




GBase8a V95 集群实战演练

经过一个月的学习(GBase 8a MPP Cluster 数据库培训班),为了检验学习成果,加深理解,官方为我们组织了一次实战演练活动。
一、集群的安装
1.1 安装介质
- /opt/GBase8a_MPP_Cluster-License-9.5.2.39-redhat7.3-x86_64.tar.bz2 --安装包(必须)
- /opt/20220315-02.lic --License授权文件
1.2 节点说明
| 节点 | 外网IP | 内网IP | OS |
|---|---|---|---|
| 主节点,节点1 | 118.195.185.192 | 10.206.16.104 | CentOS Linux release 7.6.1810 (Core) |
| 节点2 | 118.195.185.192 | 10.206.16.105 | CentOS Linux release 7.6.1810 (Core) |
1.3 安装步骤
1.3.1 准备安装环境
- 准备节点1
# 创建DBA用户
useradd gbase
# 修改gbase密码,建议所有节点都一样
passwd gbase
# 创建安装目录、并赋权相关目录
mkdir -p /opt/gbase && chown gbase:gbase /opt/gbase
# 解压安装包,会在解压目录下生成gcinstall目录
cd /opt && tar xfj GBase8a_MPP_Cluster-License-9.5.2.39-redhat7.3-x86_64.tar.bz2
# 设置环境变量
cd /opt/gcinstall/ && python SetSysEnv.py --dbaUser=gbase --installPrefix=/opt/gbase --cgroup
# 拷贝配置脚本到其它节点(节点2)
scp /opt/gcinstall/SetSysEnv.py root@10.206.16.105:/opt
- 准备节点2
# 创建DBA用户
useradd gbase
# 修改gbase密码,建议所有节点都一样
passwd gbase
# 创建安装目录、并赋权相关目录
mkdir -p /opt/gbase && chown gbase:gbase /opt/gbase
# 设置环境变量
cd /opt && python SetSysEnv.py --dbaUser=gbase --installPrefix=/opt/gbase --cgroup
1.3.2 安装软件
在主节点上,执行以下操作。
su - gbase
cd /opt/gcinstall/
vi demo.options
./gcinstall.py --silent=demo.options
【demo.options】内容参考以下
installPrefix = /opt/gbase
coordinateHost = 10.206.16.104,10.206.16.105
coordinateHostNodeID = 104,105
dataHost = 10.206.16.104,10.206.16.105
dbaUser = gbase
dbaGroup = gbase
dbaPwd = ‘gbase 账户的密码’
rootPwd = ‘root 账户的密码’
1.3.3 申请和导入授权
在主节点上,执行以下操作。
1.3.3.1 申请license
导出集群各节点的指纹信息并邮件申请license
服务器中已存在license,故跳过该步骤
1.3.3.2 导入授权
su - gbase
cd /opt/gcinstall/
./License -n 10.206.16.104,10.206.16.105 -f /opt/20220315-02.lic -u gbase -p gbase账户的密码
检查授权导入情况:
./chkLicense -n 10.206.16.104,10.206.16.105 -u gbase -p gbase账户的密码
二、集群服务启动及初始化
2.1 启动全部集群服务
在所有节点,执行以下脚本。
su - gbase gcluster_services all start
2.2 初始化集群环境
在主节点,执行以下脚本。
su - gbase
## 设置分片信息
gcadmin distribution /opt/gcinstall/gcChangeInfo.xml p 1 d 1 pattern 1
## 登录,初始密码为空
gccli -uroot -p
## 数据库初始化
gbase> initnodedatamap;
三、创建数据库及表
3.1 创建数据库
create database if not exists GBase8a_zhaozhiguo;
use GBase8a_zhaozhiguo;
执行结果:

3.2 创建表
-- 员工表
drop table if exists Employee;
create table Employee(
id int primary key COMMENT '主键',
name varchar(50) COMMENT '员工姓名',
departmentId int COMMENT 'Department表中ID的外键',
workingAge tinyint COMMENT '工龄'
) COMMENT='员工表';
-- 部门表
drop table if exists Department;
create table Department(
id int primary key COMMENT '主键',
Ename varchar(100) COMMENT '部门英文名称',
Cname varchar(50) COMMENT '部门中文名称'
) COMMENT='部门表';
-- 薪水表
drop table if exists Salary;
create table Salary(
employeeID int NOT NULL COMMENT 'Employee.id',
salary int COMMENT '工资',
yearmonth varchar(6) NOT NULL COMMENT '年月(YYYYMM)'
) COMMENT='薪水表';
执行结果:
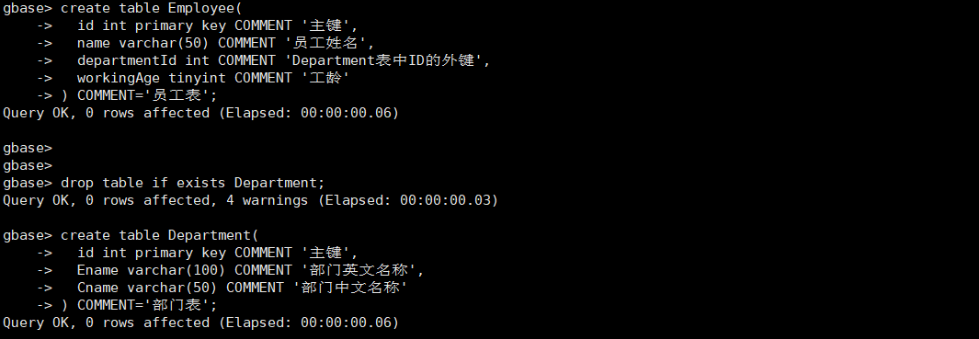

3.3 加载测试数据
将《南大通用2022数据库实战演练活动题目01_测试数据.xls》中的三个sheet页分别另存为:Employee.csv、Department.csv、Salary.csv,并上传至主节点的/home/gbase目录下
特别注意,在winodw下,默认保存的csv为GBK编码。
load data infile 'file://10.206.16.104/home/gbase/Employee.csv' into table Employee character set gbk data_format 3 having lines separator fields terminated by ',' ENCLOSED BY '"';
load data infile 'file://10.206.16.104/home/gbase/Department.csv' into table Department character set gbk data_format 3 having lines separator fields terminated by ',' ENCLOSED BY '"';
load data infile 'file://10.206.16.104/home/gbase/Salary.csv' into table Salary character set gbk data_format 3 having lines separator fields terminated by ',' ENCLOSED BY '"';
执行结果:

四、SQL练习题目
4.1 题目1
将Department.Ename分解为两列,一列是部门简称EnameAbbr,一列是部门全称EnameDetail,分隔符是冒号。分隔后的名称不能有空格。请将结果存入新表department_new中。
解答:
create
table
department_new as select
substring_index( Ename, ':', 1 ) EnameAbbr,
replace(
substring_index( Ename, ':',- 1 ),
' ',
''
) EnameDetail
from
department;
SUBSTRING_INDEX(str,delim,count) :返回字符串 str 中在第 count 个分隔符 delim 之前的子串。
执行结果:

4.2 题目2
列出各部门员工工龄段。
解答:
select
d.Cname,
e.name,
e.workingAge,
case
when e.workingAge <= 5 then '1~5年'
when e.workingAge <= 10 then '6~10年'
else '10年以上'
end 工龄段
from
department d,
employee e
where
d.id = e.departmentId;
语法参考:CASE WHEN [condition] THEN result [WHEN [condition] THEN result …]
[ELSE result] END
执行结果:

分别统计各部门员工工龄(1~5年)、工龄(6~10年)、工龄(大于10年)的数量。
解答:
select
d.Cname,
sum( case when e.workingAge <= 5 then 1 else 0 end ) '1~5年',
sum( case when e.workingAge > 5 and e.workingAge <= 10 then 1 else 0 end ) '6~10年',
sum( case when e.workingAge > 10 then 1 else 0 end ) '10年以上'
from
department d,
employee e
where
d.id = e.departmentId
group by
d.id,
d.Cname
执行结果:
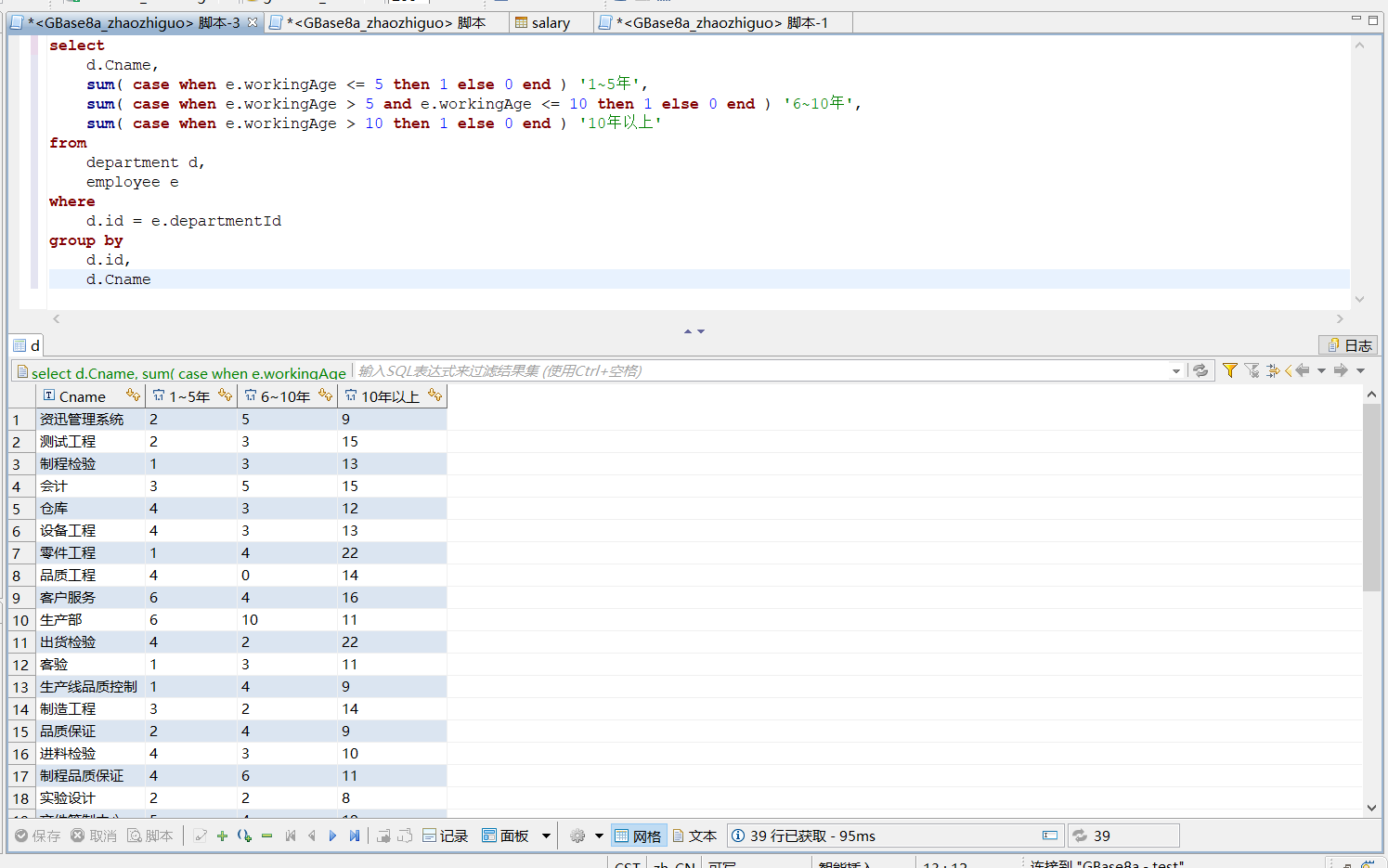
4.3 题目3
列出2021年06月每个部门收入排名前三的员工。结果集为部门名、员工姓名、工资。注意:某部门工资前三名员工数量可能大于或小于3;特例:没有第三高的工资。
解答:
select
d.Cname,
name,
salary
from
(
select
e.departmentid,
e.name,
s.salary,
dense_rank() over(
partition by e.departmentid
order by
s.salary desc
) as ranking
from
employee e,
salary s
where
e.id = s.employeeid
and s.yearmonth = '202106'
) as a,
department d
where
d.id = a.departmentid
and ranking <= 3;
RANK并列跳跃排名,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,跳跃到总共的排名。
DENSE_RANK并列连续排序,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,依然按照连续数字排名。

执行结果:
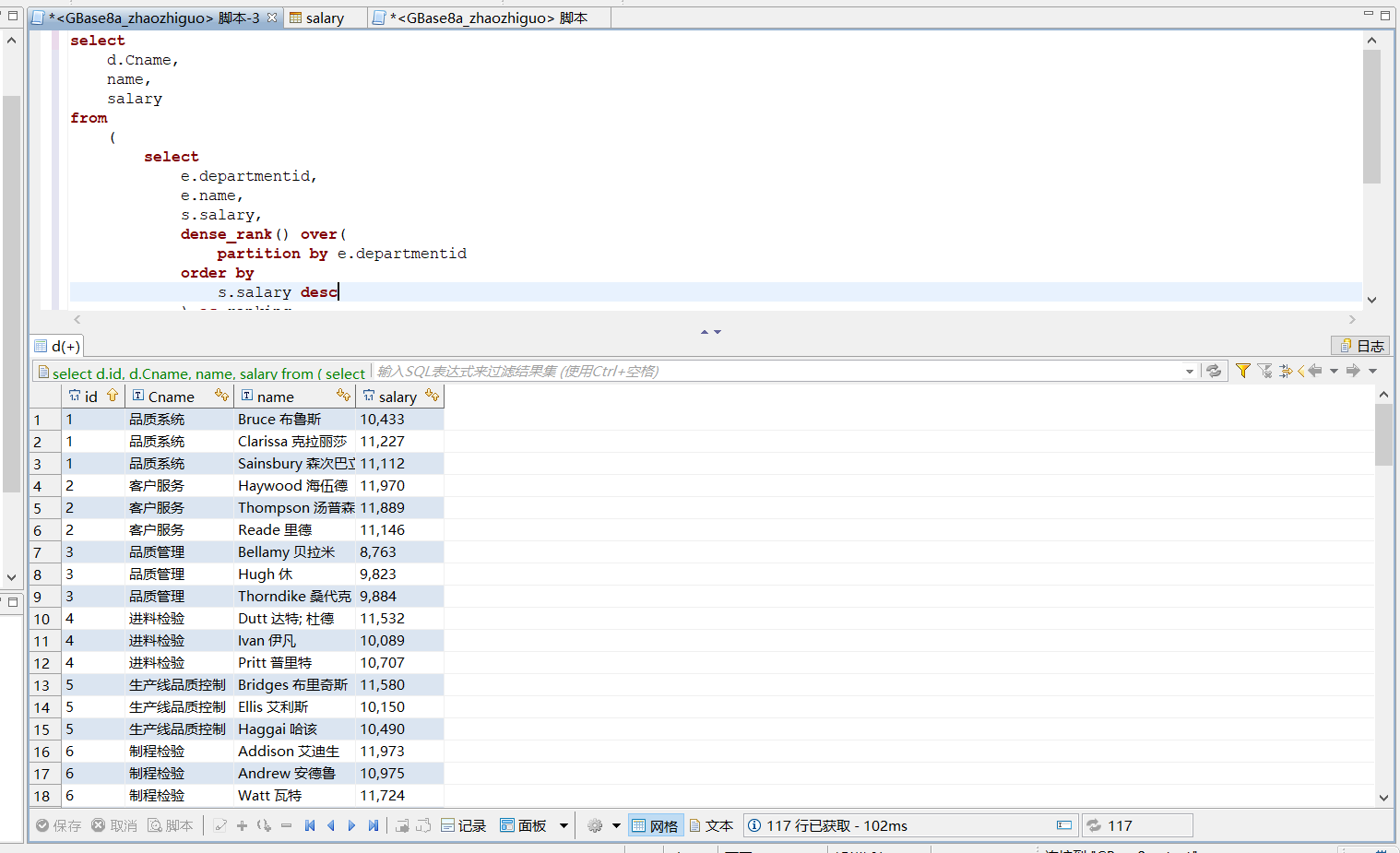
4.4 题目4
统计每月各部门内员工收入在本部门的占比。结果集为:年月、部门、员工姓名、收入在本部门的占比。
解答:
select
s.yearmonth,
d.Cname,
e.name,
concat( round( s.salary / sum( s.salary ) over( partition by s.yearmonth, e.departmentId )* 100.00, 2 ), '%' ) 部门占比
from
employee e,
salary s,
department d
where
e.id = s.employeeID
and d.id = e.departmentId
执行结果:

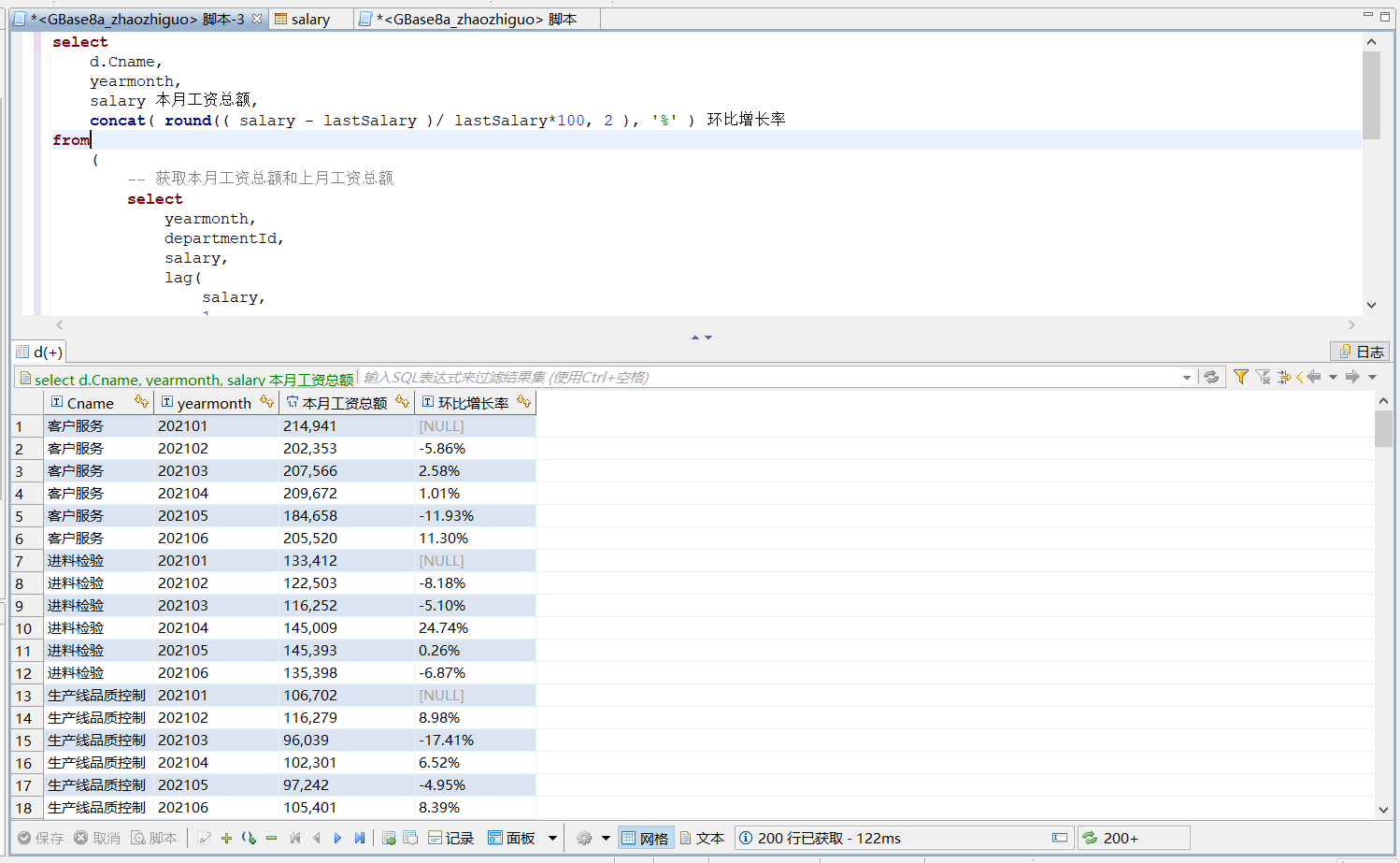
4.5 题目5
统计每个部门总收入每月的环比增长率( (本月-上月)*100%/上月 )。注意202101没有上月的比对数据,所以环比为空。
解答:
select
d.Cname,
yearmonth,
salary 本月工资总额,
concat( round(( salary - lastSalary )/ lastSalary*100, 2 ), '%' ) 环比增长率
from
(
-- 获取本月工资总额和上月工资总额
select
yearmonth,
departmentId,
salary,
lag(
salary,
1
) over(
partition by departmentId
order by
yearmonth
) lastSalary
from
(
-- 各年月各部门汇总工资
select
s.yearmonth,
e.departmentId,
sum( s.salary ) salary
from
employee e,
salary s
where
e.id = s.employeeID
group by
s.yearmonth,
e.departmentId
) t
) t2,
department d
where
t2.departmentId = d.id
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
执行结果:
活动感受
理论结合实践,有效掌握学习到的知识,激发学习兴趣,期待后续的学习…
