





摘要
本文是对来自FAIR(Facebook AI Research)的程鑫磊(XinLei)和何恺明(KaiMing)最新工作《Exploring Simple Siamese Representation Learning》的解读,该篇文章发表在CVPR2021上,并获得最佳论文提名。数据标注成本越来越高,如何在大量无标注的数据中学习到有效表征是十分重要的问题,因为这对于工业界模型落地有重大的意义。自SimCLR以来,计算机视觉领域中关于无监督特征学习的工作层出不穷,这些工作大多数都是基于对比学习的。对比学习中孪生网络已成为一种常见的结构,这种结构通过最大化一个图像的两种变换之间的相似性来学习到有意义的表征。但这样学习有可能会导致模型退化为一个常数,这种现象称为模型坍塌。论文作者探索出一种简单的孪生网络(Simple Siamese 以下简称SimSiam)即使在不使用负样本对、大批量、动量编码器的情况下也能够学习到有意义的特征表达。论文中采用梯度截断(stop-gradient)操作截断一侧网络的梯度传播防止模型退化,并通过实验验证这一操作在预防坍塌中起着至关重要的作用。实验表明,SimSiam在基于ImageNet的分类任务以及基于VOC的下游任务(检测、分割)上取得了有竞争力的结果,论文作者在论文中对SimSiam不退化的原因提出了思考,希望该方法能够激励学者重新思考在无监督表征学习中的孪生网络结构的作用。
对比学习
对比学习是一种无监督(自监督)的图像/文本的表示学习。其最初的动机是:人类最初往往是通过比对多种事物之间的差异来进行特征学习的,并且人类在学习的过程中往往不学习事物的细节(如图像的像素),而是学习足以区分对象的高层次语义特征。举例来说,不难分辨下图的A、B两张图像描述的是一个场景,但是我们可以看出,其中像素级别上的整体位置是发生了较大改变的,理论上来说,一个较好的人工智能模型应该能够像人一样,顺利的分辨出两张图像的语义相似度,而对比学习也就是为解决这样的问题而产生的。

图1 类似图的不同位置
对比学习的思想就是通过构造比对样本对,学习到一个表征函数,能够使得同类样本之间的相似度远远大于非同类样本之间的相似度。
目前,基于这种思想,SimCLR、SwAV、BYOL等模型不断涌现,刷新各大排行榜。深度学习两巨头Bengio和LeCun在ICLR 2020上也说Self-Supervised Learning(SSL,自监督学习)是AI的未来,代表便是对比学习,一时间对比学习热度甚高,而下文主要介绍的就是Kaiming提出的模型SimSiam。
对比学习常见算法简介
SimCLR是较早的对比学习算法。其利用了大量的负样本进行对比学习,主要思想为:同类应该具有不变性,于是对输入的图片进行随机数据增强(随机剪裁、旋转、颜色过滤、灰度化等),以此来模拟图片不同视角下的输入,同时将不同类的图片作为负样本输入(图2)。之后正负样本均通过一个编码器(encoder)进行编码,定义一个函数来度量样本之间的相似度(比较经典的为向量内积),然后试图最大化同类样本在不同数据增强下的相似度,并最小化非同类之间的相似度。由于负样本的存在,模型不易坍塌。实验证明了:在基于负样本的对比学习中,负样本数量越多,对比学习模型效果越好,因此这类对比学习模型的Batch Size往往会非常大。

图2 正负样本示例图
之后衍生出许多不需要负样本的对比学习算法,其中一个比较有名的就是在模型中加入聚类思想的SwAV。SwAV比较不同视角下的经过encoder后的聚类结果而不是直接对比特征。看上去并未使用负样本,但他要求两个通过数据增强后的样本聚类后的中心越近越好,而与其它聚类中心越远越好。本质上,它与直接采用负样本的对比学习模型,在防止模型坍塌方面作用机制是类似的,采用了一种隐形的负样本。
另一种对防止模型坍塌有效的模型为BYOL,它的结构不同于SimCLR的两个encoder之间的权值共享,而是其中一个encoder的权值是另一个encoder权值的加权平均。目前还未有定论为什么这个模型能够防止崩塌,但一定与这种非对称的结构相关。
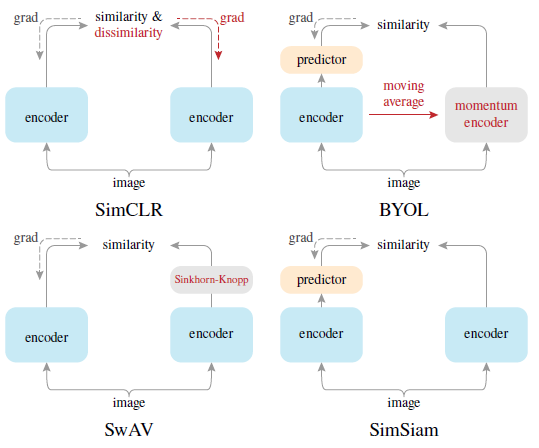
图3 simsiam与其他模型结构对比图
SimSiam模型介绍
SimSiam模型架构(图3右下)是以图像x的两个随机增强得到x1和x2作为输入。这两个视图由一个编码器网络f处理后得到z1和z2,该网络由一个骨干网络(例如ResNet)和一个多层感知机组成。编码器f在两个视图之间共享权重。再将经过z1一个预测多层感知机 (表示为h)后输出为p1。即表示为p1=h(f(x1)和z2=f(x2),然后最小化它们的负余弦相似度D,定义一个对称的损失函数
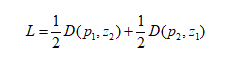
在反向传播过程中有一个重要组成部分就是对模型右边进行梯度截断操作。这意味着z2在这一项中是常数。则损失函数变为
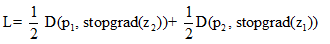
在这里,x2上的编码器的第一项没有接收到来自z2的梯度,但第二项接收到来自p2的梯度(x1也是如此)。
作者还通过理论和实验从侧面验证梯度截断是模型不坍塌的重要原因。理论上解释导入梯度截断操作等同于引入一些虚构的参数(隐变量),让SimSiam的学习机理类似于EM算法,去估算数据增广后的期望值。另外梯度截断的效果对比实验如图4。
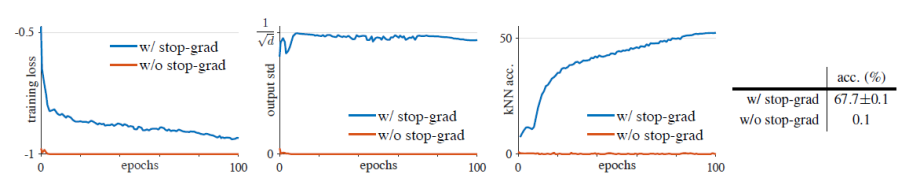
图4 梯度截断对比结果展示
实验结果
作者分别在ImageNet的分类任务以及基于VOC的下游任务(检测、分割)上做了实验,对比了各种不同对比学习框架的效果。
表1 SimSiam实验结果
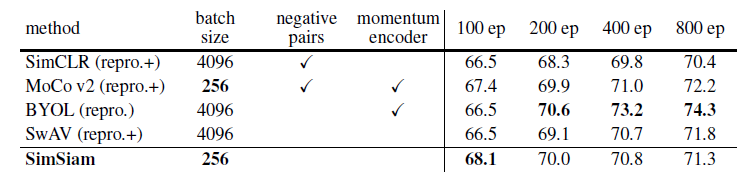
表1显示了SimSiam与其他对比学习模型在ImageNet线性分类任务上的精度比较。SimSiam以256批大小进行训练,既不使用负样本也不使用动量编码器。尽管它很简单,还是取得了很有竞争力的结果。在所有方法中,100轮训练周期的预训练的准确率最高,但训练时间越长获得的收益越小。在所有情况下,它的效果都优于SimCLR。BYOL可以算是在SimSiam模型上的一个改进。
表2 常见对比学习算法在下游任务中的表现
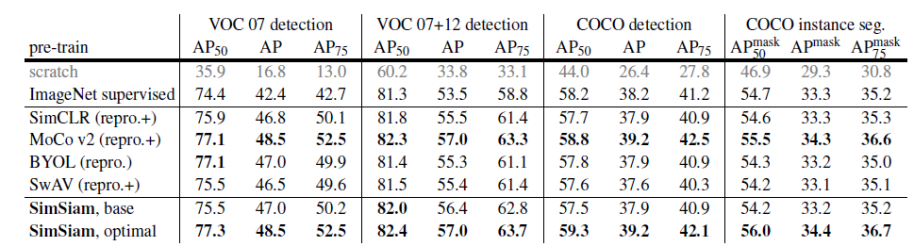
通过将它们转移到其他任务,包括VOC目标检测、COCO目标检测和实例分割,来比较它们的表征质量。在表2中可以看到SimSiam表征可以很好的迁移到ImageNet以外的任务上,迁移模型的性能极具竞争力。另外其他的对比学习方法如SimCLR、BYOL、SwAV等在迁移学习中都是非常成功的,在所有任务中性能都可以超过或与ImageNet有监督下的预训练对应的方法相当。尽管有许多设计上的差异,这些方法的共同结构是孪生网络。这一比较表明,孪生结构是它们普遍成功的一个核心因素。
总结
在计算机视觉领域中,对比学习是近年来实现自监督学习最热门的方法之一,目标在于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。由于只需要在抽象语义级别的特征空间上学会对数据的区分即可,使得模型变得更加简单,泛化能力更强。由于孪生网络天然具有建模不变性的特征,而这也是表征学习的核心所在,目前最流行的对比学习框架都是基于孪生网络。为了解决模型坍塌问题,不同模型采取了不同的措施,例如SimCLR加入负样本,SwAV利用聚类,而SimSiam用梯度截断机制同样消除了模型坍塌问题并从侧面验证了孪生网络在对比表征学习中的重要性。作者希望他们的研究能够引起人们对于孪生网络在表征学习中的基本作用的关注。
人工智能评测服务
上海计算机软件测评重点实验室(SSTL)人工智能测评服务面向计算机视觉、语音识别、自然语言处理、推荐与搜索等领域,聚焦人工智能应用过程中的模型功能有效性评估、模型性能评估、数据集质量评估、对抗样本防御能力等,提供全方位的测评服务,保障人工智能应用的质量。
主要测评内容包括:
A 人工智能模型的功能有效性
包括混淆矩阵、准确率、精度、召回率、F1-Score、ROC、AUC等测评指标
B 人工智能模型的性能
包括模型推断时间、模型运行占用的资源、模型的压缩程度、模型的存储需求、模型的算力需求等
C 人工智能系统数据集质量评估
包括数据集规模、数据集标注质量、数据集的均衡性等
D 人工智能系统防御对抗样本能力
利用自研的对抗样本生成工具,通过白盒或黑盒的方式生成对抗样本,评估系统防御对抗样本的能力、系统对于物理世界攻击的防御能力等
E 人工智能系统的鲁棒性
包括干扰数据对系统的影响、数据集分布对系统的影响、业务不相关数据对系统的影响等
F 人工智能系统的安全性
包括模型是否采用加密算法、系统的功能安全认证、接口安全认证、网络通讯的安全性等
G 人工智能治理评估
包括模型的可解释性、模型的公平性、系统的应用风险、系统的伦理风险等

上海市计算机软件测评重点实验室(简称SSTL),由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
