




大家应该都接手过这种项目,前人找一个开源软件改一改,发上线。
我这里便曾经遇到过类似的问题。
随着需求的增加,各种维护人员东改改西改改,原来的开源项目被改的面目全非,再也无法和上游合并。
甚至TLS协议栈被改掉,不再兼容HTTPS协议。
然后有些人基于这个代码又拖出来一份新代码,实现自己的功能。
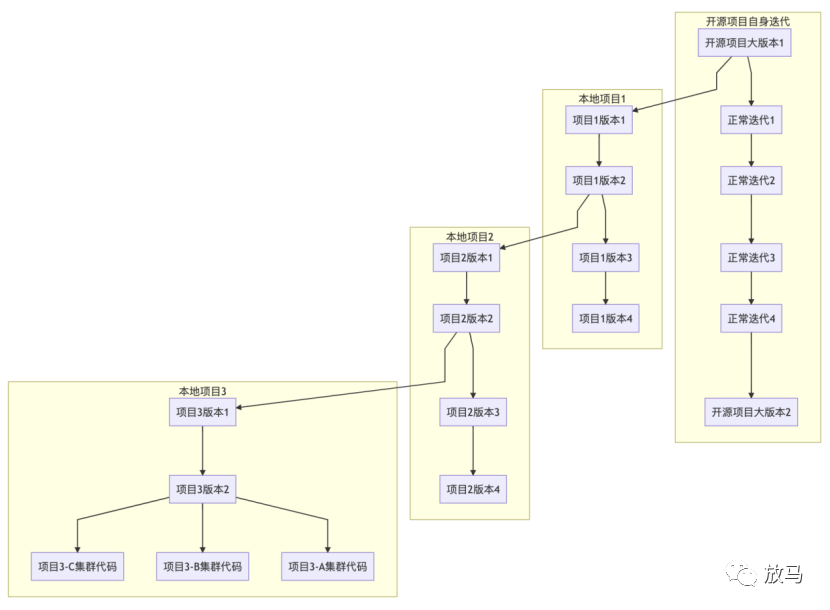
核心代码被魔改,各种变量删的删,想法是好的,“方便维护”,“方便开源”,“方便KPI”,结果是睿智的。
这几个软件再也无法合并到上游,甚至彼此之间互相独立,成了三个仓库、五个分支、八个应用,更别说跟着开源项目一起更新。
最后这些项目因为都属于流量相关,最终流转到我这里。
我第一次理清这些关系的时候,高兴的一夜没睡觉。
本次apisix网关源码阅读和整理,便是为了摸透整个系统,归纳出最佳实践方案,避免自己像前人一样到处魔改,导致整个系统最终很难维护。
apisix选型
选择apisix的原因很简单,apisix解决了nginx两个最大的问题:“动态路由”、“动态证书”,大大方便了nginx网关的维护工作。同时得益于nginx+luajit,apisix的性能还算不错。
除此之外,apisix提供了相对比较完善的插件模式,方便我们进行插件的二次开发,在接下来的文章中我们会详细介绍apisix的源码和二次开发。
apisix实现方案
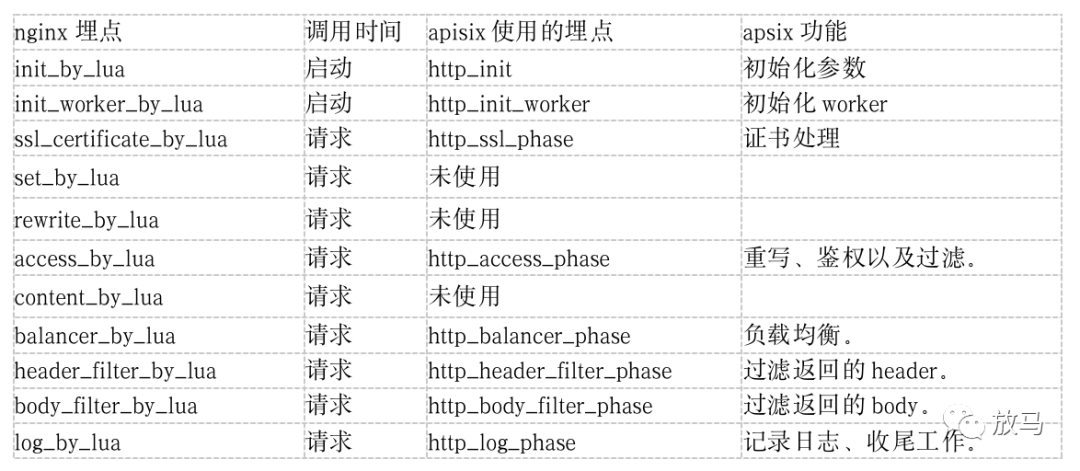
Tengine/Openresty的nginx-lua模块在nginx中预设了lua埋点,nginx在执行对应的模块时,会先调用对应的lua埋点,然后继续向下执行。
Apisix 则是基于这些埋点,做到了动态 host、动态证书等功能。
对于配置变更,则是监听etcd,使用etcd实现配置管理和配置变更通知,启动的时候设置定时器回调,使用轮询监听(3s超时并启动下一次监听)来进行变更监听。
再加上 nginx 本身的高性能、热加载能力,和 luajit 本身的高性能,apisix 性能不会比 nginx 转发性能弱太多。
如果有一张图解释清楚apisix的话,那么应该是:
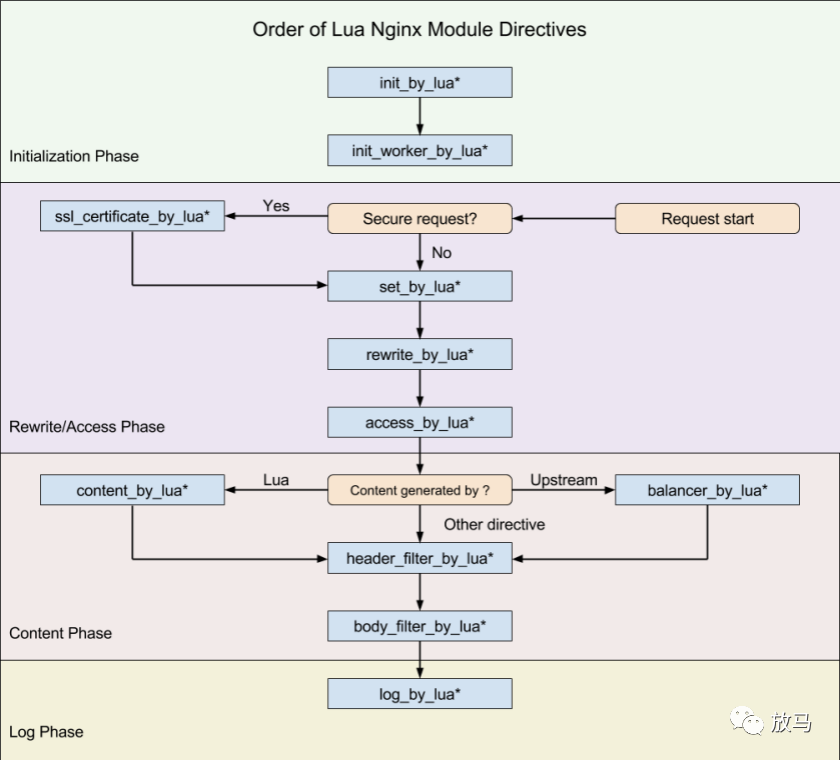
而apisix并没有使用全部的十一个埋点,而是选择了其中的八个埋点,分为两个部分:初始化部分和请求部分。
证书处理,ssl_certificate_by_lua_block,执行apisix.http_ssl_phase()
未使用埋点:set_by_lua、rewrite_by_lua,其中rewrite功能由access_by_lua_block块代为实现。
请求处理,access_by_lua_block,执行apisix.http_access_phase()
请求代理:balancer_by_lua_block,执行apisix.http_balancer_phase()
请求返回头过滤:header_filter_by_lua_block,执行apisix.http_header_filter_phase(),调用header_filter插件。
请求返回body过滤:body_filter_by_lua_block,执行apisix.http_body_filter_phase(),调用body_filter插件。
日志模块:log_by_lua_block执行apisix.http_log_phase()
apisix概念
apisix共有三个概念:route、service、upstream。
Route 就是路由,通过定义一些规则来匹配客户端的请求,然后根据匹配结果加载并执行相应的 插件,并把请求转发给到指定 Upstream或者Service。
一个路由建议指向一个或者多个域名+uri。
Service 是某类 API 的抽象(也可以理解为一组 Route 的抽象)。它通常与上游服务抽象是一一对应的,Route 与 Service 之间,通常是 N:1 的关系。
Upstream 是虚拟主机抽象,对给定的多个服务节点按照配置规则进行负载均衡。虽然Upstream 的地址信息可以直接绑定到 Route(或 Service) 上,但是仍然建议单独配置Upstream,并通过“引用”的方式避免重复。
apisix初始化
apisix的初始化流程分为两步:http_init和http_init_worker,http_init执行一次,而http_init_worker则是每个worker执行一次。
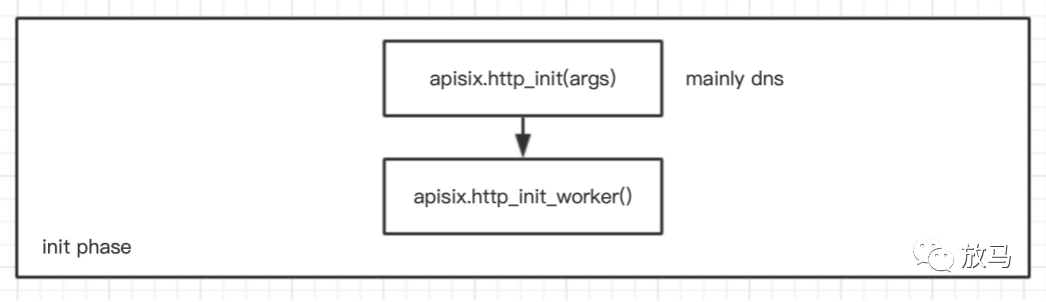
http_init 初始化函数> set: jit_stack_size jit.opt 设置一些luajit的参数> randomseed 初始化随机种子> parse_args set DNS 设置DNS> core.id.init() 初始化随机ID,用于后期的健康检查、状态上报。
http_init_worker初始化worker,每个worker执行一次。> apisix.discovery.init_worker > 初始化服务发现中心(仅支持eureka)> apisix.balancer.init_worker() > 监听 etcd upstreams> apisix.admin.init.init_worker() > 初始化 apisix/admin 管理路由> router.http_init_worker()> apisix.http.router.radixtree_uri.init_worker() > 开始监听 etcd routes 并生成 http 路由> apisix.http.router.radixtree_sni.init_worker() > 开始监听 etcd ssl 监听证书> 监听 etcd global_rules 全局插件> apisix.http.service.init_worker() > 开始监听 etcd services 监听服务> plugin.init_worker() 插件加载逻辑> load plugin 加载插件> foreach load_plugin()> _plugin_.init() 调用插件init方法> sort by priority 对所有(包括未加载)的插件按照优先级排序> load stream plugin 加载流处理插件> default only mqtt 目前仅支持mqtt> apisix.consumer.init_worker() > 开始监听 etcd consumers> apisix.core.config_yaml.init_worker() 如果注册中心使用yaml的话,加载配置文件。> apisix.debug.init_worker() 调试相关方法> 初始化dns缓存
apisix请求处理
在apisix中,一个完整的请求生命周期,从前到后包含六个部分,请求如图所示:
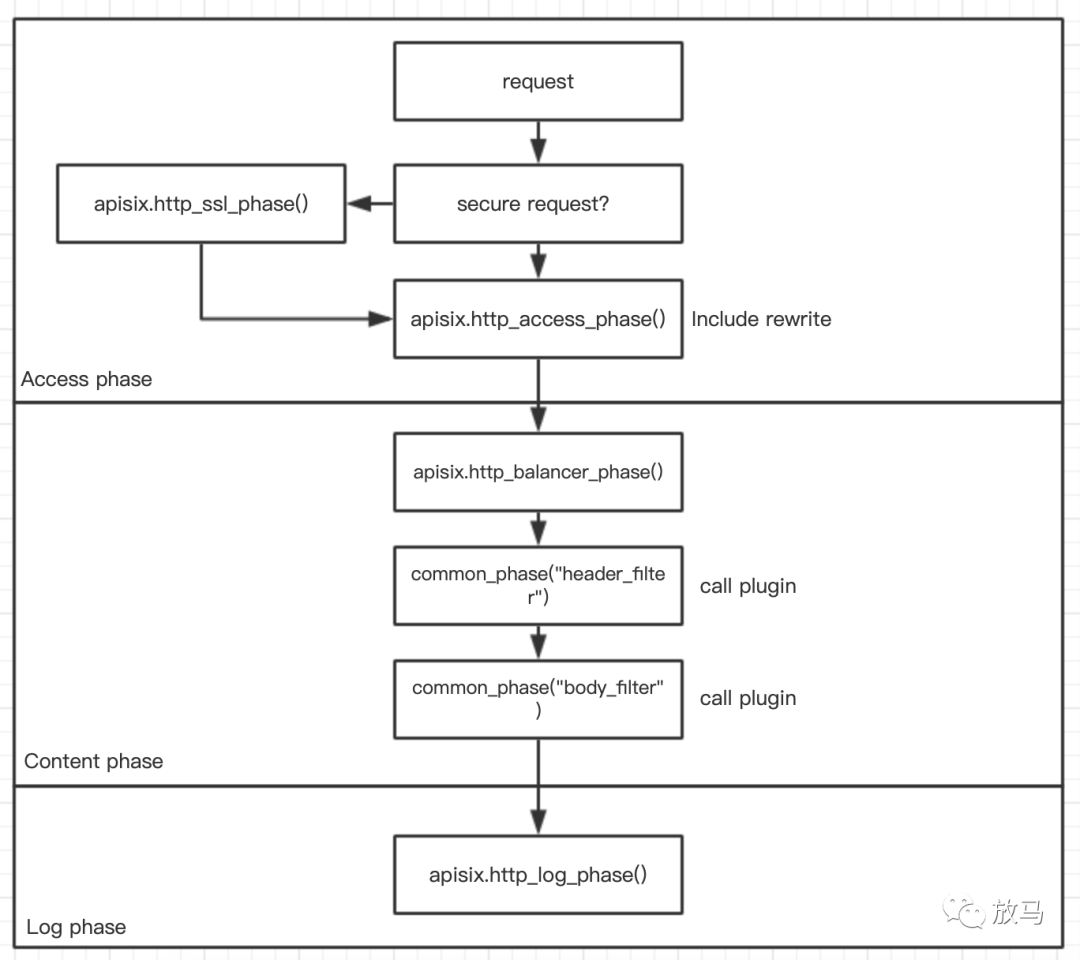
apisix的大部分逻辑还是在配置变更方面,用于处理请求的代码反而不是很多,整体处理流程如下:
http_ssl_phase> router.router_ssl.match_and_set(api_ctx)> 设置上下文> radixtree_router:dispatch获取证书,如果获取不到则返回failed to fetch SNI> set_pem_ssl_key 清除默认证书,并使用etcd中的证书替换http_access_phase> 调用全局rewrite插件> 调用全局access插件> radixtree_uri match域名、路由匹配> 如果是grpc则转发到grpc逻辑处理> 获取service并合并service配置> 解析后端域名> 调用rewrite插件> 合并consumer配置,做身份认证> 调用access插件http_balancer_phase> 如果有balancer插件,则调用balancer插件。> 否则调用默认的balancer插件。common_phase(header_filter)> 调用header_filter插件common_phase(body_filter)> 调用body_filter插件http_log_phase> 调用log插件> 清理tablepool
apisix运维方案
在弄清了apisix的架构和使用方法之后,运维方案便比较简单了:
目录方案:apisix不强行依赖任何文件目录,可以随意定制,只需要系统PATH中存在openresty。
启动方案:openresty -p $openresty_dir -c $openresty_dir/conf/nginx.conf
停止方案:openresty -p $openresty_dir -c $openresty_dir/conf/nginx.conf -s stop
reload方案:openresty -p $openresty_dir -c $openresty_dir/conf/nginx.conf -s reload
扩容方案:LVS后面增加节点。
apisix管理方案:
有两种配置管理方案:
apisix自身实现了配置管理的部分接口,可以通过调用接口进行配置管理。apisix同时提供了简易的控制台(vuejs),可以基于此二次开发。
直接操作etcd。
apisix 管理接口权限校验方案:
目前apisix管理api提供了两种鉴权方案,
ip白名单。
写在配置中的token。
备注:目前apisix还没有提供动态可配token的方案,所以前期需要ip白名单+token一起用。
apisix证书管理方案:
证书更换是我以前面临过的问题之一。
一般半年或者一年一换,所有涉及到证书的系统重启更新证书,是一件体力活。
而apisix的证书存储在etcd,可以通过接口或者api动态配置,在ssl_certificate_by_lua_block阶段替换证书。
http_ssl_phase> core.tablepool.fetch("api_ctx")> router.router_ssl.match_and_set(api_ctx)> create_router> radixtree_router:dispatch 获取证书,如果获取不到则返回failed to fetch SNI> set_pem_ssl_key 清除默认证书,并使用etcd中的证书替换
apisix与k8s集成方案:
两种方式:
使用apisix提供的ingress-controller,绑定到service。
使用k8s提供的clusterip。
upstream提供了k8s_deployment_info选项,但是目前还是TODO状态。
备注:
ingress controller 尚不完善,可能需要投入人力进一步开发。
apisix日志收集方案:
nginx日志:
使用logkit,filebeat,fluentd或者logagent,都会提供对应的nginx日志收集工具收集nginx日志。
其他日志:
apisix也预设了kafka-logger、tcp-logger、http-logger、syslog插件,也可以自己开发插件,也可以自己开发。
apisix 二次开发方案:
apisix插件逻辑预设了如下埋点,都是一些通用插件逻辑,不再赘述:
属性:attr:versionpriorityname方法:initcheck_schema 检查配置json格式rewriteaccessbalancerheader_filterbody_filterlog
我们知道,分布式追踪在网关上面的实现方式,用一句话描述的话,“在请求头中预埋trace id”。
以自带的zipkin插件为例:
rewrite 阶段进行trace id埋点function _M.rewrite(conf, ctx).......ctx.opentracing_sample = tracer.sampler:sample().......local request_span = tracer:start_span("apisix.request", {child_of = wire_context,start_timestamp = start_timestamp,tags = {component = "apisix",["span.kind"] = "server",["http.method"] = ctx.var.request_method,["http.url"] = ctx.var.request_uri,}).......endaccess阶段启动一个子span,用于统计access阶段的调用时长function _M.access(conf, ctx)......opentracing.proxy_span = opentracing.request_span:start_child_span("apisix.proxy", ctx.ACCESS_END_TIME)......endlog阶段作收尾和上报工作function _M.log(conf, ctx)......local log_end_time = opentracing.tracer:time()opentracing.body_filter_span:finish(log_end_time)......opentracing.request_span:set_tag("http.status_code", upstream_status)opentracing.proxy_span:finish(log_end_time)opentracing.request_span:finish(log_end_time)......local ok, err = ngx.timer.at(0, report2endpoint, reporter)end
所以如果我们想要实现对应的插件,只需要按照apisix插件的格式,实现对应的功能,并注册到config.yaml中。
apisix的缺陷:
apisix目前存在部分问题,根据我所看到的代码和实践经验,总结如下:
| 可能存在问题的模块 | 可能存在的问题 |
| 心跳模块 | heartbeat默认每小时向https://www.iresty.com/apisix/heartbeat发送一次心跳信息,可能存在信息泄露的风险,需要手动关闭该模块。 |
请求重试 | 默认不会配置健康检查请求。 请求失败,重试次数至少一次,默认重试次数和upstream中配置的vhost个数数相同,无法设置不重试。 当负载均衡算法为roundrobin时,会将upstream中所有的上游重试一遍。 当负载均衡算法为hash时,只会对当前的上游机器进行重试。 |
限流插件 | 全局限流插件依靠redis,一次请求对应三次redis操作。可能会导致redis流量过大,需要手动改成令牌桶等算法。 |
apisix的性能测试
本性能测试不算特别规范,尤其是当我使用压测机2测试的时候,家用交换机的延迟在0.5ms左右,比请求本身的时间还要高,所以测试数据仅供参考。
测试方法:wrk -d 10 -c ${连接数} http://192.168.56.26:9080/hello
测试参数:服务线程:1,转发线程:1。
| 场景 | openresty提供服务 | 使用openresty转发 | 使用apisix转发(不开启插件) | 使用apisix转发(开启限流插件) |
| 本机施压/2连接数 | 68461 0.03ms | 15895 0.12ms | 18938 0.1ms | 19058 0.1ms |
| 本机施压/16连接数 | 69565 0.22ms | 17459 0.92ms | 41859 0.48ms | 37906 0.49ms |
| 测试机2施压/2连接数 | 2971 0.66ms | 2568 0.76ms | 2084 / 0.94ms | 2189 / 0.90ms |
| 测试机2施压/16连接数 | 17654 / 0.82ms | 13899 / 1.02ms | 16670 / 0.87ms | 16186 / 0.90ms |
没错,我个人测试的场景中,openresty提供服务+openresty转发,性能好像更差一点。
apisix的用户
我一向提倡“eat your own dog food”的开发模式,自己是自己的用户,自己是自己的开发。
homelabbity.com的技术栈如下图所示:

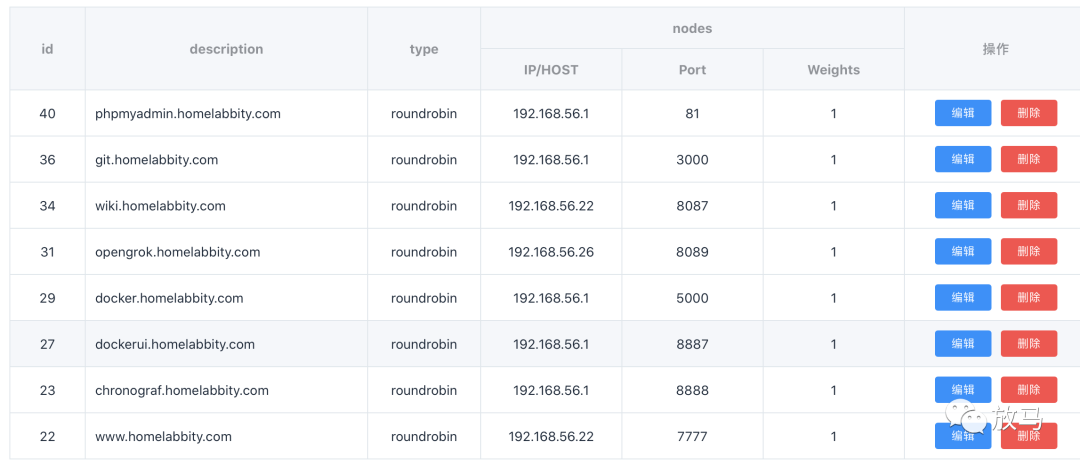
而在调研了apisix之后,homelabbity.com也很快迁移到了apisix,效果如图所示:
jenkins本身依赖一些比较高级的nginx参数,因此不太好向apisix迁移,我正在寻找新的解决办法。
这也引出了最后一个问题。
当业务比较简单、使用nginx独有特性不太多的情况下,是很好向apisix做迁移的。
但是当业务大量依赖nginx的某些功能,或者背有沉重的历史包袱的时候,迁移的成本比较高。插件可以写,功能可以做,但是梳理域名终归是个细致的体力活,一不小心就做错。
这也就是目前迁移到apisix可能存在的最大问题。
