




上次在PostgreSQL 12 索引中学习了PG基础索引类型,同时了解了还有多列索引、索引和order by、组合多个索引、唯一索引、表达式索引、部分索引、覆盖索引、操作符类和操作符族、索引和排序规则以及如何检查索引使用情况。
覆盖索引以前已经学习过,像同时了解了还有多列索引、索引和order by、组合多个索引、唯一索引、表达式索引,这些看名字就大概知道怎么回事,但是部分索引不一样。
今天主要学习一下部分索引以及应用场景。
一个部分索引是建立在表的一个子集上,而该子集则由一个条件表达式(被称为部分索引的谓词)定义。而索引中只包含那些符合该谓词的表行的项。部分索引是一种专门的特性,但在很多种情况下它们也很有用。
使用部分索引的一个主要原因是避免索引公值。由于搜索一个公值的查询(一个在所有表行中占比超过一定百分比的值)不会使用索引,所以完全没有理由将这些行保留在索引中。这可以减小索引的尺寸,同时也将加速使用索引的查询。它也将加速很多表更新操作,因为这种索引并不需要在所有情况下都被更新。
eg.
创建一个表test_sample

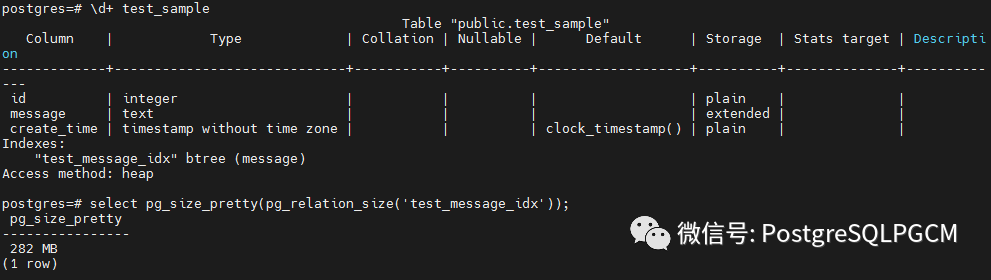
创建500W条数据,并在message创建btree索引,查看索引大小
查询表数据,Index Only Scan

更新表test_sampl中300W数据的message字段为相同值

再次查询,发现已经是全表扫描了,在a8d201418c95ca6939631995ca8f3e6a这个值上创建索引已经没有意义,反而会增加DML操作与存储的成本

这时我们删除原btree索引,创建部分索引
排除a8d201418c95ca6939631995ca8f3e6a值,查看索引大小
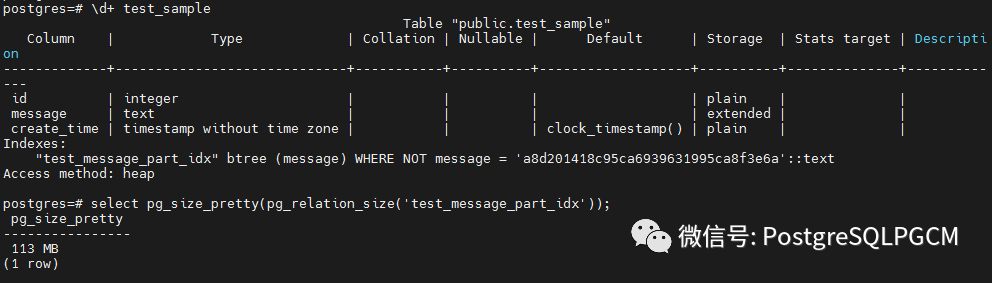
部分索引查询要求公值能被预知,因此部分索引最适合于数据分布不会改变的情况。这样的索引也可以偶尔被重建来适应新的数据分布,但是这会增加维护负担,在大部分情况下,一个部分索引相对于一个普通索引的优势很小。
