




最近跟一个同样在创业的师弟微信聊起来现代数据技术栈,不约而同的提起了一个现代数据技术栈公司-Materialize。这个公司在2019年初刚刚成立,到2021年9月份完成C轮融资,总融资规模已经达到1亿美金。在前面几期翻译的关于现代数据技术栈的文章中,dbt的CEO和Continual的Jordan Volz也都提到了这家公司。现在我们就来了解一下这家正在向独角兽迈进的公司的情况。
Materialize基本情况
公司:Materialize
成立时间:2019年2月
创始人:Arjun Narayan , Frank McSherry
产品:支持SQL的流式分析数据库
融资情况:
2019年3月初 A轮融资850万美金 Lightspeed Ventures领投
2020年11月底 B轮融资3200万美金 Kleiner Perkins领投
2021年9月底 C轮融资6000万美金 Redpoint领投
人员规模:约50人
Materialize发展历史
Materialize的创始人&CEO-Arjun Narayan在创立Materialize之前的时候在小强数据库(CocroachDB)的研发公司Cocroach Labs担任软件工程师职务。2019年3月开始创业创立Materialize公司。另外一位联合创始人Frank McSherry曾经在微软研究院工作,是差分隐私技术的联合发明人之一。具体到什么是差分隐私技术,将来我可能会专门写一篇关于数据安全公司相关的文章,再做介绍。Frank也因为差分隐私技术相关的论文获得了杰出论文的Gödel Prize。多说一句,Arjun是宾夕法尼亚大学的博士,Frank是华盛顿大学的博士。两位创始人妥妥的学霸人设!
之所以创立Materialize是创始人发现当时的现代数据技术栈基本上是围绕云端数据仓库创立的以离线批量数据处理为基础的相关技术。但是随着数据使用的深入,越来越多的基于流式数据进行实时数据处理的需求越来越强烈,而当前的流式处理方案一般都需要比较重的工程师的开发和运维投入,对于很多企业来讲,无论时间周期还是成本代价都不是一般企业能够承受的。因此决定开发一套基于SQL的,更简单易用的流式处理平台,这就是Materialize的来历。
2020.2 Materialize的第一个版本V0.1版本发布,并且将代码放到了github上进行了开源。
2021.1 Materialize的V0.6版本发布
2021.8 Materialize的V0.9版本发布
2021.9 Materialize的云版本开始公测
2021.11 Materialize的V0.10版本发布,Materialize重新规划发布版本体系
从Materialize官方博客的发布节奏看,Materialize版本发布的速度还是比较快的,基本上两个月一个小版本的发布。
Materialize的技术特点
Materialize的目标是打造一个流式数据的SQL平台,那么它有什么样的技术特点?与主打流式计算的Flink以及Kafka研发团队做的KSQLDB又有什么区别呢?
下图是Materialize的技术架构图:
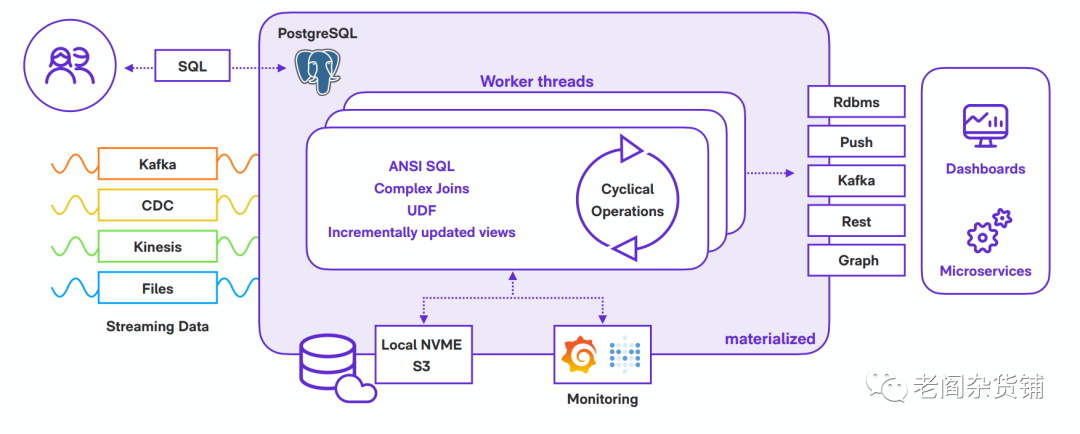
从Materialize的文档看,它的实现是基于两个基础技术:Timely Dataflow和Differential Dataflow. 这两个基本技术从2013年就开始开发,并且已经在不少世界500强在部署使用。
Timely Dataflow在大约2014年底在github上开源,是一套低延时的循环数据流计算模型,来自于论文"Naiad: a timely dataflow system"。Timely Dataflow为了解决如下的核心问题:
能在一个实时数据流上进行数据处理
在流式数据进行处理时,支持迭代处理
支持在新鲜的数据上进行交互式查询,并且获取一致性结果
当时的流式系统只能解决实时性处理问题,但是不支持迭代,比如Storm。批量系统能比较好的处理迭代性计算的需求,但是延时太长。而在流式计算上增加trigger的方法虽然能支持迭代计算,但是只有弱一致性保障。
Timely Dataflow为了解决这个问题,设计了一个新的计算模型,这个计算模型包含如下的特点:
在数据流中允许数据反馈的结构化环
有状态的数据流顶点(图算法中的点的概念),可以消费和生成数据
一个数据流顶点在一个给定的输入或者迭代周期内收到所有的记录后发送通知
论文中这些特点的描述比较晦涩,我做个相对简化的阐述:为了解决前面提到的几个需求,Timely Dataflolw在数据流处理的时候引入了有方向同时可以有环的图(相对照的是一般数据加工流程是有向无环图DAG)。在引入有向有环图的同时,加上通知机制以及时间戳,就可以比较好的支持前面提到的需求。有兴趣深入了解论文细节的同学,可以从网上搜一下Naiad的论文来看。论文的主要贡献者来自于微软。
而为了在工程上真正能够实现Timely Dataflow的高性能,这个开源项目采用了Rust语言进行编写。国内的数据库当红明星PingCap就是用Rust来编写自己的TiDB的。另外,Timely Dataflow这个项目的核心贡献者就是Materialize的联合创始人-Frank McSherry,下图这位老兄
看了一下,去年这位老兄在开源上有691次贡献,真是活跃和高产:
在前面提到了Materialize是基于Timely Dataflow和Differential Dataflow,我们已经简单介绍了Timely Dataflow,那么Differential Dataflow又是什么呢?
Differential Dataflow是在Timely Dataflow的基础上实现的一套支持高并发,低延时以及高吞吐率的编程框架。Timely Dataflow这个编程模型可以很好的解决传统的流式或者批式数据都解决不好的功能性问题,而Differential Dataflow则是将Timely Dataflow并行化,从而使得整套系统成为能够支持大数据的系统。Differential Dataflow的操作原语基本上就是我们比较熟知的数据处理操作,比如map, count, distinct等等。
实际上提到大数据的流式计算,我脑子里最早想到的一定是Flink。我在大约2015年的时候,由于我们团队有些流式处理的需求,而当时在使用Spark的Spark Streaming并不是特别好用,我自己和团队的工程师对Flink进行过一些调研,后来在线上的统计分析系统中,将Flink应用到了我们的流数据处理当中。后来2016年,我去参加Oreilly Data Summit, 还见到了Flink的CTO,跟他聊Flink对SQL支持的一些看法以及他们的计划。当时我总体感觉Flink应该是一个非常有前途的技术,毕竟他们实时流式数据为先的理念更代表了未来。只是没想到在2019年初阿里巴巴9000万美金全资收购了Flink的母公司Data Artisans。
从技术上来讲,Flink的底层抽象概念是有状态实时数据流,然后基于这个概念进行了DataStream和DataSet API的封装。从概念视角看,Flink和Spark类似,都是先从数据进行抽象。Flink是一条一条的数据处理的概念(Stateful Data Steam),而Spark则是一块一块数据的概念(Resilient Distributed Dataset),有了数据抽象,再根据自己解决的问题域去做架构和设计,比如Flink通过DataSet API来解决机器学习的问题。
相比Flink来讲,Materialize依赖的Timely Dataflow则是从数据流本身的计算约束支持出发来进行设计,底层先抽象了数据流的计算模型。引入有向有环图来保证迭代型计算等等场景,然后再在上层封装不同的API。Materialize把自己定位为一个支持SQL的流式数据库,而目前Flink更多的是作为一个流式计算框架在使用。当然,最新Flink Forward的大会中,Flink正在做的也是流式数据仓库,这应该也是目前的趋势。
再来简单看一下ksqlDB - Confluent公司开源的流式数据库。提到Confluent公司,大家都知道Kafka。Kafka基本上已经变成了在互联网行业的事实消息总线的不二之选,虽然有Apache Pulsor在追赶,但是Kafka的地位目前还是比较稳固的。ksqlDB是基于Kafka的实时数据仓库,它的核心理念是既然kafka已经是目前基本事实上的消息总线,实际上可以理解为流式数据的数据库了。只不过过去的方式是Kafka对接的消费者要么是流式的数据计算和处理,要么就是直接把数据做转换放入到数据仓库中。由于目前对于流式数据实时计算分析的需求越来越强烈,Confluent决定自己在Kafka上实现一个支持SQL的查询引擎,这就是ksqlDB。ksqlDB从能力上来讲,支持在kafka这个存储上进行SQL的查询,从而使得用户不再需要一个新的基于实时流式数据的技术组件就能满足实时数据处理相关的需求,并且只要会用SQL就能完成相关的工作,大幅度降低使用的成本。对比Materialize,ksqlDB也是解决流式数据上进行SQL查询到需求,只不过因为自己有广泛的kafka用户基础,直接在已有的产品上做了新的扩展。
Materialize的商业化
Materialize作为一个新型数据库,算是Infra方面的产品。最近几年MongoDB, Confluent, Elastic等公司在Infra层面走出了一条成功的道路,就是open core,但是云端服务收费的模式。而这几家公司目前也都在百亿美金市值规模,并且年收入的增长也很漂亮。正是因为看到了这几家公司的成功,Materialize也采用了类似的路径,就是open core来打造产品和做社区影响力,然后通过cloud服务来获取营收。目前Materialize在github上已经有3400颗星,并且有70个社区贡献者。Materialize的license比较有意思,是BSL(Business Source License)。这个License最早应该是来自于MarialDB,是一种延迟开源模式。源代码在到期之前,单节点服务可以使用,但是不能做集群,不能做为公开可以提供的数据库服务(不能提供云服务)。 从这个license可以看出,Materialize的开源基本上是让企业可以把玩,但是要真正的生产使用,就只能花钱了。
总结
基于实时流式数据的场景进行分析,预测和决策无疑是数据使用到今天的趋势,这也是为什么Materialize能够获得资本认可的原因。不过在这个赛道上,Materialize还需要更多的客户的使用来获得证明。毕竟这个领域的玩家不少,有我们提到的Flink, ksqlDB,也有同样是初创公司的Rockset。而云端数仓的老大Snowflake以及蠢蠢欲动挑战Snowflake的Databricks也在加紧构建自己实时的能力。让我们拭目以待,看看谁能成为这个领域的王者。
