SGA的性能调整和优化思路
一、SGA组成
•Buffer Cache:主要缓存数据块
•Shared Pool:缓存Cursor相关的信息和数据字典
•Log Buffer:缓存重做日志条目
提示:Log Buffer不能实现在线动态调整

•SGA的一些重要属性
•计算性内存。在Unix/Linux系统中,可以通过ipcs观察共享内存
•数据库实例的一部分,正常访问表数据的通道
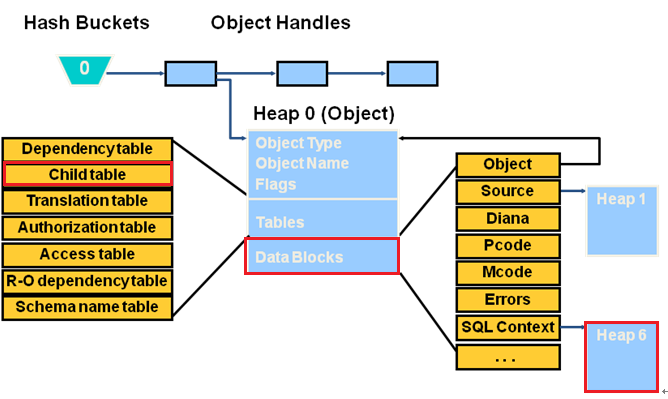
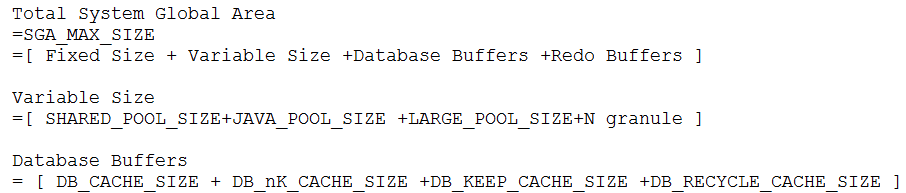
GRANULE
•GRANULE是一块真正意义上连续的内存块。是组成SGA的最小原子内存单位(SGA大小能被整除),分为三种状态:
ØFree
ØInitialized
ØAllocated
注意:SGA动态内存管理(ASMM)时,内存之间的移动是以GRANULE为单位的。
•获得GRANULE大小的方法:
Ø通过查看隐含参数_ksmg_granule_size获得
Ø通过查询V$SGAINFO获得
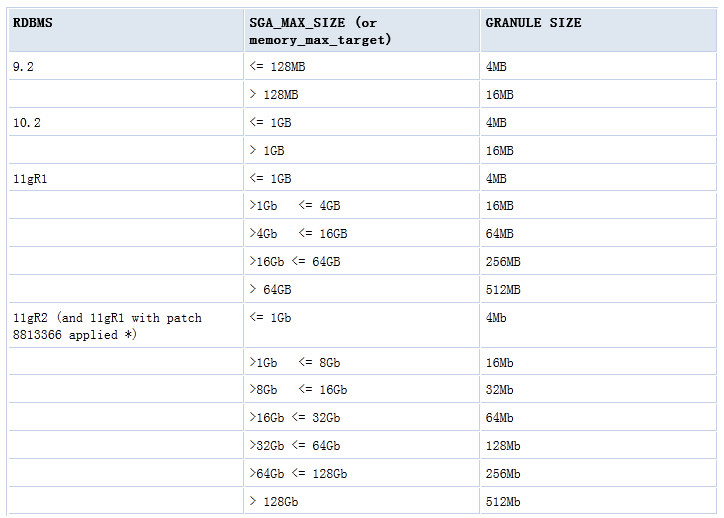
•GRANULE的大小与SGA大小和数据库版本有关:
二、详解BUFFER CACHE
Buffer Cache的作用
•数据库存放在磁盘中
•作为数据库的缓存
•可以缓存不同大小的数据块
•并发性访问受Latch保护
提示:多重缓存不仅带来浪费内存,而且会带来额外的开销,如内核调用
Buffer Cache的使用进程
•前台进程:从磁盘中读block至buffer cache中
•DBWR进程:从buffer cache写block至磁盘中
提示:前台进程和DBWR进程可以有多个,所以Buffer Cache中需要有latch来保护并发性访问
BUFFER CACHE的命中率
•从BUFFER CACHE中读取数据块一般需耗时100ns
•从磁盘读取数据块一般需耗时10ms左右(假设缓存没有命中)
•问题:Buffer Cache的命中率越高越好?
提示:BUFFER CACHE的命中率并不是越高越好,避免无效的数据块读取才是数据库优化之根本
•BUFFER CACHE的命中率高,并不意味着数据库性能良好。
Ø执行计划出错时,逻辑读高,但效率低下
Ø“热”块争用时,逻辑读低,但效率低下
Buffer Cache种类
•Default buffer cache:数据块的默认缓冲池,与db_block_size参数有关
•Keep buffer cache:缓存热块
•Recycle buffer cache:缓存冷块

提示:BUFFER CACHE中没有内存碎片这一说法
BUFFER CACHE的内部结构
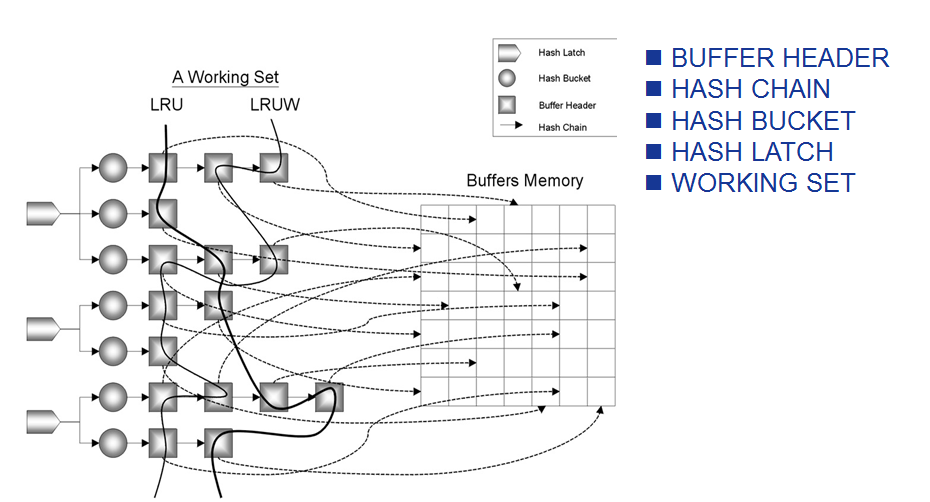
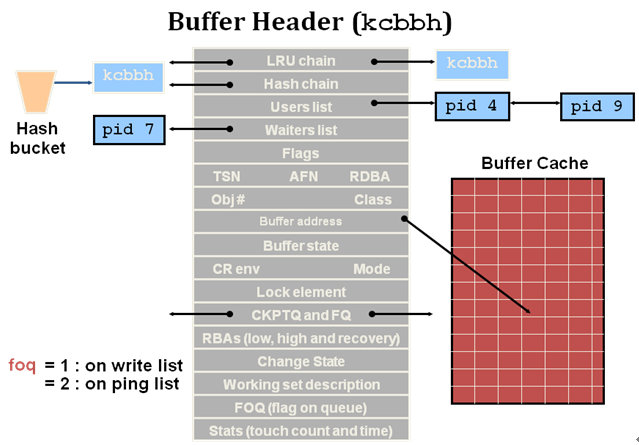
•BUFFER HEADER指的数据块的缓冲块头,BUFFER HEADER的地址位指向真正的数据块缓冲区。
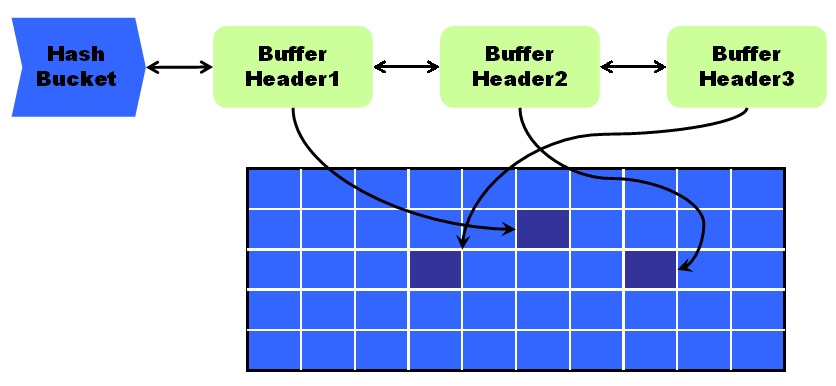
•根据该数据块的DBA/CLASS值进行类HASH运算,然后根据计算出的HASH值挂载到某一个HASH BUCKET中。
•不同的数据块经过HASH运算之后可能挂载到同一个HASH BUCKET中。
•Oracle将同一个HASH BUCKET的不同数据块用一条HASH CHAIN串联起来
•为了防止HASH CHAIN受到进程并发性访问的破坏,Oracle设计了专门的CACHE BUFFERS CHAINS LATCH(以下简称:CBC LATCH)用于保护HASH CHAIN
BUFFER HEADER
•控制结构大小占188个字节(Oracle 9i)
•查看使用过的BUFFER HEADER的方法如下:
Ø查询X$BH(Buffer Headers)
Ø使用命令DUMP BUFFER CACHE
记住字节大小意义不大,除非是做一些研究性工作。
HASH BUCKET
•挂载具有相同HASH值的数据块
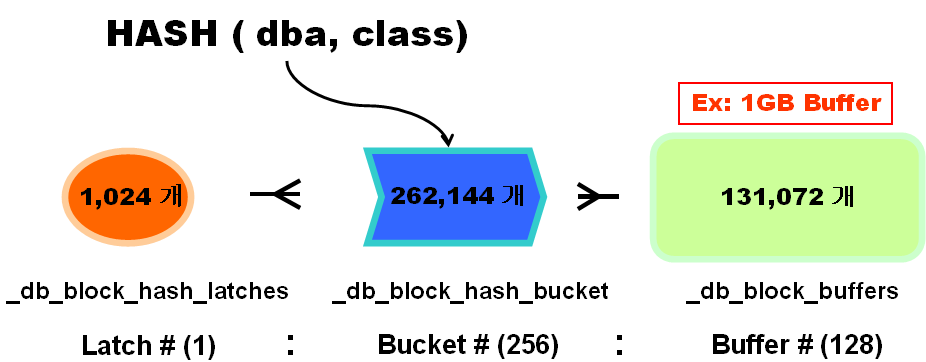
•默认数量为DB_BLOCK_BUFFERS x 2,查看隐含参数_db_block_hash_buckets获取具体的数量
•增加HASH BUCKET的方法:
Ø调整BUFFER CACHE的大小
Ø调整隐含参数_db_block_hash_buckets
HASH CHAIN
•串联具有相同HASH值的数据块
Ø会话通过计算数据块(RDBA,CLASS)的HASH值就可以快速定位数据块
Ø同一个数据块的CR块都具有相同的DBA值(CR块数量由隐含参数_db_block_max_cr_dba 控制)
热链
•热链指的是高频访问的HASH CHAIN
•问题:“热”链如何打破?
使用Hash表或更大的pctfree等技术分散数据块
LATCH:CACHE BUFFERS CHAINS
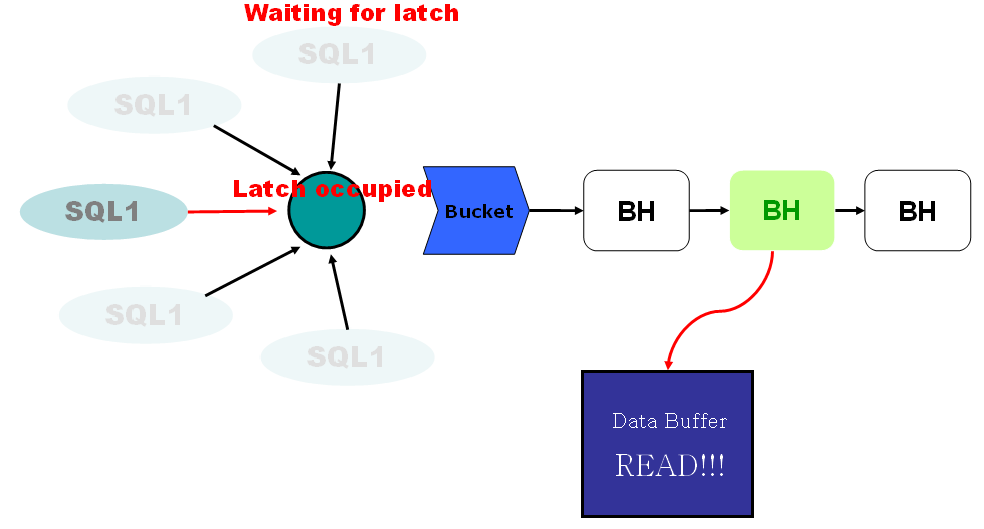
•多进程并发访问时保护HASH CHAIN结构
•一个CBC LATCH保护着多条HASH CHAIN
•v$session_wait.P1和P1RAW值表示CBC LATCH的地址(属于哪一条hash chain)
•服务器进程需要获得CBC LATCH情况:
Ø服务进程扫描HASH CHAIN中的数据块时
Ø服务进程将数据块挂载(PIN)到HASH CHAIN时
•通过以下方法可以查询CBC LATCH数量:
Ø查看隐含参数_db_block_hash_latches
Ø查询v$latch_children视图
•发生LATCH:CACHE BUFFERS CHAINS等待事件主要有以下几个原因:
Ø低效的SQL。多个并发进程同时大范围扫描表和索引
Ølatch数量不足
ØHash chain 过长
ØHot block。多个并发进程同时读取同一个数据块
LRU相关列
•LRU列
•LRU-W列
•LRU-XO列
•LRU-RO列
LRU列
•LRU列,又叫替换列。分为主列和辅助列:
Ø主列:已使用的(pinned/ unpinned dirty)数据块缓冲区列
Ø辅助列:空闲的数据块缓冲区列(系统启动之初)
LRU-W列
•LRU-W列,又叫写入列(LRU-Write list),脏数据列。分为主列和辅助列:
Ø主列:已修改的数据块缓冲区列
Ø辅助列:当前正等待或正通过DBWR进程写的数据块缓冲区列
•服务器进程在检索空闲缓冲区时,首先会检索LRU列的辅助列,当辅助列没有剩余缓冲区时,才会检索LRU主列中的COLD区域
•DBWR进程扫描LRU主列脏块,然后将其移动(指针的变化)至LRU-W主列,DBWR进程写脏块时,会将脏块移动至LRU-W辅助列
•数据块的buffer header只能挂载在LRU列或者LRU-W列的其中一个列
LRU-XO/XR列
•LRU-XO列:Reuse object list;
Ødrop/truncate table等操作
•LRU-XR列:Reuse range list; buffers to be written for reuse block range
Ø表空间begin backup/read only等操作
•分为主列和辅助列
触发DBWR写脏块条件
•Make free requests
•Checkpoints
•Ping writes(Oracle 8i OPS)
•Cleanout of cold dirty buffers
TOUCH COUNT
•dump buffer cache
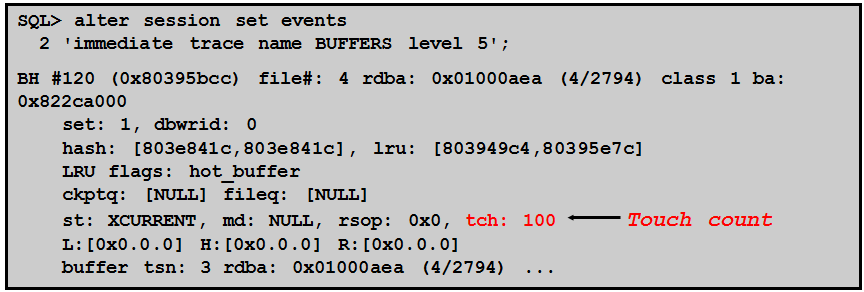
•查询x$bh

•使用TCH(访问计数器,隐含参数_db_aging_hot_criteria,默认为2 )记录某个buffer被访问的次数。
•分为HOT和COLD区域(_db_percent_hot_default,默认50%)
•前台进程扫描LRU LIST深度由隐含参数_db_block_max_scan_pct来调整
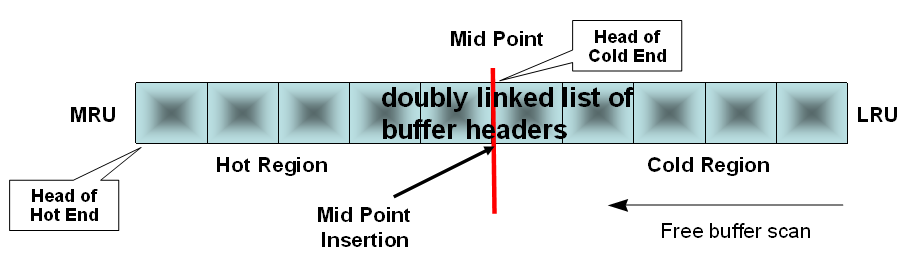
•TCH算法如下:

•3秒内(_db_aging_touch_time),如果数据块再次被访问,则TCH不增长
•TCH增长不需要LATCH保护,所以可能会出现增长丢失情况
CACHE BUFFERS LRU CHAIN LATCH
•主要用于保护进程并发访问LRU LIST
•通过以下方法获取当前系统中CACHE BUFFERS LRU CHAIN LATCH的数量:
Ø查询隐含参数_db_block_lru_latches
Ø查询V$LATCH_CHILDREN
•不同的缓冲池使用独立的LRU LATCH
•和DBWR的数量有关
Ø DBWR数小于4,则创建4*CPU_COUNT
Ø DBWR数大于4,则创建DB_WRITER_PROCESSES*CPU_COUNT
•需要获得LRU LATCH的情况如下:
Ø服务进程扫描LRU列( round-robin 方式)获取FREE BUFFER,即数据块进入BUFFER CACHE之前
ØDBWR进程写脏数据块之前扫描LRU列和LRU-W列
ØDBWR进程将FREE BUFFER 移动至LRU辅助列之前
•当许多进程(服务进程和DBWR进程)同时检索LRU列或者LRU-W列时(则容易出现LATCH: CACHE BUFFERS LRU CHAIN等待事件。低效的SQL是主因,大量数据块涌入buffer cache)
•LRU LATCH争用往往伴随着大量的 物理I/O
•不要简单地通过调整隐含参数_db_block_lru_latches来解决LATCH: CACHE BUFFERS LRU CHAIN等待事件
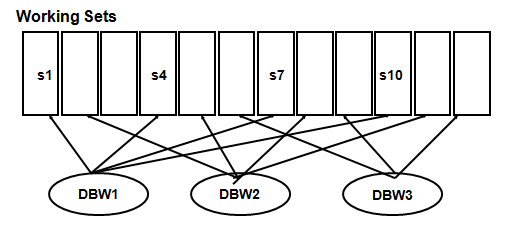
•LRU列和LRU-W列的集合称之为Working Set
•每个Working Set拥有独立的LRU LATCH
•1个DBWR进程管理1个或者多个Working Sets
•不同的Buffer Cache拥有不同的Working Sets
HASH列和LRU列区别
•HASH列的作用为了定位数据块
•LRU列的作用为了分配缓存(服务进程的工作)和换出缓存(DBWR进程的工作)BLOCK
•CBC LATCH和LRU LATCH之间的区别:
Ø多个会话并发访问相同的表或者索引(相同的数据块)时,则发生CACHE BUFFERS CHAINS LATCH争用的概率较高
Ø多个会话并发访问不同的表或者索引(不同的数据块)时,则发生CACHE BUFFERS LRU CHAIN LATCH争用的概率较高
•问题:使用KEEP POOL能改善CBC LATCH争用吗?
看情况。合理使用Keep Pool能有效减少物理读,即减少数据库pin CBC机会,从而减少CBC LATCH争用
FREE BUFFER WAITS
•DBWR进程在写脏块完成(批处理写操作可以通过参数_db_block_write_batch来调整)之前,服务进程等待空闲缓冲区时会出现FREE BUFFER WAITS等待事件
•通常是由以下原因引起的:
Ø低效的SQL
ØBUFFER CACHE过小
ØDBWR进程数量不足或者写脏块的速度不够快
Ø存储I/O问题
•问题:如何判断DB CACHE是否已经足够?
看AWR报告中BUFFER CACHE建议一栏,另外BUFFER CACHE设置大没有坏处,但前提是不产生交换,CPU资源较充足
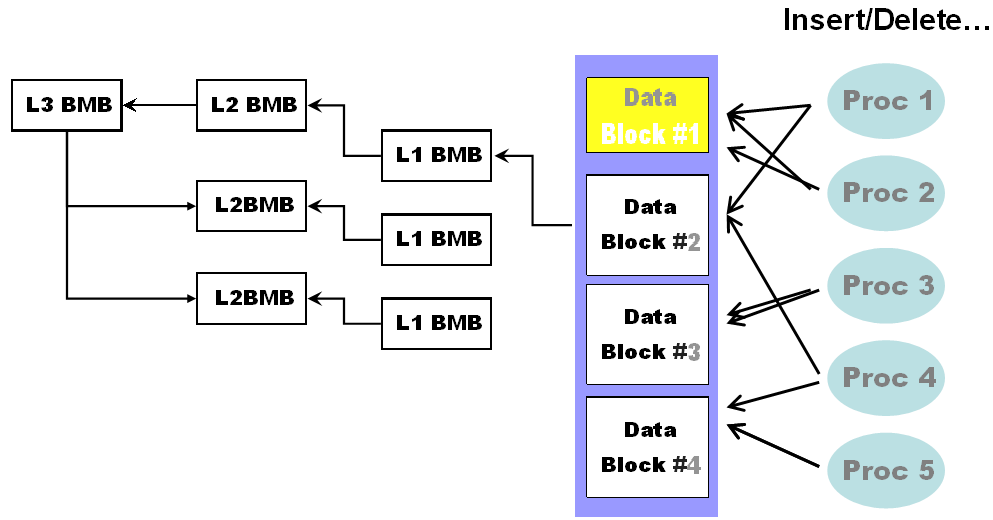
BUFFER BUSY WAITS
•阻塞会话(BLOCKING会话)正在修改数据块时,想以当前模式访问的会话需要等待
•v$session_wait中P1值代表数据文件号,P2值代表数据块号,P3值代表数据块类型
•手动段管理方式(MSSM,即用FREELIST管理可用数据块)管理方式的段头在并发INSERT操作时容易引起争用
READ BY OTHER SESSION
•一个以上的会话欲访问buffer cache上不存在的数据块时,发现该数据块正在被另外一个会话从磁盘读往缓冲区
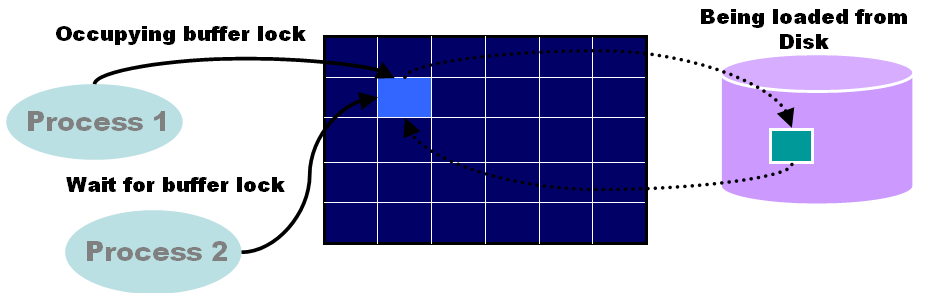
•往往伴随着DB FILE SEQUENTIAL READ或者DB FILE SCATTERED READ等待事件出现
•突然出现大规模此类事件时,往往是执行计划不准确引起的
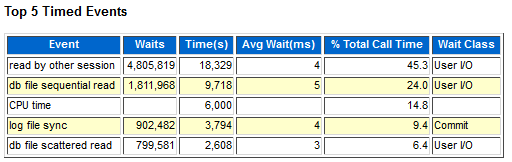
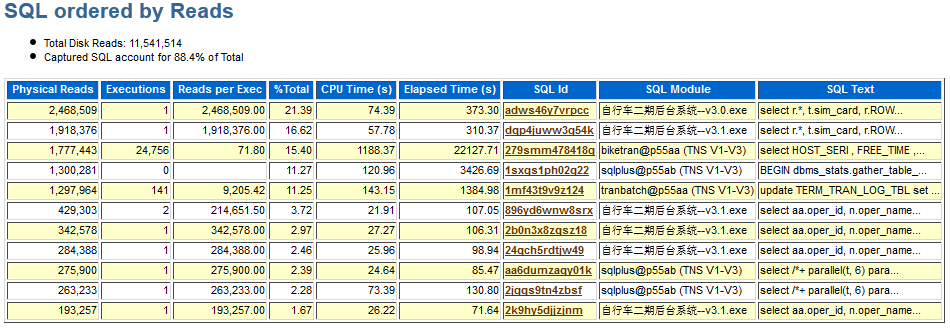
BUFFER CACHE大小的建议值
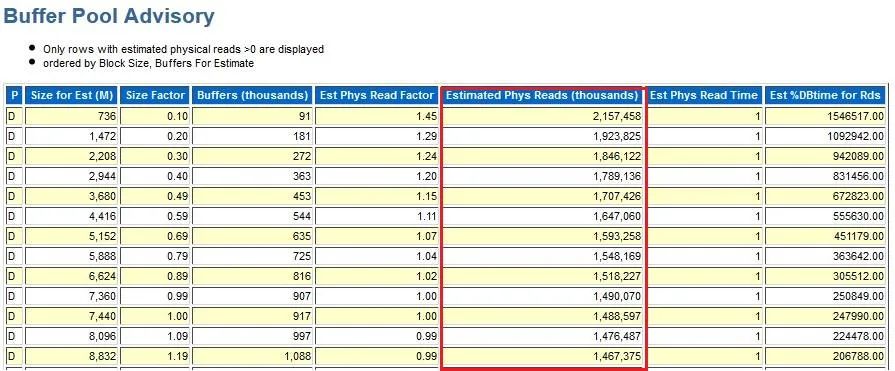
•查询V$DB_CACHE_ADVICE
•查看AWR报告中Buffer Pool Advisory
BUFFER CACHE内存不足的优化思路
•加大buffer cache内存
•调整糟糕的SQL语句写法或执行计划
•DBWR进程数不足或者存储性能缓慢
提示:适当加大buffer cache内存是没有坏处的
BUFFER CACHE中数据块争用的优化思路
•重新设计应用
•让数据块中的数据尽可能地分散
Ø使用不同块大小的数据块
Ø修改数据块PCTFREE参数
Ø表中添加固定大小的列,增加冗余数据
Ø使用HASH分区表和HASH 簇表
Ø使用反转键索引(REVERSE INDEX)
Ø增大BUFFER CACHE
Ø合理使用KEEP POOL和RECYCLE POOL
Ø使用ASSM(自动段空间管理)
Ø加大数据块INTRANS参数
•使用直接路径读写(DIRECT PATH I/O)
•CPU紧张的系统中,适当减小BUFFER CACHE
•RAC系统中,提高本地节点的BUFFER CACHE命中率
•CPU、内存资源充足的情况下,增加buffer cache容量没有坏处,但前提是不要产生换页
三、详解SHARED POOL
SHARED POOL的主要内容
•SHARED POOL从结构上可以大体分为如下几类:
ØPERMANENT AREA:进程/会话数据、ges resource等
ØLIBRARY CACHE
ØROW CACHE
ØRESERVED AREA
Ø
堆(HEAP)管理
•SHARED POOL是利用堆内存管理(KGH heap Manager)方式管理
•Oracle 9i开始,可以有多个最高级堆(TOP-LEVEL HEAP),最高级堆可以分为多个副堆
•SHARED POOL,PGA,UGA,CGA可有多个高级堆
SHARED POOL的内存结构图
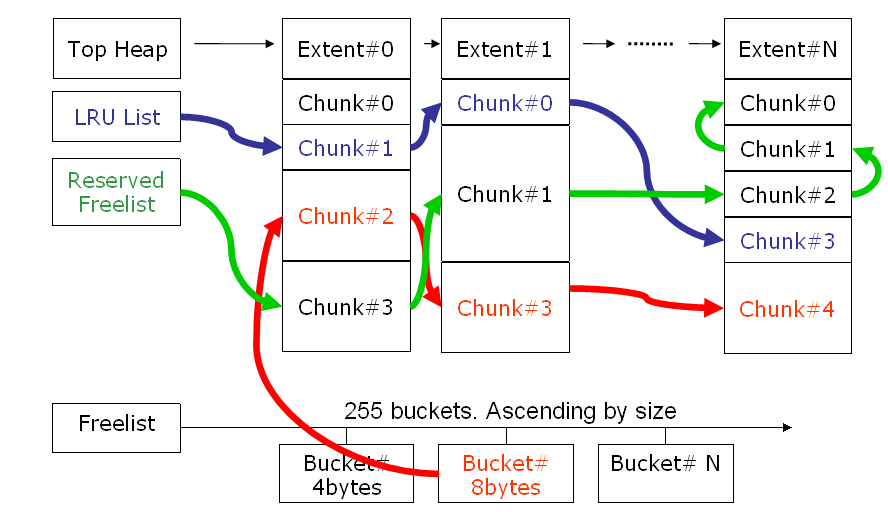
•一个堆由多个内存区(EXTENT)以LINKED LIST的形式连接组成
•EXTENT是物理上连续的内存区域
•一个内存区由多个CHUNK组成
HEAP DUMP
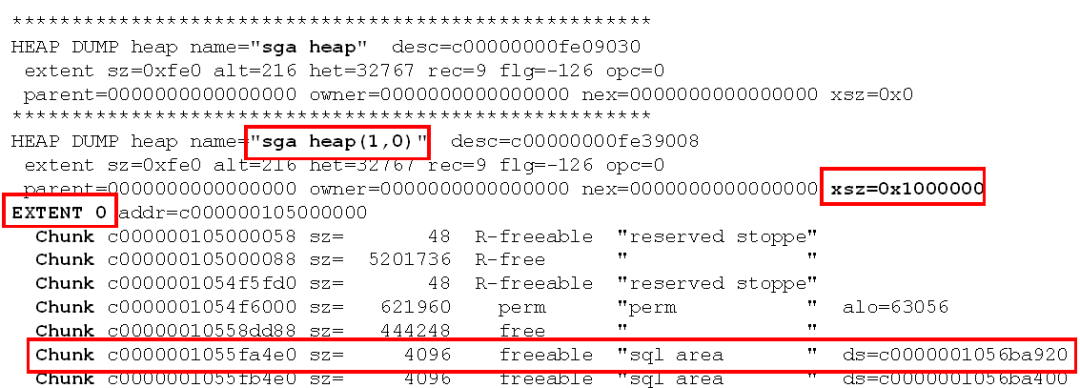
CHUNK
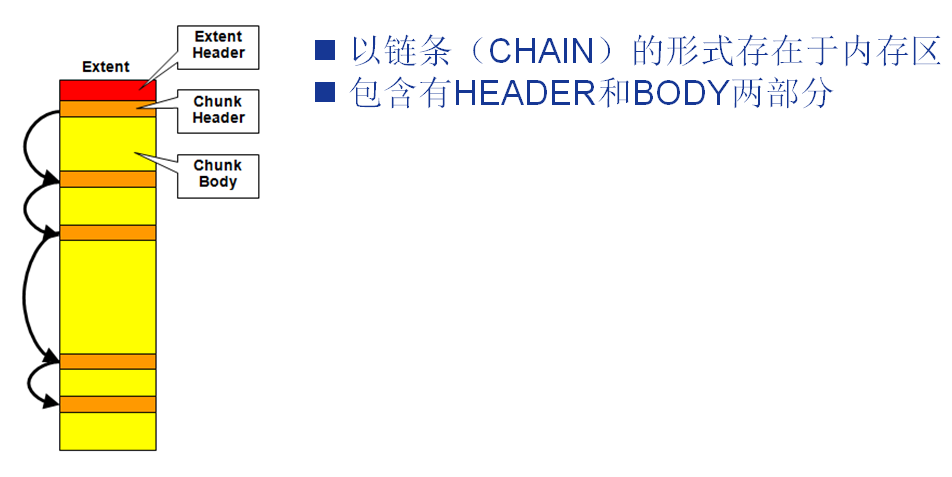
•分为以下几种状态(可以从视图x$ksmsp中查询):
ØFREE(可马上使用)
ØRECREATABLE(可再生)
ØFREEABLE(只有在SESSION或CALL期间内保存必要的对象状态)
ØPERMANENT(永久,不可再生)
FREE LIST
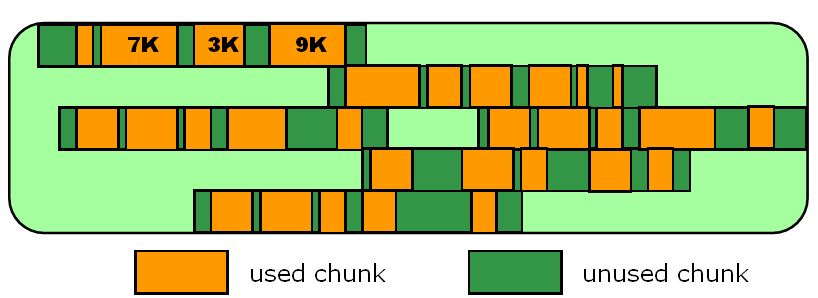
•FREE LIST主要用于管理空闲的CHUNK。9i后,由256个BUCKET管理的,8i或者更早版本,只包含10个BUCKET
•根据请求的chunk大小遍历合适大小的buckets,如果找不到合适的则遍历下一个buckets(bucket 0的内存碎片会越来越多)
•分割产生的空闲CHUNK或者释放的CHUNK,会被挂载到相应的bucket上
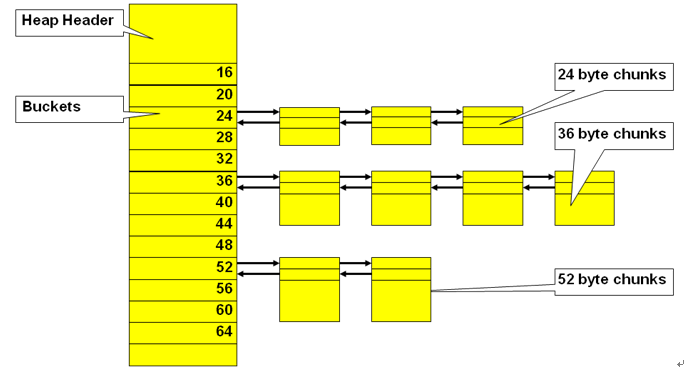
•分割连续的内存导致的内存碎片(chunk大小不一致),如下图:
注意:
(1)同一个BUCKET中的chunk不严格排序
(2)内存碎片是不可避免的,相邻的碎片会定时合并
如果literal SQL使用较多而且shared pool又很大,长时间使用后内部内存freelist上会产生大量小的内存碎片,使得shared pool latch被持有的时间变长,进而导致性能问题。在这种情况下,较小的shared pool也许比较大的shared pool好。因为 Bug:986149 的改进,这个问题在8.0.6和8.1.6以上版本被大大减少了。
•合并shared pool碎片的方法:
SQL> alter system flush shared_pool;
•注意: flush shared pool之后可能会导致:
Ø实例hang
Øsequence(cache属性)不连续
Ø过量的硬解析导致latch:shared pool争用
LRU LIST
•主要保存着可以重建(recreateable)的chunk :
Øpinned (in use)
Øunpinned (inactive)
•unpinned chunk主要分为2种LRU LIST:
ØTransient list:可能不会马上用到(cursor chunks)
ØRecurrent list:可能会马上用到(row cache chunks)
RESERVED FREE LIST
•大小由参数SHARED_POOL_RESERVED_SIZE决定,默认为SHARED POOL大小的5%。最大不能超过SHARED POOL大小的一半
•只有大于_shared_pool_reserved_min_alloc隐含参数阀值(默认值为4400)的CURSOR才能进入RESERVED FREE LIST
•只有高级堆有RESERVED FREE LIST
•从Oracle 7.1.5首次引进,一般情况下,不常用到
•查询V$SHARED_POOL_RESERVED
Ø如果REQUEST_FAILURES > 0
LAST_FAILURE_SIZE >SHARED_POOL_RESERVED_MIN_ALLOC
则:
(1)增加 SHARED_POOL_RESERVED_SIZE大小
(2)增加SHARED_POOL_SIZE大小
Ø如果REQUEST_FAILURES > 0
LAST_FAILURE_SIZE<shared_pool_reserved_min_alloc< span=""></shared_pool_reserved_min_alloc<>
则:
(1)减少_SHARED_POOL_RESERVED_MIN_ALLOC值
(2)增加SHARED_POOL_SIZE
Hidden free memory
•实例启动之初分配shared pool内存的一半
•不在free list中
•使用后不再回收
•从V$SGASTAT中可以观察:
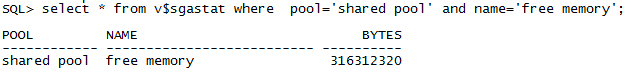
SHARED POOL的内存分配顺序
•进程在shared pool中分配内存的顺序:
(1)在FREE LIST查找合适大小的空闲CHUNK
(2)检索LRU LIST,查找recreateable unpined的CHUNK
(3)从父堆里分配空间
(4)自动扩展shared pool
(5)出现ORA-4031错误
注意:
(1)如果FREE LIST列表过长(即包含的FREE CHUNK过多),那么会话搜索可用的FREE CHUNK的时间可能会延长,从而导致持有SHARED POOL LATCH的时间更长
(2)如果达到了隐含参数_shared_pool_reserved_min_alloc的阀值,内存分配则从RESERVED FREE LIST中分配
•Shared pool释放空闲内存顺序:
(1)释放没有上锁的对象
(2)释放带空锁的对象
注意:锁住/KEEP的对象是不能释放的
LATCH:SHARED POOL
•扫描/分配/回收free chunk时需要申请latch:shared pool。如果free chunk过多则容易导致持有latch:shared pool过长。
注意:LATCH:SHARED POOL争用时,随意增大SHARED POOL的大小可能会更加恶化数据库性能
SHARED POOL的SUB POOL技术
•Oracle 9i开始,SHARED POOL可以分为多个SUB POOL,其数量受以下几个因素影响:
Ø系统CPU的数量(A)
Ø共享池的大小(B)
Ø隐含参数_kghdsidx_count值(C)
Oracle设置SUBPOOL大小的数量取值如下:

注意:NUMBER OF CONFIGURED SHARED POOL SUBPOOLS IS NOT CORRECT(Bug 4994956)
•不同版本下的subpool的最小大小

•每个SUB POOL拥有独立的FREE LIST、LRU LIST和SHARED POOL LATCH
•从Oracle 10g开始,每个SUB POOL由4个SUB PARTITION组成
•查询X$KSMSS获得每个SUBPOOL所分配的内存、剩余内存
•查询X$KGHLU观察每个SUBPOOL发生ORA-04031的情况
•
关于SGA内存抖动
•设置SGA_TARGET参数时,同时设置SHARED_POOL_SIZE和DB_CACHE_SIZE参数,使得SHARED POOL和BUFFER CACHE值维持在参数值之上,进而降低内存抖动的频率
•设置的参考标准?
DICTIONARY CACHE
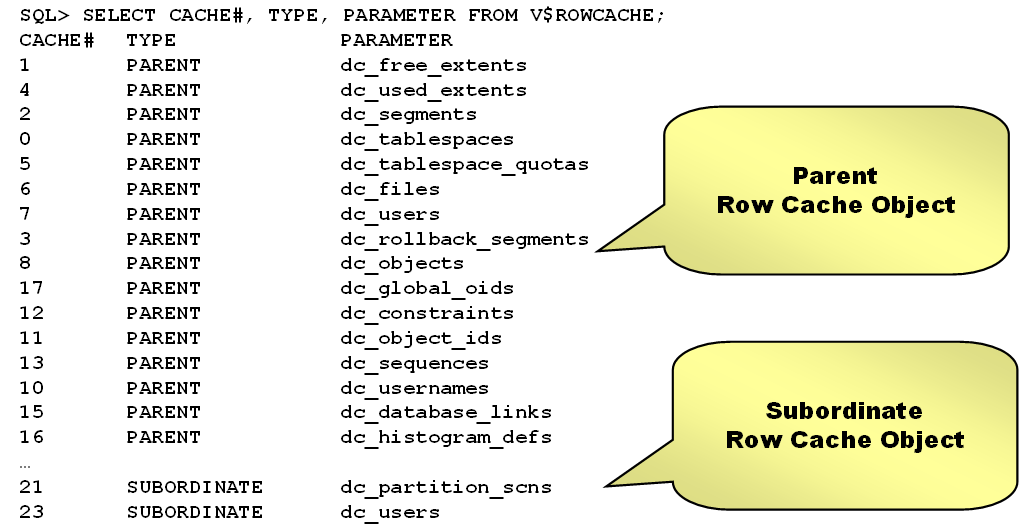
•主要用于缓存Oracle数据字典
•以行(Row)为单位存放,不是以块(Block)为单位,主要存放以下内容(dc_xxx对象):
ØTablespace
ØTable
ØIndex
ØSegment
ØView
ØUser
Ø…
•以下情况需要访问Dictionary Cache:
ØDDL语句
ØSequence.nextval
Ø需要访问对象、用户、空间等数据字典信息
ROW CACHE LOCK
•主要用于保护row cache中的对象(objects)
•用户访问row cache之前需要获得row cache lock:
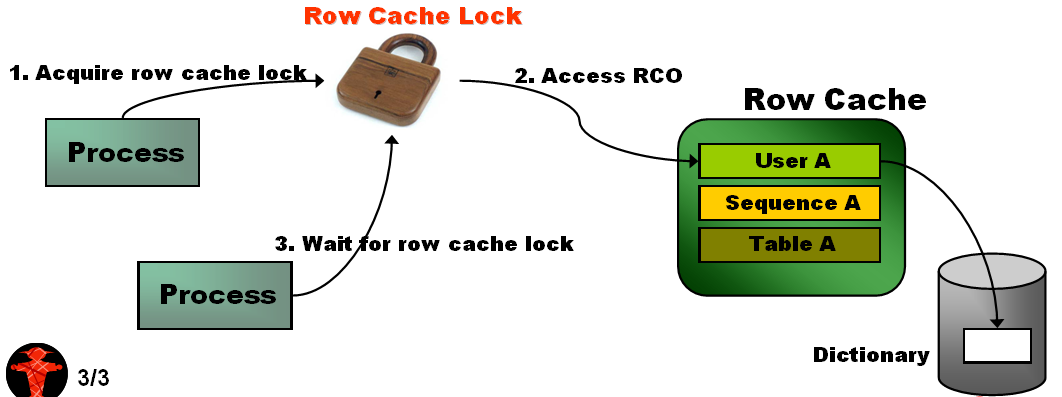
•引起row cache lock的原因:
Ø通常是高并发访问sequence(no cache)引起
Ø频繁访问柱状图信息
ØBug
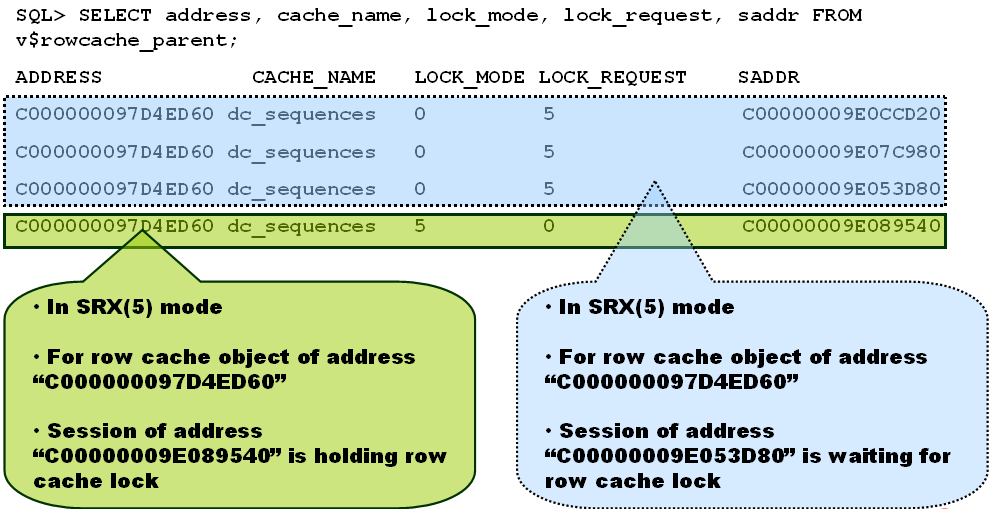
•可以通过v$rowcache_paraent查询holder和waiter:
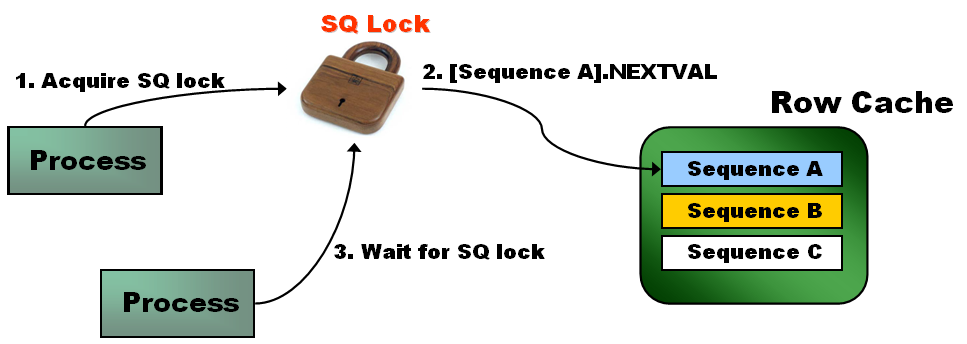
enq:SQ-contention
•主要用于保护以下场景:
ØSequence从dictionary cache中申请cache资源
Ø前台进程获取Sequence nextval
LIBRARY CACHE的内部结构
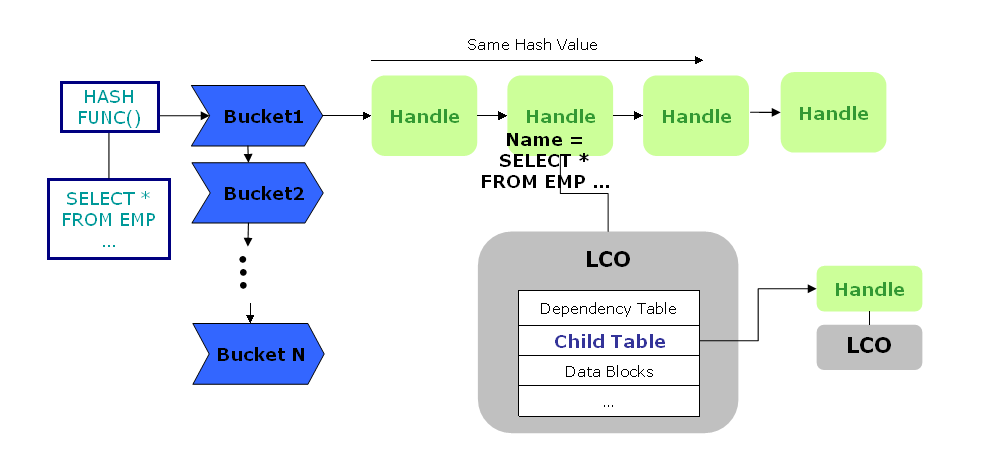
•BUCKET主要由LIBRARY CACHE LATCH保护
•HANDLE由LIBRARY CACHE LOCK保护
•LCO由LIBRARY CACHE PIN保护