




最近一位同事给来个SQL,说很慢. 如果取消最后一个LEFT JOIN 就很快乐
select m.register_name,aa.*,c.product_namefrom(SELECT *FROM order_trans awhere 1= 1and a.no= '510324'and a.status= '02'and a.time >= '2021-12-01 00:00:00'and a.time <= '2021-12-31 23:59:59'and code is not nullorder by id desclimit 0, 10) as aaLEFT JOIN custer_info m ON aa.merchant_id= m.idLEFT JOIN pay_info b on aa.pay_code= b.pay_codeLEFT JOIN pay_product_info c ON c.product_code= aa.product_code AND c.pay_code= aa.pay_code+----+-------------+------------+----------------------------------------------------------------------------------------------------------------------------------------+--------+--------------------------------------------------------------+-----------------------+---------+-----------------+------+----------+----------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+------------+----------------------------------------------------------------------------------------------------------------------------------------+--------+--------------------------------------------------------------+-----------------------+---------+-----------------+------+----------+----------------------------------------------------+| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL || 1 | PRIMARY | m | NULL | eq_ref | PRIMARY | PRIMARY | 8 | aa.custer_id | 1 | 100.00 | NULL || 1 | PRIMARY | b | NULL | ref | idx_pay_code | idx_pay_code | 93 | aa.pay_code | 1 | 100.00 | Using index || 1 | PRIMARY | c | NULL | ALL | NULL | NULL | NULL | NULL | 288 | 100.00 | Using where; Using join buffer (Block Nested Loop) || 2 | DERIVED | a | time_20220105 | ref | time_idx,trans_no_idx,ode_idx | custer_trans_no_idx | 93 | const | 1 | 5.00 | Using index condition; Using where; Using filesort |+----+-------------+------------+----------------------------------------------------------------------------------------------------------------------------------------+--------+--------------------------------------------------------------+-----------------------+---------+-----------------+------+----------+----------------------------------------------------+5 rows in set, 1 warning (0.00 sec)
从执行计划来看似乎没有优化的空间,主表 A 也就是 ID=2 这部分好像有个FILESORT 可以优化.优化主表好像没有价值,比较少了个LEFT JOIN 就非常快.
MYSQL 8.0 ANALYZE执行计划
explain analyze
| -> Nested loop left join (cost=2.29 rows=1) (actual time=0.232..0.232 rows=0 loops=1)
-> Nested loop left join (cost=1.46 rows=1) (actual time=0.230..0.230 rows=0 loops=1)
-> Nested loop left join (cost=0.86 rows=1) (actual time=0.230..0.230 rows=0 loops=1)
-> Table scan on aa (cost=2.73 rows=2) (actual time=0.001..0.001 rows=0 loops=1)
-> Materialize (cost=0.26 rows=1) (actual time=0.228..0.228 rows=0 loops=1)
-> Limit: 10 row(s) (cost=0.26 rows=1) (actual time=0.137..0.137 rows=0 loops=1)
-> Sort: a.id DESC, limit input to 10 row(s) per chunk (cost=0.26 rows=1) (actual time=0.136..0.136 rows=0 loops=1)
-> Filter: ((a.`status` = '02') and (a.code is not null) and (a.settle_no is null)) (actual time=0.126..0.126 rows=0 loops=1)
-> Index lookup on a using custer_trans_no_idx (custer_no='510324'),
with index condition: ((a.time >= TIMESTAMP'2021-12-01 00:00:00') and (a.time <= TIMESTAMP'2021-12-31 23:59:59'))
(actual time=0.124..0.124 rows=0 loops=1)
-> Single-row index lookup on m using PRIMARY (id=aa.custer_id) (cost=0.30 rows=1) (never executed)
-> Index lookup on b using idx_channel_code (channel_code=aa.channel_code) (cost=0.30 rows=1) (never executed)
-> Filter: (c.pay_code = aa.pay_code) (cost=0.42 rows=1) (never executed)
-> Index lookup on c using idx_product_code (product_code=aa.channel_product_code) (cost=0.42 rows=1) (never executed)
从8.0的ANALZYE 上也没有看到LOOPS 太大的.
MYSQL 5.7 图形执行计划
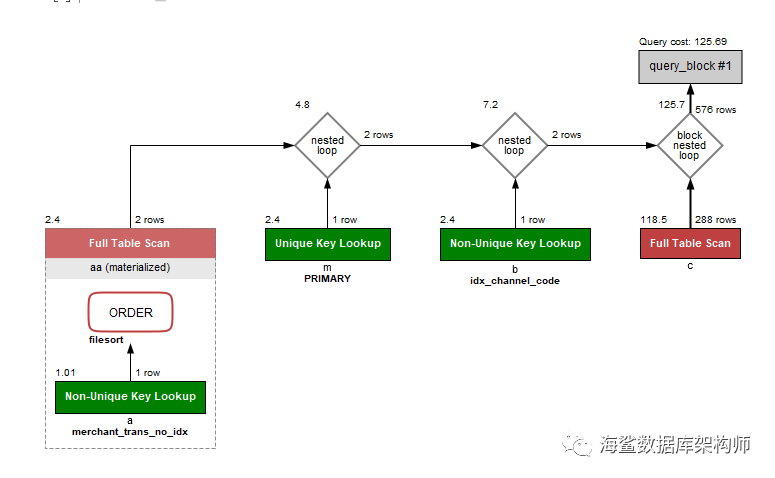
从 图形界面来看 似乎 和C表LEFT JOIN的时候 结果集居然是576 行.
最后呈现是10行啊! 咋回事呢?
MYSQL 8.0 图形执行计划
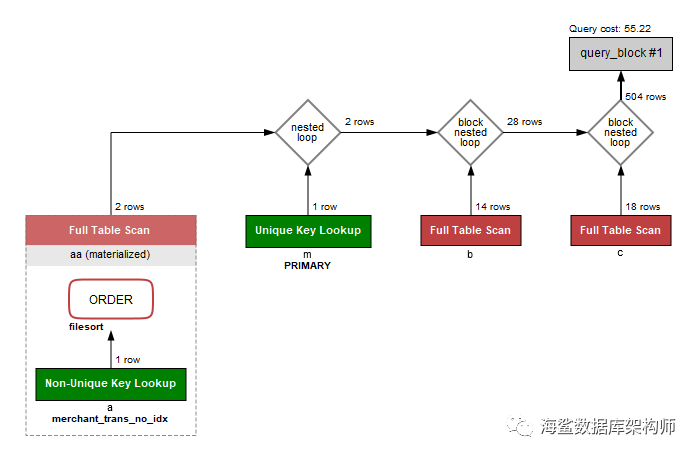
MYSQL 8.0 好像也没有优化这个问题
对JOIN 列 创建组合索引后

MYSQL join有 NESTED LOOP 和 BLOCK NESTED LOOP 两种,关于两种算法在这里不谈,差不多来说,面对大数据,MYSQL 采用 BLOCK NESTED LOOP 来加速JOIN ,否则使用过去的NESTED LOOP 是非常慢的.
不过MYSQL 8.0 新加入了HASH JOIN , 看样子这点数据量估计不采用HASH JOIN, 或许HASH JOIN算法还不过成熟,优先使用BLOCK NESTED LOOP算法.
不过总得来说 发现了BLOCK NESTED LOOP 字眼出现 说明JOIN 此表的时候参与JOIN的数据量太多了.
上面的 普通的EXPLAIN EXTRA 字段
Using where; Using join buffer (Block Nested Loop)
MYSQL JOIN 时候,是先JOIN 然后再过滤数据. 听起来好像没啥问题.
不过好像ORACLE 并非如此, 做JOIN时候,查询对方记录,通过索引好,还是通过全表也吧,找到符合条件的行,顺便也过滤一下. 最终参与JOIN的行就非常少了.
假如只要ID 索引
LEFT JOIN B ON A.ID=B.ID AND B.X=A.X AND B.Z=A.Z
WHERE B.H='XXXX'
这个在ORACLE 里面基本上都会优化掉,就是在找B表的数据的时候,
B.ID=A.ID 同时 把B.H='XXXX' AND B.X=A.X AND B.Z=A.Z 一起判断.
为什么MYSQL不这样呢?
因为MYSQL 服务层和引擎层是分工的, 过滤的事情由服务层干!
INNODB 只根据索引去匹配,没有索引全返回给服务层, 关于过滤条件,你服务层自己去过滤吧!
大家多注意下这点. LEFT JOIN 列 最好全在索引里.
附加算法参考
Nested Loop Join算法
将外层表的结果集作为循环的基础数据,然后循环从该结果集每次一条获取数据作为下一个表的过滤条件去查询数据,然后合并结果。如果有多个表join,那么应该将前面的表的结果集作为循环数据,取结果集中的每一行再到下一个表中继续进行循环匹配,获取结果集并返回给客户端。
伪代码如下:
for each row in t1 matching range
{
for each row in t2 matching reference key
{
for each row in t3
{
if row satisfies join conditions,
send to client
}
}
}
Block Nested-Loop算法
MySQL BNL算法原本只支持内连接,现在已支持外连接和半连接操作,包括嵌套外连接。
BNL算法原理:将外层循环的行/结果集存入join buffer,内存循环的每一行数据与整个buffer中的记录做比较,可以减少内层循环的扫描次数
举个简单的例子:外层循环结果集有1000行数据,使用NLJ算法需要扫描内层表1000次,但如果使用BNL算法,则先取出外层表结果集的100行存放到join buffer, 然后用内层表的每一行数据去和这100行结果集做比较,可以一次性与100行数据进行比较,这样内层表其实只需要循环1000/100=10次,减少了9/10。
for each row in t1 matching range
{
for each row in t2 matching reference key
{
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3
{
for each t1, t2 combination in join buffer
{
if row satisfies join conditions,
send to client
}
}
empty buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
}
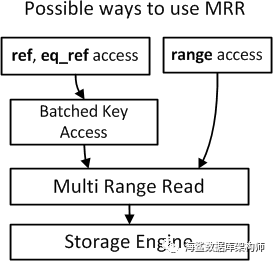
Batched Key Access Joins
MySQL实现了一种连接表的方法,叫做Batched Key Access(BKA),当存在对第二个连接操作数生成的表的索引访问时,可以应用BKA。像BNL算法一样,BKA算法采用连接缓冲区积累由连接操作产生的第一个的行中的感兴趣的列。然后BKA算法建立KEY到表的访问在缓冲区中连接所有行,,并将这些KEY批量提交到数据库引擎以进行索引查找。在提交key之后,MRR引擎函数以最佳方式在索引中执行查找,获取由这些密钥找到的连接表的行,并开始向匹配行提供BKA连接算法。每个匹配行与对连接缓冲区中的行的引用相耦合。
使用BKA时,值join_buffer_size定义了每个请求到存储引擎的批量密钥的大小。缓冲区越大,对连接操作的右侧表的顺序访问就越多,这可以显着提高性能。
要使用BKA,必须将系统变量的batched_key_access标志 optimizer_switch设置为on。BKA使用MRR,因此mrr标志也必须是 on。目前,MRR的成本估算过于悲观。因此,也有必要对 mrr_cost_based要 off用于要使用的BKA。以下设置启用BKA:
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
1
MRR功能有两种执行方式:
第一种方案用于传统的基于磁盘的存储引擎,例如InnoDB和 MyISAM。对于这些引擎,通常将来自连接缓冲区的所有行的键一次提交给MRR接口。特定于引擎的MRR函数对提交的密钥执行索引查找,从中获取行ID(或主键),然后根据BKA算法的请求逐个获取所有这些选定行ID的行。返回的每一行都带有一个关联引用,该引用允许访问连接缓冲区中的匹配行。MRR函数以最佳方式获取行:它们以行ID(主键)顺序获取。这提高了性能,因为读取是按磁盘顺序而不是随机顺序。
第二种方案用于远程存储引擎,例如NDB。来自连接缓冲区的一部分行的密钥包及其关联由MySQL服务器(SQL节点)发送到MySQL Cluster数据节点。作为回报,SQL节点接收匹配行的包(或多个包)以及相应的关联。BKA连接算法获取这些行并构建新的连接行。然后将一组新密钥发送到数据节点,并使用返回的包中的行来构建新的连接行。该过程将继续,直到将来自联接缓冲区的最后一个密钥发送到数据节点,并且SQL节点已接收并加入与这些密钥匹配的所有行。
对于第一种情况,保留一部分连接缓冲区以存储由索引查找选择的行ID(主键),并作为参数传递给MRR功能。
没有特殊的缓冲区来存储为连接缓冲区中的行构建的密钥。相反,为缓冲区中的下一行构建键的函数作为参数传递给MRR函数。
在EXPLAIN输出中,使用BKA时Extra显示的值是Using join buffer (Batched Key Access),type的值是 ref或者eq_ref.
BNL和BKA,MRR的关系
BNL和BKA都是批量的提交一部分结果集给下一个被join的表(标记为T),从而减少访问表T的次数,那么它们有什么区别呢?BNL和BKA的思想是类似的,详情见:《nest-loop-join官方手册》
第一 BNL比BKA出现的早,BKA直到5.6才出现,而BNL至少在5.1里面就存在。
第二 BNL主要用于当被join的表上无索引,Join buffering can be used when the join is of type ALL or index (in other words, when no possible keys can be used, and a full
scan is done, of either the data or index rows, respectively)
第三 BKA主要是指在被join表上有索引可以利用,那么就在行提交给被join的表之前,对这些行按照索引字段进行排序,因此减少了随机IO,排序这才是两者最大的区别,但是如果被join的表没用索引呢?那就使用BNL了。
BKA实现的过程中就是通过传递keys给MRR接口,本质上还是在MRR里面实现,下面这幅图则展示了它们之间的关系:
#使用hint,强制走bka
mysql> explain SELECT /*+ bka(a)*/ a.gender, b.dept_no FROM employees a, dept_emp b WHERE a.birth_date = b.from_date;
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------------+--------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------------+--------+----------+----------------------------------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | NULL |
| 1 | SIMPLE | a | NULL | ref | idx_birth_date | idx_birth_date | 3 | employees.b.from_date | 62 | 100.00 | Using join buffer (Batched Key Access) |
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------------+--------+----------+----------------------------------------+
2 rows in set, 1 warning (0.00 sec)
