




在开始今天这篇文章之前,先修正一个上一篇文章中的错误。在文章里边我提到了PingCap用Rust来写TiDB,这是一个错误。PingCap应该是用Rust来写的TiKV,TiDB的主要开发语言应该是Go.
这篇文章是关于现代数据技术栈中一个相对比较新的产品领域,数据可观测性-Data Observability。在这里会简单的介绍一下什么是数据可观测性以及在海外和国内有哪些公司在做相关的工作。
什么是可观测性?
在讲数据可观测性之前,我们先来简单的介绍一下什么是IT领域的可观测性(Observability)。做过系统的同学们都知道,任何一个线上运行的生产系统,一定会有监控和报警。监控和报警一般是收集系统的运行状态的数据,在系统出现问题或者某些参数超过给定的阈值的时候触发报警,从而能进行及时的干预,从而提高系统的SLA。在企业内部,监控和报警一般是运维团队来负责,系统的SLA的保证也大部分情况下是运维团队的核心KPI之一。
但是随着技术的发展,尤其是近些年云原生和微服务技术的发展,使得系统的相互依赖变得越来越复杂。另外,数据驱动也越来越被企业所认可。在这个背景下,传统的相对粗粒度的数据支撑的监控报警以及不能满足企业数字化驱动的需求。传统运维逐渐的转变为DevOps,而团队的职能也从支撑职能向业务化在演进。除了基础的监控报警,还需要更细粒度数据的对系统各种资源的管理、自动的资源分配、以及分布式追踪技术等等。正式因为这个背景,在大约2018年,可观测性(Observability)被引入到IT领域中。
从维基百科上,可观测性定义为一个系统的内部状态可以通过外部外部输出的知识中可以被推断出的程度。这个词实际上是来自于控制论。更直接来讲,就是如果你知道了一个系统的表现,你有多少能力知道整个系统内部运行的状态。对于现在的IT线上生产系统来讲,引入可观测性之后,系统就不再是一个黑盒子,我可以通过提高系统的可观测性,来更好的让我的系统实现基于数据的问题诊断,自动故障发现,自动恢复等等。这就好比一个人我有日常收集到各种身体数据,生病时有了症状我可以根据数据发现身体哪一部分有问题,而日常我也可以根据数据的变化预测身体是否快要生病,是否需要预先干预。
可观测性一共分为五级,如下图:
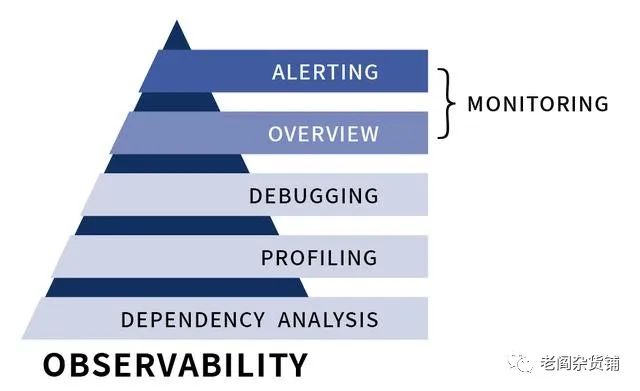
而要实现可观测性,则需要如下三个核心的能力:
日志(Logs)
分布式追踪(Distributed Tracing)
指标(Metrix)
数据可观测性
前面简单介绍了一下可观测性的概念,现在我们再来看看数据可观测性。阅读过前面关于现代数据技术栈相关文章的内容的朋友们应该都了解,对于现代的数据处理系统来讲。一般的过程是不同的SaaS业务系统产生数据,然后通过数据集成服务(Fivetran, Airbyte等)把数据接入到云端的数据仓库CDW。然后企业在根据业务的需要,利用dbt等来生成自己的数据处理流程,这些数据处理流程被调度执行,结果可能再写回到CDW或者通过反向ETL写入到业务系统。如下图:
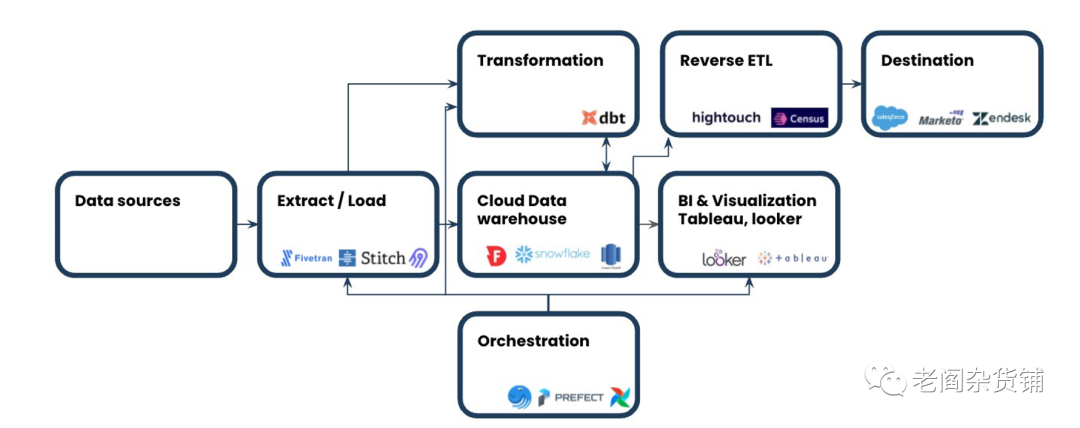
我们可以看到,在实际的生产环境中,数据从获取到最终被使用,经过了多个不同的环节。数据驱动最核心的目标是利用处理后的数据做决策和驱动业务,但是一个复杂的分布式系统中,任何一个地方的小的问题,都会影响到最终的结果,进而就会影响到决策。而当结果数据出现异常的时候,大家往往会问是数据处理系统中的流程出了问题?数据质量出了问题?还是业务出了问题?对于任何一个数据系统的使用者来讲,这是经常发生的情况。在我带领数据团队的时候,这也是一个经常困扰我的问题。数据可观测性就是针对这个场景提出来的对数据系统的可观测能力进行评估的一个方法。从定义上讲,数据可观测性是一个组织或者企业了解它的数据系统的健康情况,通过结果反推出数据系统中系统或者数据问题的能力的。类似于软件系统的可观测性一样,数据系统的可观测性也有自己几个核心的评估方面:
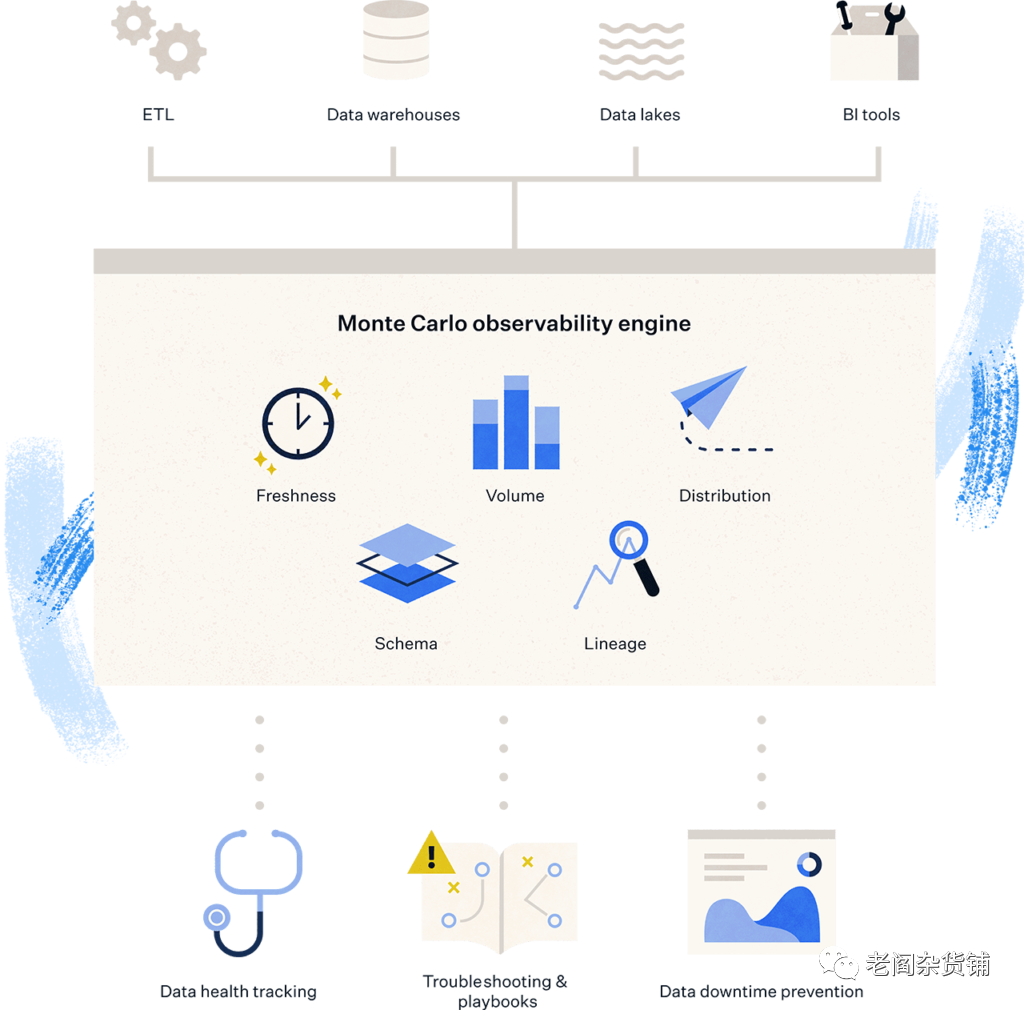
新鲜度(Freshness) - 数据是否即时的被获取和处理
分布(Distribution) - 数据值的分布是否异常
数据量(Volumn) - 数据量是否有显著的异常变化
模式(Schema) - 表的数据结构是否发生了变化
血缘(Lineage) - 数据的血缘和世系是否有变化,是否有问题节点
数据可观测性的公司
Monte Carlo Data公司
2019年5月 种子轮 Accel
2020年9月 A轮1600万美金 Accel
2021年2月 B轮2500万美金 GGV, Redpoint
2021年8月 C轮6000万美金 ICONIQ Growth,Salesforce Venture
Monte Carlo Data是基于现代数据技术栈提供数据可观测性产品的公司。公司的CEO Barr Moses是一位女CEO,创立公司之前曾经在以色列空军,贝恩资本工作过,并且是毕业于斯坦福的高材生。另一位创始人Lior Gavish则毕业于特拉维夫大学,曾经作为产品负责人创立过一家公司Sookasa。公司的数据可观测性产品平台通过在收集在客户云端数据处理系统的数据,帮助客户及时发现数据相关的问题,降低宕机的时间,从而提高企业对数据的信任程度。如下是Monte Garlo Data的数据可观测性平台的简单的示意图:
2020年5月 种子轮 600万美金 Costanoa Ventures,Point72
2021年4月 A轮 1700万美金 Sequoia Capital
2021年9月 B轮 4500万美金 Coatue
Bigeye同样是一家成立于旧金山的数据可观测性公司,CEO Kyle Kirwan在创立Bigeye之前曾经在Uber做产品经理。另一位创始人Egor Grayznov则曾经在Uber做工程师,显然两位创始人曾经是同事,然后一起从Uber出来创业。
从产品形态上看,Bigeye公司把整个数据可观测性平台拆成了几个不同的模块,分别是:
Automatrics
Autothresholds
Issues
Dashboard
Deltas
Integrations
从产品的重心描述看,Bigeye更注重数据质量的监控。具体到产品的销售模式,Bigeye在官网有Pricing,但是没有真正的价格显示,只是提供了自己的报价方式,如下图:
可以理解Bigeye的商业化也是在探索过程中,因此也没有形成自己的相对完整的定价标准。
目前Bigeye的客户包括:Instacart,clubhouse,udacity,crux等等
Datafold公司
-成立时间:2020年
-创始人:Alex Morozov, Gleb Mezhanskiy
-所在地:旧金山
-人员规模:小于20人
-融资规模:2220万美金
2020年5月 Pre-seed 12.5万美金 YC孵化器
2020年11月 种子轮 210万美金 New Enterprise Associate
2021年11月 A轮 2000万美金 NEA, Amplify
Datafold成立的时间比MC Data和Bigeye都要晚一些,公司的CEO同时也是创始人Gleb Mezhanskiy曾经在Lyft, Autodesk从事数据科学、数据工程、产品经理等等公司。公司的目标是打造数据可靠性平台。针对数据可靠性,公司有四个产品,分别是:
Data Diff - 应用于数据流水线的回归测试
Column-Level Lineage - 数据的血缘关系
Data Monitoring - 利用AI/ML自动发现数据异常
Data Catalog - 数据目录
通过这四个产品,就可以完整的覆盖数据可观测性所需要的所有的能力。从Datafold的官方文档看,Datafold已经与现代数据技术栈中主要的产品做了集成和对接。从其官网报价看,包含Cloud版本和Enterprise版本,但是由于是更晚出来的产品,真实价格都需要电话沟通获取。估计很多价格策略都还在实验验证阶段。
Databand公司
-成立时间:2018
-创始人:Evgeny Shulman, Joshua Benamram, Victor Shafran
-所在地:以色列特拉维夫
-融资规模:1450万美金
2020年12月 A轮融资1450万 Accel领投
Databand公司是一家在以色列特拉维夫成立的数据可观测性平台公司,与前面几家不同,这家公司采用的是open core,然后云端商业化的方式。公司开源了dbnd这个数据流水线跟踪的框架,使用者可以采用这个框架去收集pipeline运行的状态。整个开源代码是用python来实现的。目前看,这个开源框架的热度一般,有211颗星,21个贡献者。
从集成能力看,databand已经和Snowflake, Spark, Redshift, Bigquery等主流数据仓库做了对接,并且已经对接了Airflow这个data pipelin引擎。但是对现代数据技术栈的其他的产品并没有做对接,不在美国本土让这个团队对现代数据技术栈的敏感度似乎有所欠缺。
从商业化看,Databind的商业化应该是几家公司中更成熟的一个,官网的报价也比较符合云端产品的报价特点,只是没有Free版本,有Growth版本,Pro版本和Enterprise版本。Growth版本每个月500美金,Pro版本则需要联系销售。相比另外几家公司来讲,Databind的官网也更整洁和具有一定的科技范。
总结
在一月初跟郭炜郭大侠关于数据领域的一些问题和机会曾经非常深入的进行过一些探讨和交流。2020年Snowflake的上市以及去年Databricks的大额融资让大家都看到了云端数据仓库或者说数据湖的未来的机会。于是国内大批的创业团队都打算成为中国的Snowflake或者Databricks。但是在数据技术这个领域,除了数据仓库(数据湖)、数据库,在云上还有很多周边的数据工具需要去用创新的思路和方式进行实现。郭大侠决心做dataops就是一个很好的方向,数据可观测性就是dataops中非常重要的一个能力。只要有耐心,让用户能够体验到工具带来的效率的提升,相信时间会给出答案。另外,2B的业务很难靠资本快速催熟,我们可以看到海外这些公司能够拿到大额的融资,但是公司还是维持一个较小的规模,耐心打磨产品,通过用户口碑传播,最终在爆发期能够实现超过线性的增长,从而带来更丰厚的资本回报。
