




拖延症害死人,BDAS开了个头,结果就等到了现在才开始往下续。五一劳动节补上一部分内容吧。
BDAS的技术栈从提出到现在,已经孕育了非常知名的Spark, Alluxio,Mesos,新的技术栈估计在未来会接着孕育出更多的技术性产品出来。我们公司的CEO崔小波同学3月份去硅谷后深有感触的就是硅谷的技术加上中国的商业模式,应该是未来。我作为技术人员,也深以为然。国内的技术在最近10年无疑取得了巨大的进步,不过距离硅谷的跨越式的创新,还有相当的一段路要走。在技术上,我们仍旧是学生,期待再过10年我们的技术的创新能够逐渐追上硅谷,真正的迎来更多原创的技术的革新,而不是Copy to China。现在我们先能够同步了解大洋彼岸的技术的理念,无疑对我们的未来能够创新也是有巨大的帮助,站在巨人的肩膀上,我的自然能够看得更远。
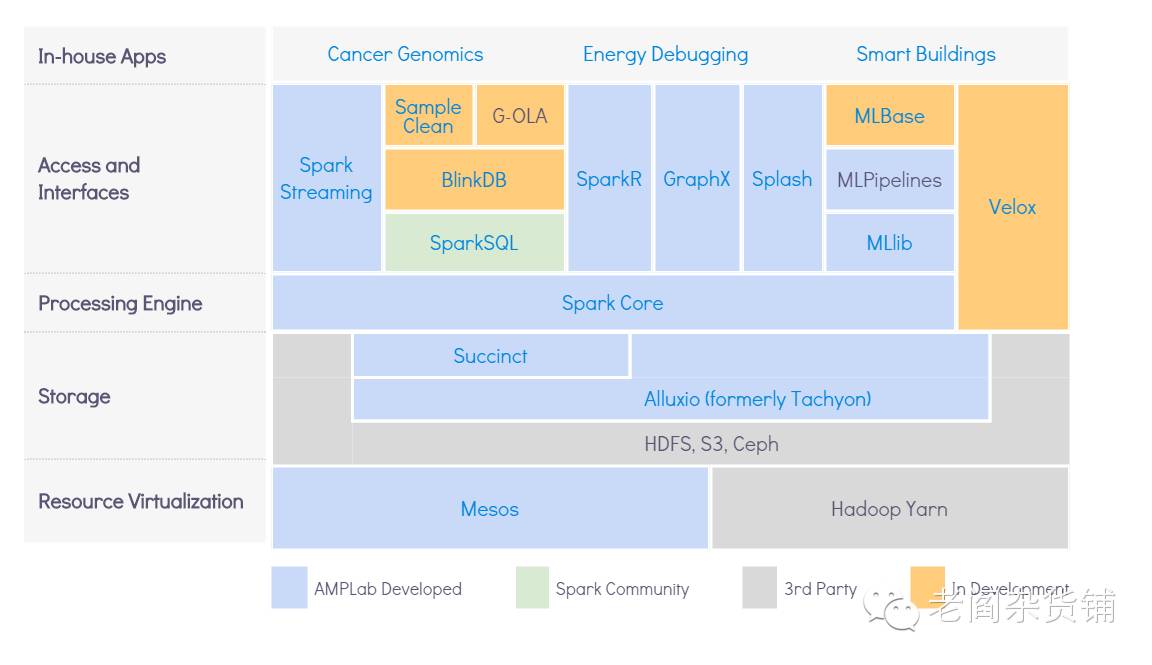
BDAS技术栈之Mesos
Mesos是应该是Berkley在BDAS系列项目中最早的一个项目,来自于2010年的一篇论文《Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center》,目的就是解决在数据中心中细粒度的进行资源控制和共享的问题。实际上真正在做大数据技术的各位同学都会遇到相同的烦恼,就是大数据处理需要很多的机器,可是机器资源如何能够更好、更合理的利用是一个非常令人头疼的事情。Mesos就是为了解决这个问题而产生的,目前是Apache社区的顶级项目,当前的版本是0.28.0。从github上看,整个项目一直比较的活跃,如下图:
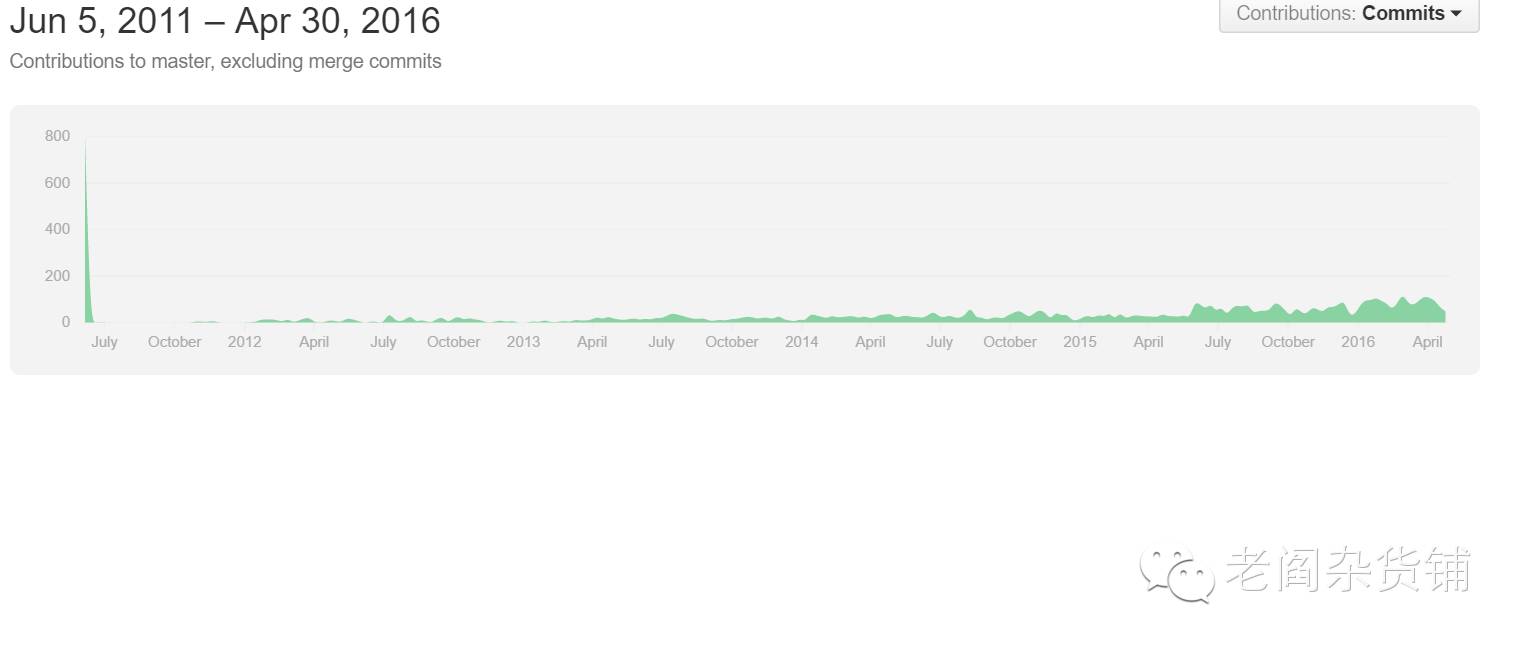
两千多个Star以及800多个fork说明了项目有不错的热度,当然了,这个项目远不能和Spark这个现在业界的宠儿相比。Spark有8000多的Star和7000多的fork。不过,关于Spark,他的产生就是因为要验证Mesos的细粒度资源调度能力而开发的,应该是Mesos的一个副产品(Mesos的论文中有如下描述:“To validate
our hypothesis that specialized frameworks provide
value over general ones, we have also built a new framework
on top of Mesos called Spark, optimized for iterative
jobs where a dataset is reused in many parallel operations, and shown that Spark can outperform Hadoop by
10x in iterative machine learning workloads),结果是Spark变成了真正的一个现象级的产品了。目前Mesos在twitter, airbnb都有不错的使用。
Mesos是采用C++语言开发的,采用类似于Linux Kernel的原理,只不过是在不同层面上做抽象,期望能够使得不同类型的应用(Hadoop MR, Spark, Kafka,Elastic Search, MPI)都能够采用同样的资源管理的调度接口来使用整个数据中心的资源。特点包括:
支持万级别规模的节点
使用ZK来保证容错
支持Docker
利用linux container来隔离任务
多种资源的调度能力(CPU, memory,disk, ports)
多种开发语言API的支持
有Web UI支持集群状态的查看
架构图如下:
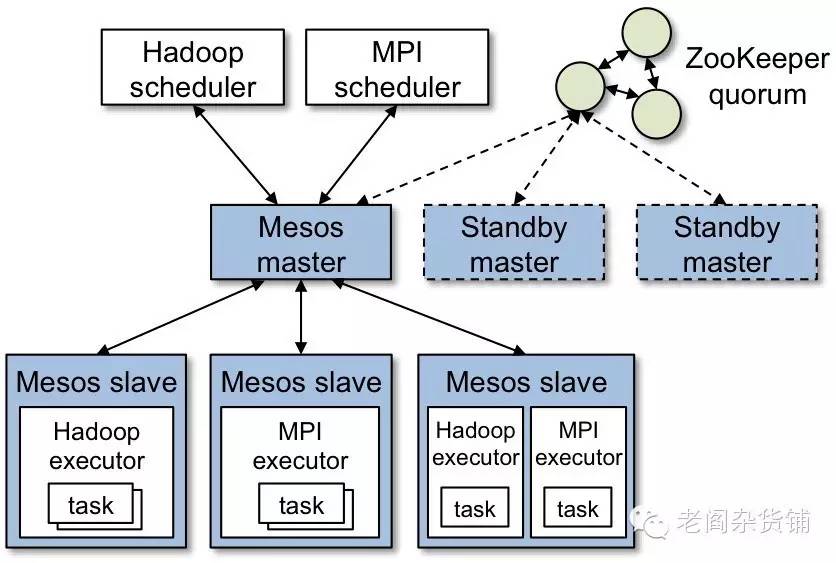
整个架构中,蓝色部分是Mesos的组件,Mesos Master负责接收资源请求者的请求,将任务发送到Mesos Slave中。 Mesos Slave则是真正的资源提供者和任务执行者。Mesos Master通过ZK来实现高可靠性。具体资源调度的过程如下图:
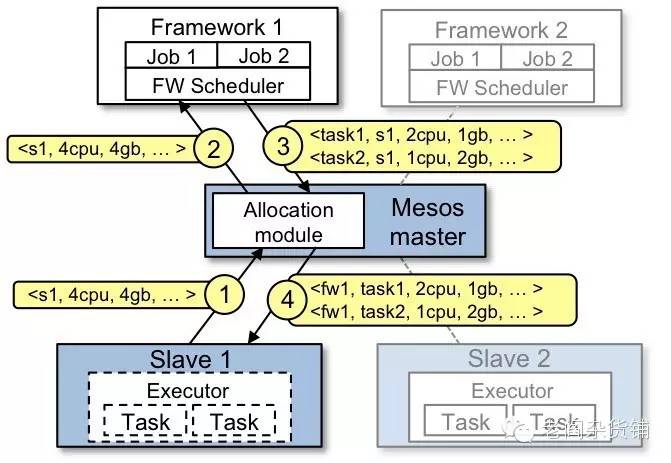
FrameWork是需要请求资源的计算框架,比如前一张图的Hadoop和MPI。资源分配的逻辑非常的容易理解:
1,每个Slave(干活的小组)告诉Master(大队长)我现在有多少资源可以用来干活。Slave 1说我有(4个CPU,4G内存)
2,大队长查了一下自己的小本本,发现需要资源满足客户(Framework 1)的请求。于是告诉Framework 1说,我能够让Slave 1这组人帮你干活,你把活交过来吧。
3,Framework 1于是将两个任务,Task 1(需要2 CPU,1G内存)和Task 2(需要1 CPU, 2G内存)发给Master说你将这俩任务给Salve 1吧。
4,Master将对应的任务转交给Slave 1去执行。
提到Mesos,就不得不提到Hadoop 2.0引入的资源调度框架YARN。真实的情况是,虽然Mesos出现的更早,但是在国内使用YARN的公司却远远多过Mesos。其原因我想主要还是YARN是Hadoop中自带的,社区更为活跃,按照国内技术选择的倾向,活跃的开源产品往往在国内会有更多的人去选择。关于YARN和Mesos的对比的资料,网上有不少。这里不过多的做赘述,有兴趣的可以看一下 https://www.quora.com/How-does-YARN-compare-to-Mesos
不过考虑到docker越来越普及,而多种计算框架共存也会越来越多,因此Mesos估计会有越来越多的选择。
BDAS技术栈之Alluxio
Alluxio很多人看着这个名字会比较奇怪,它实际上是Tachyon最新的名字。提到Tachyon,国内知道的人就比较多了。脱胎于Amplab的这个项目最近两年因为Spark的火热也得到了广泛的关注。另外由于国内的百度、阿里都在采用Alluxio作为分布式内存存储来提高Spark任务的性能,同时核心团队以华人为主,因此Alluxio(Tachyon)在国内有非常高的知名度和关注度。话说,这是为数不多的有完全中文语言文档的开源项目之一,中文文档和英文文档基本都在同步更新。
Alluxio主要处在传统的物理存储和计算框架的中间,如下图:
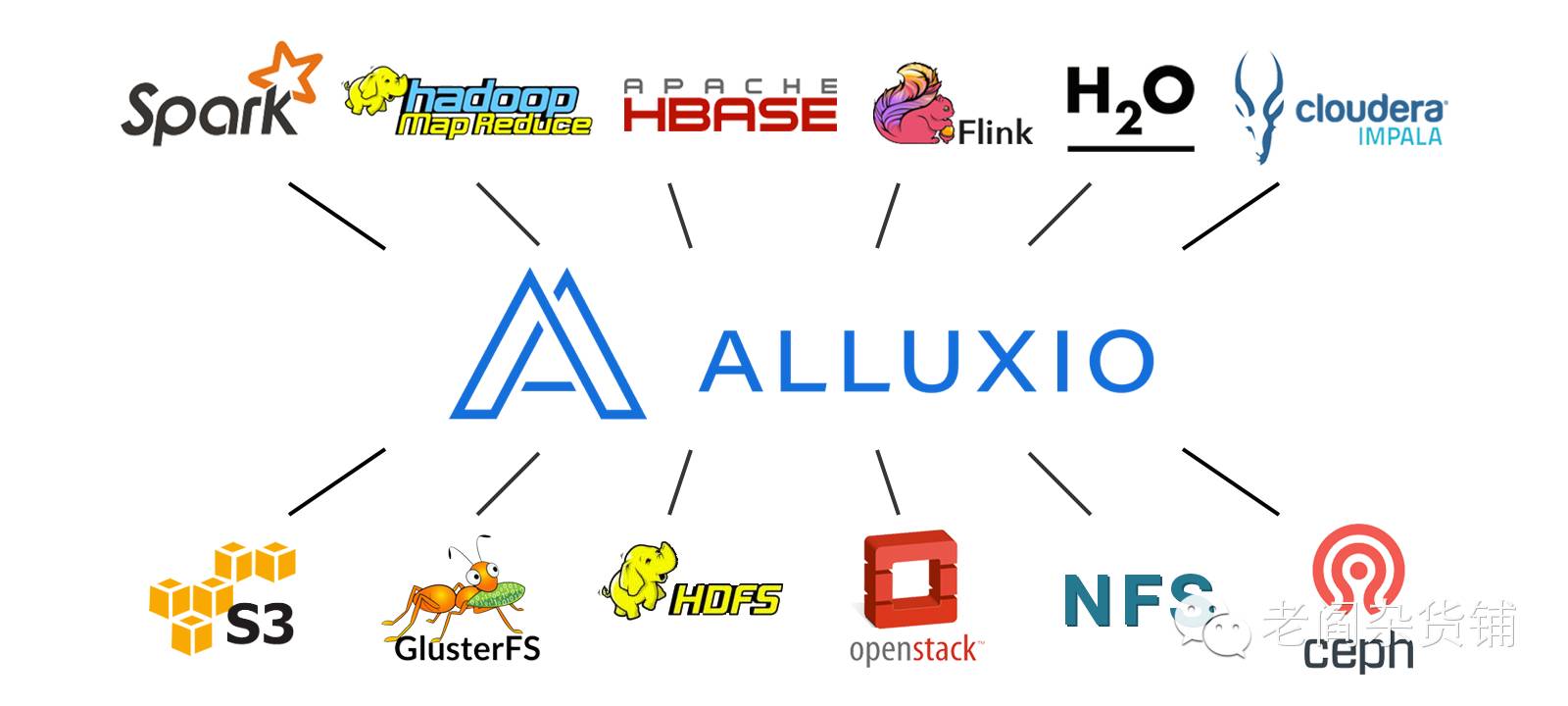
对于大数据来讲,很多的数据实际上是按照时间有热数据、冷数据之分的。数据使用的特点非常适合分层存储,而Alluxio则非常适合数据分层的这个特点。
Alluxio主要的特点是以内存为中心的分布式存储系统。它将底层存储和上层计算应用隔离开,对于访问底层不同存储的不同协议的程序,只需要将协议转变为alluxio:// 就可以非常方便的通过alluxio进行对应的数据读取和存储了。另外由于alluxio本身支持分层存储,程序不需要关注数据是存储在HDFS中还是在内存中。这样MEM, SSD, HDD可以比较方便的被合理的使用起来,通过策略的配置,可以使得数据的访问方便的在不同的层级之间进行切换。
由于交互式数据分析的越来越多的需求,可以预见Alluxio必然会被越来越多的公司采用,从而取得越来越好的发展。
BDAS技术栈之Succinct
Succinct在BDAS技术栈之中也处于存储层,国内知道的人并不多。度娘基本上查不到太多的资料,可见在国内对于很多人这个还是很陌生的一个东西。原因也比较简单,一个是这个项目比较新,2014年才开始。另外由于社区的热度也不够,按照国内的技术氛围,不热的东西一般不太有人关注,大家都不喜欢冒险引入没有经过别人验证的东西。
Succinct是用来解决在压缩的情况下不用解压缩还能够执行高效率的Query的问题。开源项目的地址是 https://github.com/amplab/succinct
整个项目也是来自于一片论文《Succinct: Enabling Queries on Compressed Data》。说一句题外话,美国人很多牛逼的东西都是有一篇比较牛逼的论文,配合着是一个非常牛的实现。国内貌似很少看到论文和技术产品同时有的,这也是差距啊。
具体Succinct的技术原理,实际上是利用了压缩后缀数组(Suffix Array)的一些特点来组织存储,从而能够高效的存储数据并且可以直接在存储结构上进行检索。在实现上,Succinct利用一些采样、斜小波树(Skewed Wavelet Tree)等来达到更高效的压缩。
Succinct Spark则是将Succinct算法在Spark上进行支持,从而使得Spark可以作为文档型的一个存储,类似于ElasticSearch。通过Succinct,Spark可以取得比Elastic Search快2.75倍的查询速度同时节省2.5倍的存储空间(来自于http://succinct.cs.berkeley.edu/wp/wordpress/)。
笔者曾经用Succinct做过一些测试,总的来讲Succinct还不是很成熟,不能够支持中文,如果是英文的日志类型的数据,的确可以取得不错的存储和检索效果。但是对于我们自己的设备ID类型(类似于MD5之后的结果),则存储空间并没有很好的节省。
由于这个项目还处于比较早期,需要持续的关注,由于目前文本检索的需求越来越强烈,而可选的无非就是Solr或者ES,Succinct Spark无疑会给大家提供一个新的选择。
