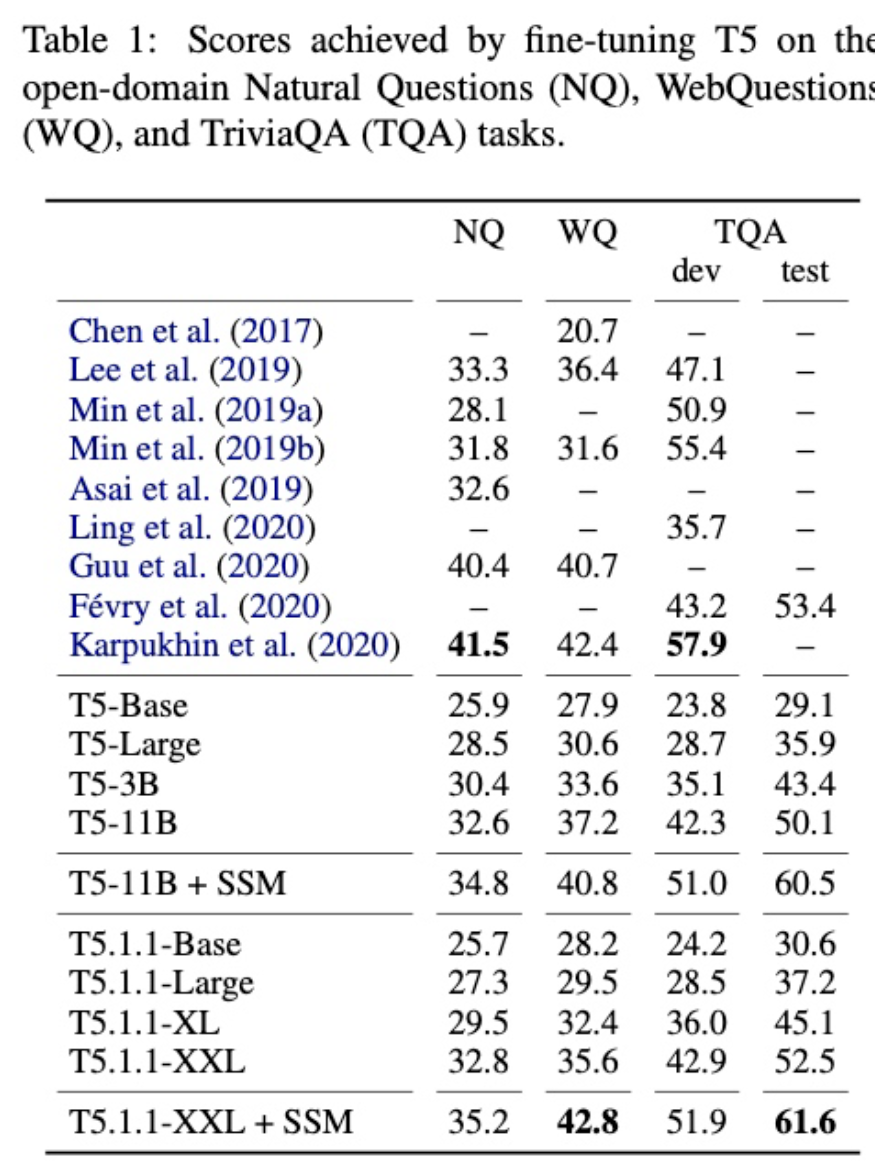
可以看到,T5通过此方法在“闭卷”问答中可以得到和“开卷”问答模型相当的结果,这说明通过fine-tune是可以将“知识”输入预训练语言模型并存储的。
小结
oLMpics- On what Language Model Pre-training Captures
此文[18]通过设定多种探针任务,针对“预训练语言模型究竟能捕获到什么信息”这一设问进行了验证。作者为了验证不同的预训练语言模型在不同的“知识”形式、不同“知识推理”上下文情况下的能力,提出了如下几个任务:

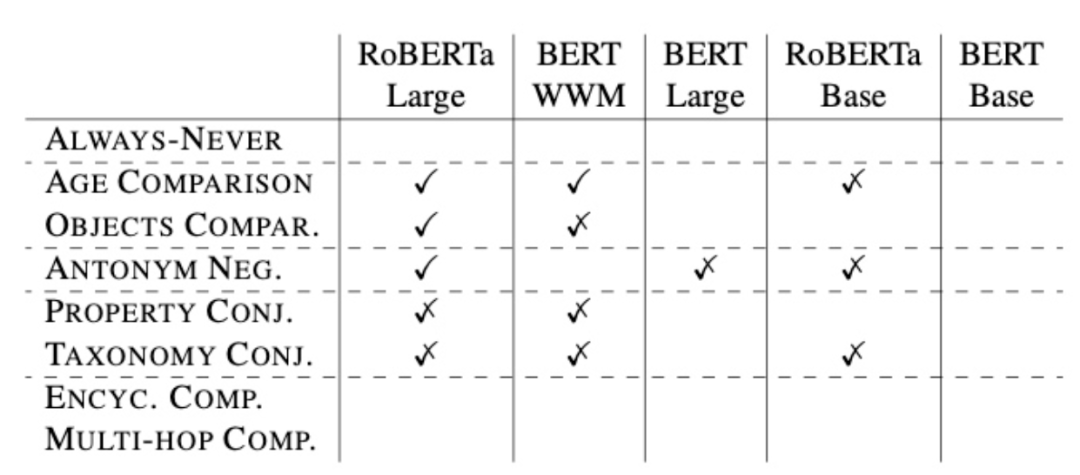
从结果上看,预训练语言模型是可以在部分上述设定的任务中取得一定效果的。较为突出的是RoBERTa Large模型,体现出了较强的能力。但是,在Always-Never任务、百科类推理任务和多跳推理任务中,没有任何一个模型能得到有效的效果。总体上看,在作者的任务设定下,预训练语言模型在知识推理中得到的结果差强人意,其效果与模型和任务组织形式有着明显的相关性。也许在更大规模的预训练语言模型,或更符合预训练语言模型的推理任务设定下,可以让效果更加明显。
Knowledgeableor Educated Guess? Revisiting Language Models as Knowledge Bases
此文[19]是软件所韩先培老师组发表在ACL 2021的工作。作者对设定的“将预训练语言模型作为知识库使用”这一前提进行了探索性实验,主要围绕着prompt范式下从预训练语言模型中获取知识的性能与效果来源进行了实验与分析。
作者根据现有工作,将通过提示语从预训练语言模型中获取知识的方式分为了三大类:
实验
如上文所述,作者针对不同的提示语构建方式分别定义了几组实验。
1. 基于提示语的知识抽取
作者使用LAMA与WIKI-UNI两个分布不同的数据集,使用相同的提示语通过MLM进行知识获取,如下图所示:
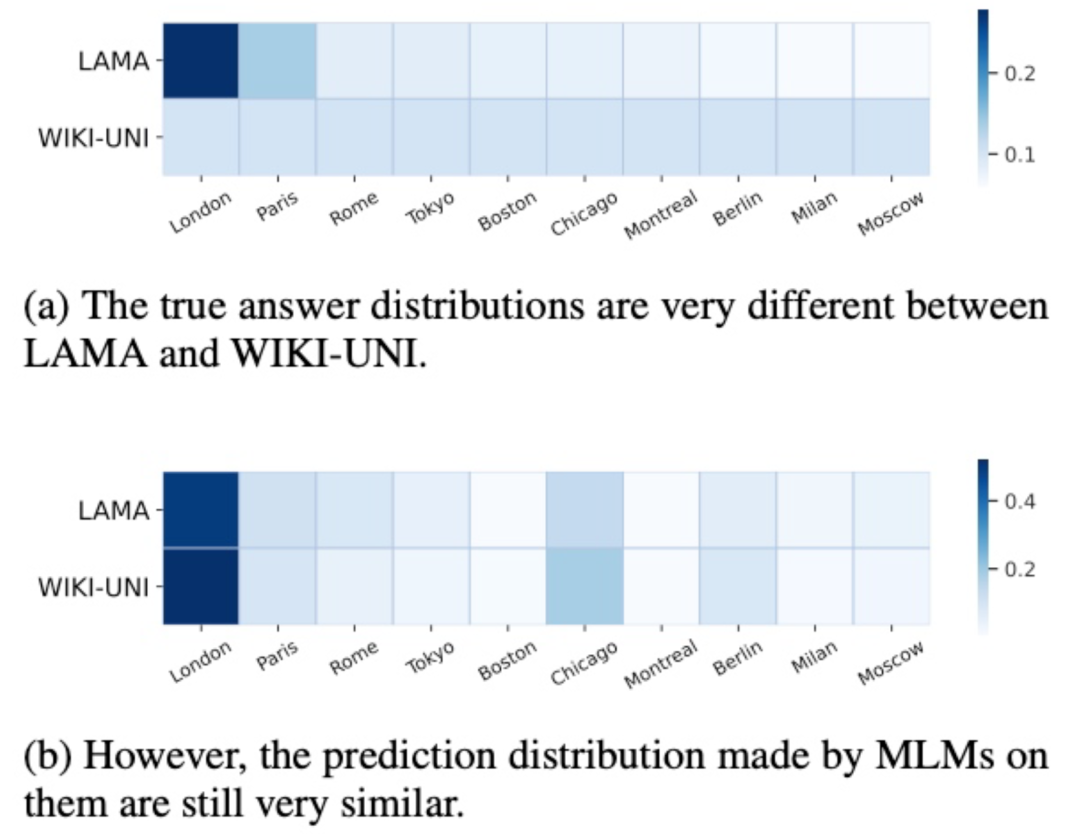
2. 基于示例的类比知识抽取
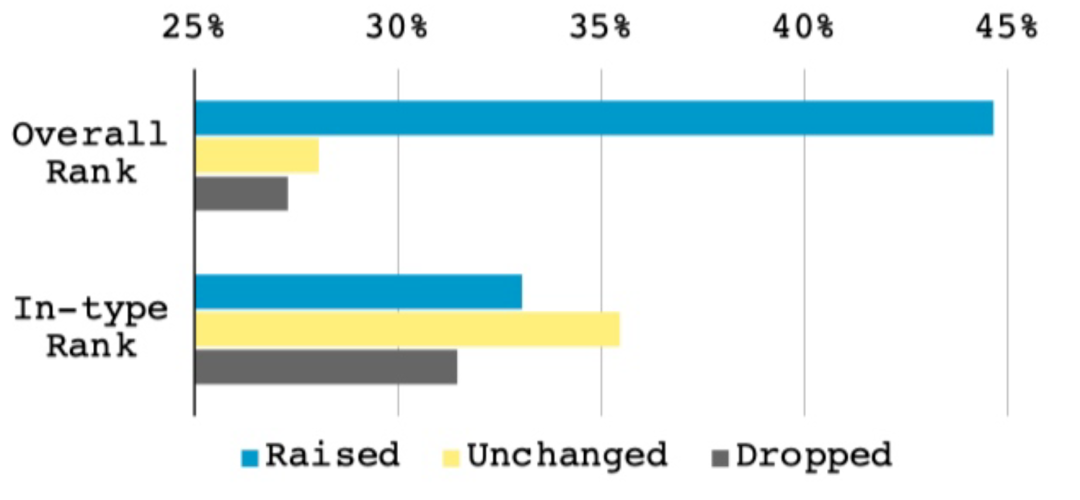
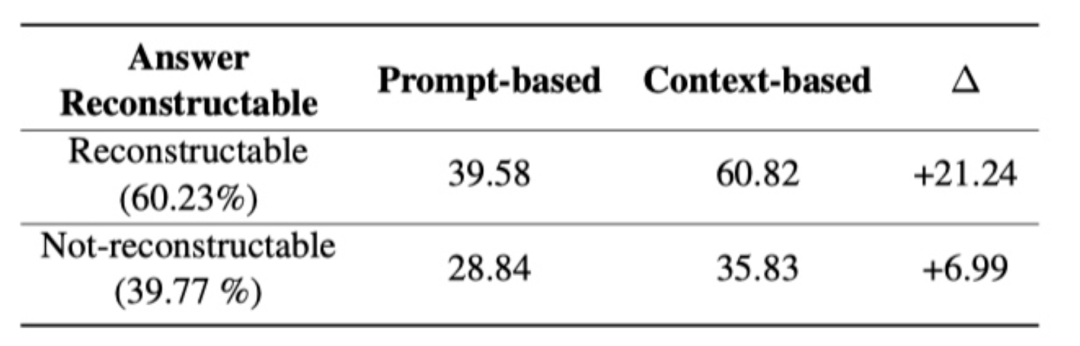
3. 基于上下文的知识抽取


小结
作者通过探索性实验发现,与预训练语言模型知识获取准确性相关的主要因素是提示语的构建,包括提示语偏差、类别指导和答案泄露几种非预期的行为导致了预训练语言模型作为知识库的性能提升,因此在目前的情况下,还不能claim“预训练语言模型可以替代知识库”这一结论。
总结
在本文介绍的这几篇论文中,可以发现现在研究者们仍然是将预训练语言模型作为黑盒进行研究的,主要通过构建不同的探针任务来经验性的判定预训练语言模型学习知识、获取知识的手段与效果。如果后续能对预训练语言模型的机制进行更具体的探讨,以及对fine-tune或prompt等获取知识的方法进行更精细的建模,可能会得到更加可信、更加无偏的结果,这样才能进一步研究或探讨将预训练语言模型代替知识库的可能性。
[1] Efficient Estimation ofWord Representations in Vector Space, ICLR 2013
[2] Bag of Tricks for Efficient Text Classification, EACL 2017
[3] Enriching Word Vectors with Subword Information, TACL 2017
[4] GloVe: Global Vectors for Word Representation, EMNLP 2014
[5] Deep Contextualized Word Representations, NAACL 2018
[6] Attention Is All You Need, NIPS 2017
[7] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,NAACL 2019
[8] Improving Language Understanding by Generative Pre-Training, 2018
[9] K-BERT: Enabling Language Representation with Knowledge Graph, AAAI 2020
[10] ERNIE: Enhanced Language Representation with Informative Entities, ACL2019
[11] Ernie: Enhanced representation through knowledge integration, 2019
[12] Pre-Training with Whole Word Masking for Chinese BERT, 2019
[13] Pre-trained Models for Natural Language Processing: A Survey, ScienceChina Technological Sciences 2020
[14] Pre-Trained Models: Past, Present and Future, 2021
[15] Language Models as Knowledge Bases?, EMNLP 2019
[16] How Much Knowledge Can You Pack Into the Parameters of a Language Model?,EMNLP 2020
[17] Exploring the Limits of Transfer Learning with a Unified Text-to-TextTransformer, JMLR 2020
[18] oLMpics - On what Language Model Pre-training Captures, ACL 2020
[19] Knowledgeable or Educated Guess? Revisiting Language Models as KnowledgeBases, ACL 2021
更多链接


