




TiDB 数据库优化器原理
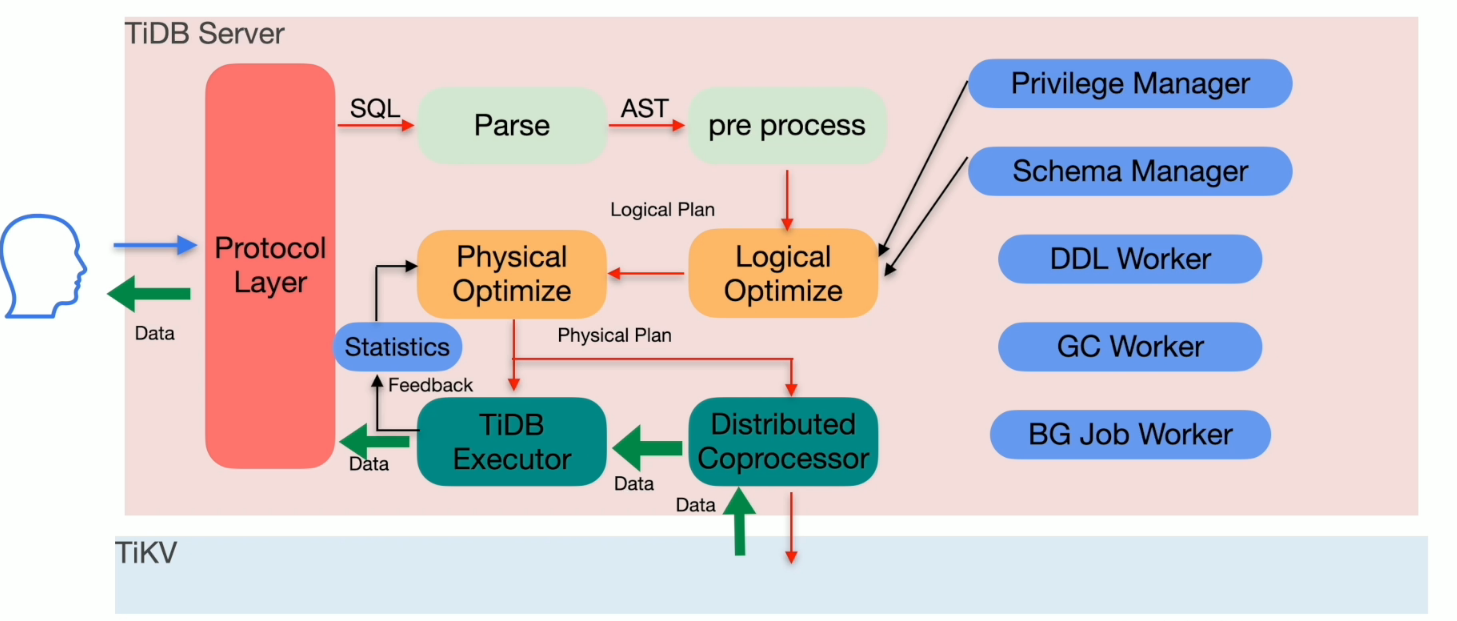
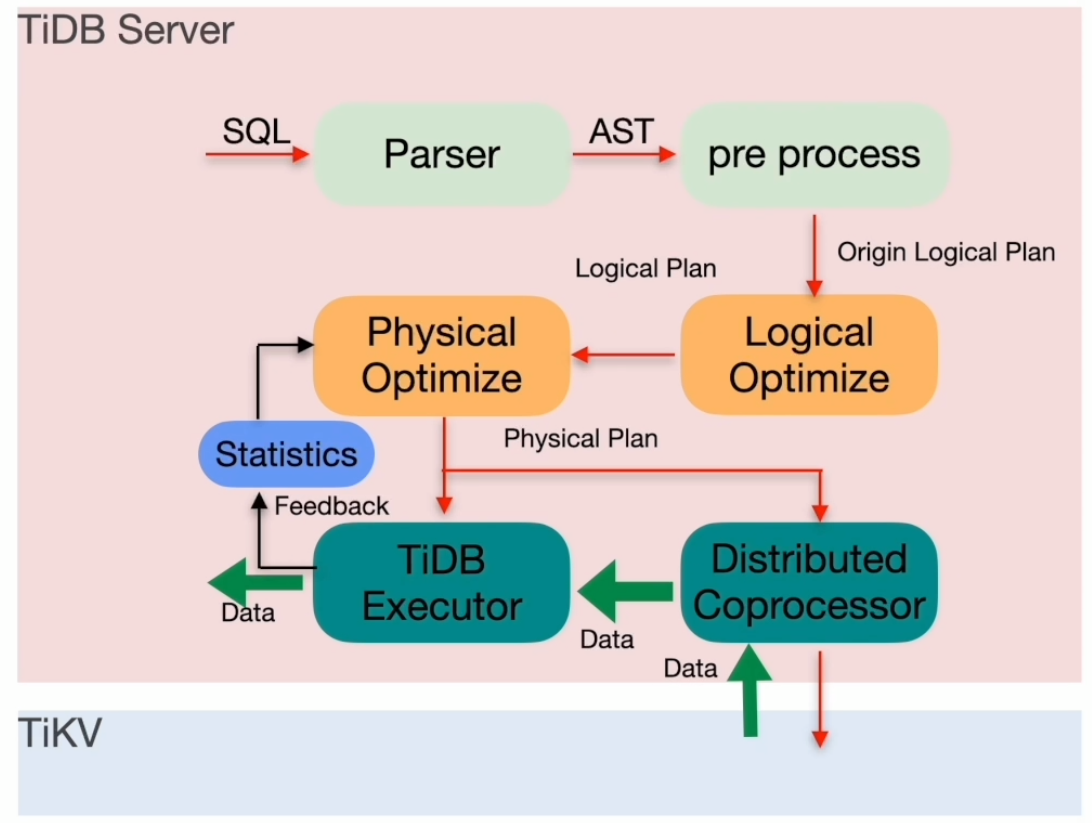
TiDB 优化器架构
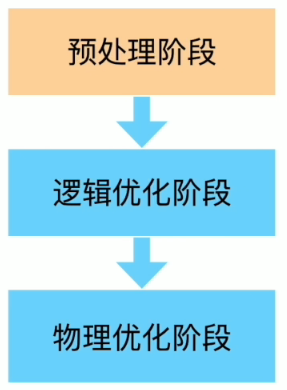
理解优化器预处理优化的方法
预处理阶段概述
- 针对点查( PointGet )进行优化
- 构造初始的逻辑执行计划
- 常量折叠
- 表达式简化
- 子查询处理
对于点查( PointGet )的优化
- 定义
- 单表的 SELECT/UPDATE/DELETE 操作
- 只扫描表的1行或者0行,过滤条件为等值查询
- 返回的记录条数为1行或者0行
SELECT id, name FROM emp WHERE id = 1001;
UPDATE emp SET name = 'Jim' WHERE id = 1001;
DELETE FROM emp WHERE id = 1001;
- 优化原因
- 优化方式较为单一
- 使用频率最高( OLTP )
- 如何优化
- 跳过下面的逻辑优化和物理优化,直接下推到 SQL 执行器
构建初始逻辑执行计划
- 常量折叠

- 表达式简化

- 子查询简化

逻辑优化
逻辑优化的规则
- 列剪裁
- 分区剪裁
- 聚合消除
- MAX/MIN优化
- 投影消除
- 外连接消除
- 谓词下推
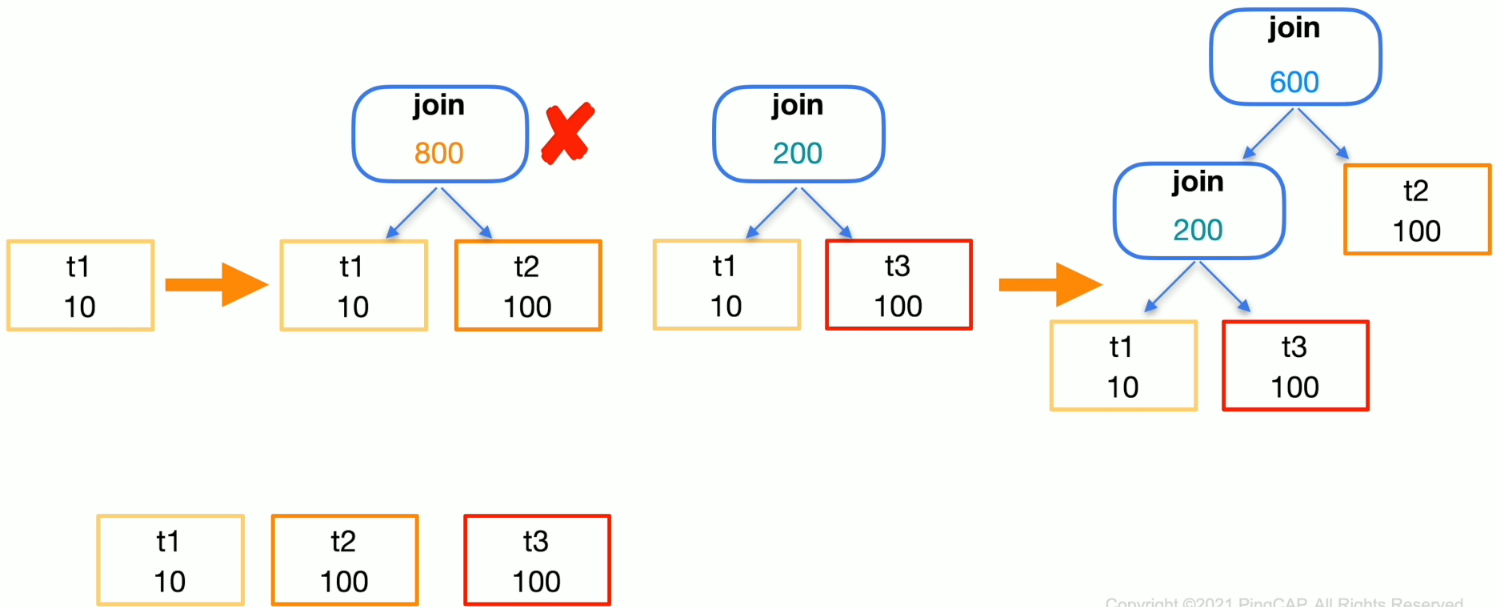
- 连接顺序调整
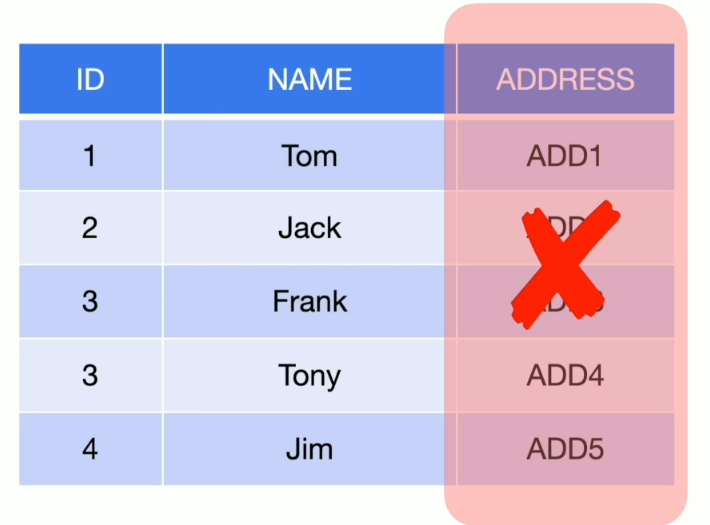
逻辑优化–列剪裁
SELECT name FROM emp WHERE id < 3;
逻辑优化–谓词下推
谓词下推(一)
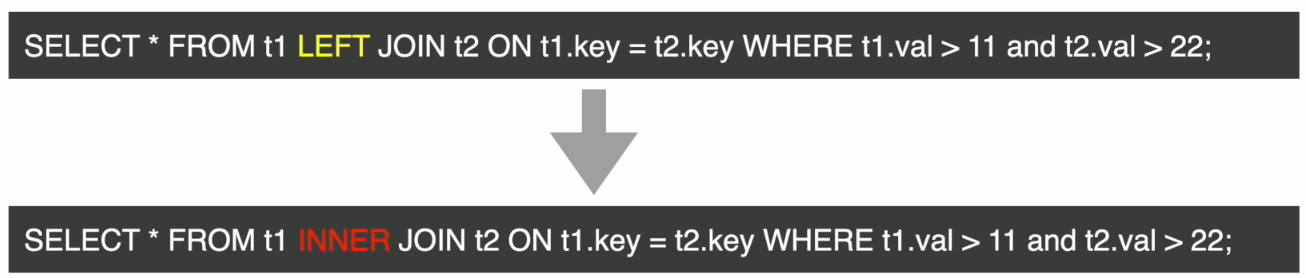
谓词下推(二)
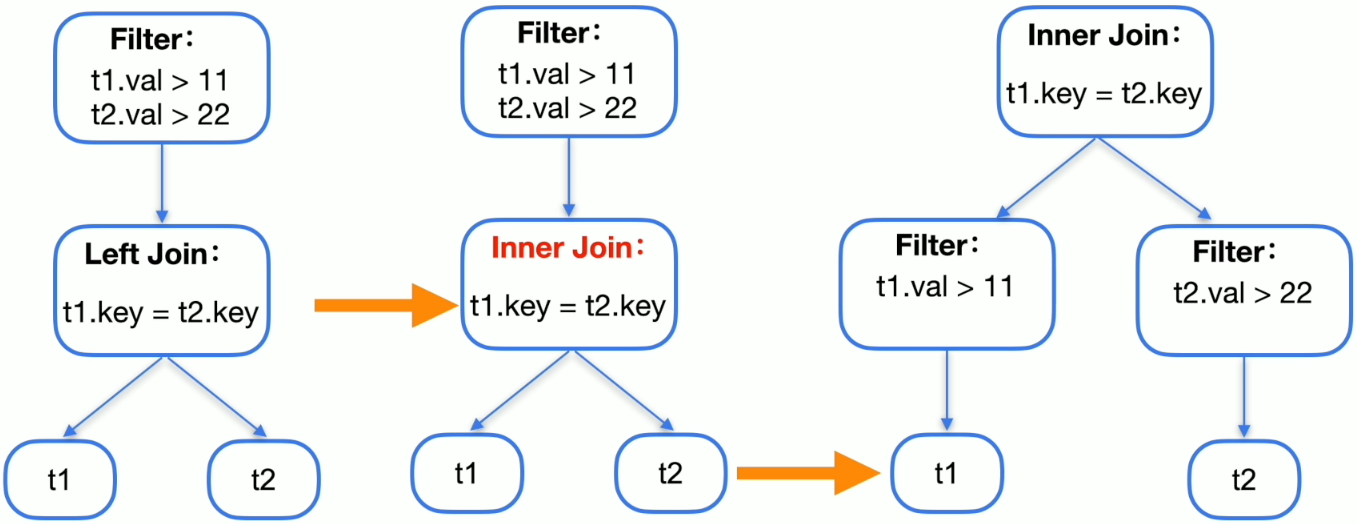
逻辑优化–连接顺序调整
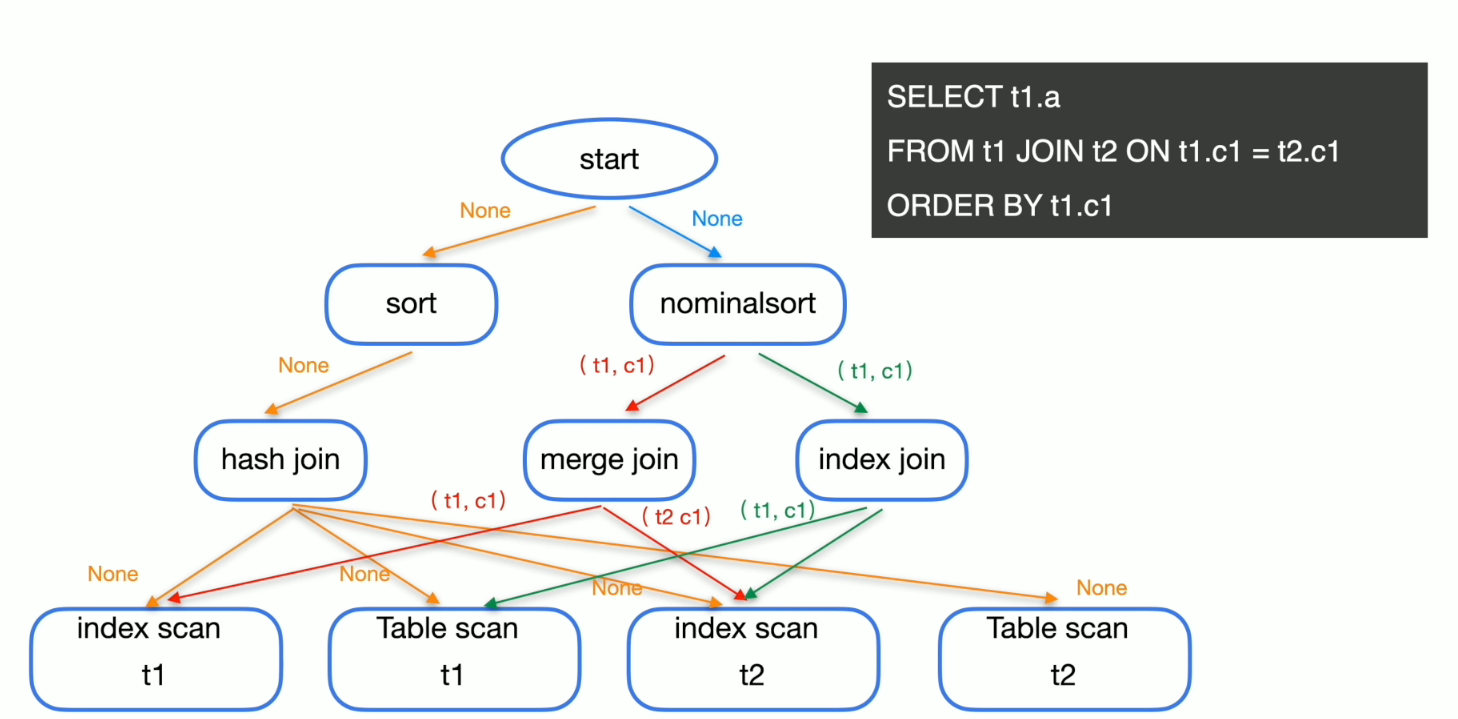
物理优化
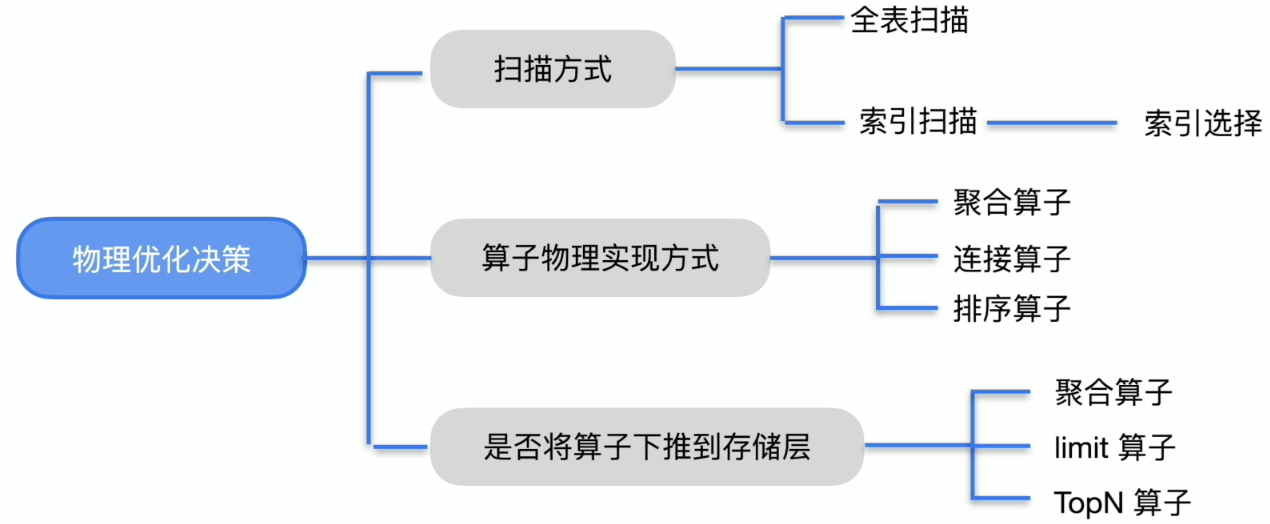
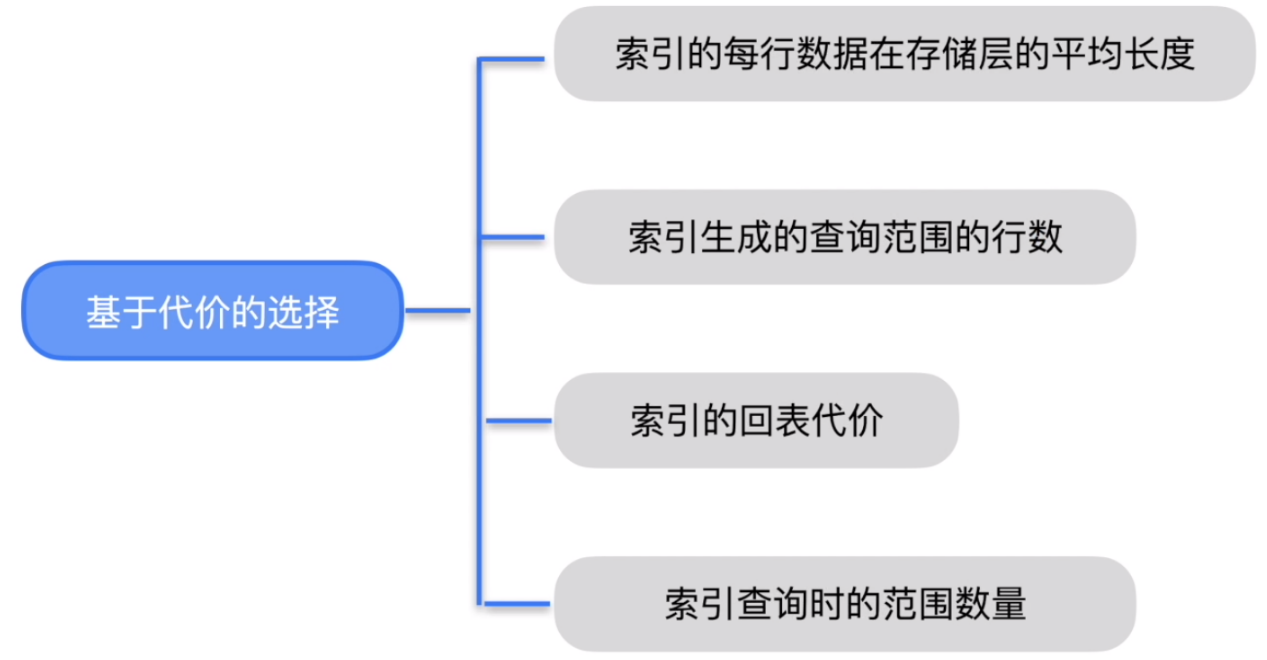
物理优化的维度
物理优化的决策
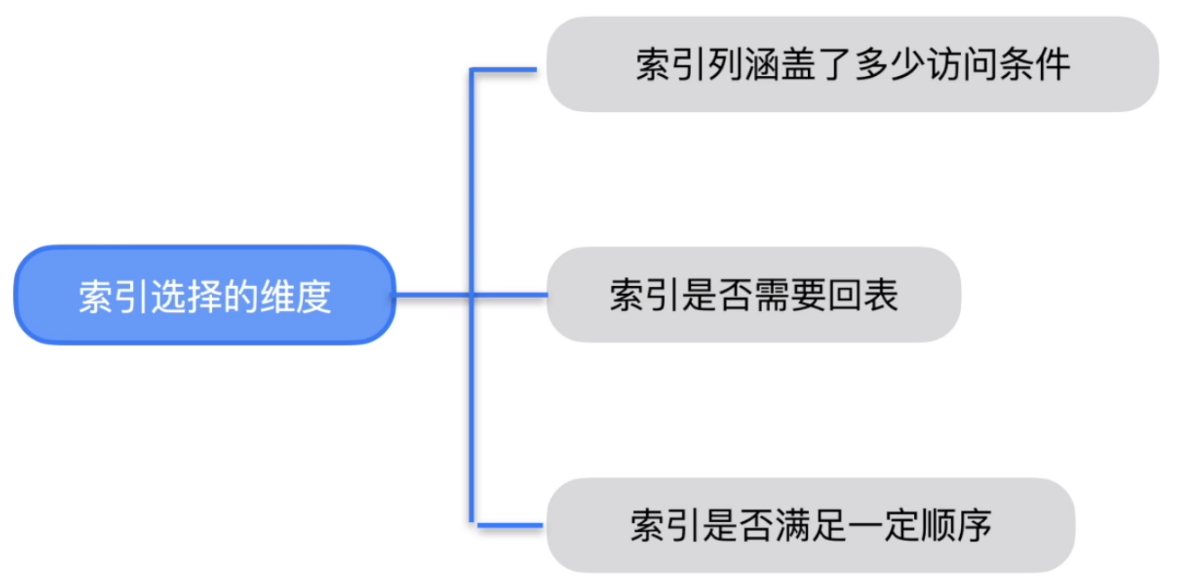
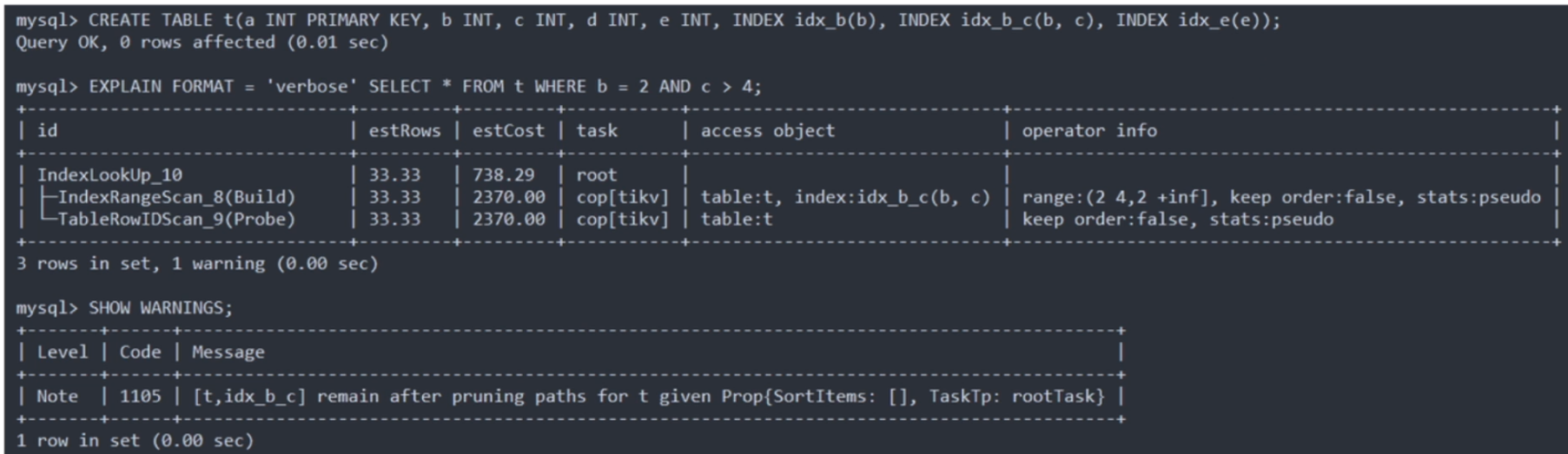
物理优化的索引选择
- 索引覆盖的范围
- 给定索引的抽取访问条件
- 过滤的条件可能是多种多样的(CNF 与DNF)
- 选择单列索引还是复合索引
- 索引不能有 false-negative 误判
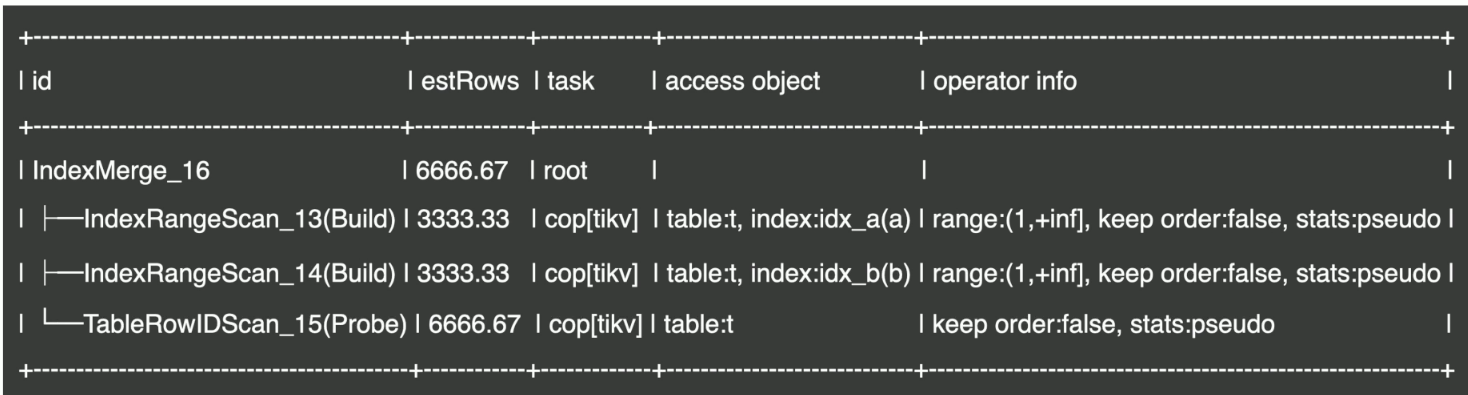
- Index Merge 访问
- 将访问条件合并转化
理解执行计划
使用 EXPLAIN 查看执行计划
EXPLAIN SELECT count(*) FROM trips WHERE start_date BETWEEN '2017-07-01 00:00:00' AND '2017-07-0123:59:59';
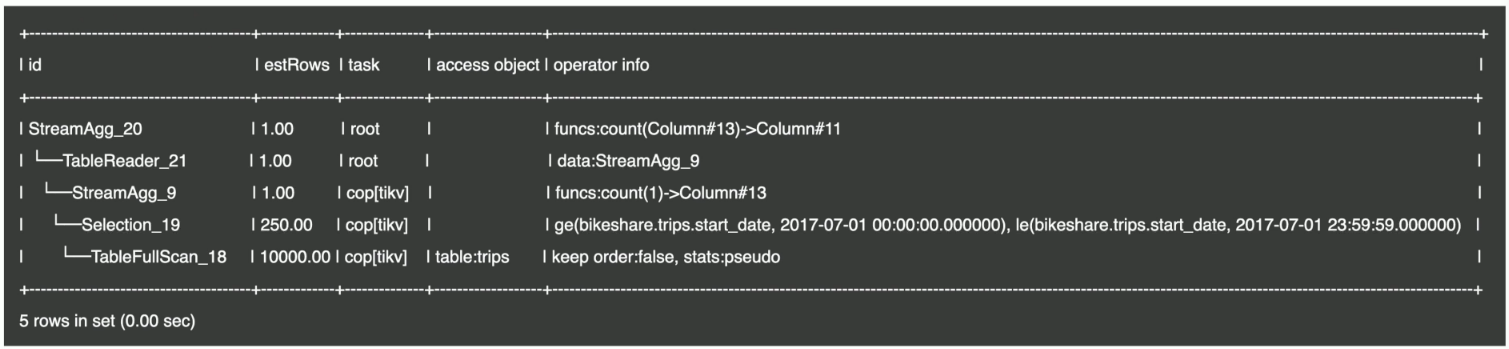
EXPLAIN 的输出格式

EXPLAIN ANALYZE 的输出格式
EXPLAIN ANALYZE 会执行对应的 SQL 语句,记录其运行的信息,并且和执行计划一起返回

阅读执行计划
执行计划中的算子
- 汇聚数据类算子
- Hash Aggregate
- Stream Aggregate
- 扫描数据类算子
- Point Get / Batch Point Get
- Table Reader
- Index Reader
- Index Lookup Reader
- Index Merge Reader
- 表连接类算子
- Hash Join 算子
- Merge Join 算子
- Index Join 算子
- Index Hash Join 算子
汇聚数据类算子
- Hash Aggregate 示例
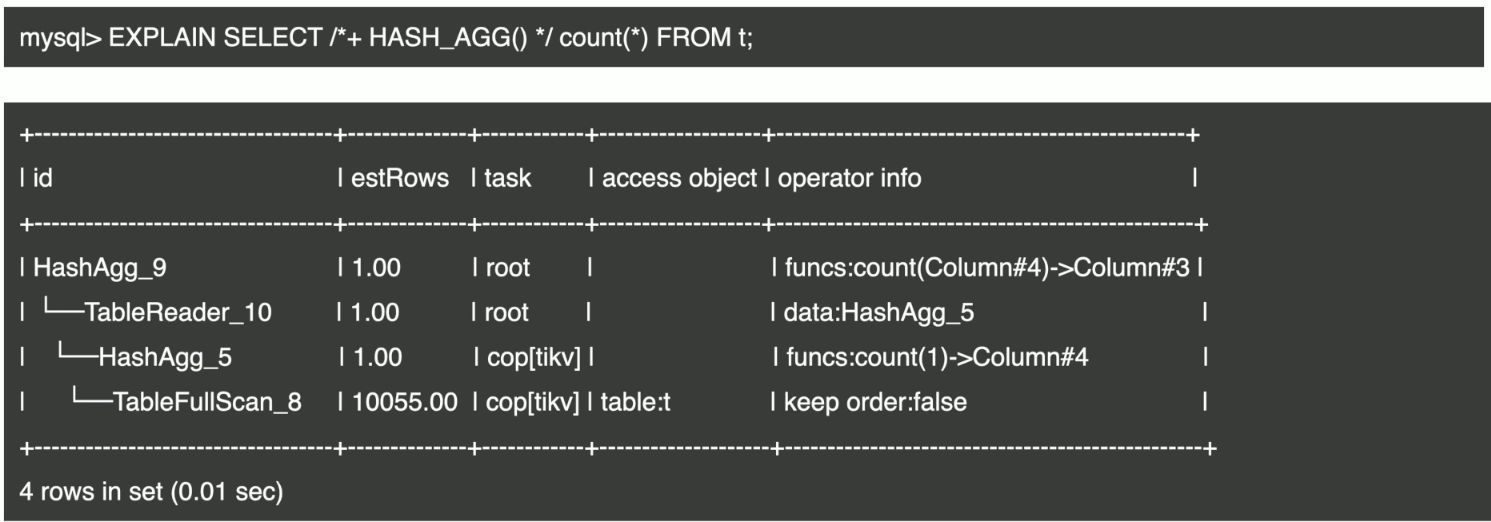
- 阻塞式执行,需要整个计算完成才可以对上层算子输出结果
- 不需要提前排序
- 支持并行
- 内存占用较大
- Stream Aggregate 示例

- 非阻塞式执行,对于类似 limit 操作友好
- 内存占用小
- 单线程执行
扫描数据类算子


- Index Lookup 示例
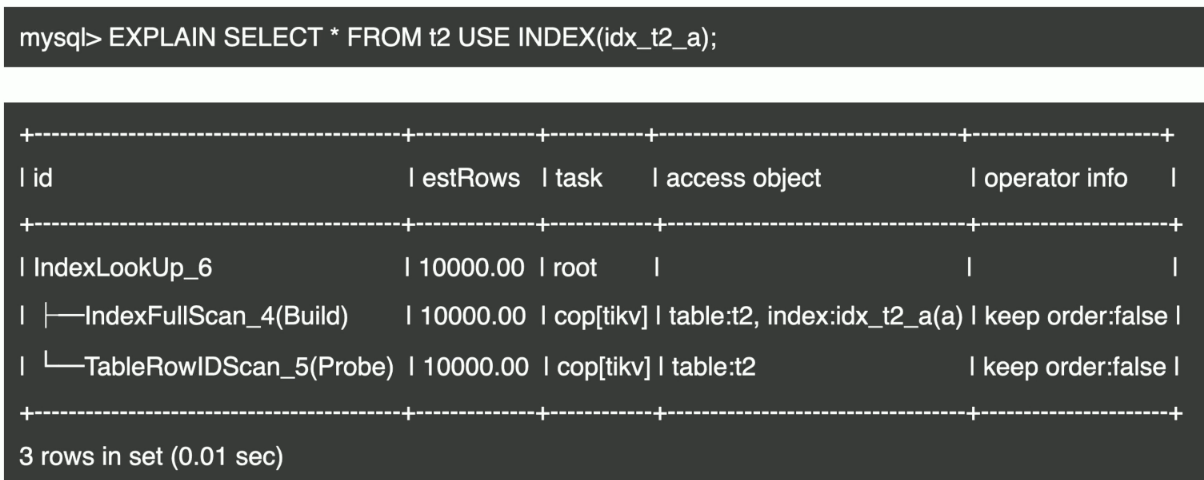
- Table Reader 示例
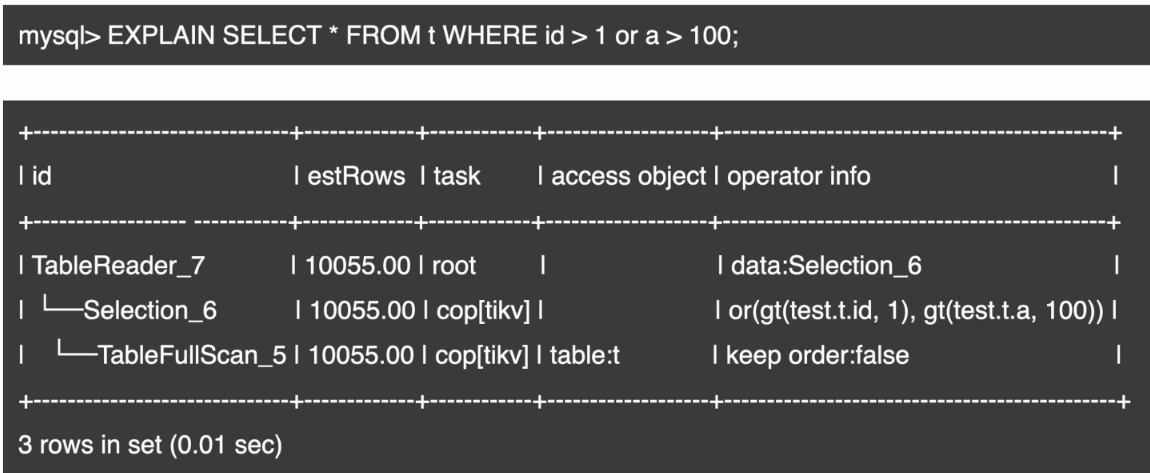
- Index Merge 示例

表连接类算子
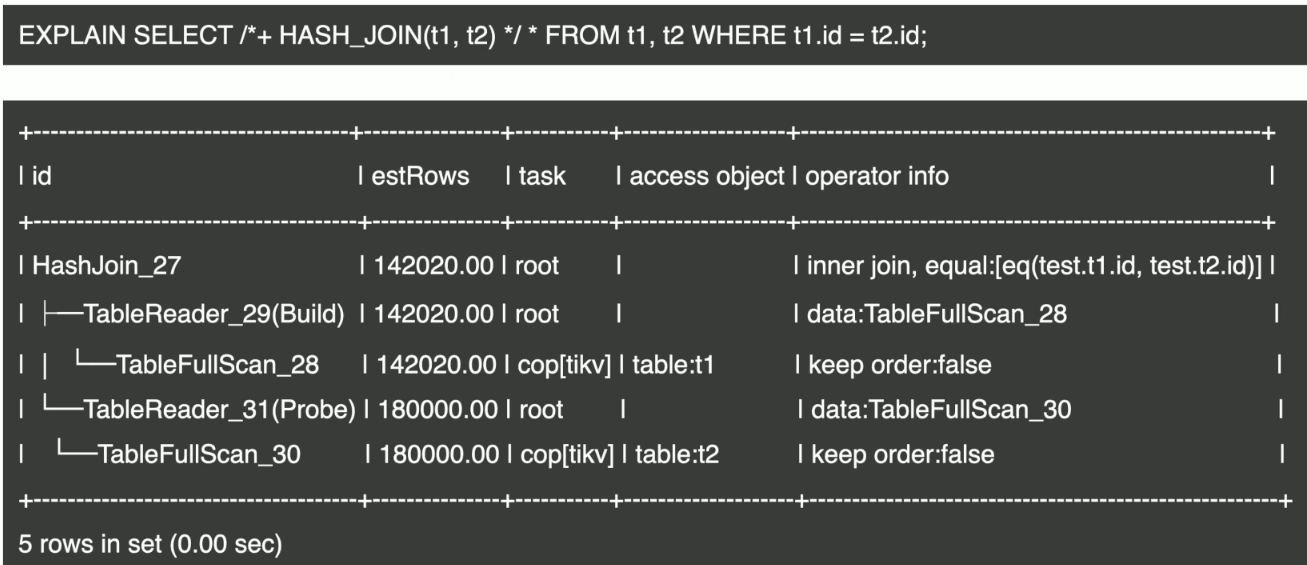
表连接–Hash Join
- Hash Join 示例
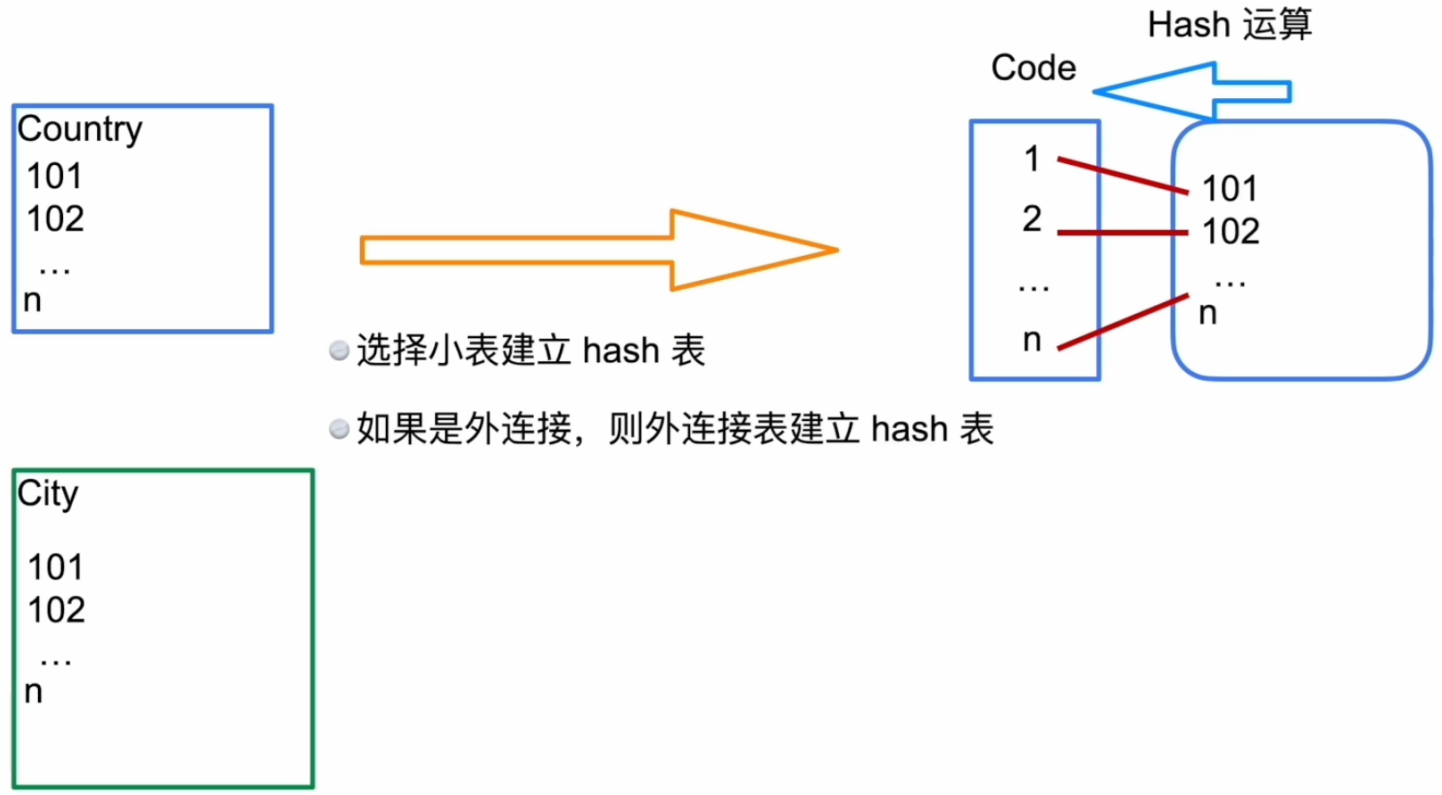
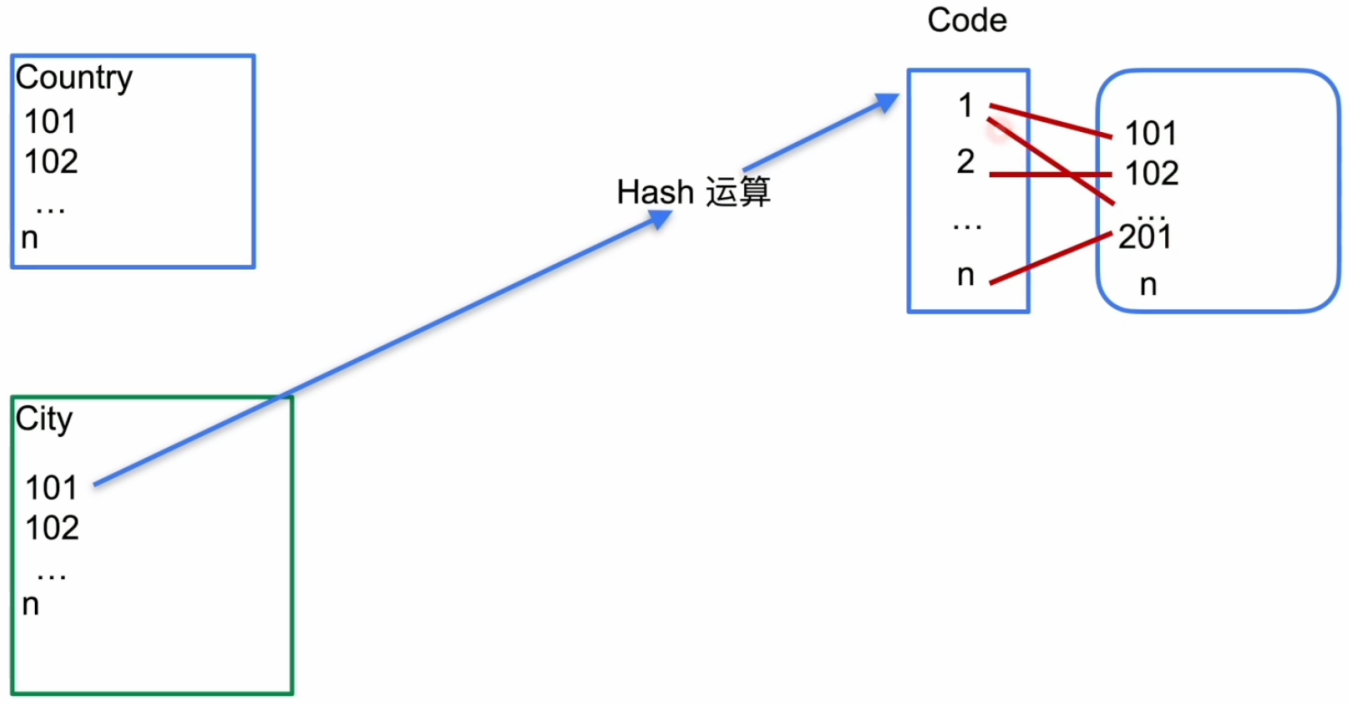
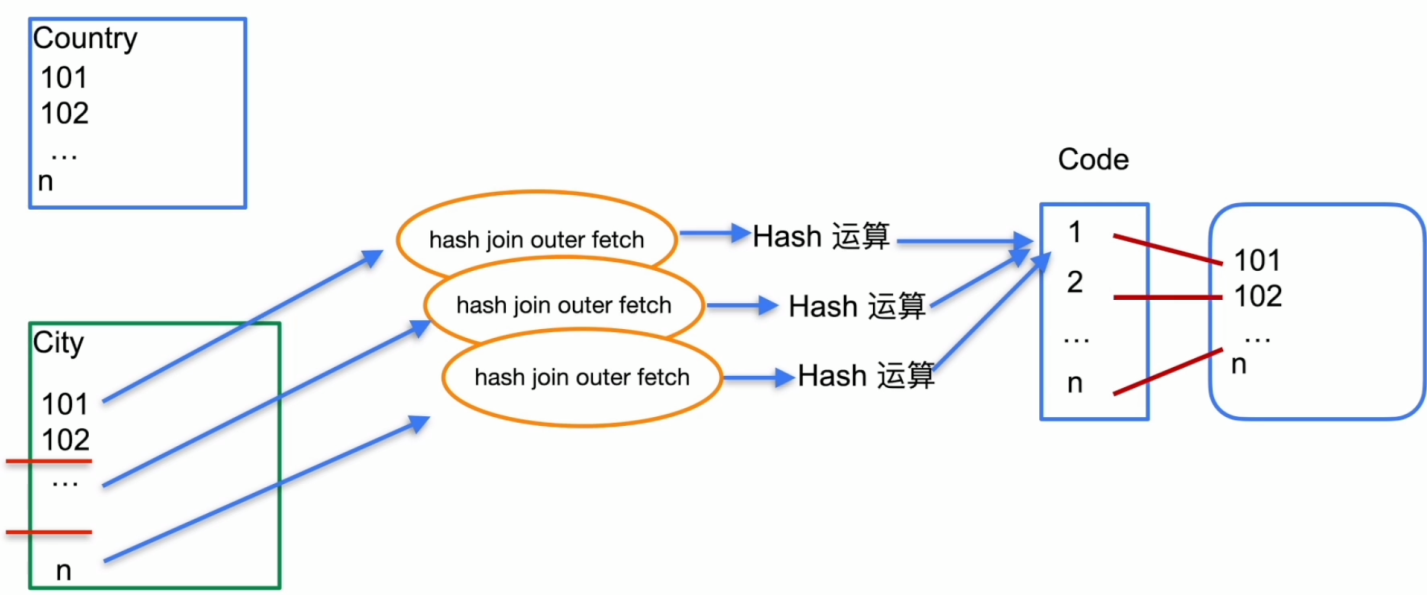
表连接 – Merge Join
- Merge Join 示例
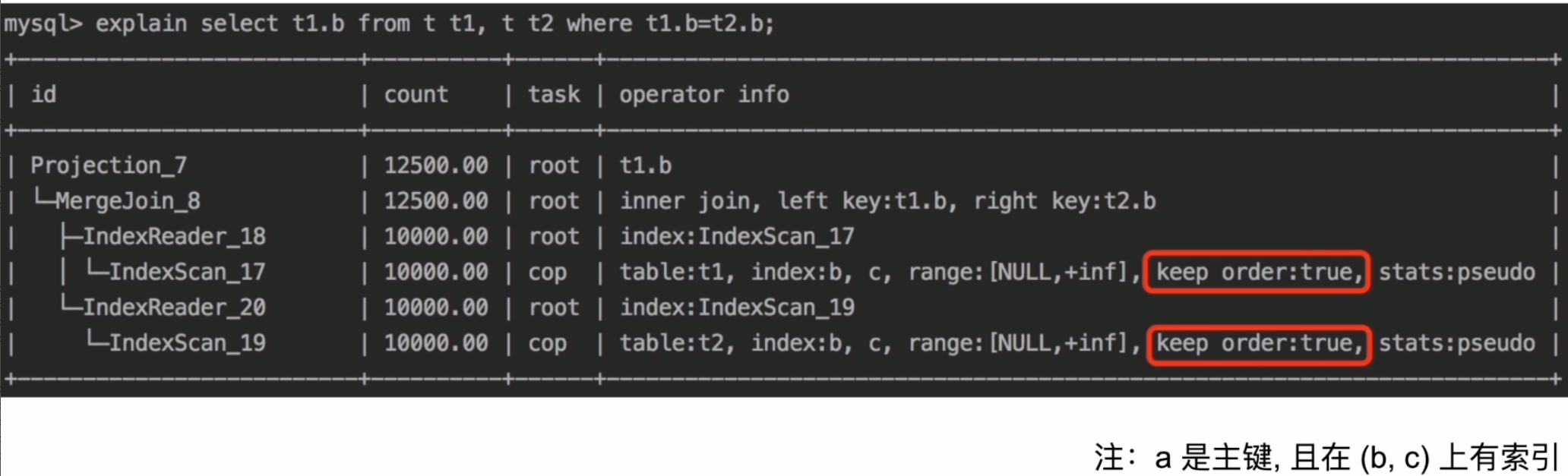


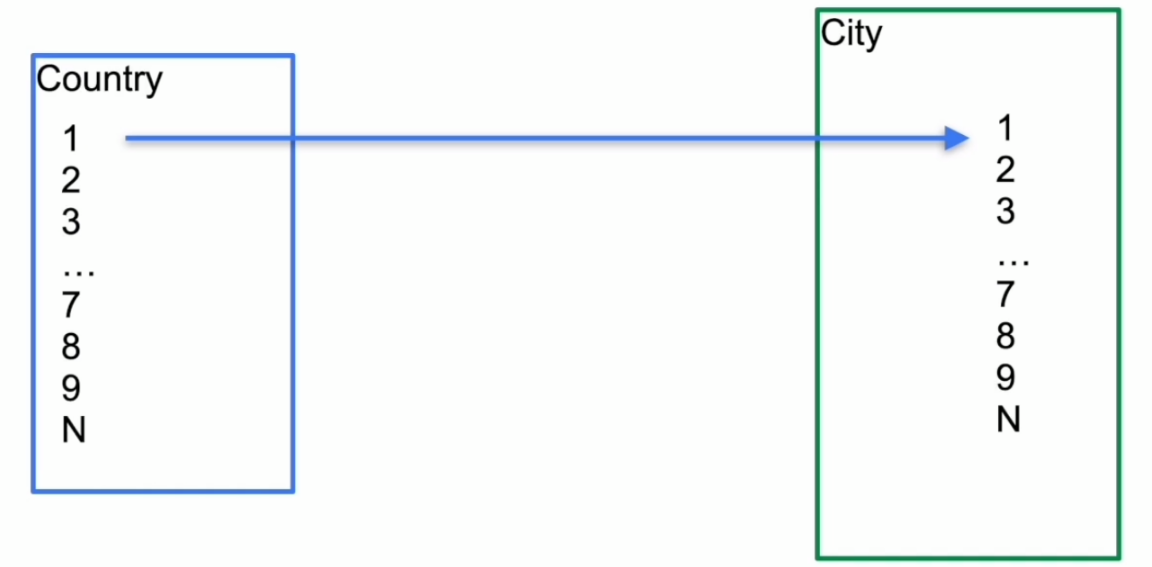
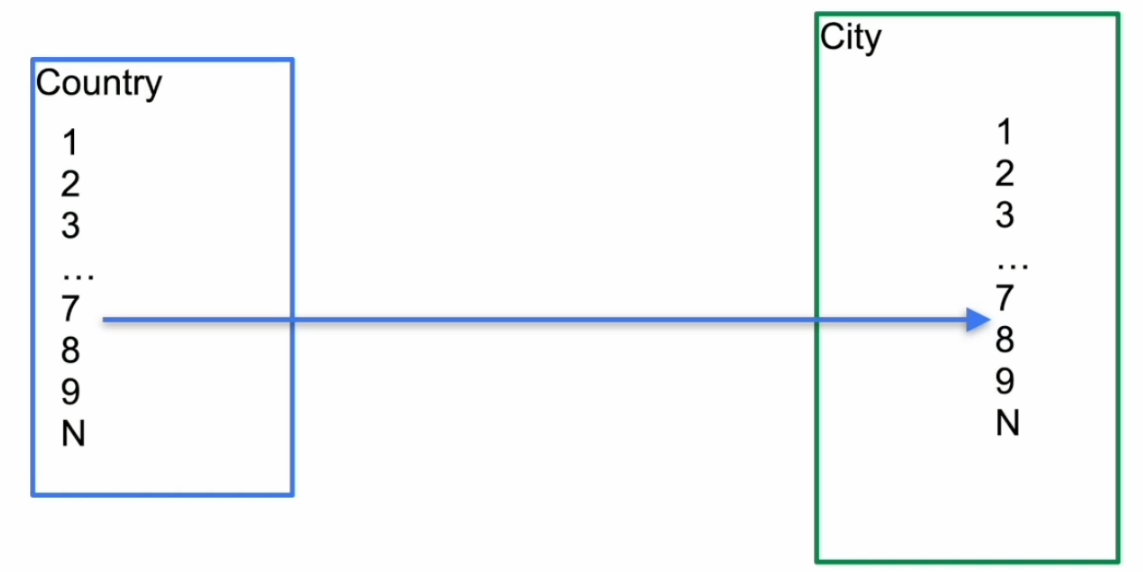
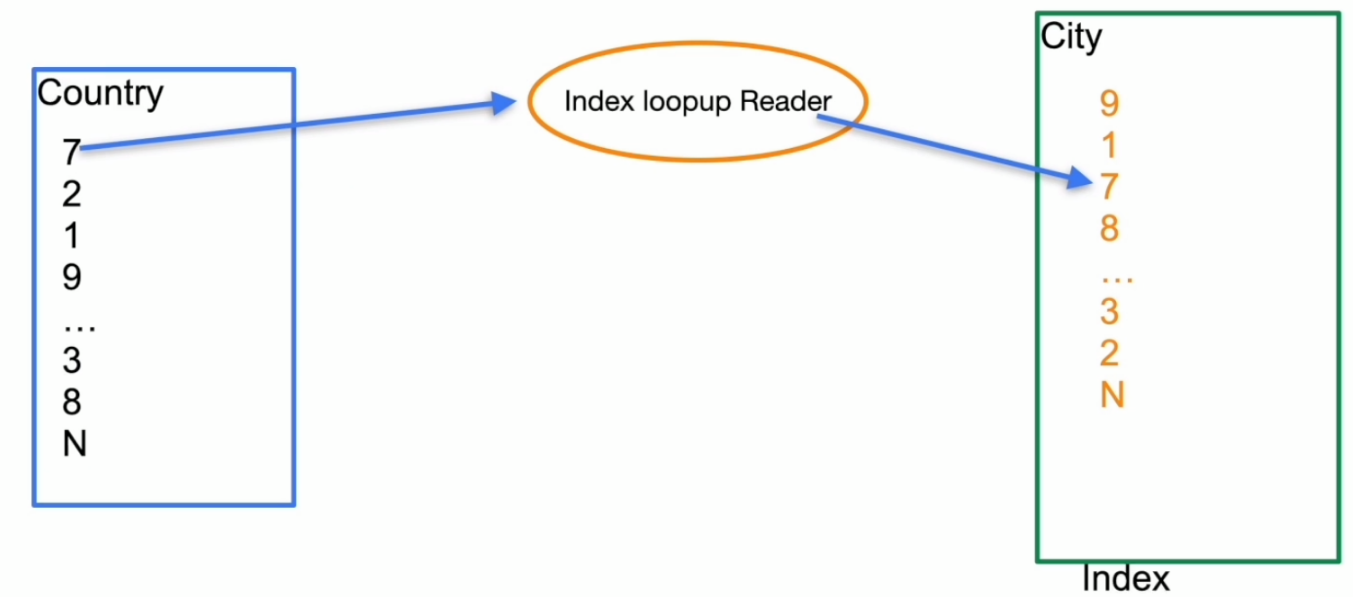
表连接–Index Join
- Index Join 示例
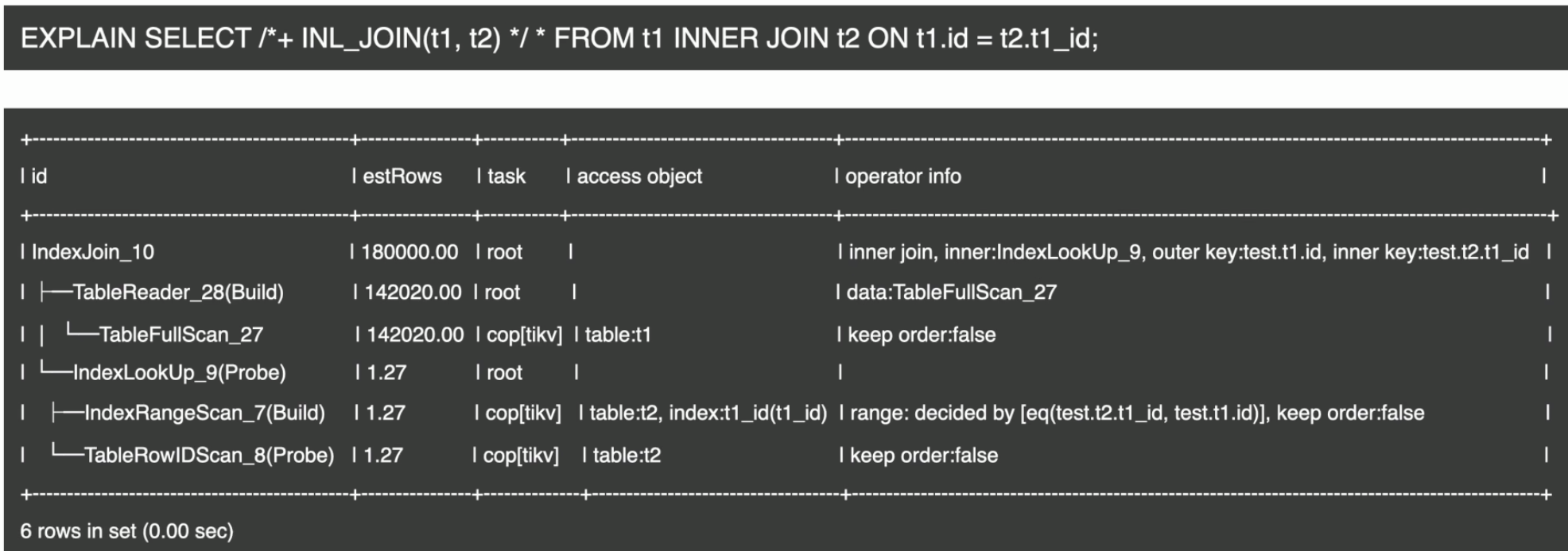
- Batched Nested loop join based on index

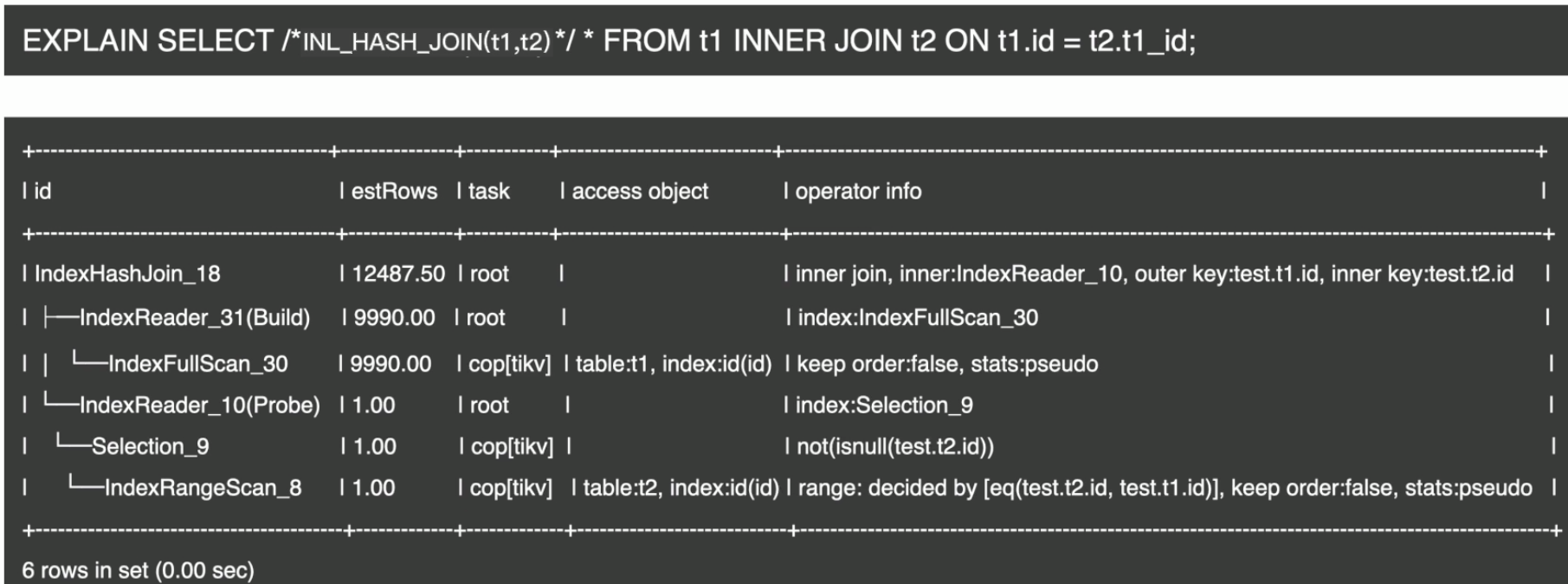
表连接–Index Hash Join
- Index Hash Join 示例
管理执行计划
优化器 Hint
- 通过 /*+ … */ 注释的行为跟在 SELECT、UPDATE 或 DELETE 后面
- Hint 不区分大小写
- 多个不同的 Hint 需要使用逗号隔开
SELECT /*+ USE_INDEX(t1, idx1, idx2) */* FROM t1;
SELECT /*+ IGNORE_INDEX(t1, idx1, idx2) */* FROM t t1;
SELECT /*+ HASH_JOIN(t1, t2) */* FROM t1,t2 WHERE t1.id = t2.id;
SELECT /*+ USE_INDEX(1,idx1), HASH_AGG(), HASH_JOIN(t1) */ count(*) FROM t t1, t t2 WHERE t1.a=t2.b;
绑定执行计划
- 创建绑定
CREATE BINDING FOR --创建绑定关键字
SELECT * FROM t WHERE a>1 --被绑定的SQL语句
USING --USING关键字
SELECT * FROM t use index(idx) WHERE a>2; --期望替换的带有hint的语句
- 查看绑定
SHOW [GLOBAL | SESSION] BINDINGS --查看绑定的关键字
SELECT * FROM t WHERE a>1 --被绑定的SQL语句
- 删除绑定
DROP [GLOBAL | SESSION] BINDING FOR --删除绑定的关键字
SELECT * FROM t WHERE a>1 --被绑定的SQL语句
统计信息管理
统计信息原理
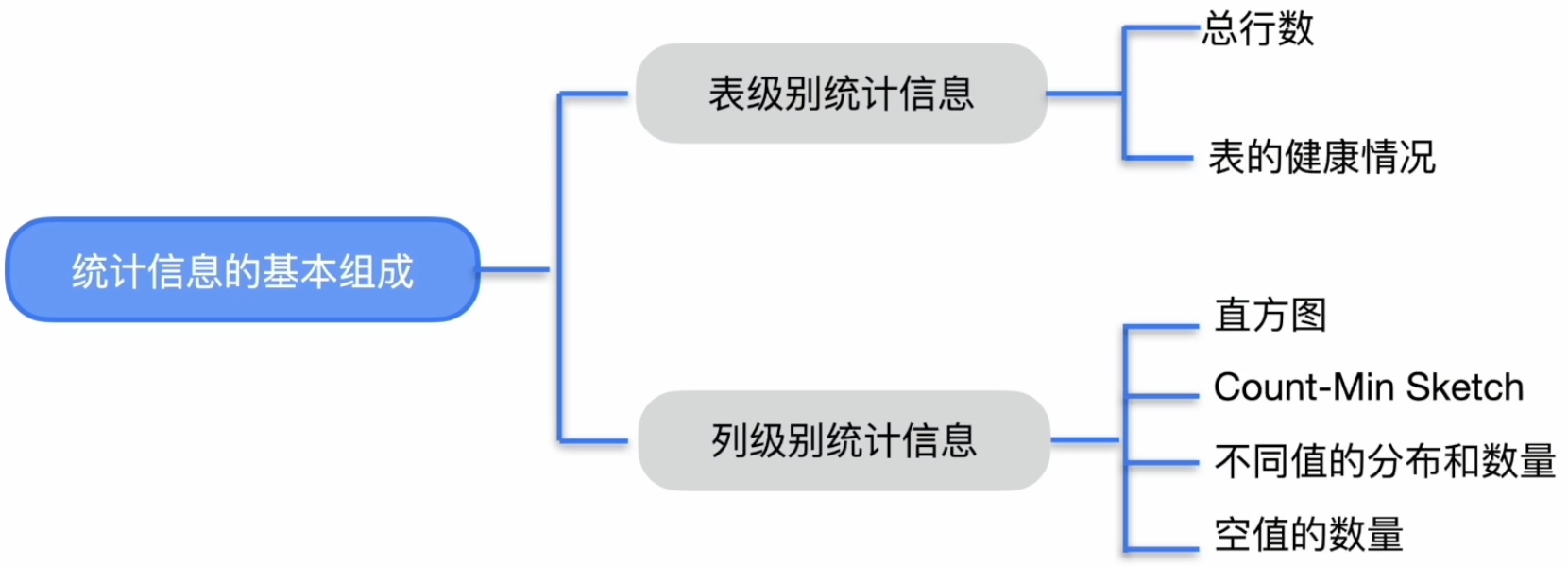
统计信息的基本组成
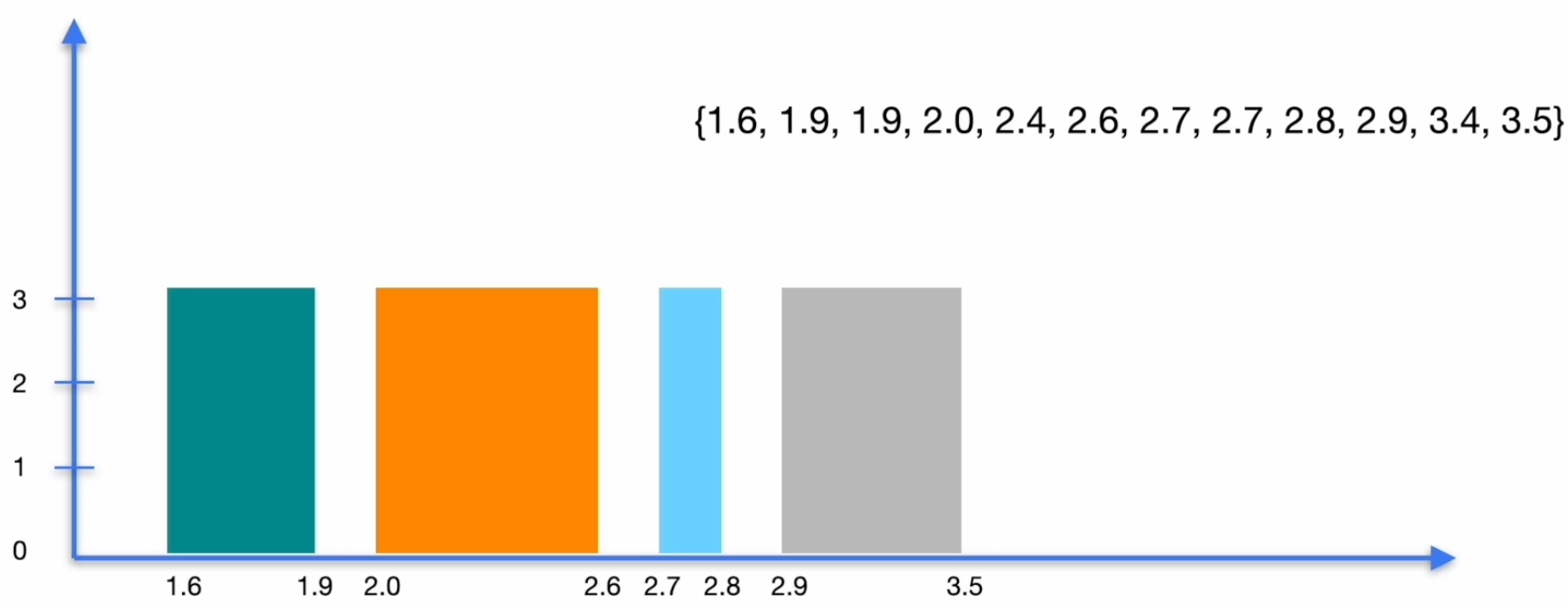
直方图
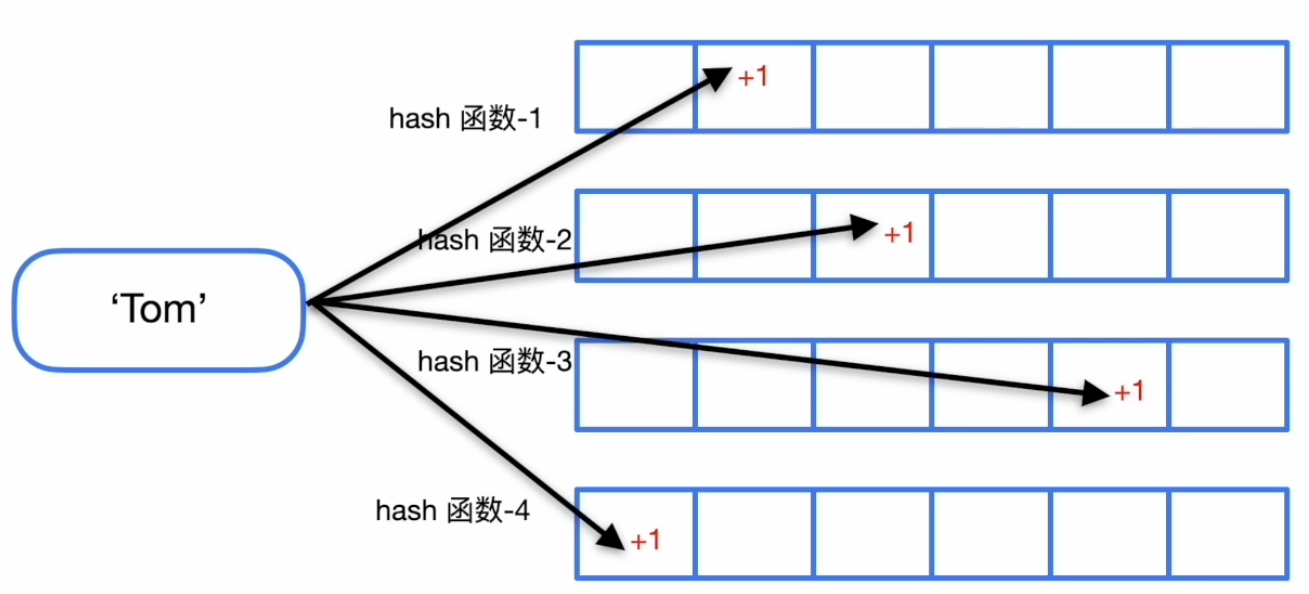
Count-Min Sketch
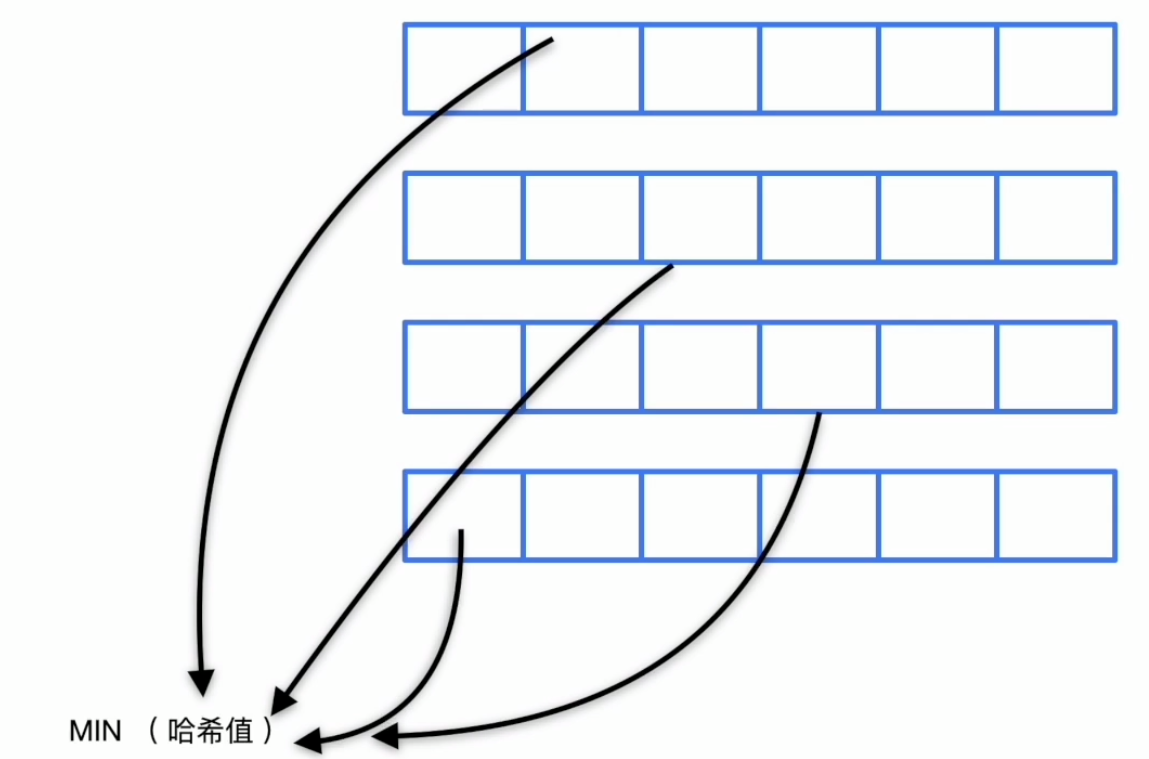
统计信息收集方法
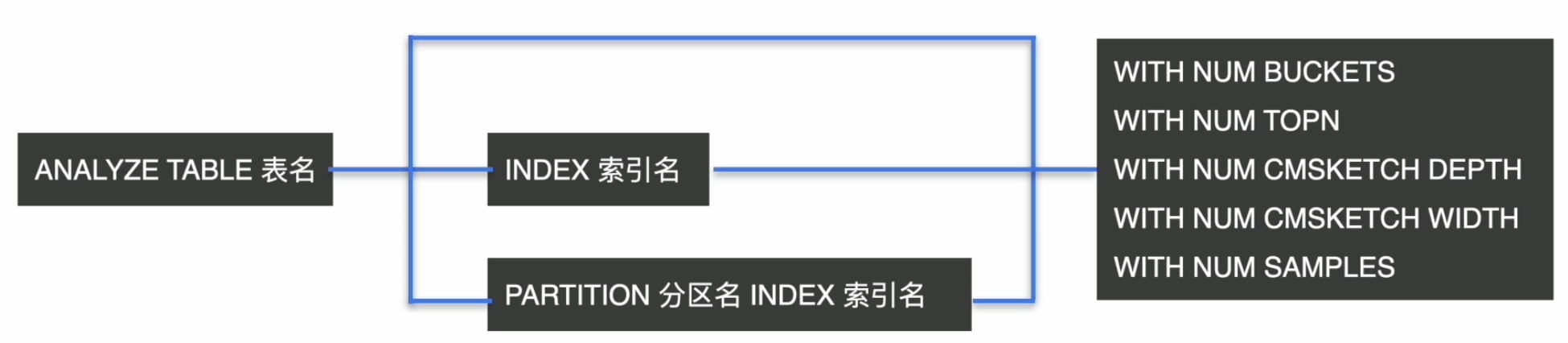
控制 ANALYZE 的并发度

自动更新统计信息
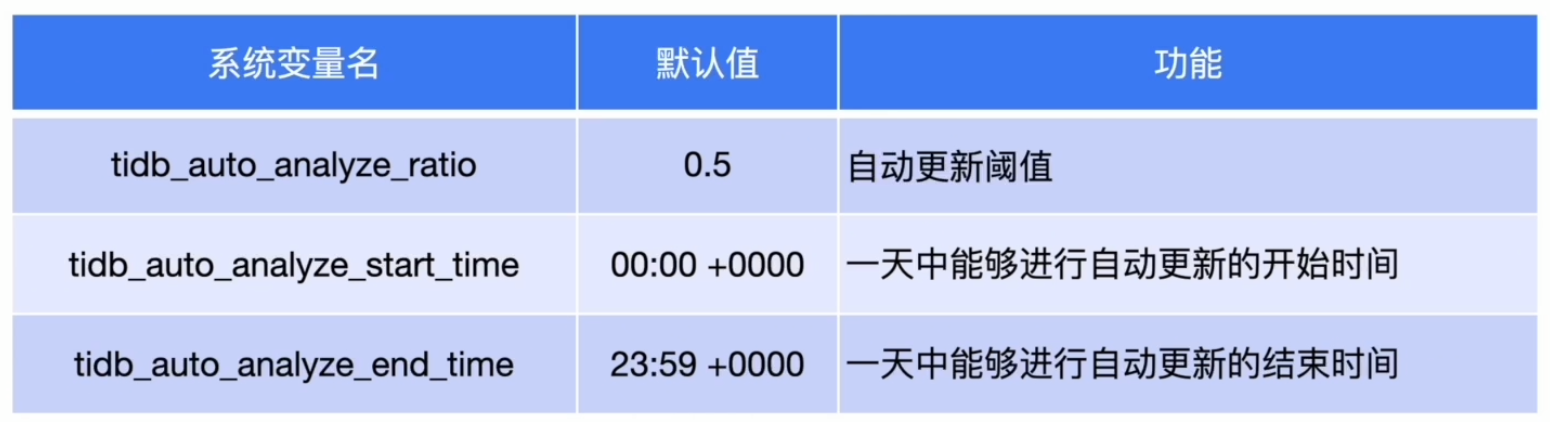
查看 ANALYZE 的状态

查看表的统计信息
- 查看表的元信息
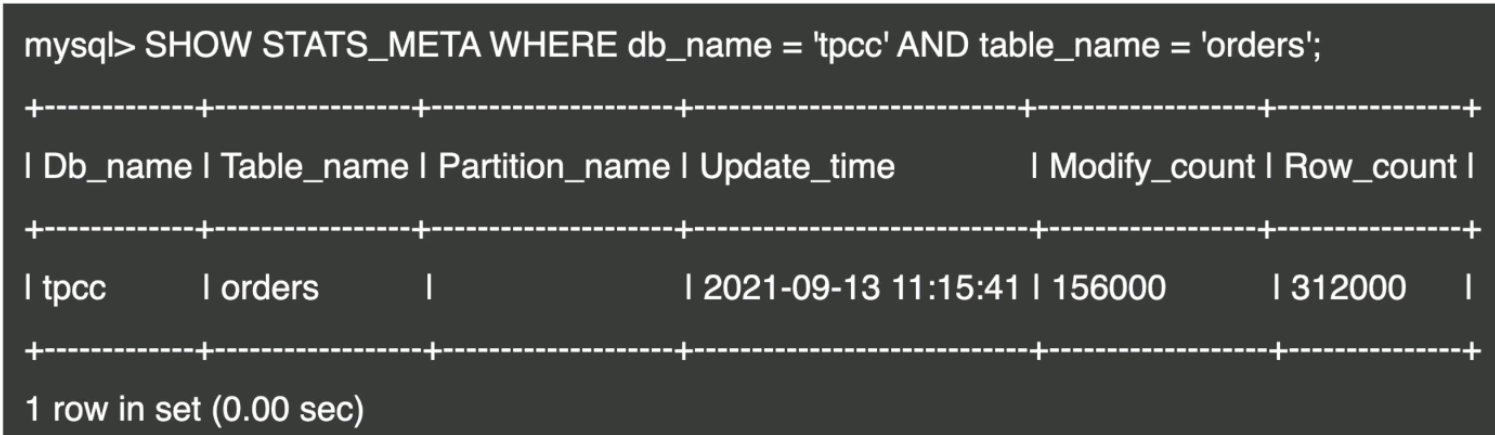
- 查看表的健康状态

- 查看列的元信息
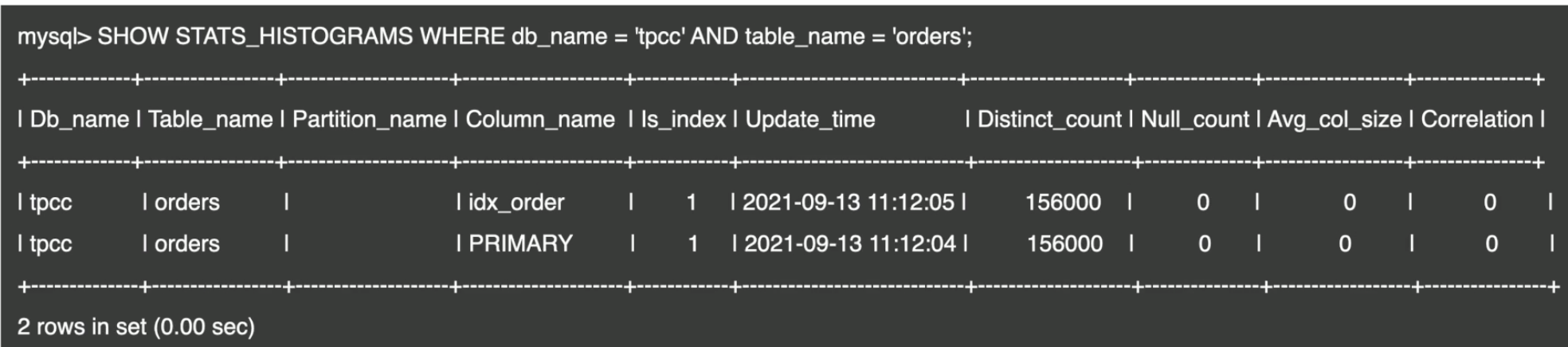
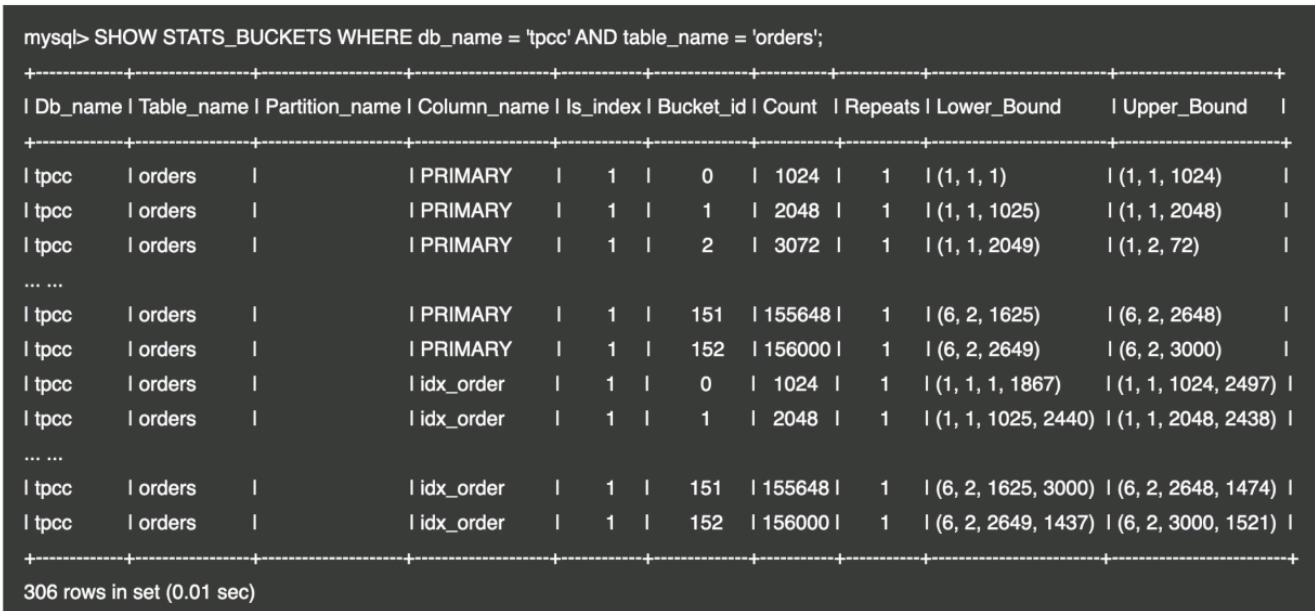
- 查看直方图的信息
导入导出统计信息
- 导出当前的统计信息∶
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}
- 导出某一时间的统计信息∶
http://${tidb-server-ip}:$(tidb-server-status-port}/stats/dump/$(db_name}/${table_name}/${yyyy-MM-dd HH:mm:ss}
- 导入统计信息∶
LOAD STATS 'file_name';
基于索引的 SQL 优化
索引的管理方法
TiDB 中的 Online DDL
TiDB 增加索引的原理
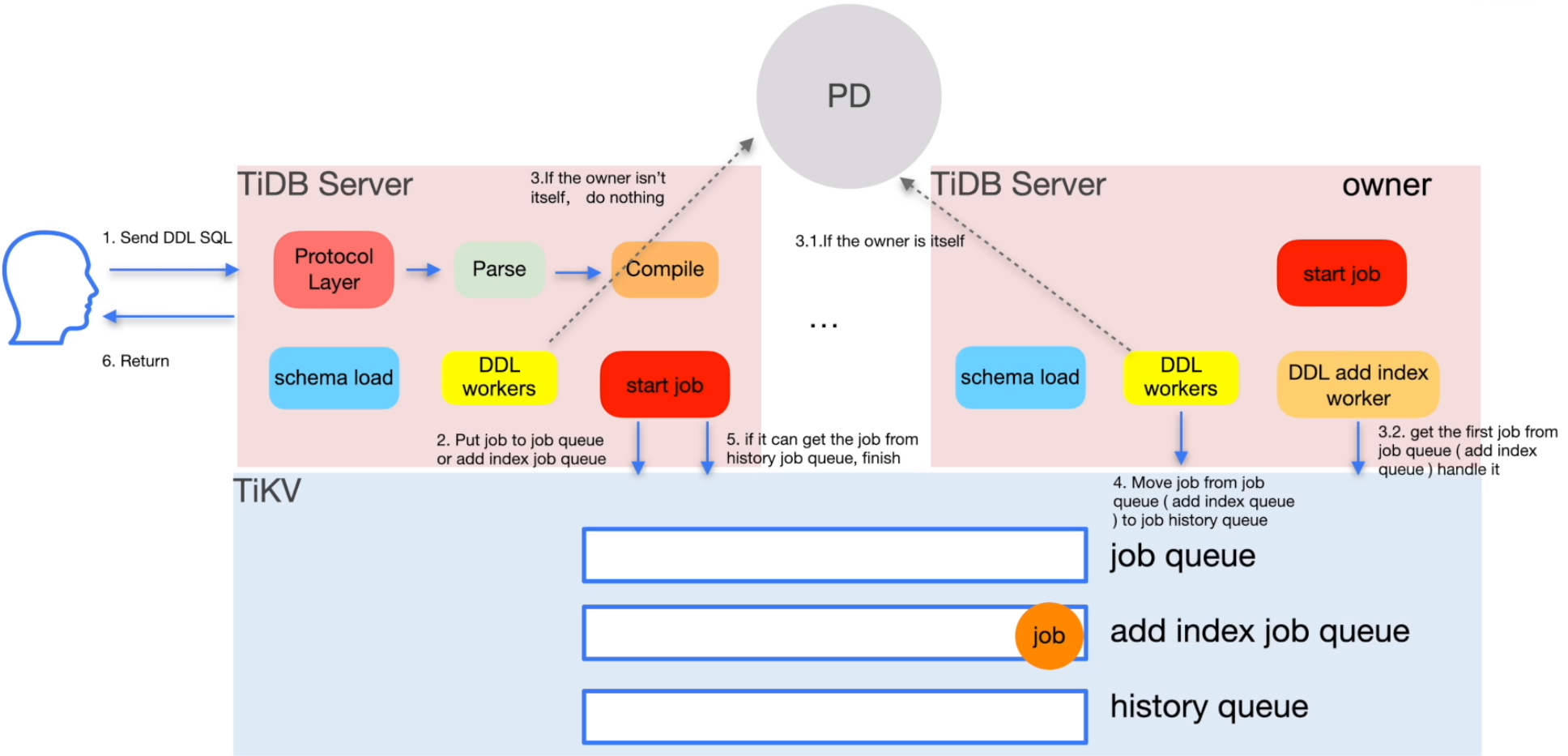
动态调整创建索引的速度
| 参数 | 默认值 | 说明 |
|---|---|---|
| tidb_ddl_reorg_worker_cnt | 4 | 控制 DDL 操作 re-organize 阶段的并发度 |
| tidb_ddl_reorg_batch_size | 256 | 控制每个 worker 一起回填数据单位,以 batch 为单位 |
| tidb_ddl_reorg_priority | PRIORITY_LOW | 调整创建索引优先级,参数有 PRIORITY_LOW/PRIORITY_NORMAL/PRIORITY_HIGH |
| tidb_ddl_error_count_limit | 512 | 失败重试次数,如果超过该次数创建索引会失败 |
在线创建索引时,我们需要时刻关注:
- 创建索引对系统的压力,我们可以通过 Grafana 的 dashboard 来查看系统的压力
- 创建索引的速度,当系统压力不大的时候,我们可以适当的调整创建索引的速度
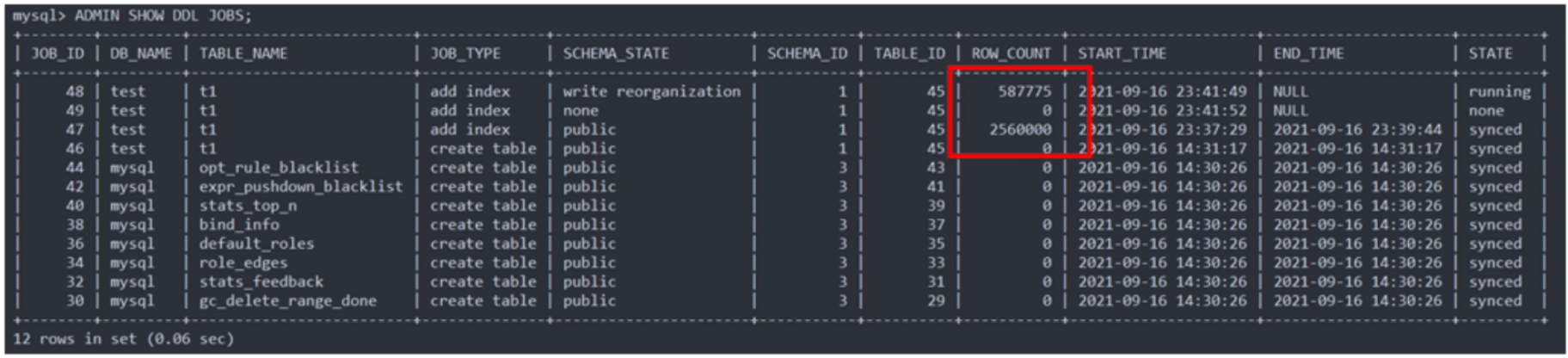
增加索引对于线上业务的影响
目标列上存在频繁读写的场景
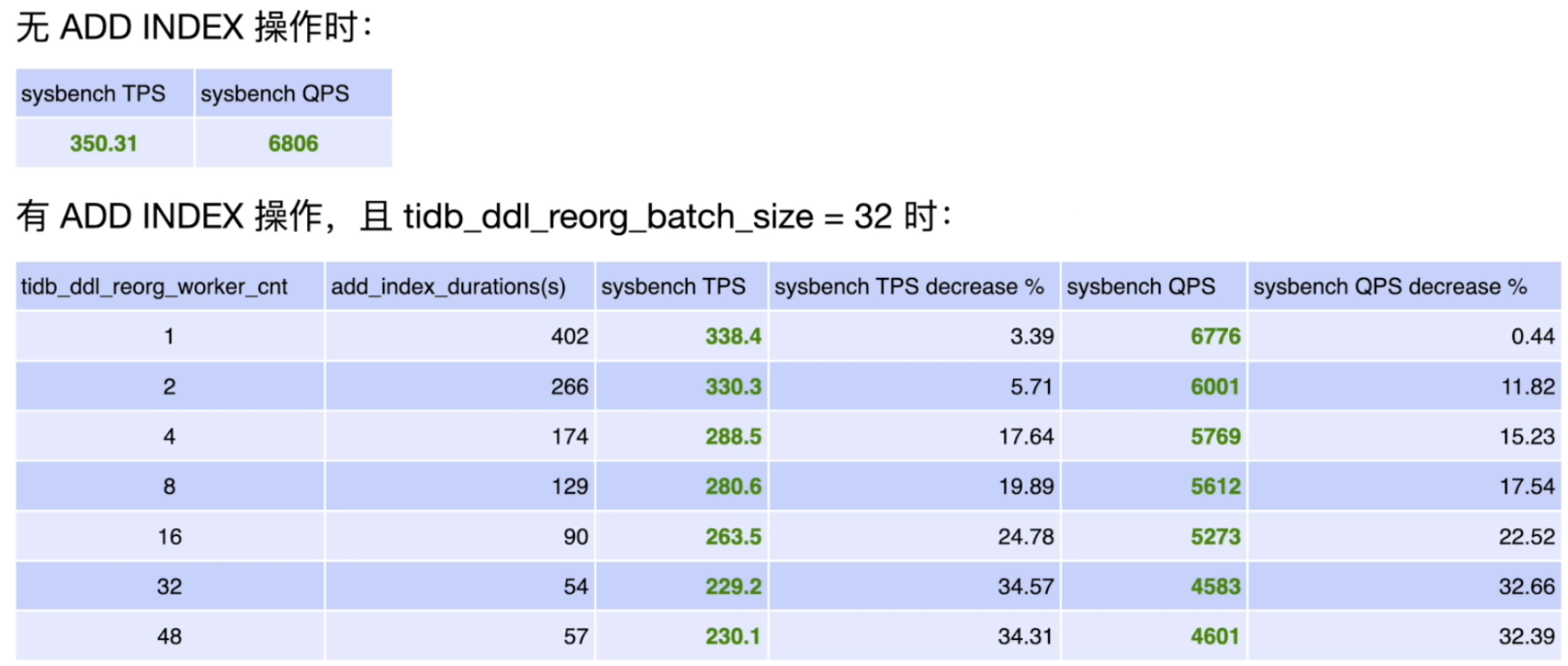
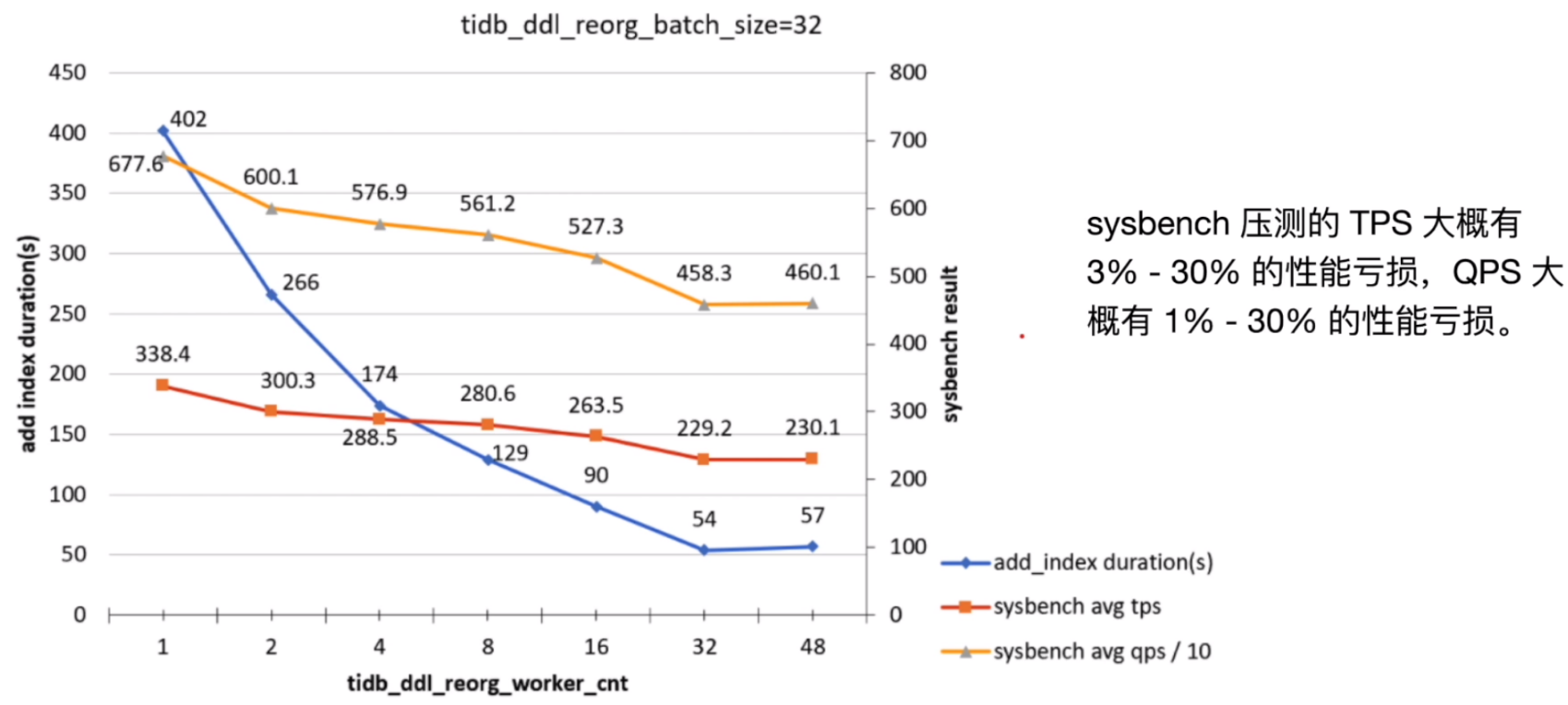
随着两个参数(tidb_ddl_reorg_worker_cnt 与 tidb_ddl_reorg_batch_size) 的逐渐增大,影响主要来源于 ADD INDEX 与 Column Update 并发进行造成的写冲突,系统的表现反应在:
- TiKV_prewrite_latch_wait_duration 有明显的升高,造成写入变慢。
- admin show ddl 命令可以看到 DDL job 的多次重试,此时 ADD INDEX 会持续非常久才能完成。
目标列只读场景
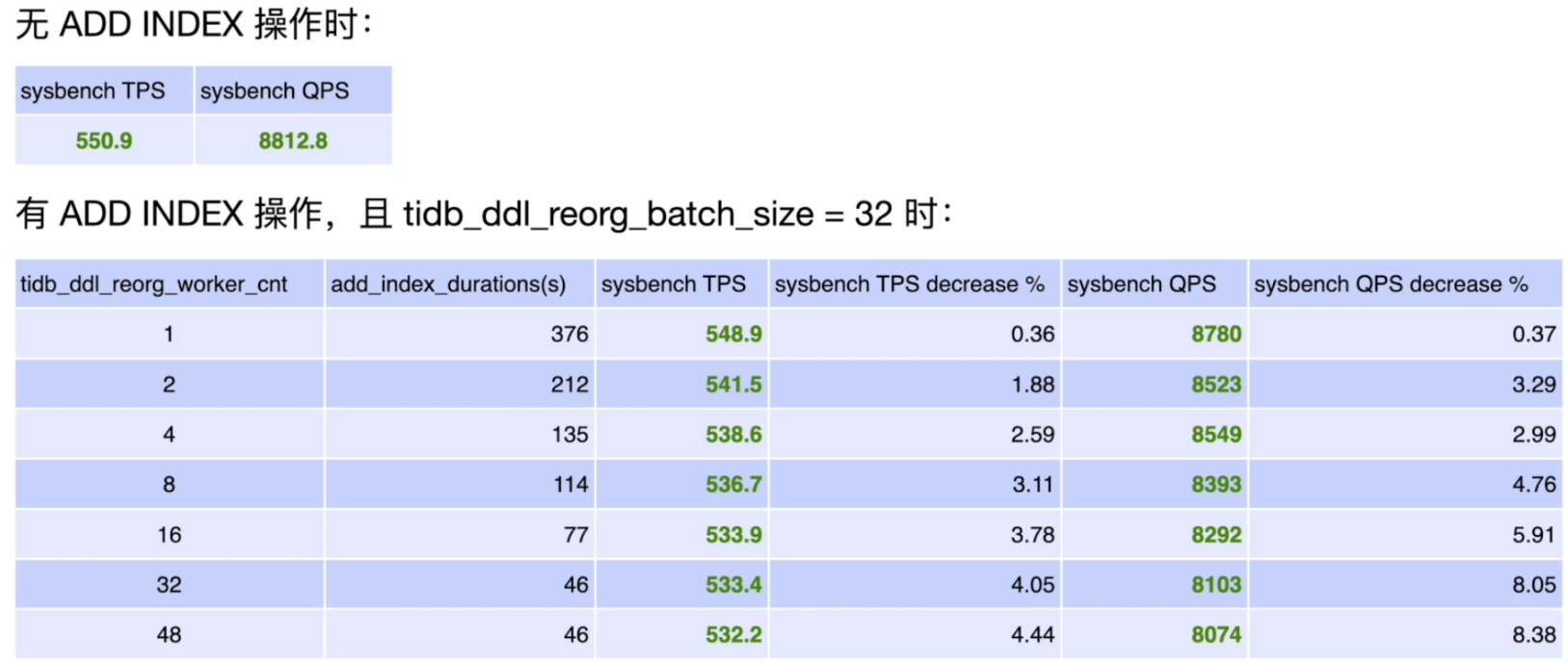
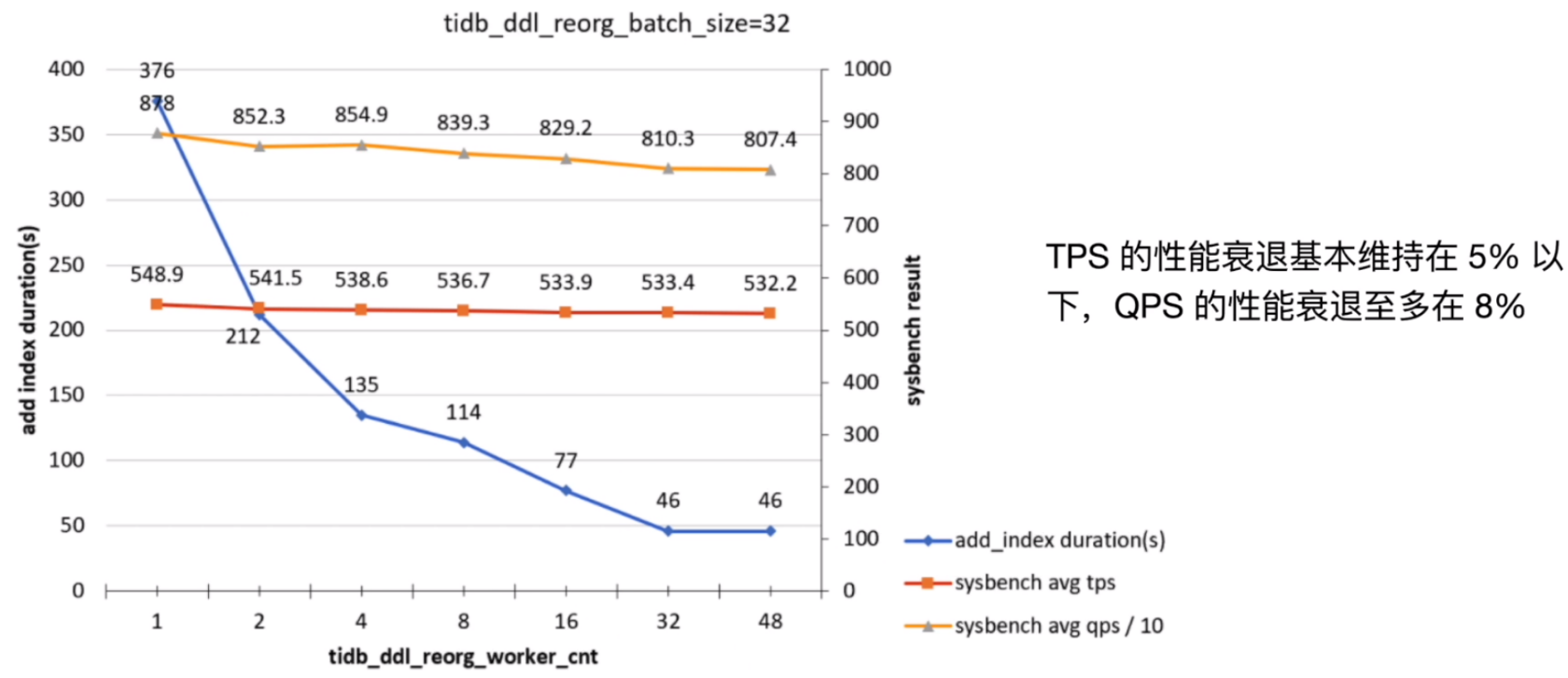
目标列不涉及读写的场景
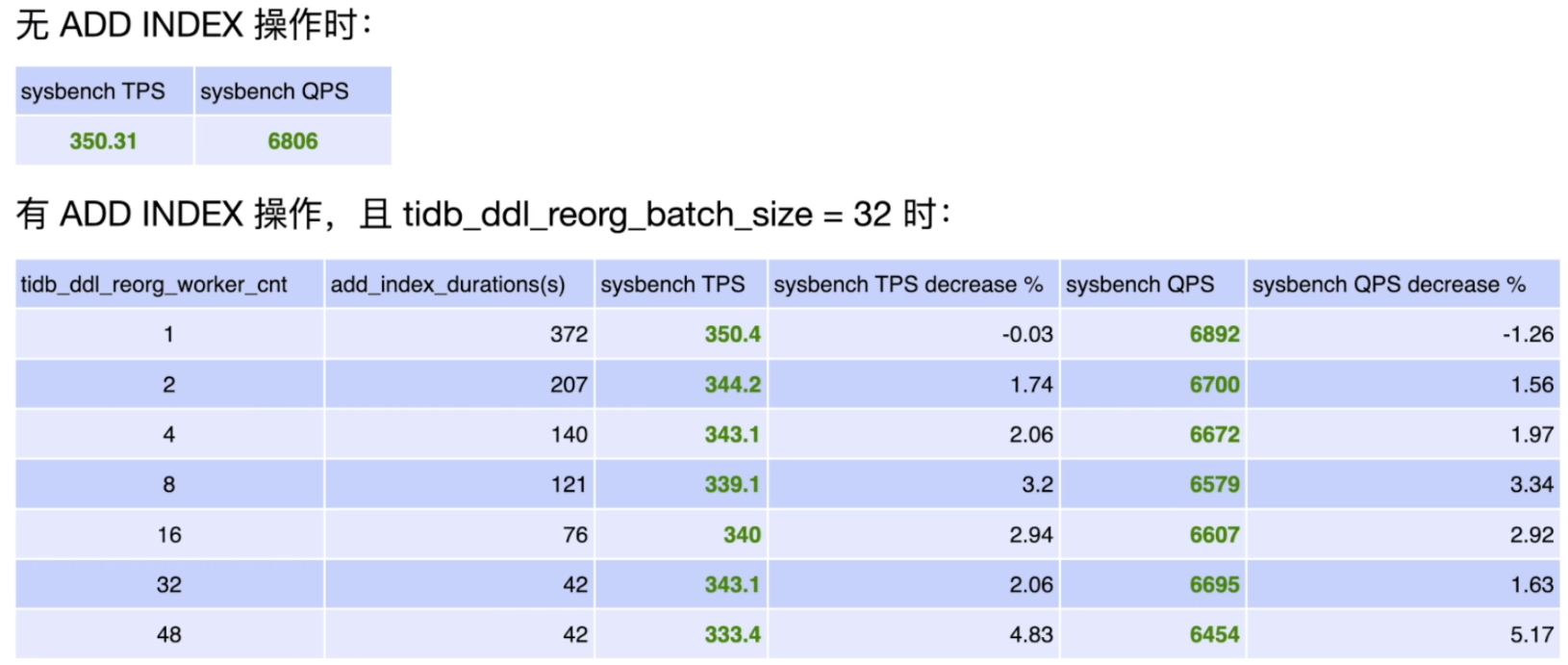
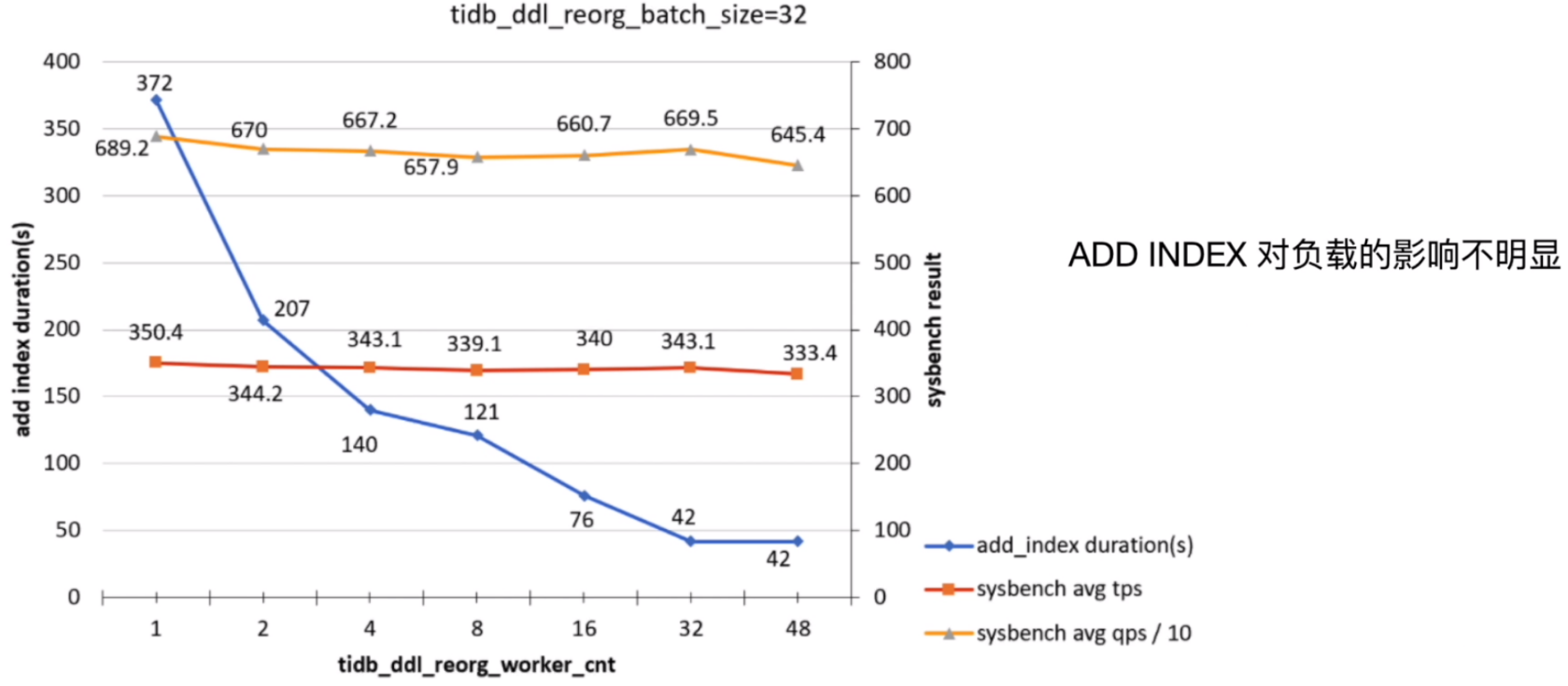
总结
- 目标列被频繁更新(包含 UPDATE、INSERT 和 DELETE)时,默认配置会造成较为频繁的写冲突,使得在线负载较大
- 当 ADD INDEX 的目标列仅涉及查询负载,或者与线上负载不直接相关时,可以直接使用默认配置
- ADD INDEX 也可能由于不断地重试,需要很长的时间才能完成。
索引扫描的方式
Point Get 与 Batch Point Get

要使得优化器能够选择 PointGet 算子,需要满足几个条件:
- 返回的值至多只能有一个,或者说没有返回结果
- 一定要有唯一键,有主键或者唯一索引
Index Full Scan
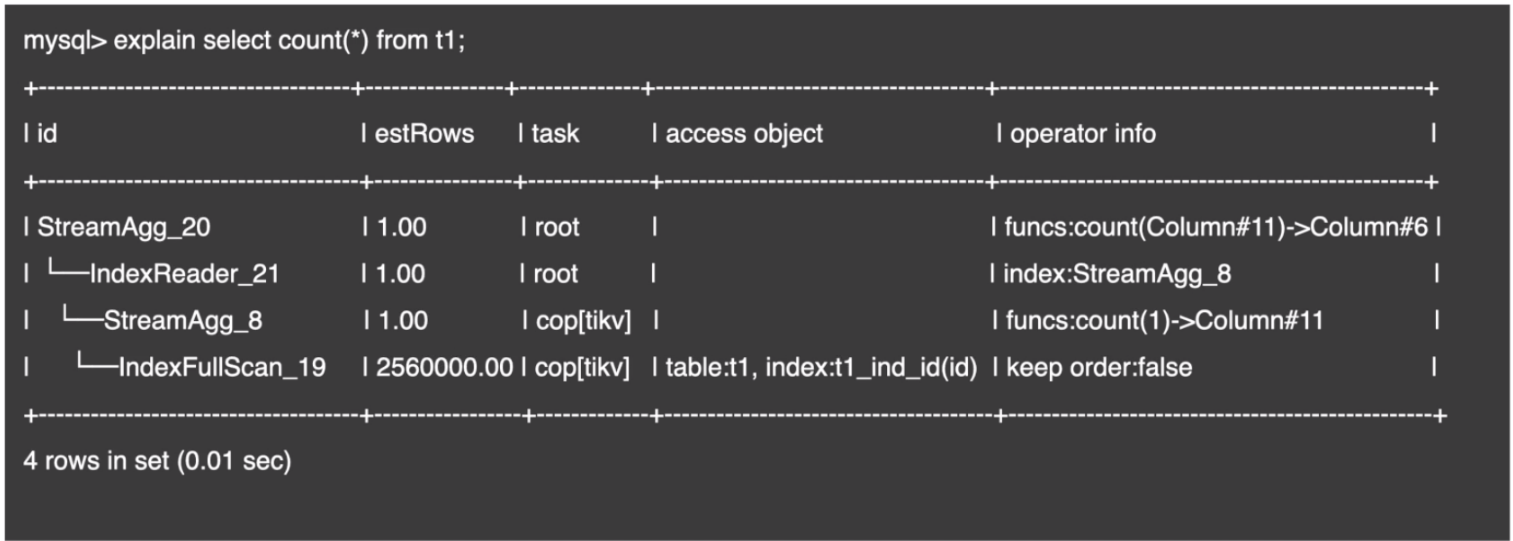
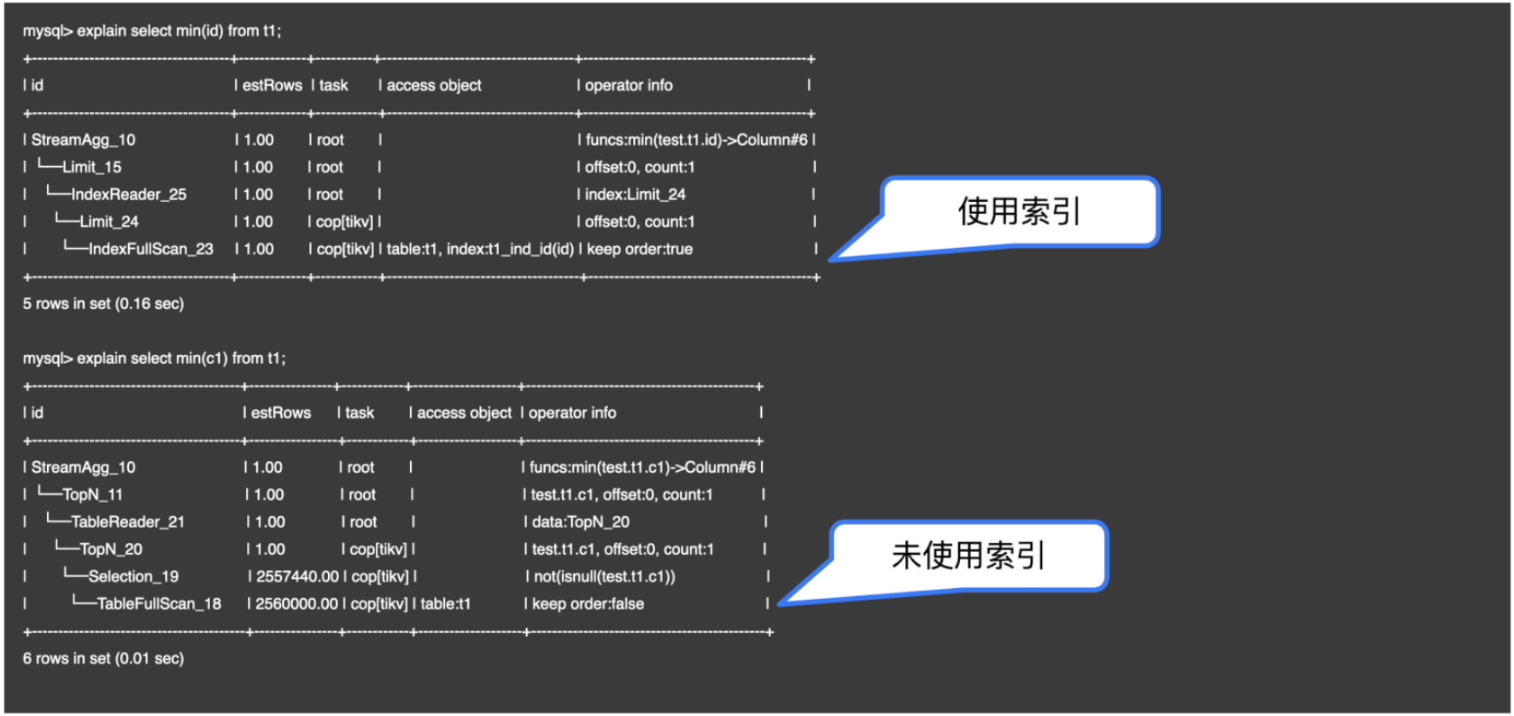
Index Range Scan

索引选择的维度
TiDB SQL 优化实战
问题 SQL 与慢 SQL 的定位
快速定位到有问题的SQL
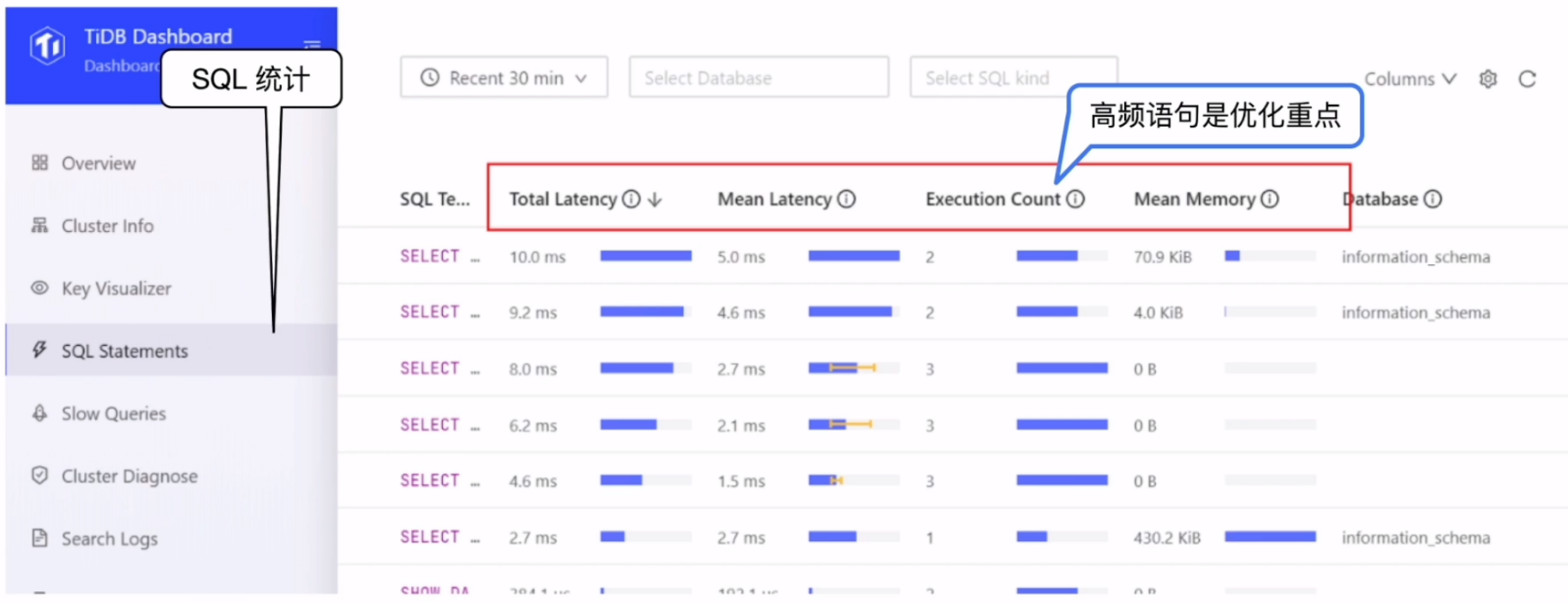
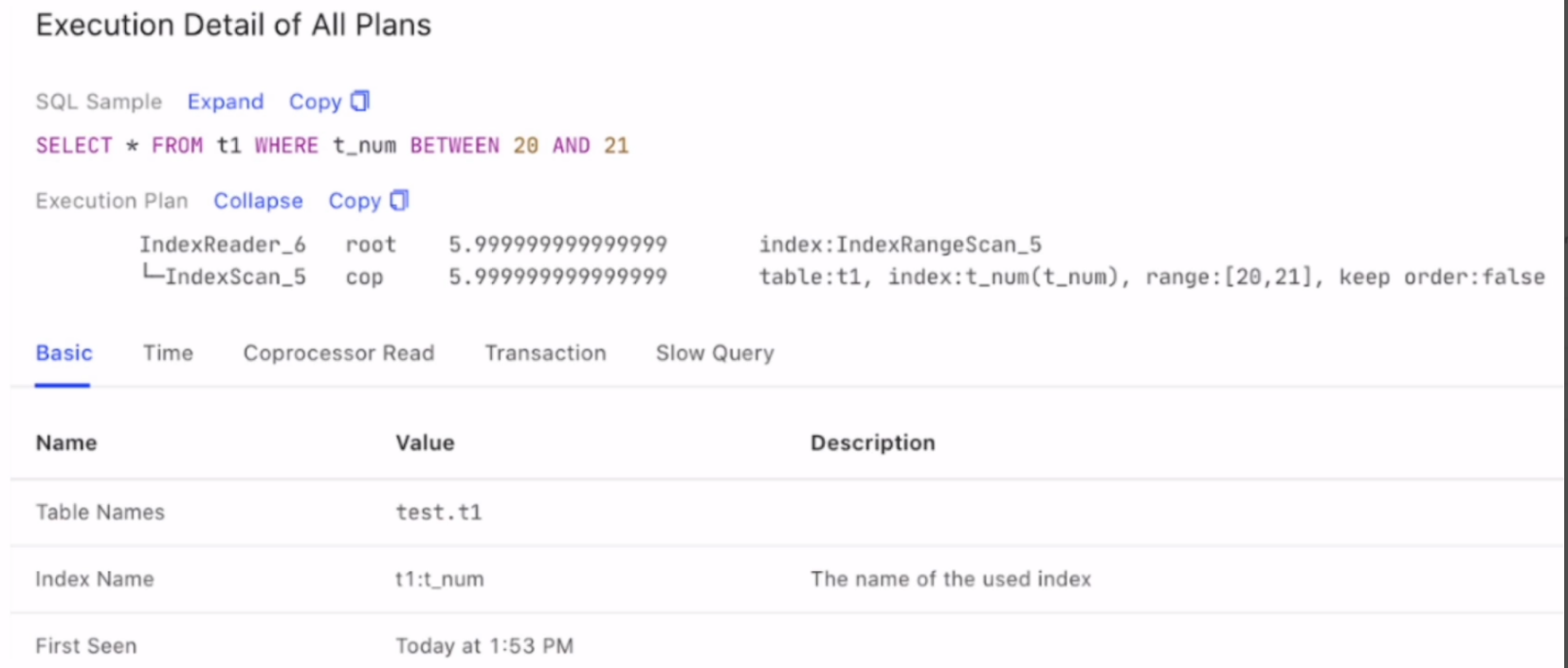
快速定位慢查询
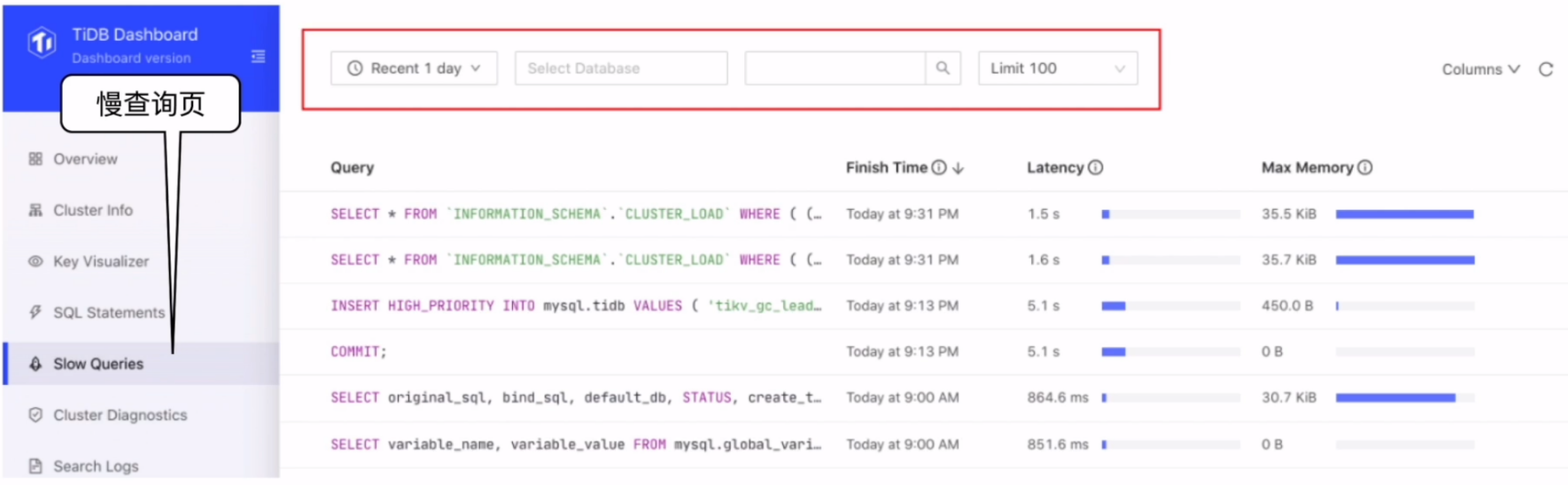
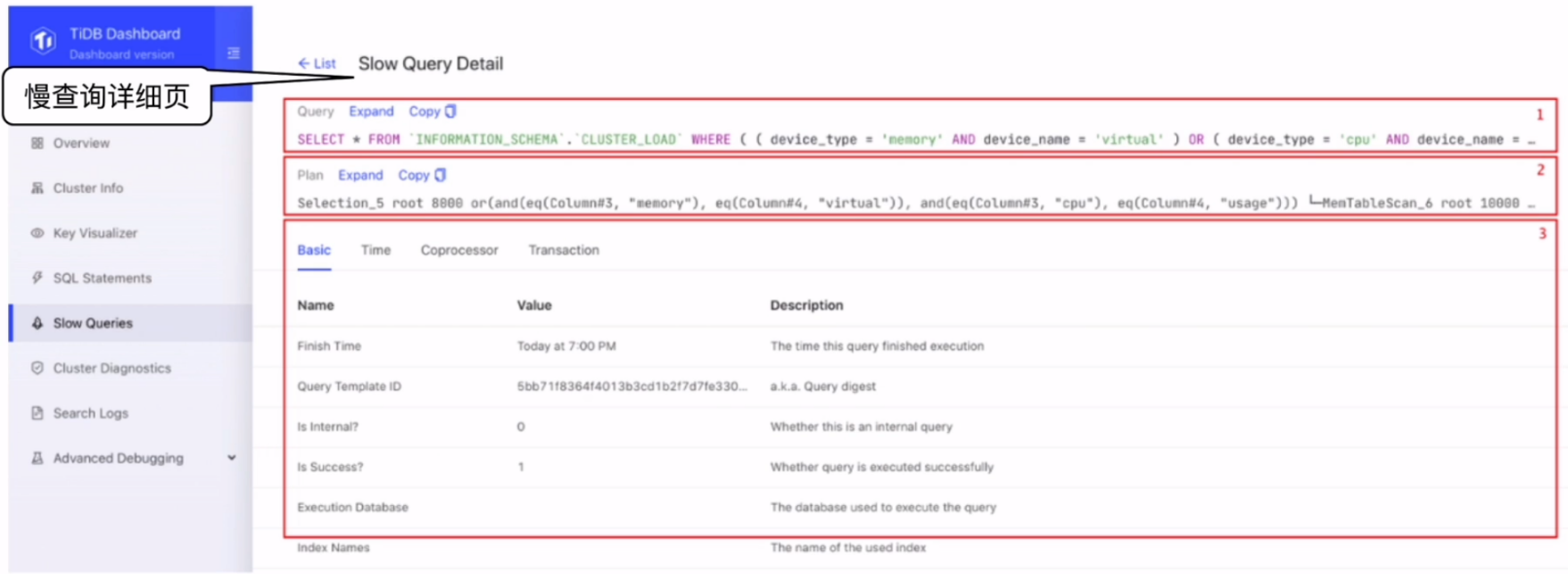
DML语句优化
大量 DML 操作导致 O0M
- 背景

- 现象

- 解决
方案一:
通过 hint 或者 use index 的方式强制走索引
问题:在大量读取数据的场景,强制走索引很有可能会带来更差的效果。
方案二:
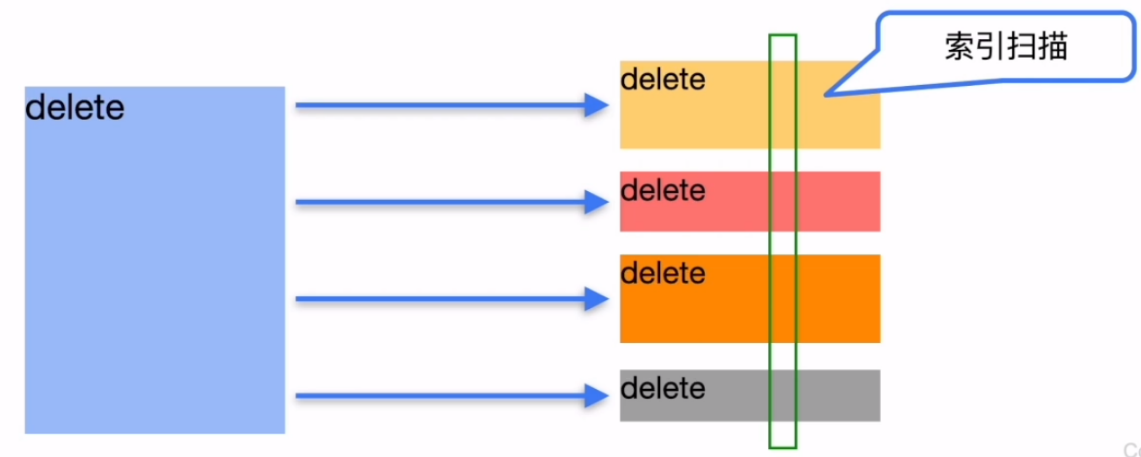
基于执行计划的优化
执行计划不稳定导致查询延迟增加
- 背景
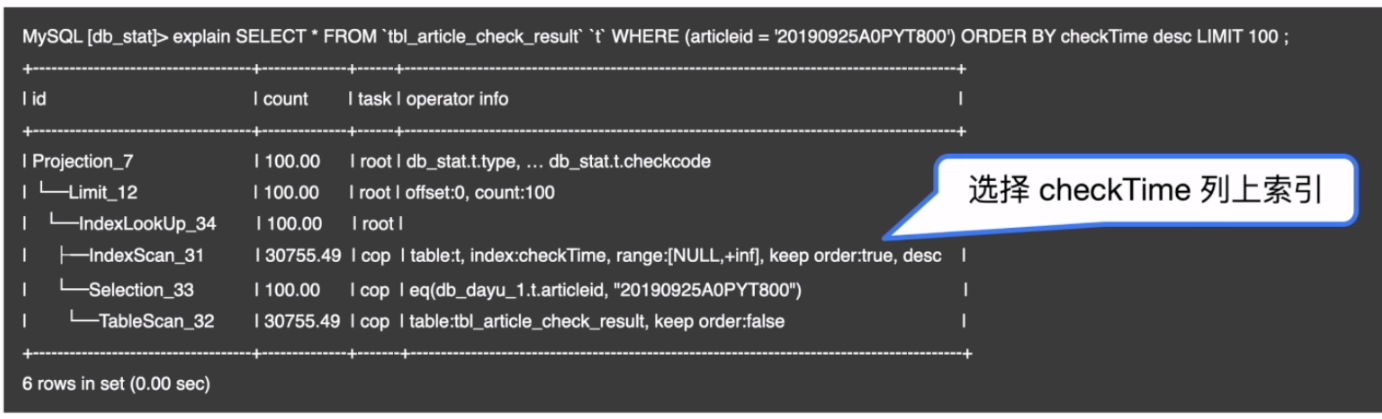
- 现象
执行计划不稳定可能会导致业务的相应延迟升高,duration 出现抖动的情况。 - 解决
方案一: 及时收集统计信息 - 考虑使用 analyze table 来手动收集统计信息,或者结合 cron job 的方式。
- 调整 tidb_auto_analyze_ratio、tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 参数提高收集的频次,扩大收集的窗口时间。
方案二: 更改执行计划
- 使用 hint 或者 use index 语句固化执行计划。
- 使用 sql hint 的方式更改执行计划。
SQL 执行计划不准
- 背景

- 执行计划
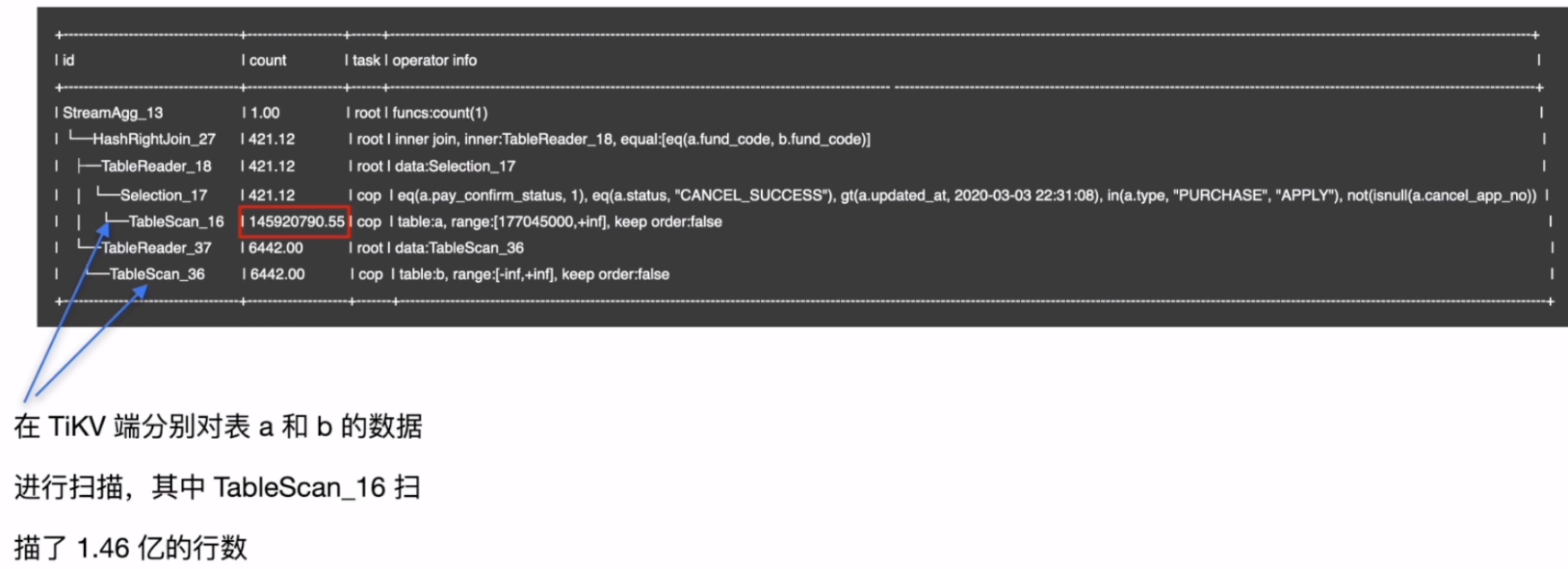
- 索引分析

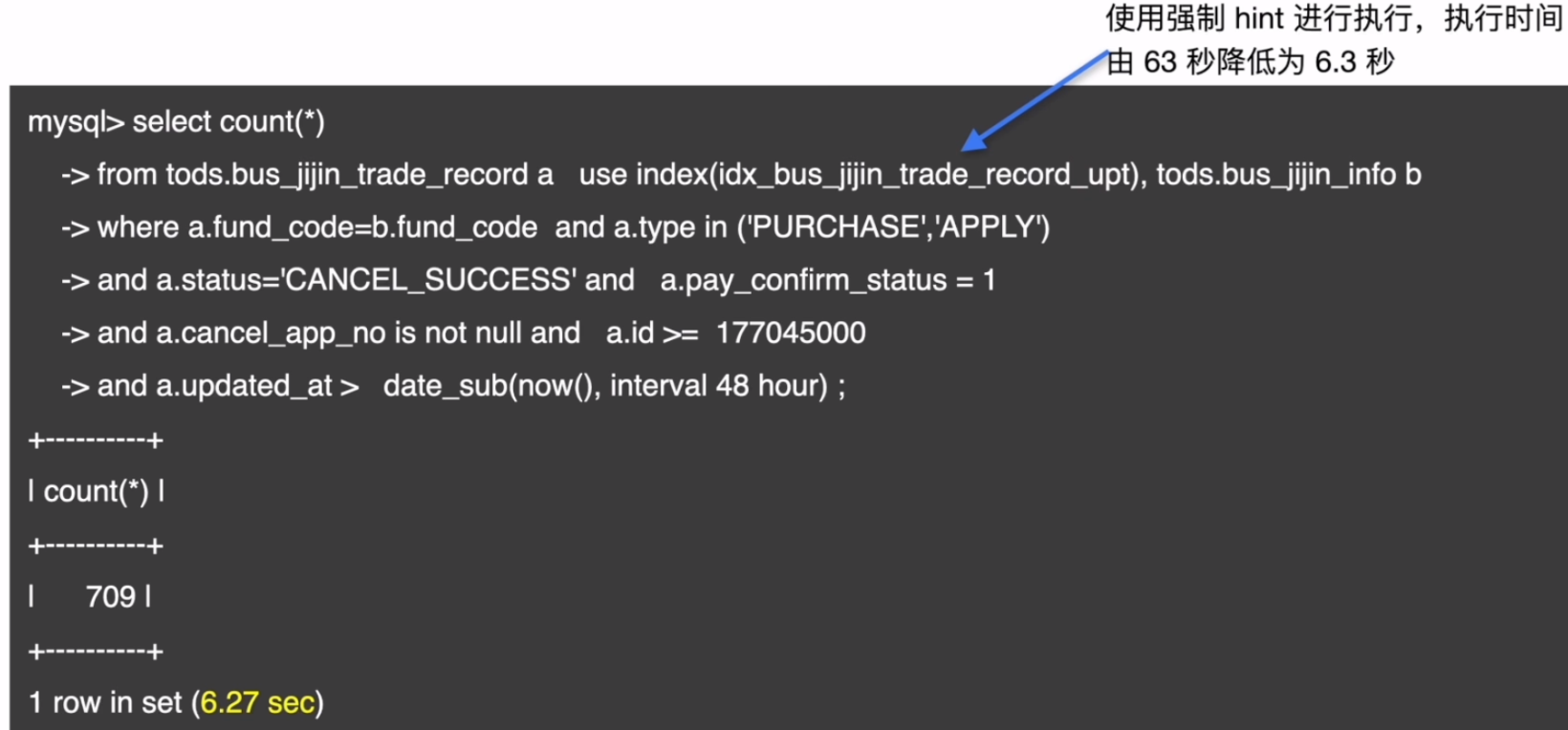
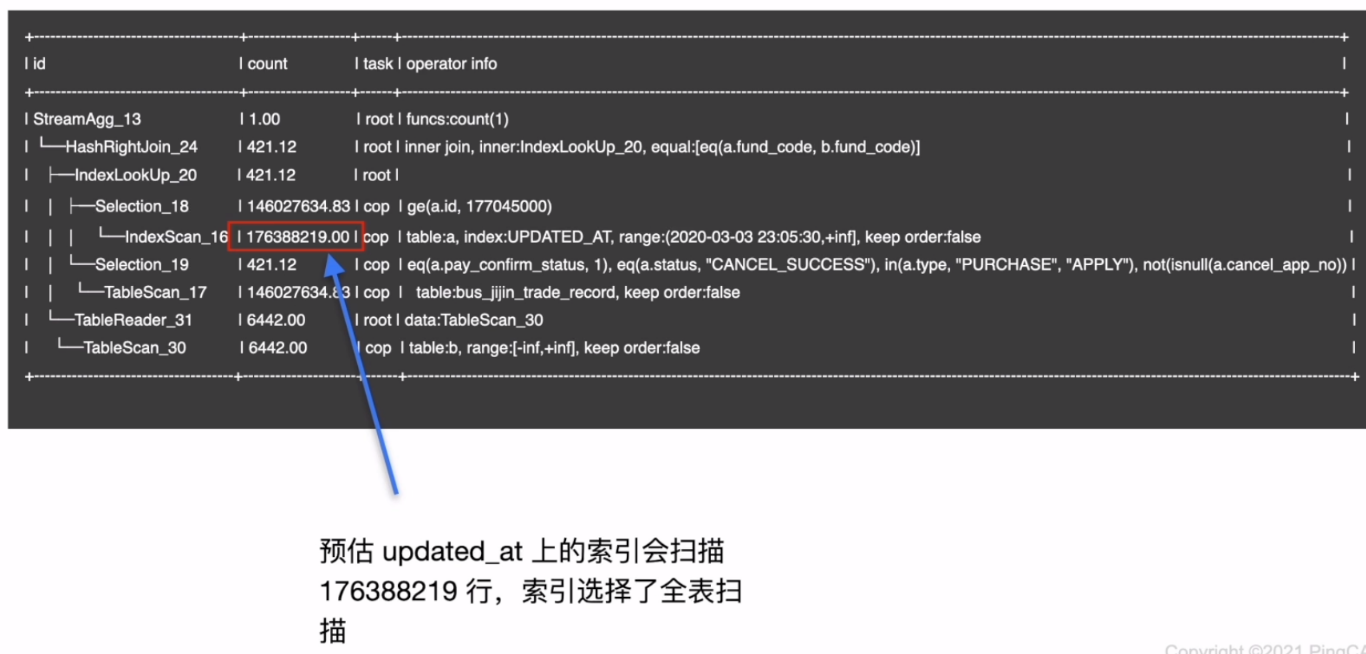
- 统计信息分析
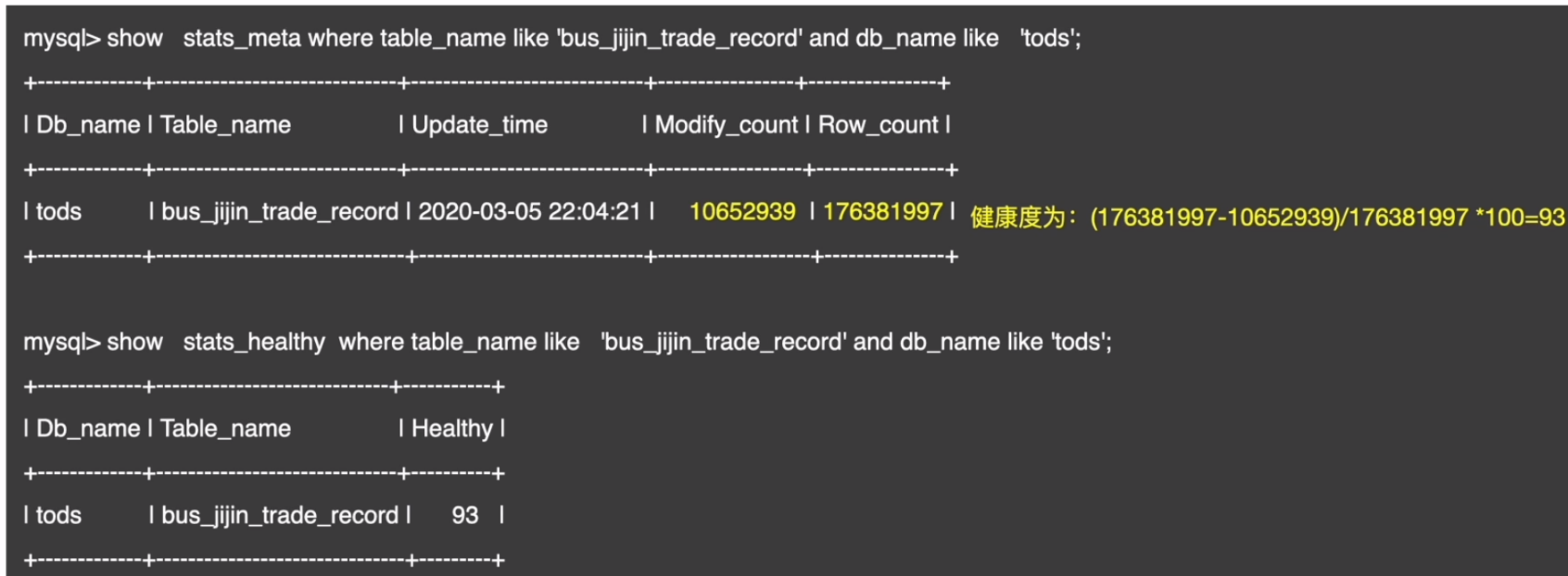
- 统计信息收集后
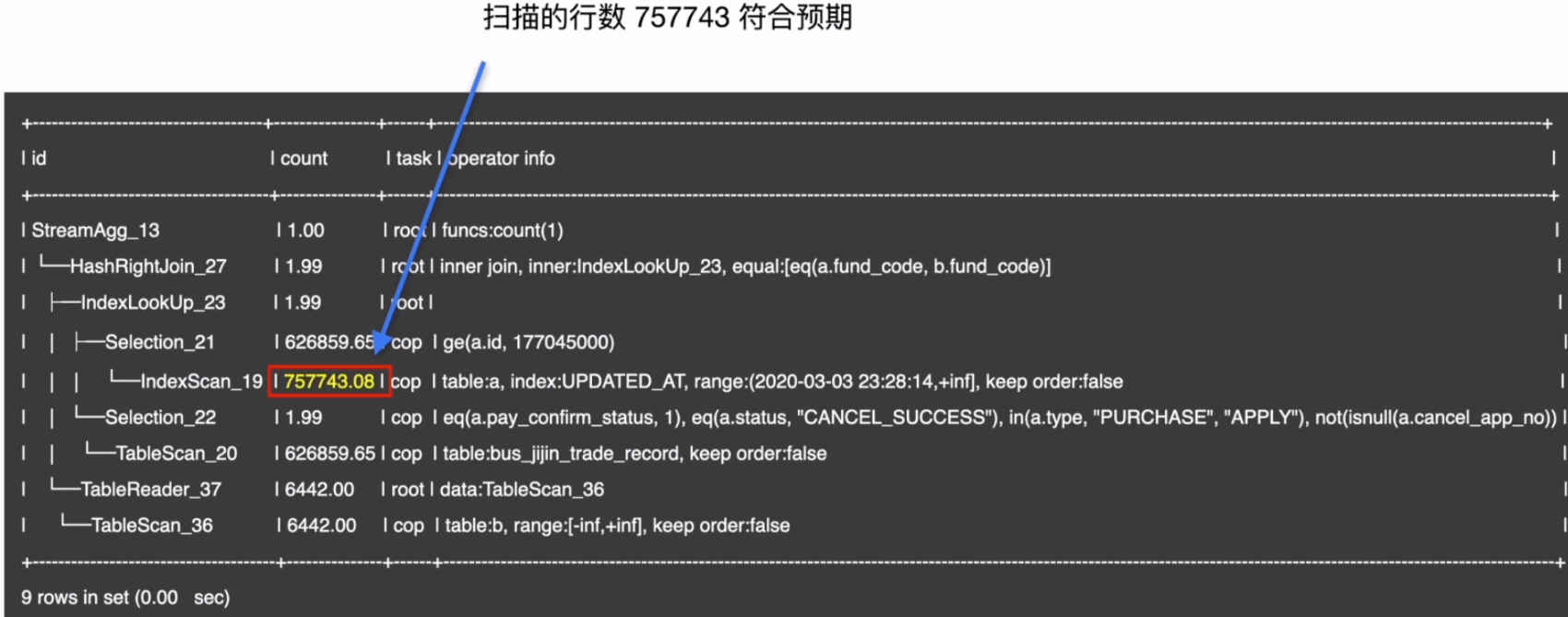
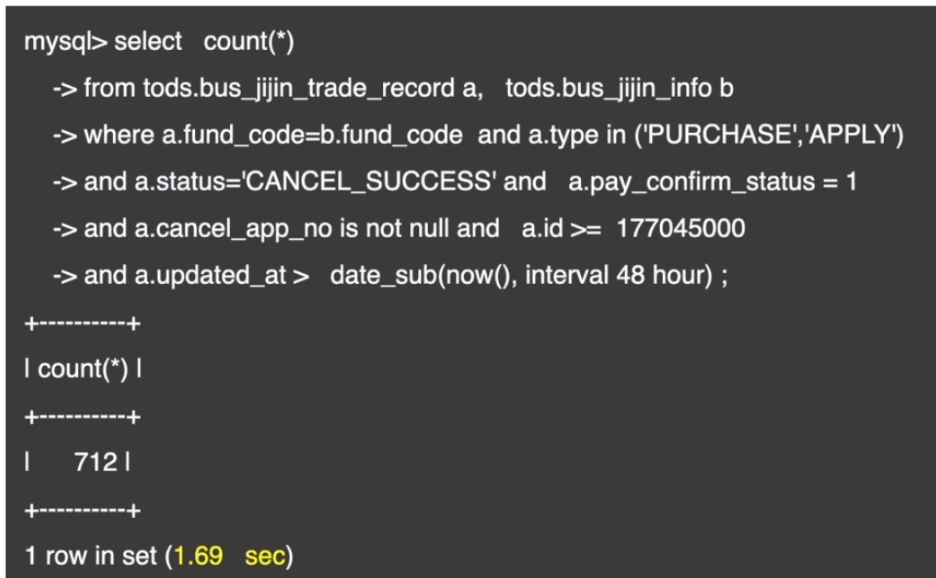
- 验证结果
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
