




摘要
本文是对CVPR2020 Workshop中的论文《Interpreting mechanisms of prediction for skin cancer diagnosis using multi-task learning》的解读,该论文提出了一种多任务学习框架,可以对基于深度学习的皮肤镜图像分类问题内部的机制进行解释。论文根据皮肤镜诊断准则7 point checklist构造了七个子任务,然后提出Gate Block来对各个任务进行整合并观察不同任务之间的关联程度,以此进行神经网络的可解释性分析。文章使用了Derm7pt数据集,并在测试集上取得了较好的效果。
01.
多任务学习相关工作
多任务学习(Multi-task learning)方法是机器学习的一种训练范式,多任务学习过程比单任务学习更准确地反映了人类的学习过程,因为整合跨领域的知识是人类与生俱来的天赋。例如,若新生儿学会走路,他就会学习到与平衡相关的抽象概念和直观上物理学的一般运动技能,这些抽象概念可以被用于以后生活中更复杂的任务,如骑自行车。
人类学习新知识往往是基于拥有大量的先验知识情况下进行的,而单任务的深度学习模型往往是从头进行的,这也是为什么深度学习往往需要大量的数据集和时间,而人类在某个领域常常用极少的样本做到“触类旁通”。
目前多任务学习的手段主要分为三个方向:架构设计(architecture design)、优化方法(optimization)与任务关系学习(task relationship learning)[1]。
1.1 架构设计
目前各领域中都研发了各种形态不同的网络架构,本文只讨论计算机视觉中常用的网络结构。
首先是共享骨干网络,这是传统计算机视觉中的许多多任务架构都遵循的简单范式:一个由所有任务共享的卷积层组成的全局特征提取器,而对于单独任务则有自己的分支。其中Zhang、Dai和Ma等人分别研发了不同的共享骨干网络设计细节,Zhang等人最早采用基础的多叉树型网络结构做图像分类[2],Dai等人则采用级联模式以类似循环神经网络的结构构建任务之间的协同[3],Ma则提出了一种基于骨干网络输出线性组合的网络结构,通过多个门控制不同任务之间共享骨干网络的情况[4],图1展示了Zhang等人的网络结构。

图1 共享骨干网络典型架构
其次是交叉网络,这种架构为每个任务设计一个单独的网络,而不是单一的共享网络,但在不同的任务网络中共享某些权重和信息,图2是一种典型的交叉网络结构,这是Misra等人在2016年发表的Cross-Stitch network,这种网络通过并行层将不同子任务之间的特征图进行线性整合,从而达到各个任务之间的全流程中间信息共享[5]。另外,对于交叉网络结构,还有一项有名的工作是来自Gao等人的NDDR-CNN,这种网络用堆叠与1*1卷积代替简单的线性组合,进行多任务之间的共享[6],在本文所解读的论文中也用到了类似的思想和结构,其网络架构如图2所示。
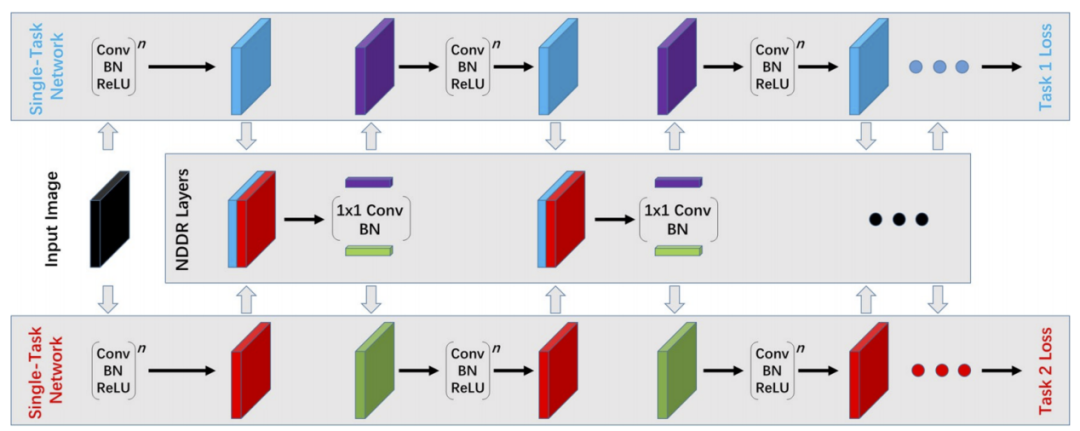
图2 NDDR-CNN网络架构
除此之外,目前还有许多不同的架构形式,如基于二进制掩码的任务路由架构,这种架构将交叉网络做了进一步的泛化,使得不同任务之间得到了更细粒度的共享,也取得了不错的效果。还有一种将同一任务的对抗样本和正常样本混合,利用同一网络在反向传播过程中整合梯度,以达到在训练中抵御对抗样本的效果,提升模型鲁棒性。
1.2 优化方法
优化方法目前主要包括损失函数的整合、正则化参数、任务规划、梯度修正与知识蒸馏。
其中损失函数整合主要考虑如何将不同任务的损失进行有效整合,一个朴素的思想是确定不同损失的权重进行加权,由于不同任务之间的损失函数的范围有差异,所以确定的方法也不尽相同,如Kendall等人最早提出根据不确定性(也就是信息量)对不同任务进行整合[7];Chen等通过学习速度测度任务之间的权重[8],这类似GAN中平衡判别器与生成器学习速率的策略,还有一些方法如取不同损失函数的调和平均、通过评估学习质量进行加权等方法。
正则化参数主要的思想是通过约束条件对不同任务的参数进行约束,本质上是软共享参数的手段;任务规划主要关注的目标是在训练过程中对各个任务的选择进行先后次序的排列,主要思想是将子任务拆分成mini batch粒度的序列,并根据一定准则对当前训练的mini batch进行规划。
梯度修正是为了对抗多任务之间负迁移的一种具有潜力的手段,在两个不相关任务之间的梯度符号相反时,对一个任务的学习有可能会损伤另一个任务的效果,那么显式的修改梯度是一种可能防止负迁移的手段。
知识蒸馏是最常用的方法是向一个多任务“学生”网络学习多个单任务“教师”网络的知识,这也是人类学习知识的朴素想法——“博采众长”,在许多情况下,学生网络甚至可以获得更好的性能。
1.3 任务关系学习
任务关系学习目标是学习任务或任务之间关系的显式表示,例如通过相似性将任务聚类成组,并利用学习到的任务关系改善目标任务的效果。目前,这种方法相比前两种还处于探索研究阶段,主要的思路有:任务分组与迁移关系。
任务分组是作用与任务本身,多用于大量任务之间的相关性分析,对多任务进行相关性分析的目的是为了找到在多任务情况下到底哪些任务会促进目标任务,而哪些任务会造成任务之间的负迁移;迁移关系主要通过迁移学习构造任务之间的关系,以便对任务之间的关联性做出判断,其中Zamir将任务之间的关联性通过有向图进行表示,其结果如图3所示[9]。
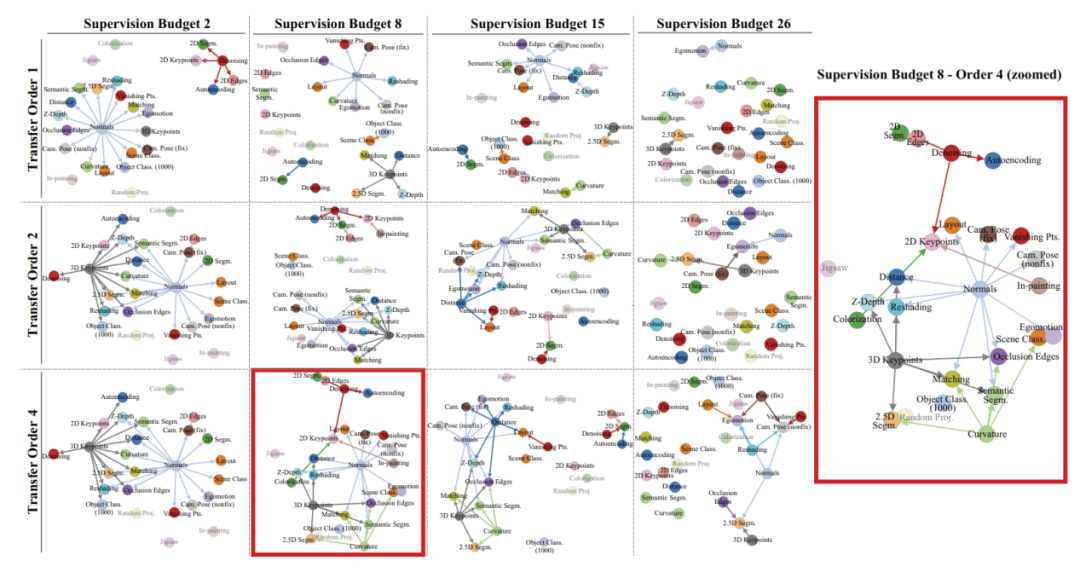
图3 基于迁移关系的任务关联图
综上所述,目前的多任务学习在深度学习中的研究范围广泛,不同学者研究了许多解决方案。本文所关注的论文采用类似架构设计的NDDR-CNN网络结构,同时也对损失函数添加了一定的正则项,并定量给出了不同任务之间的关系程度,从某种意义上来说也是一种任务关系的学习方法。
02.
皮肤镜诊断的多任务网络结构
2.1 整体架构
该论文基于7点验证法构建了七个不同的任务:诊断结果、色素网络判断、蓝色斑点、血管结构、色素沉着、纹理、轮廓、回归结构,通过这七个任务模拟专家经验及判断方法手法对不同任务进行整合。其数据集示例如图4所示:
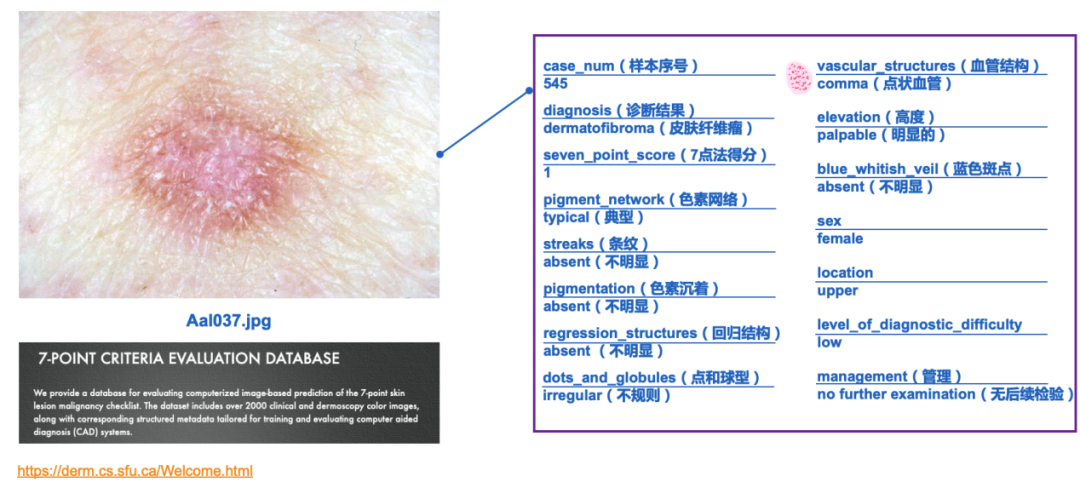
图4 数据示例
论文构建了一个gate block对多个任务分别进行独立卷积操作,并通过1*1的卷积对feature map进行整合,其整体架构如图5所示:
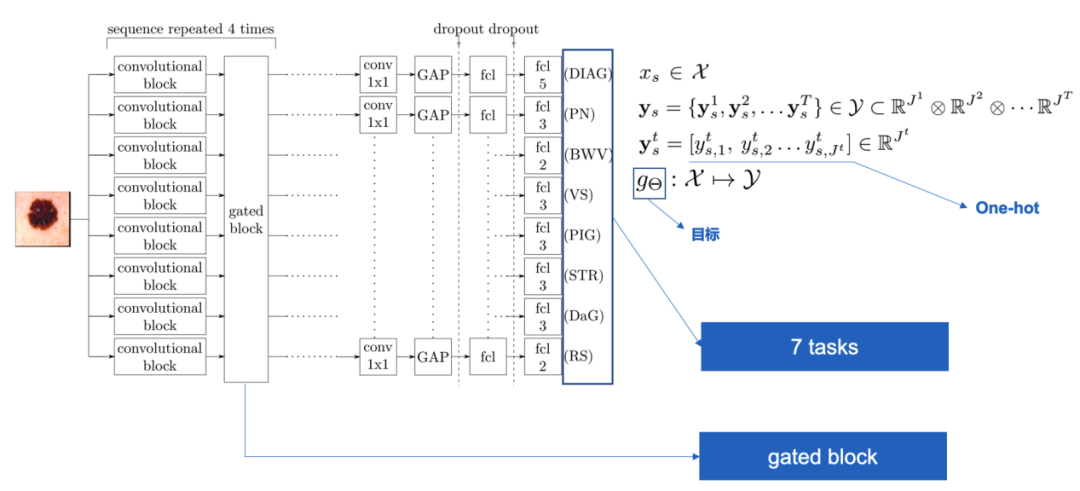
图5 网络整体架构
该架构可以被视为软共享的一种手法,通过多个“卷积-gated block”的堆叠保证对整个网络之间做中间监督,在网络后段分割任务相关的独立模块,采用“1*1卷积-全局平均池化-全连接”的结构做最终分类器,得到每一个任务的结果。
2.2 Gated Block
论文中提出的Gated Block是最主要的创新点之一,其内部是通过构造一个二进制的掩码向量在通道维度进行特征图的整合,其内部结构如下图6所示:
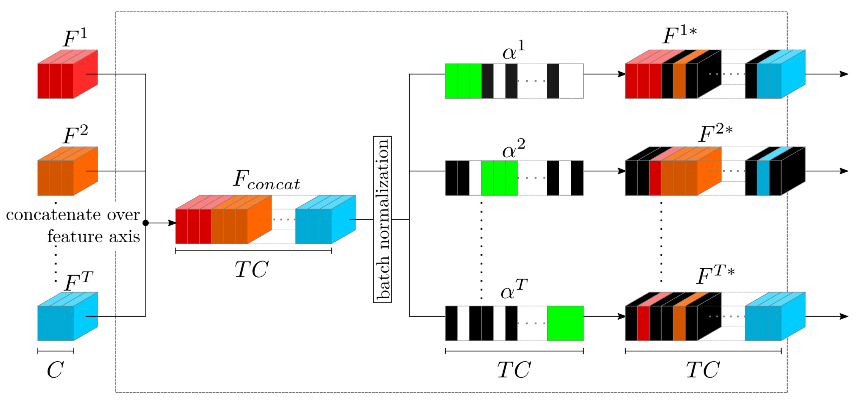
图6 Gated Block示意图
ated block接收多个卷积后的特征图,并将其堆叠起来,形成一个T*C维度的特征图,然后在进行批归一化后点乘一个二进制向量ɑ=[ɑ1,..,ɑt],由于二进制向量的值域不连续,因而其变化方式并不可导,无法进行反向传播,于是,作者采用类sigmoid函数

对原始连续变量进行连续性建模,构造一个可学习的向量。经过点乘后,其得到的特征图具备了稀疏性,图6中黑色部分表示为0的通道,这样再经过1*1卷积即可将不同特征图进行维度层面的整合,得到最后的输出。
在这里,有一个问题,1*1的卷积可以被视作channel-wise的全连接,也就是说,卷积后的每一层特征图都是前面T*C维度的特征图的加权,那么如何保证被滤去的维度(即全为0的feature层)前的系数为0呢?答案是在初始化阶段,本文采用对每个任务除自身相关的特征图对应的系数为100外,其余所有梯度的部分都以0做初始化,而在反向传播的过程中,由于其特征图层为0,那么其梯度也必然接近0,在多次训练后,被滤去的维度(即全为0的feature层)对应的系数则会几乎收敛到0,也就是保证了每个任务的“过滤”动作是切实有效的。当然,原文中并没有对此过多解读,只是笔者的一种分析。
2.3 采样策略
在本文中,由于每一个皮肤镜样本会对应不同任务的多个标签,如某一张皮肤镜图像在诊断任务中被归类为“痣”,同时在判断色素沉淀任务中被分类为“不明显”...并且由于样本的不均衡性,有些类别的样本量极少,这使得随机抽取样本会有较大概率出现某些任务的样本全属于同一类,以致无法训练到较好的结果,为了避免这种情况,本文采用了一种自定义的采样策略:首先指定超参数k,然后在对于每个标签,都在训练数据集中抽取k个样本。举例来说,某次训练抽取黑色素瘤样本3个,痣样本3个,明显的色素沉淀3个,不明显的色素沉淀3个...以此类推,论文中构造的7个任务共有24个标签,如图7所示:
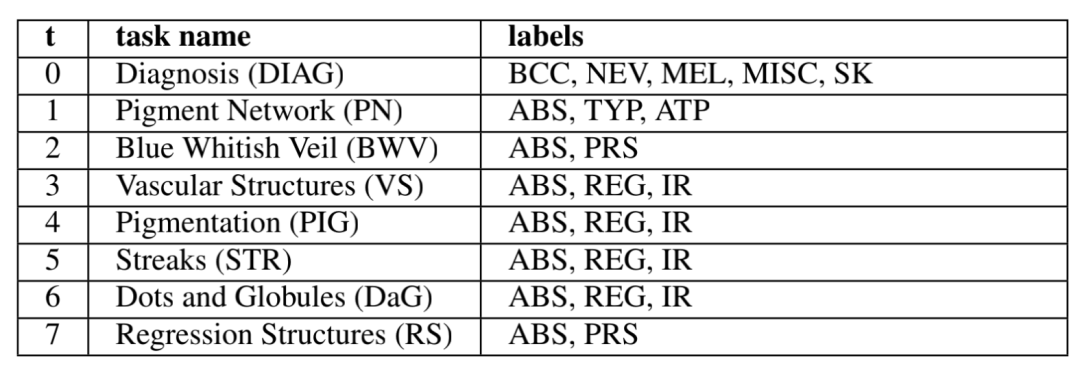
图7 任务及标签组成
这样,每个batch会存在24*k个样本,但是这些样本可能会重复,为了平衡重复的问题,论文通过下式评估每个样本的重要程度,并将其体现在损失函数中。
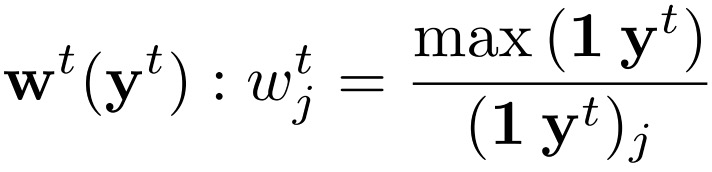
2.4 损失函数
论文的损失函数主要分为两部分:focal cross-entropy loss和L2正则项,其表达式为:
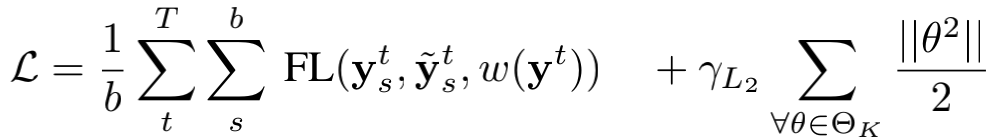
其中,
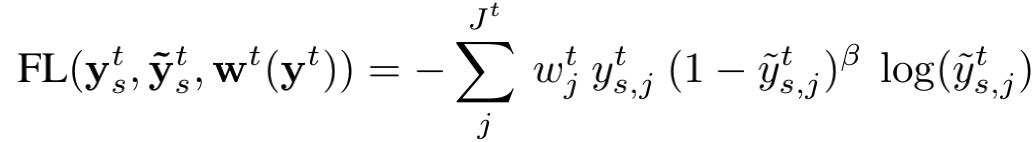
设计这种损失函数具有如下考虑:首先,focal cross-entropy loss可以解决样本不平衡问题,论文采用特殊采样策略,本质上是将样本不平衡问题“暂缓”,而利用这个损失函数可以将“暂缓”的问题彻底进行“填坑”;其次,对参数的L2正则化使得参数不要太大,这说明作者希望看到参数大小与数量的不同是否会影响后续的实验结果,但很可惜,原文中作者没有解释这样做的原因。
03.
实验结果
论文设计了五个不同种实验进行对比,其内容如图8所示:

图8 不同任务说明
作者主要通过不同实验对各个任务之间的共享关系进行评价,采用了系数的归一化作为“共享度”,其结果如下图9所示,其中越绿表示两任务之间的共享程度越大:
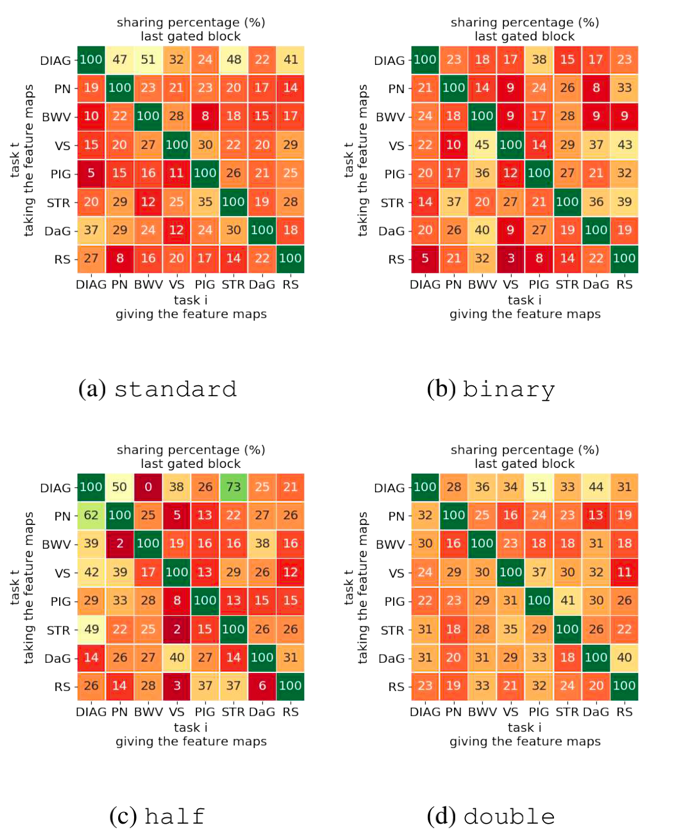
图9 不通过任务之间的共享关系
对这样的结果,可以看到在二分类任务中,任务之间几乎没有共享,而在半参数量的情况下,共享度普遍更高,作者对该现象做出了相关的解释,但这涉及到一些医学上的常识,本文更多关注方法论,在此不赘述。
04.
总结
本文对基于计算机视觉的多任务学习的相关工作做出了整理,分别从结构设计、优化方法及任务关系学习三个角度介绍现有方法。对论文《Interpreting mechanisms of prediction for skin cancer diagnosis using multi-task learning》进行解读,该论文提出了一种端到端的多任务学习框架,可以对不同任务之间的关联进行量化表达,并作为解释皮肤损伤诊断的内在机制的手段。总体来说,该论文角度新颖,将重点放在可解释性问题上,具有现实意义,但方法层面创新不多,代码没有开源。
[参考文献]
[1] Crawshaw M. Multi-task learning with deep neural networks: A survey[J]. arXiv preprint arXiv:2009.09796, 2020.
[2] Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xiaoou Tang. Facial landmark detection by deep multi-task learning.In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, Computer Vision – ECCV 2014, pages 94–108, Cham, 2014. Springer International Publishing. ISBN 978-3-319-10599-4.
[3] Jifeng Dai, Kaiming He, and Jian Sun. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3150–3158, 2016.
[4] Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, page 1930–1939, New York, NY, USA, 2018.
[5] Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Martial Hebert. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3994–4003, 2016.
[6] Yuan Gao, Jiayi Ma, Mingbo Zhao, Wei Liu, and Alan L Yuille. Nddr-cnn: Layerwise feature fusing in multi-task cnns by neural discriminative dimensionality reduction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3205–3214, 2019.
[7] Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, 2017.
[8] Danqi Chen and Christopher Manning. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 740–750, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1082.
[9] Amir R Zamir, Alexander Sax, William Shen, Leonidas J Guibas, Jitendra Malik, and Silvio Savarese. Taskonomy: Disentangling task transfer learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3712–3722, 2018.

人工智能评测服务
上海计算机软件测评重点实验室(SSTL)人工智能测评服务面向计算机视觉、语音识别、自然语言处理、推荐与搜索等领域,聚焦人工智能应用过程中的模型功能有效性评估、模型性能评估、数据集质量评估、对抗样本防御能力等,提供全方位的测评服务,保障人工智能应用的质量。
SSTL主要测评内容

上海市计算机软件评测重点实验室(简称SSTL)由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

