




前言:
在现代数据技术栈的未来(一)我们翻译了来自Continual的Jordan Volz的关于现代数据技术栈展望的文章的上半部分,今天继续剩下部分的翻译。
现代数据技术栈 V2.0
在现代数据技术栈成长到今天这个时候,我相信如下的几个关键领域的创新正在成熟:
人工智能
数据分享
数据治理
流式计算
应用服务
这些代表了许多从现有用例中自然地演变而来的许多新的用例,更具备企业市场支持能力,并且使得平台能抵御对于未来的不可避免的颠覆者的影响。我们将在下面依次对这些领域进行讨论。
01
人工智能

任何在过去十年从事数据科学相关的工作的人都可能熟悉"Data Science Hierarchy of Needs", 它如下图所示:
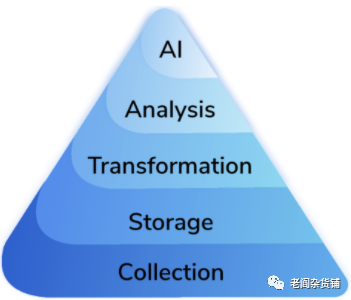
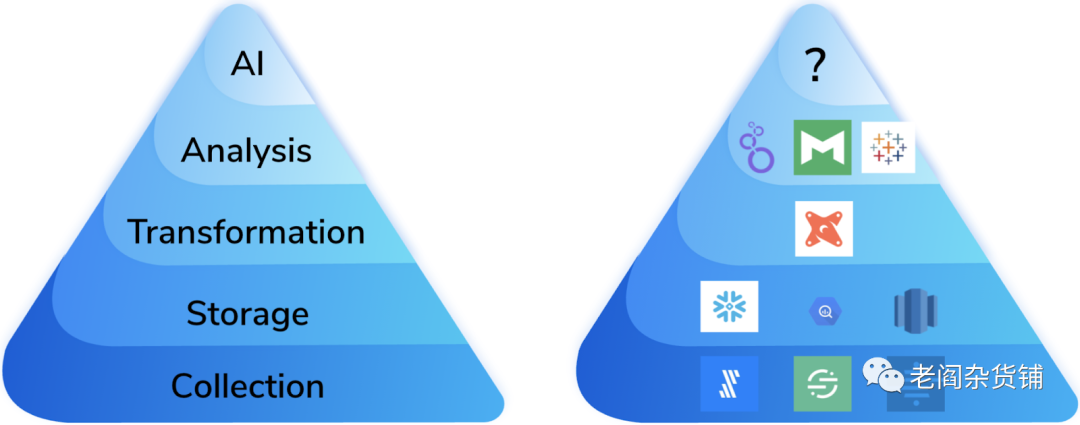
对于初学者:这里想说明的是每个步骤都建立在它下面的步骤之上,该图说明了达到甚至可以开始解决 AI 问题的所需要的依赖。如果一家公司没有一个很好的数据收集、存储以及修改数据的规划,那么任何数据科学项目在开始之前就注定失败,因为它所依赖的基础正在迅速转变。对于现代数据技术栈,图表的前四层完美地描述了入门所需的工具,我们只缺少 AI 层:
对于许多业务来讲,AI代表了巨大的增长机会。我们相信到 2030 年,几乎每个行业的领先公司都将把在整个企业中启用人工智能作为优先考量的事情。然而,不乏文章哀叹普通公司未能将他们的数据科学工作投入到有意义的生产环境中。正如安德森·霍洛维茨 (Andreesson Horowitz) 的这张图所表明的那样,这个问题并没有随着时间都推移变得更容易做到。
那么为什么现代数据技术栈是一个人工智能的理想平台呢?我们计划在以后的文章中详细的介绍这一点。重要的是现代数据技术栈是一个新型AI平台的一个重要的着陆点,这个AI平台是一个声明式的数据优先的AI平台,能够大幅度的简化操作AI的复杂度。我们在Continual一直在构建这么一个平台,并且我们相信这将是企业未来选择执行 AI 用例的主要方式。这种数据优先的方法由 Apple (Overton) 和 Uber (Ludwig) 等公司开创,它们提供了一种不同于传统的以pipeline或模型为中心的机器学习平台的使用AI的方法。数据优先的系统优先考虑AI的自动化和可操作性,大大减少了构建和维护新用例并将其投入生产所需的时间。
Michael Kaminsky 去年写了一篇很棒的博客,介绍了现代数据科学技术栈的样子,我们相信这些大部分都在一个声明式系统里做了充分的实现。对于公司而言,人工智能代表了如此巨大的增长方向,如果没有该领域的创新,现代数据堆技术栈将难以与这个方向进行关联。与此同时,传统机器学习系统既不符合现代数据技术栈的主要原则,同时也证明它们很快就会淹没在复杂性中。我们相信一批新的AI平台提供者正在试用更易于操作和健壮的平台来颠覆AI领域。要详细了解我们在现代数据技术栈上对 AI 的愿景,请参阅我们的博客。

译者:
现代数据技术栈的核心是围绕着云端数据仓库构建的,因此天然适合分析。但是数据使用发展到今天这个阶段,基于数据做预测无疑是更具备价值的事情,而且AI/ML都是强依赖数据的。有了现代数据技术栈能够把数据集中准备好,补全AI能力是一个自然而然要发生的事情。
02
数据共享(数据即服务)
Census和Hightough公司给客户提供宝贵的服务,使得用户能轻松快速的把数据从他们的云端数仓搬移到需要数据的下游应用当中。对于许多用例来讲,这是非常关键的,如果没有专门构建的工具,公司将不得不编写难以维护和实施的自定义的集成脚本或者定制工具。
在这里,公司还有另外一个用例:共享数据。也许这就像维持一个产品描述数据库一样简单,分销商可以在他们自己的网站上访问和使用。在今天,对数据的访问可能是作为 API 提供的,这就需要工程工作来设置和维护,对于使用 API 的每个公司也是如此。在现代云时代,为什么不简单地将这个数据库提供给同一平台上的其他人呢?这就是 Snowflake 数据市场背后的想法。Databricks 最近还宣布了 Delta Sharing,旨在实现类似的目标。通过直接在数据平台中提供对数据的访问,这些公司将数据集成需求降低到零,用户可以立即使数据在他们自己的组织中可以被使用。
这些解决方案非常适合与您在同一数据平台上的客户。但实际上,您可能会与采用各种平台提供商工作的公司进行互动。如果有一个工具可以代理您去访问您在不同平台上的数据,并使您可以轻松上传和管理数据集,那就太好了。从历史上看,这些数据即服务公司一直专注于自动化构建供外部使用的 API。但随着现代数据技术栈的兴起,我们可以想象一个对于工作在每个原生共享机制的平台上的新的需求,充分利用这些平台提供的内生选项。
译者:
一直有一个说法,数据只有被分享和能流动才能产生更大的价值。在企业内部,如果有了一个居中的CDW,不同业务团队必然有更多的使用数据的诉求。企业间在解决数据隐私安全的前提下,也有分享数据的要求,因此数据分享的确是一个非常重要的需求。但是如何解决数据安全,本文并没有提及。以我个人的经验,数据安全也是现代数据技术栈中需要创新和发展到关键的技术。
03
数据治理
回到让现代数据技术栈能够服务大型企业这个话题:数据治理的重要性再怎么强调都不为过。一些公司有如此多的数据集,如果没有数据治理工具,几乎不可能跟踪和理解他们的数据。这是一个单个的个体会经常忽略的问题-与公司总体的数据视图相比,一个人的视野通常会比较有限。但是优秀的数据领导者会始终如一的强调好的数据治理工具的重要性,这些工具通常涵盖数据发现、数据可观测性、数据目录、数据血缘以及审计等等。
没有良好的数据治理工具,对于大型企业及其庞杂的数据来讲,现代数据技术栈通常会显得非常对混乱和笨拙。数据治理使得组织的数据更有秩序,并且经常能打破自然生成的障碍从而使得数据发现和协同真正成为可能。
大型企业可能会继续的采用多个云服务提供商提供服务这种方式,这意味着提供跨数据平台的源数据工具将会提供巨大的ROI并且能够非常好的与云平台供应商自己提供的任何类似工具进行竞争。
在现在数据技术栈为背景的基础上,有不少公司在尝试解决这个问题。尽管这场竞赛还远未结束,但是有一些供应商表现出了巨大他的前景:Monte Carlo Data, Stemma以及Metaplance。
译者:
数据治理是个老生常谈的话题,从传统数据仓库时代就有相关的概念。不过现代数据技术栈的采纳使得数据的使用更便利,从而就会造成更多的混乱。我自己在2016年带数据团队的时候就遇到了这个问题。当时内部也做过关于数据治理工具的不同的讨论,也调研过不同的数据治理工具。实际上,我个人认为AI技术在现代数据技术栈上可以很好的帮助数据治理工具,期待这方面的进展。
04
流式处理
流式数据处理和计算确实是云数据仓库的圣杯。当与现代数据技术栈的用户进行讨论时,我在询问实时场景用例时得到的最常见回答是:“我们甚至都没办法理解什么是实时。” 但是,我们不可避免的会承认如果让普通公司都可以非常容易的使用到实时能力,是非常惊人的。如果 CDW 供应商能够令人信服地提供对数据的实时访问,那么对于许多公司来说,这可能会改变游戏规则。
然而,随着公司在他们的数据用例中取得进展,他们将不可避免地需要在流数据上执行一些用例。也许不是今天,也许不是明天,但最终我们会达到这样的地步,无法处理流数据的公司将输给能够处理的公司。因此,我们再次处于岔路口,现代数据技术栈要么提供与其他技术完美搭配的优雅解决方案,要么迫使客户切换平台。而切换平台无疑会侵蚀人们对现代数据技术栈的信心,因此,我们需要找到前进的道路。
与 AI 一样,流式处理用例也往往非常复杂,这为供应商提供了一个很大的机会来简化以 CDW 为中心的用例。当前的流式计算技术似乎假设您要么是软件开发人员,要么是某种时间巫师,而我们确实还没有看到流式处理世界彻底改变了我们使用数据仓库的方式。如果有人能够提供一种解决方案,我不需要考虑基础设施,将我的数据移动到一个新平台,并且可以通过标准 SQL 查询简单可靠地获取实时数据,这将是非常值得大书特书的。
今天,相关流式处理功能已经在不同的供应商的平台中提供:Snowflake有Snowpipe并且暗示了一些新的能力,BigQuery, Redshift以及Snowflake有物化视图(尽管有一些严重的限制); Databricks支持Structured Streaming。除了这些标准的CDW提供商外,Confluent提供ksqlDB, Decodable正在重新设计流式数据工程,Meterialize是一个新定位自己的现代数据技术栈原生的流式计算的公司(通过使用dbt插件)。我不可避免的想看到一个单独的流式处理平台会努力的去适应一个更大的现代数据技术栈,这是完全可能的。
译者:
流式处理和流式计算的重要性实际上并不用过多的阐述。Flink, Databricks的Structured Steaming都已经广为人知。国内做流批一体的技术框架也有不少。PingCap提到的HTAP也是解决OLAP和OLTP问题的技术。但是在海外现代数据技术栈基本上已经形成了一个流派,这些技术如何能融入到现代数据技术栈才是一个真正的考验。或者重新构建一个生态,或者融入一个生态,如果是你,你如何选择呢?
05
应用服务
在现代数据技术栈上我们的愿望清单的最后一项是应用服务。是的,您的数据平台最终会非常的棒,人们会意识到它包含他们写的杀手级应用的所有的数据,并且他们想要在应用中使用这些数据。而这通常是阻碍他们前行的主要障碍。云端数据仓库完全属于OLAP类型,然后实际的应用经常需要高并发和低延迟,这通常是OLTP类型的特性。
对于这个问题,有一些解决方案,比如读写分离。今天的一个明智的做法是把你的数据拷贝到一个适合做应用服务的系统中。Redis或者Cassandra或者Memcached,或者SingleStore等等。同样,我们为新问题引入了一个新平台,然后增加了复杂性和负担。我们希望在现代数据技术栈中有新的创新使得应用服务可以直接使用已经存在的数据。
Netflix使用他们最近创造的一个叫Bulldozer的工具来去处理这一困境,这个工具非常对适合于现在数据技术栈。核心是他们抽象了底层的缓存层,然后实现了一个声明式的工作流去移动数据;因此很容易想象你可以如何把这个工具应用到你所喜欢的CDW让用户去通过简单的一到两次点击就能暂存数据以实现低延时的应用服务。
Snowflake最近通过使用Snowflake Data Cloud来提供数据应用在行业内引起了不小的轰动,因此这可能是他们关注的一个用例,具体详情仍有待观察。
译者:
这一部分实际上和数据即服务类似,只是做成数据应用要考虑一个应用所具备的低延时高并发的问题。以我对技术的了解,Alluxio实际上是一个跨云的缓存加数据编排服务。不知道Alluxio的团队有没有计划去跟现代数据技术栈进行对接融合呢?
接下来会发生什么?
如果您采用了现代数据技术栈,那么接下来几年您将迎来激动人心的创新。一项关键任务将是组装一组同类中最佳的组件,以在降低开发和维护成本的同时推动对业务的影响。在 Continual,我们相信 AI/ML 是下一个在现代数据技术栈中显而易见的重要工作。无论您是进行客户流式预测以实现个性化营销,还是进行需求预测以提高利润,都不需要一堆复杂的pipleline和基础设施来支撑交付。如果这听起来很吸引人,您可以请求提前访问 Continual,看看 AI/ML 在现代数据技术上的表现。
译者:
作为一个在大数据领域的从业者,过去我更多的关注大数据相关技术的发展。海外我关注的大数据技术创业公司最近这些年也都取得了不错的成功。但是现在回想起来,大数据毕竟都是有一定规模的公司才能玩的起来的东西。但是如果能普通企业低成本低门槛的使用数据帮助自己,无疑是更有价值的事情。海外的现代数据技术栈就是应对这个场景而产生的,这不得不说是云计算的胜利。回到商业模式的选择,是从服务巨人入手,还是以服务芸芸众生小企业入手?这是个非常值得思考的问题。
