




不废话,直接上干货
增
(1)CREATE 新增节点或关系
// 新增节点// 注意,同一次执行时,别名可以跨语句使用CREATE (pp:Person {name: 'pp'})CREATE (yx:Person {name: 'yx'})CREATE (xy:Person {name: 'xy'})CREATE (xx:Person {name: 'xx'})CREATE (cc:Person {name: 'cc'})CREATE (lyon:Person {name: 'lyon'})CREATE (jason:Person {name: 'jason'})// 新增关系// 注意,新增关系时,节点需要打括号,否则报错CREATE (jason)-[:FRIEND]->(lyon)-[:FRIEND]->(pp)CREATE (yx)-[:FRIEND]->(xy)-[:FRIEND]->(xx)-[:FRIEND]->(cc)// 新增路径CREATE p =(mars:person { name:'mars',title:'AIleader' })-[:WORKS_AT{level:12}]->(kp:company{name:'kp',addr:'dl'})<-[:WORKS_AT]-(keven:leader { name: 'keven' ,title:'CEO'})
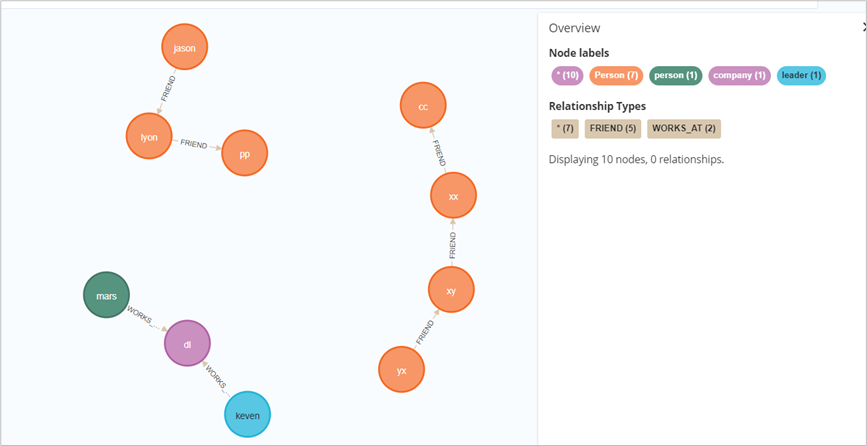
(2)MERGE (匹配或)新增节点或关系
若新node属性完全一致,则不会新增node;
若任意属性的key或者value不同,则新增node;
新node属性不全但kv一致时,则不会新增node;
另外,在未创建节点时,MERGE具有查找的功能。
// 属性key名与现有完全一致,但是title的value不一致,因此会新增节点merge (n:person { name: 'mars',title:'data leader'})// 缺了title属性,但是name属性的key和value与现有node一致,故不会新增merge (n:leader { name: 'keven'})// 新增关系和新增节点使用方式一致match (jason:Person {name:'jason'}),(pp:Person {name:'pp'})merge (jason)-[r:FRIEND {name:"new"}]->(pp)// 可以同时新增节点、关系merge (cc2:Person {name:'cc2'})-[r2:FRIEND2]->(xx2:Person {name:'xx2'})

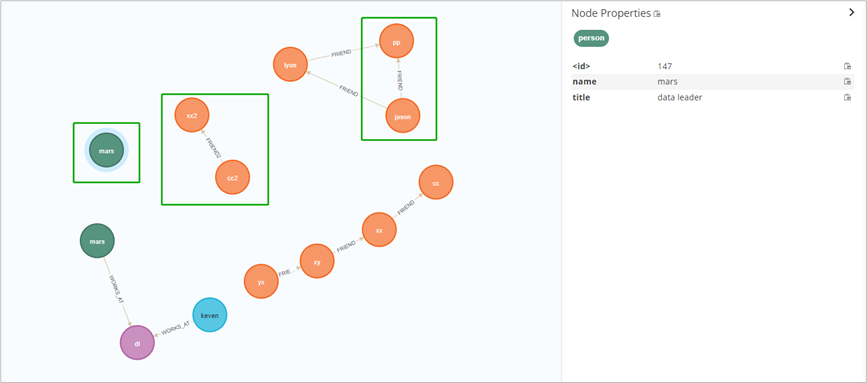
删
// 删除指定节点// 注意,节点有关系时会删除失败MATCH (e:Person) DELETE e// 删除指定节点,若有关系,则一起删除match (m: Person) where m.name = 'jason' DETACH delete m// 删除关系match (n:leader {name:'keven'})-[r: WORKS_AT]-() delete r
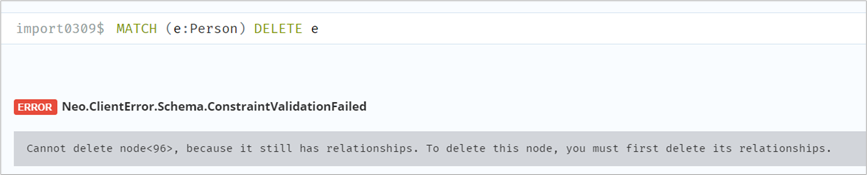
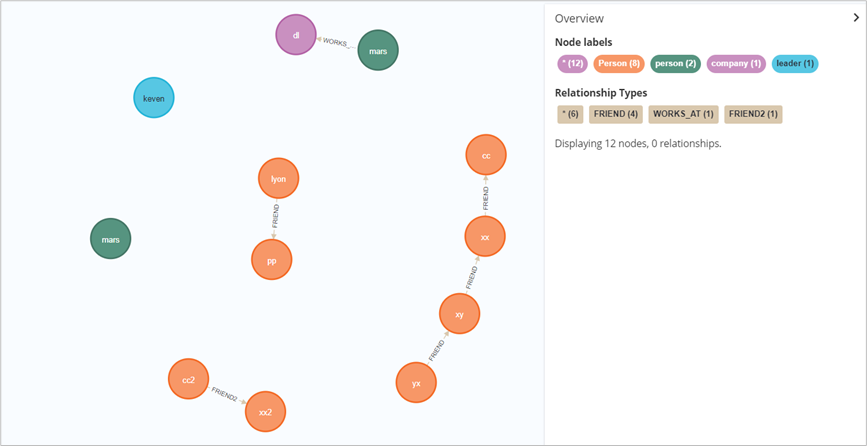
改
(1)SET 修改属性或标签赋值
// 新增属性match (cc:Person {name: 'cc'})set cc.sex='girl'// 先过滤,再setMATCH (n { name: 'mars' })where n.title = 'data leader'set n.age = 18RETURN n.name, n.age// 节点间属性替换MATCH (cc { name: 'cc' }),(cc2{ name: 'cc2' })SET cc2 = cc// 节点属性用map替换MATCH (xx{ name: 'xx' })SET xx = { name: 'xx', age: 18 }
(2)REMOVE 移除属性或者标签
// 移除属性match (keven:leader {name: 'keven'})remove keven.title// 移除标签MATCH (n { name: 'lyon' })REMOVE n:Person
查
(1)MATCH & RETURN 匹配并返回
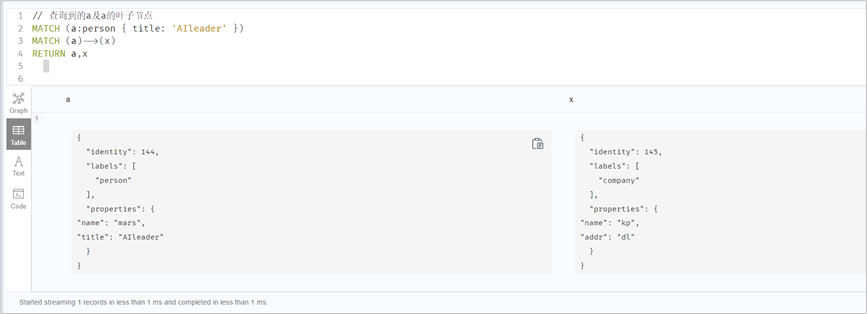
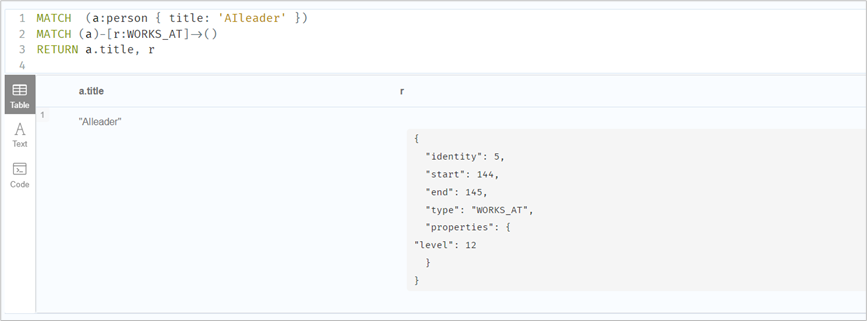
// 查询节点,并返回属性(朋友的朋友)MATCH (yx{name: 'yx'})-[:FRIEND]->()-[:FRIEND]->(xx)RETURN yx.name, xx.name// return *表示返回所有元素match(n:Person)return *// 查询到的a及a的叶子节点MATCH (a:person { title: 'AIleader' })MATCH (a)-->(x)RETURN a,x// 查询a的关系MATCH (a:person { title: 'AIleader' })MATCH (a)-[r:WORKS_AT]->()RETURN a.title, r
(2)指定关系层数查询
// 查询与yx连接的第二层节点match (n:Person {name:'yx'})-[*2]->(m:Person)return m;// 指定关系层数范围查询match(a:Person{name:'yx'})-[*1..3]->(b)return b;// 指定和yx关联的关系层数大于某个值match(a:Person{name:'yx'})-[*2..]->(b)return b;// 指定和yx关联的关系层数小于某个值match(a:Person{name:'yx'})-[*..2]->(b)return b;// 查询所有关系的节点(不指定层数)match(a:Person{name:'yx'})-[*]->(b)return b;
(3)查询path
// 查询节点和关系MATCH p =(yx:Person)-[*]-(cc:Person)WHERE yx.name = 'yx' AND cc.name = 'cc'RETURN p

(4)WHERE 过滤
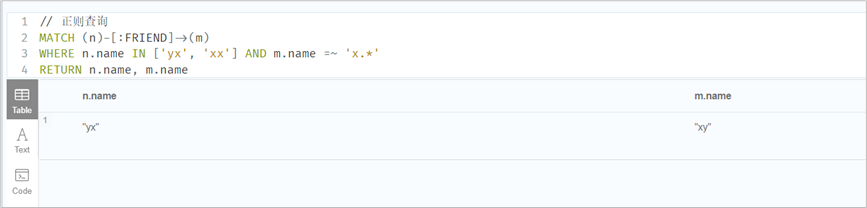
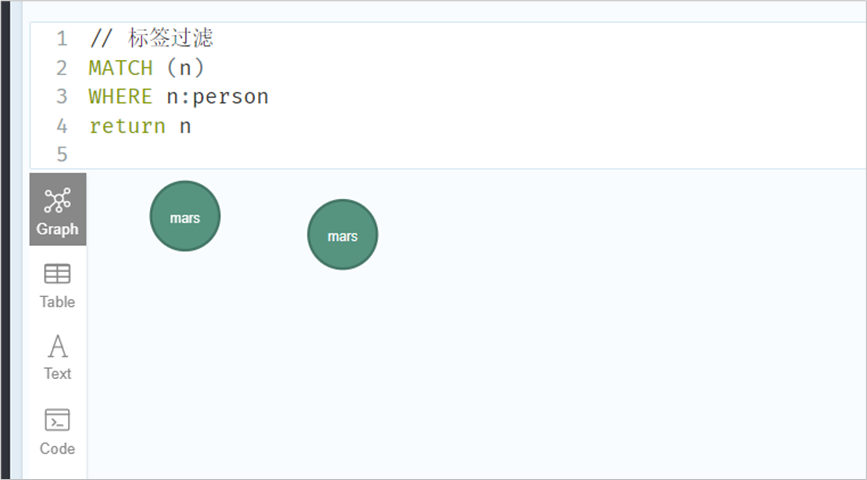
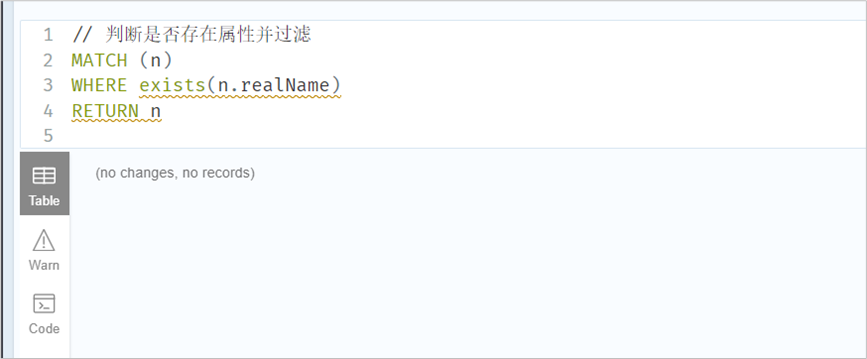
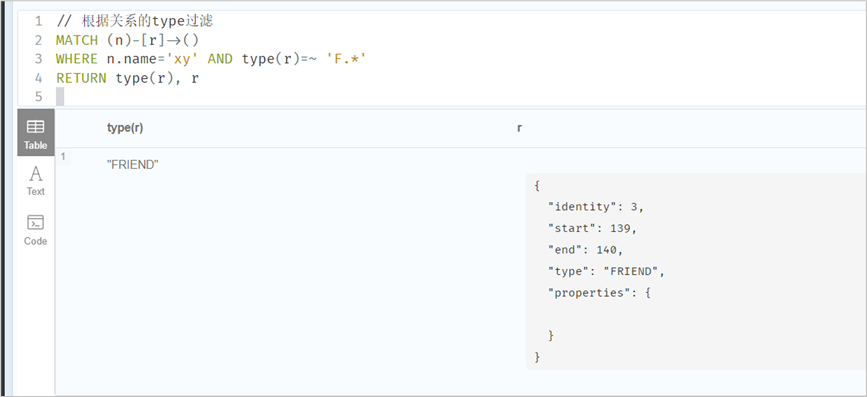
// 正则查询MATCH (n)-[:FRIEND]->(m)WHERE n.name IN ['yx', 'xx'] AND m.name =~ 'x.*'RETURN n.name, m.name// 标签过滤MATCH (n)WHERE n:personreturn n// 判断是否存在属性并过滤MATCH (n)WHERE exists(n.realName)RETURN n// 根据关系的type过滤MATCH (n)-[r]->()WHERE n.name='xy' AND type(r)=~ 'F.*'RETURN type(r), r
(5)WITH 连接
主要连接前后两个句子,可以将前句结果作为条件约束放到后句里操作。
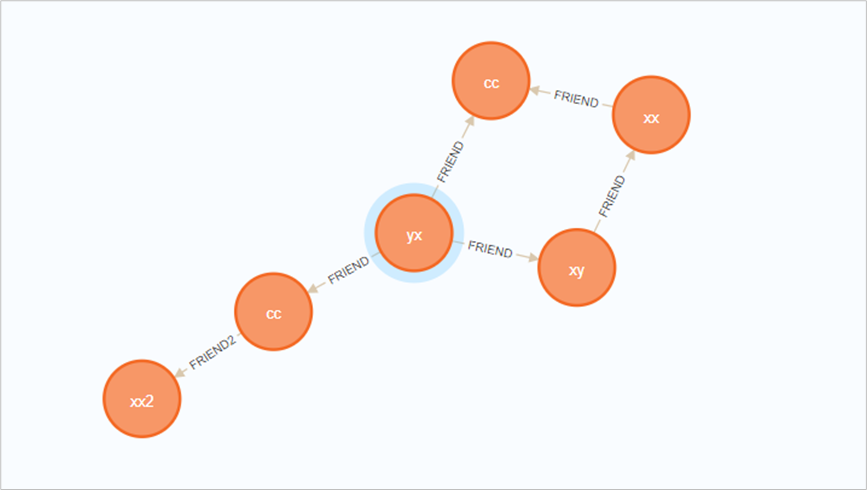
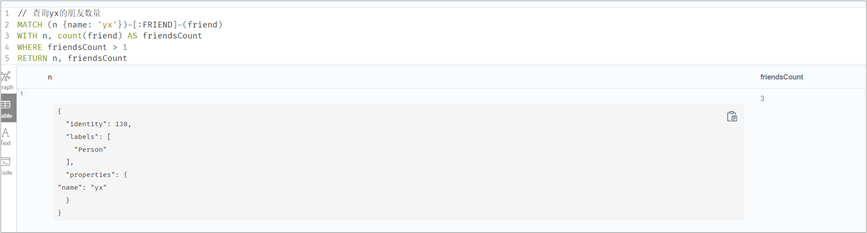
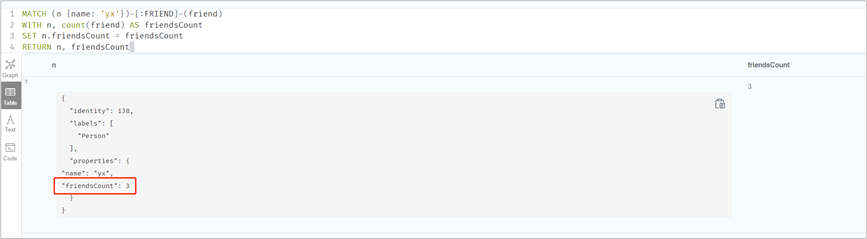
//为了实现下一个脚本,新增一组关系//因为之前有两个name:cc ,所以yx对cc一个是新建了关系,一个是更新了关系match (yx:Person {name:'yx'}),(cc:Person {name:'cc'})merge (yx)-[r:FRIEND {name:"new"}]->(cc)// 查询yx的朋友数量MATCH (n {name: 'yx'})-[:FRIEND]-(friend)WITH n, count(friend) AS friendsCountWHERE friendsCount > 1RETURN n, friendsCount// 先查后改,n多了个属性MATCH (n {name: 'yx'})-[:FRIEND]-(friend)WITH n, count(friend) AS friendsCountSET n.friendsCount = friendsCountRETURN n, friendsCount
(6)根据id查询
不做举例,只需记住用法为id(n)
MATCH (n)WHERE id(n)= 0RETURN nMATCH ()-[r]->()WHERE id(r)= 0RETURN rMATCH (n)WHERE id(n) IN [0, 3, 5]RETURN n
参考资料:
[1] neo4j系列—cypher QL https://mp.weixin.qq.com/s/N3mXTJmP-wyJcAcmvPosug
文章转载自DATA江湖,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
