




CRSD进程
Cluster Ready Service:
• Engine for HA operation
• Manages 'application resources'
• Starts, stops, and fails 'application resources' over
• Spawns separate 'actions' to start/stop/check application resources
• Maintains configuration profiles in the OCR (Oracle Configuration Repository 数据库配置文件仓库)
• Stores current known state in the OCR.
• Runs as root
• Is restarted automatically on failure
这是一个很忙碌的进程,管家。
CSSD进程
Cluster Synchronization Service :
• OCSSD is part of RAC and Single Instance with ASM
• Provides access to node membership
• Provides group services
• Provides basic cluster locking
• Integrates with existing vendor clusteware, when present
• Can also runs without integration to vendor clustware
• Runs as Oracle.
• Failure exit causes machine reboot.
• This is a feature to prevent data corruption in event of a split brain.
这是一个很重要的进程,核心。
EVMD进程
Event Manager:
• Generates events when things happen
• Spawns a permanent child evmlogger
• Evmlogger, on demand, spawns children
• Scans callout directory and invokes callouts.
• Runs as Oracle.
• Restarted automatically on failure
LCK0进程
•Instance Enqueue Process(实例队列进程)
LCK0进程主要处理非cache fustion的资源请求,比如library 和row cache 请求。
•LCK0进程处理在实例一级的锁:
Row cache entries
Library cache entries
Result cache entries
@In 9.0.1 and below, number of lock processes may be configurable using _gc_lck_procs parameter
LMON进程
•Global Enqueue Service Monitor(全局队列服务监控)
LMON进程用于监控整个集群的global enqueues和resources, 而且会执行global enqueue recovery。
•实例异常终止后,会由LMON进程来进行GCS内存方面的处理。
•当一个实例加入或者离开集群后,LMON进程会对lock和resource进行reconfiguration.
•LMON进程会在不同的实例间进行通讯检查,如果发现对方通讯超时,就会发出节点eviction,当节点发生eviction后(ORA-00481, ORA-29740等),需要查看LMON进程的trace来了解eviction的原因。
LMSn进程
•Global Cache Service Process(全局缓存服务进程)
LMSn进程维护在Global Resource Directory (GRD)中的数据文件以及每个cached block的状态
•LMSn进程用于在RAC的实例间进行message以及数据块的传输(Cache Fusion)
•每个实例会有多个LMSn进程,每个Oracle版本的默认的LMSn进程数目会有所不同,大部分版本的默认值是:MIN(CPU_COUNT/2, 2)),由参数gcs_server_processes决定
•LMSn进程可以说是RAC上最活跃的后台进程,往往会消耗较多的CPU资源(需要较高CPU优先级)
LMSn进程的优先级
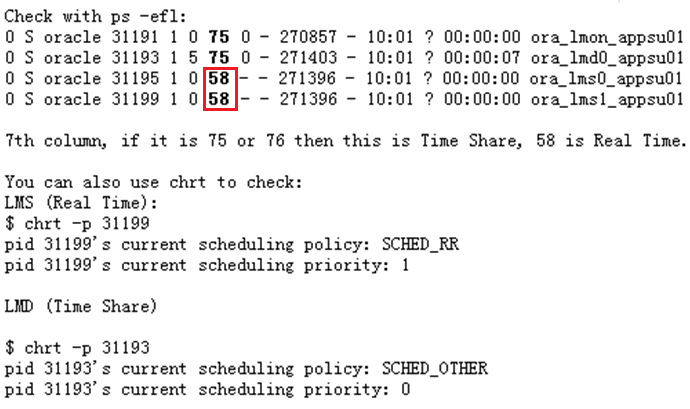
•如果LMSn进程没有运行在RT模式,则还需要检查oradism配置文件的权限:

LMD0进程
•Global Enqueue Service Daemon。(全局队列服务守护进程)
LMD0 进程主要处理从远程节点发出的资源请求。
• One LMD process per instance
• In 8.1.7 and below number of lock daemons may be configurable using _lm_dlmd_processes parameter
•Master:resource的master实例,在shared pool 中分配一些空间来存放和这个资源相关的信息
• Holder:资源持有者
• Requestor:资源申请者
LMD0 进程主要处理从远程节点发出的资源请求大概过程如下:
(1)一个连接发出了global enqueue 请求
(2)这个请求会被发给本节点的LMD0进程,前台进程会处于等待状态
(3)本节点的LMD0会找到这个资源的master节点是谁,并把这个请求发送给master节点。如果需要的话,master节点会增加一个新的master资源,这时从master节点可以获知谁是owner, waiter
(4)当这个资源被grant给requestor后, master节点的LMD0进程会告知requestor节点的LMD0进程
(5)然后requestor节点的LMD0进程会通知申请资源的前台进程
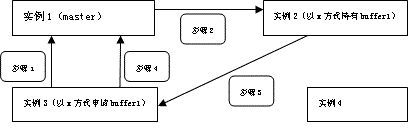
(1)实例3(Requstor)需要以X(exclusive)方式访问buffer1, 向实例(1)(Master) 发出了请求。
(2)实例发现实例2(Holder)以X方式持有buffer1,之后通知实例2释放X lock,并把buffer1发送给实例3。
(3)实例2释放X lock,并把最新版本的buffer1发送给实例3。
(4)实例3获得buffer1, 并通知master 实例更新资源buffer1的最新状态。
DRM 进程
Dynamic Resource Mastering(动态资源掌握)
•根据一段时间内(默认10分钟),每个实例根据某一个数据库对象的 (10gR1以数据文件为单位)的访问次数和方式,来决定数据库对象对应的buffer应该被mastering 到哪一个实例。
• 在指定时间内,如果某一个实例访问某个数据库对象的次数高于其他实例一定倍数(默认50倍,由_gc_affinity_limit参数控制),则oracle 会把这个对象所有的buffer的master信息,转移到对应实例(注意:不是转移buffer)
• 使用HASH的方式来决定每个BLOCK的MASTER是哪个节点,默认情况下HASH的BUCKET是 128(由参数_lm_contiguous_res_count 控制),也就是说ORACLE按照连续128个BLOCK在一个节点,然后接下来的128个BLOCK在另外一个节点这样的机制来进行平均分配块的 MASTER。
• 在DRM中,LMD进程会监控需要进行remaster的queue,然后把任务发送给LMON进程,LMON进程来实施remaster。
•DRM发生时的相关日志:
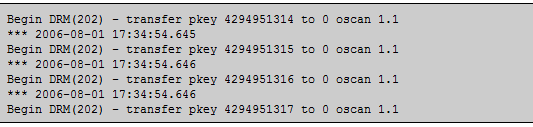
•10.2.0.2版本之前,DRM特性不是很稳定,有较多bug。Oracle也不推荐使用(但这又是缺省在使用的功能)严重的会导致系统hang住。可以通过下面两个隐含参数来禁止DRM的发生:
_gc_undo_affinity=FALSE
_gc_affinity_time=0
•DRM出现问题时,则检查LMD0,LMSn,LMON进程的相关日志
•注意:DRM必须在所有实例中同时关闭,否则启动数据库时会出现以下错误:
•ORA-01105: mount is incompatible with mounts by other instances
ORA-01606: gc_files_to_locks not identical to that of another mounted instance
•DRM的相关视图:
GV$GCSPFMASTER_INFO
X$KJDRMREQ:Dynamic Remastering Requests
X$KJDRMAFNSTATS:File Remastering Statistics
X$KJDRMHVSTATS:Hash Value Statistics
Diagnosability for Oracle Clusterware (CRS or Grid Infrastructure) Component and Resource
(文档 ID 357808.1)
CRS and 10g/11.1 Real Application Clusters (文档 ID 259301.1)
DRM - Dynamic Resource management (文档 ID 390483.1)
Script to Collect DRM Information (drmdiag.sql) (文档 ID 1492990.1)
DIAG进程
Diagnostic Capture Process
用来打印诊断信息。diag进程会响应别的进程发出的dump请求,将相关的诊断信息写到diag trace文件中。在RAC上,当发出global oradebug请求时,会由每个实例的diag进程来打印诊断信息到diag trace中。
比如:下边的命令用了“-g”,那么生产的dump信息会分别写到每个实例的diag trace文件中:
SQL > oradebug -g all hanganalyze 3
SQL > oradebug -g all dump systemstate 266
ASMB进程
ASM Background Process
用于和ASM实例进行通讯,用来管理storage和提供statistics。当使用ASMCMF的cp命令时,需要用到ASM实例上的ASMB进程,数据库实例的spfile如果位于存在ASM上,那么也会用到ASMB进程。如果OCR存放在ASM中,也会用到ASMB。
REBL进程
ASM Rebalance Master Process
作为ASM磁盘组进程rebalance时的协调者(coordinator)。在数据库实例上,由它来管理ASM磁盘组。
Onnn进程
ASM Connection Pool Process
是从数据库实例连接到ASM实例上的一些连接池,通过这些连接池,数据库可以发送消息给ASM实例。比如,由它将打开文件的请求发送给ASM实例,这些连接池只处理一些较短的请求,不处理创建文件这种较长的请求。
PZ进程
PQ slaves
PZnn进程(从99开始)用于查询GV$视图,这种查询需要在每个实例上并行执行。如果需要更多的PZ进程,会自动生成PZ98,PZ97……降序。
11g特有的进程
PING进程
Interconnect Latency Measurement Process
用来查询集群中每个实例间的私网通讯状况。每个实例每个几秒会发送给其他实例一些消息,这些消息会由其他实例的PING进程收到。发送和接收信息花费的时间会被记录下来并判断是否正常。
LMHB进程
Global Cache/Enqueue Service Heartbeat Monitor
监控本地的LMON、LMD、LCK0、RMS0、和LMSn等进程是否正常,是否被阻塞或者已经HANG了
RMSn进程
Remote Slave Monitor Process
管理后台的slave进程的创建,作为远程实例的协调者来完成一些任务。
GTXn进程
Global Transaction Process
在RAC环境中对于XA事务提供透明支持,维护在RAC中的XA事务的global信息,远程global事务的两个阶段提交。
RCBG进程
Result Cache Background Process
这个进程用来处理RAC上的Result Cache相关的信息。
ACMS进程
Atomic Control File to Memory Service Process
作为每个实例上的agent来保证SGA的更新在RAC的所有实例上都是同步的,或者是全局成功提交,或者由于一些问题而导致的全局回滚。
