





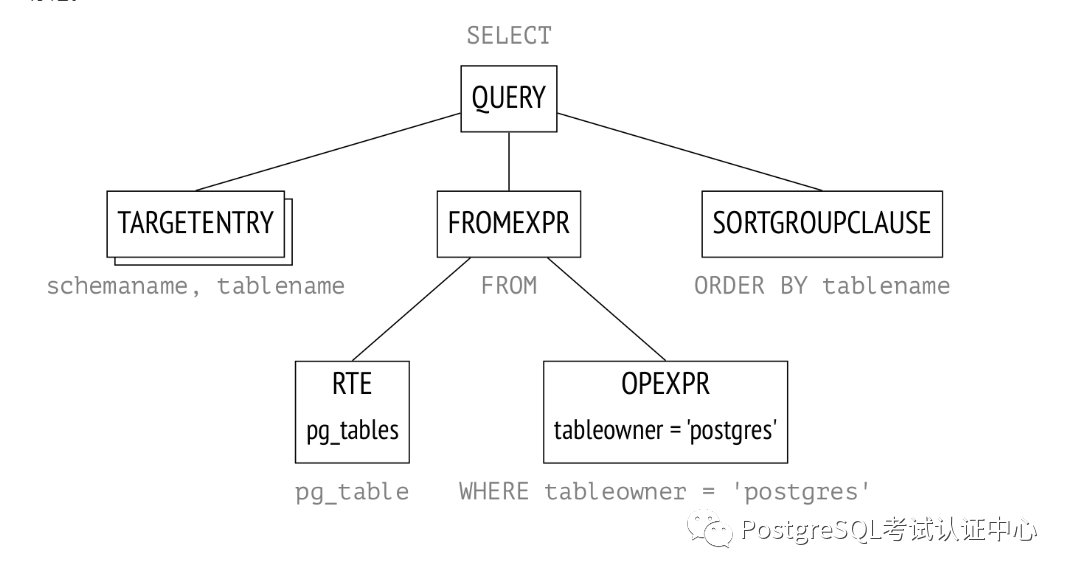
1. 解析
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
2. 转换
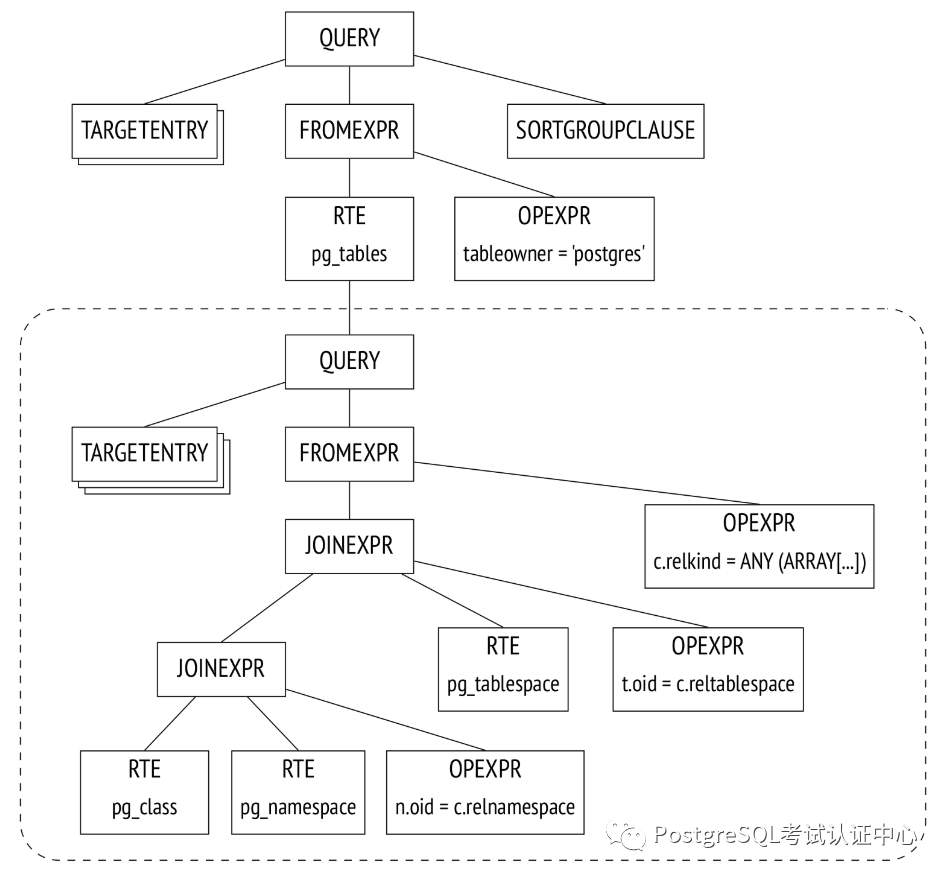
SELECT schemaname, tablename
FROM (
-- pg_tables
SELECT n.nspname AS schemaname,
c.relname AS tablename,
pg_get_userbyid(c.relowner) AS tableowner,
...
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = c.reltablespace
WHERE c.relkind = ANY (ARRAY['r'::char, 'p'::char])
)
WHERE tableowner = 'postgres'
ORDER BY tablename;
3. 计划
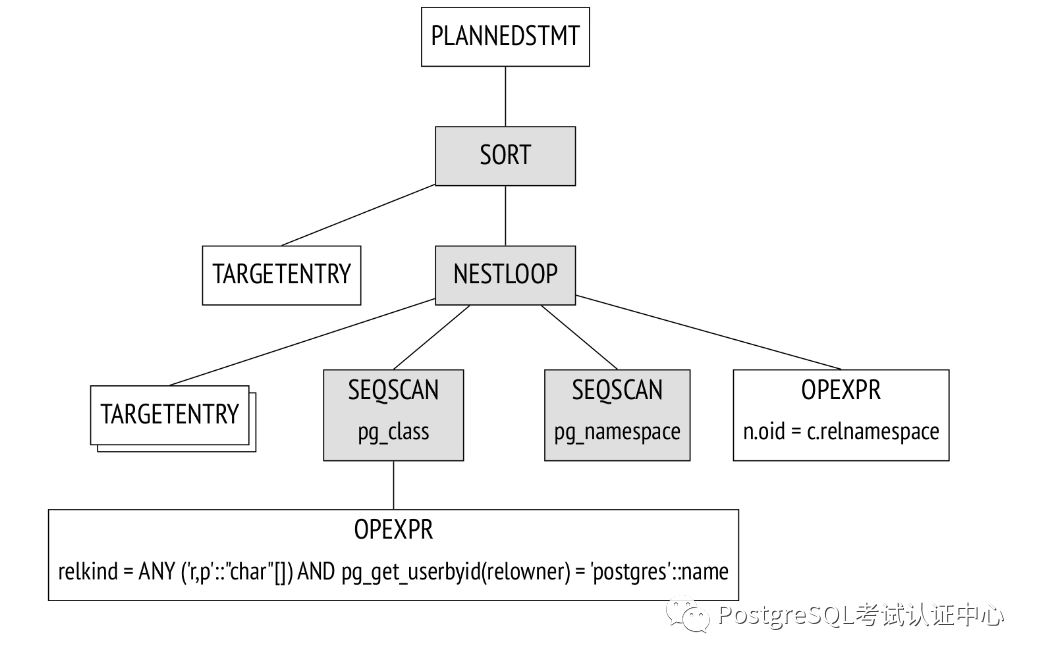
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
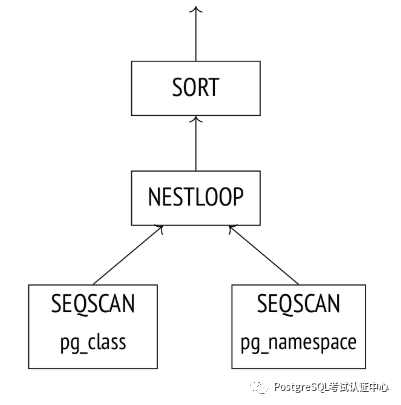
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
−> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
−> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_g...
−> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 wid...
(7 rows)
初始表之一从计划树中消失了,因为计划者发现不需要处理查询并将其删除。
估计要处理的行数和每个节点旁边的处理成本。
公共表表达式通常与主查询分开优化。从版本 12 开始,可以使用 MATERIALIZE 子句强制执行此操作。
来自非 SQL 函数的查询与主查询分开优化。(在某些情况下,SQL 函数可以内联到主查询中。)
join_collapse_limit参数与显式 JOIN 子句以及from_collapse_limit参数与子查询一起可以定义某些连接的顺序,具体取决于查询语法。
SELECT ...
FROM a, b, c, d, e
WHERE ...
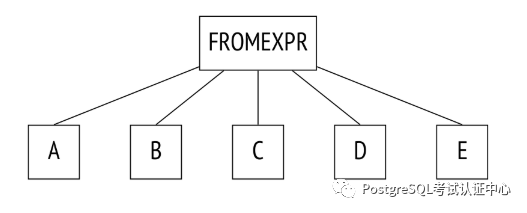
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
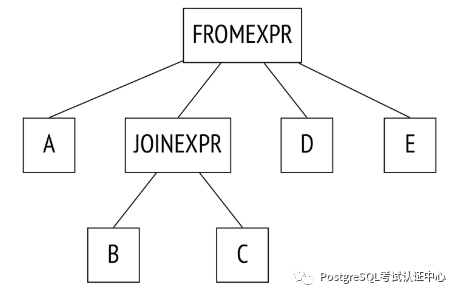
表 B 必须连接到表 C(反之亦然,对中的连接顺序不受限制)。 表 A、D、E 以及 B 到 C 的连接可以按任何顺序连接。
SELECT ...
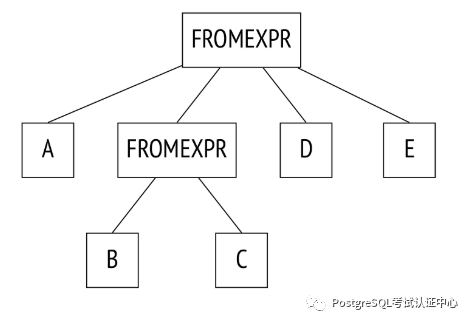
FROM a, b JOIN c ON ..., d, e
WHERE ...
Sort (cost=21.03..21.04 rows=1 width=128)
节点的子节点的基数,或输入行数。
节点的选择性,或输出行与输入行的比例。
4. 执行
5. 扩展查询协议
解析
转型
规划
执行
6. 准备
PREPARE plane(text) AS
SELECT * FROM aircrafts WHERE aircraft_code = $1;
SELECT name, statement, parameter_types
FROM pg_prepared_statements \gx
−[ RECORD 1 ]−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
name | plane
statement | PREPARE plane(text) AS +
| SELECT * FROM aircrafts WHERE aircraft_code = $1;
parameter_types | {text}
7. 参数绑定
EXECUTE plane('733');
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Boeing 737−300 | 4200
(1 row)
与文字表达式的串联相比,准备好的语句的一个优点是可以防止任何类型的 SQL 注入,因为参数值不会影响已经构建的解析树。在没有准备好的声明的情况下达到相同的安全级别将需要对来自不受信任来源的所有值进行广泛的转义。
8. 计划和执行
CREATE INDEX ON bookings(total_amount);
EXPLAIN SELECT * FROM bookings WHERE total_amount > 1000000;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (cost=86.38..9227.74 rows=4380 wid...
Recheck Cond: (total_amount > '1000000'::numeric)
−> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00....
Index Cond: (total_amount > '1000000'::numeric)
(4 rows)
EXPLAIN SELECT * FROM bookings
WHERE total_amount > 100;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on bookings (cost=0.00..39835.88 rows=2111110 width=21)
Filter: (total_amount > '100'::numeric)
(2 rows)
在某些情况下,除了解析树之外,规划器还会存储查询计划,以避免在出现时再次规划它。这个没有参数值的计划称为通用计划,而不是使用给定参数值生成的自定义计划。通用计划的一个明显用例是没有参数的语句。
EXECUTE plane('763');
EXECUTE plane('773');
EXPLAIN EXECUTE plane('319');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '319'::text)
(2 rows)
EXECUTE plane('320');
EXPLAIN EXECUTE plane('321');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '$1'::text)
(2 rows)
SET plan_cache_mode = 'force_custom_plan';
EXPLAIN EXECUTE plane('CN1');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = 'CN1'::text)
(2 rows)
SELECT name, generic_plans, custom_plans
FROM pg_prepared_statements;
name | generic_plans | custom_plans
−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−
plane | 1 | 6
(1 row)
9. 输出查询
BEGIN;
DECLARE cur CURSOR FOR
SELECT * FROM aircrafts ORDER BY aircraft_code;
FETCH 3 FROM cur;
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−+−−−−−−−
319 | Airbus A319−100 | 6700
320 | Airbus A320−200 | 5700
321 | Airbus A321−200 | 5600
(3 rows)
FETCH 2 FROM cur;
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Boeing 737−300 | 4200
763 | Boeing 767−300 | 7900
(2 rows)
COMMIT;

PG考试咨询

往期回顾
2022年中国PostgreSQL考试认证计划
PGCCC,公众号:PostgreSQL考试认证中心通知:2022年中国PostgreSQL考试认证计划
PostgreSQL认证专家-广州班开班风采
PGCCC,公众号:PostgreSQL考试认证中心永远都不晚:PostgreSQL认证专家(培训考试-广州站)
开班通知-PCP认证专家(上海站)培训开班1106PGCCC,公众号:PostgreSQL考试认证中心 开班通知-PCP认证专家(上海站)培训开班1106
PostgreSQL-PCP认证专家-北京站-精彩花絮
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL认证专家考试(培训)(10月16日北京站)精彩花絮
PostgreSQL-PCP认证专家-成都站
公众号:PostgreSQL考试认证中心开班通知-PCP认证专家(成都站)培训开班1016
PostgreSQL-PCP认证专家考试-北京站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL认证专家考试(培训)-北京站-成功举办
PostgreSQL-PCA认证考试-贵阳站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL PCA+PCP认证考试在贵阳成功举办
PostgreSQL-PCP认证专家考试-上海站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL PCP认证考试(上海站)成功举办
PostgreSQL认证专家考试-学员考试总结
薛晓刚,公众号:PostgreSQL考试认证中心难考的PostgreSQL认证考试
PostgreSQL-PCM认证大师考试-天津站-考试风采
PGCCC,公众号:PostgreSQL考试认证中心PostgreSQL-PCM认证大师考试(天津站)成功举办
如何在工业和信息化部教育与考试中心官网查询证书
PG考试认证中心,公众号:PostgreSQL考试认证中心如何在工业和信息化部教育与考试中心查询PostgreSQL证书
中国PostgreSQL考试认证体系
PG考试认证中心,公众号:PostgreSQL考试认证中心中国PostgreSQL考试认证体系
